Scraping Walmart can have many use cases. It is the leading retailer in the USA & has enormous public product data available.
When web scraping prices for Walmart products you can have a close look at any price change.
If the price is lower then you can prefer to buy it. You create a Walmart price scraper that can show trends in price change over a year or so.
In this article, we will learn how we can web scrape Walmart data & create a Walmart price scraper, we will be using Python for this tutorial.
But, Why Scrape Walmart with Python?
Python is a widely used & simple language with built-in mathematical functions. It is also flexible and easy to understand even if you are a beginner. The Python community is too big and it helps when you face any error while coding.
Many forums like StackOverflow, GitHub, etc already have the answers to the errors that you might face while coding when you do Walmart scraping.
You can do countless things with Python but for the sake of this article we will be extracting product details from Walmart.
Let’s Begin Web Scraping Walmart with Python
To begin with, we will create a folder and install all the libraries we might need during the course of this tutorial.
For now, we will install two libraries
- Requests will help us to make an HTTP connection with Walmart.
- BeautifulSoup will help us to create an HTML tree for smooth data extraction.
>> mkdir walmart
>> pip install requests
>> pip install beautifulsoup4
Inside this folder, you can create a python file where we will write our code. We will scrape this Walmart page. Our data of interest will be:
- Name
- Price
- Rating
- Product Details
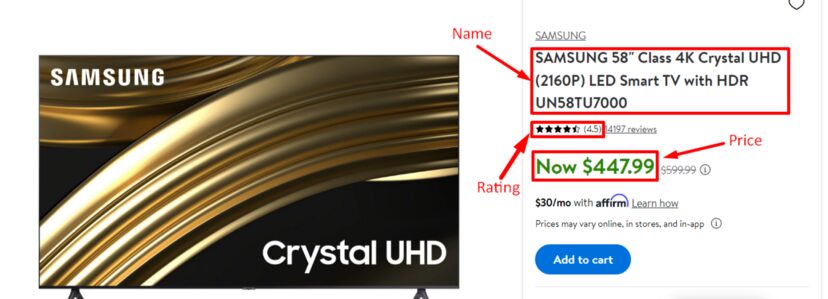
First of all, we will find the locations of these elements in the HTML code by inspecting them.

We can see the name is stored under tag h1 with attribute itemprop. Now, let’s see where the price is stored.
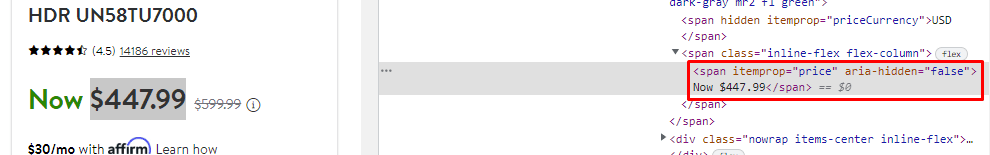
Price is stored under span tag with attribute itemprop whose value is price.
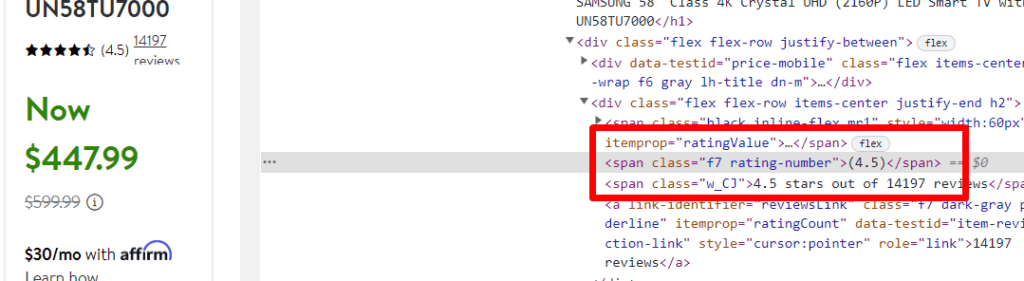
The rating is stored under span tag with class rating-number.
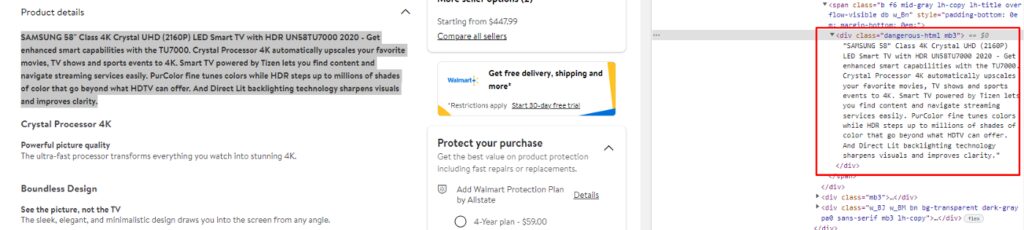
Product detail is stored inside div tag with class dangerous-html.
Let’s start with making a normal GET request to the target webpage and see what happens.
import requests
from bs4 import BeautifulSoup
target_url="https://www.walmart.com/ip/SAMSUNG-58-Class-4K-Crystal-UHD-2160P-LED-Smart-TV-with-HDR-UN58TU7000/820835173"
resp = requests.get(target_url).text
print(resp)
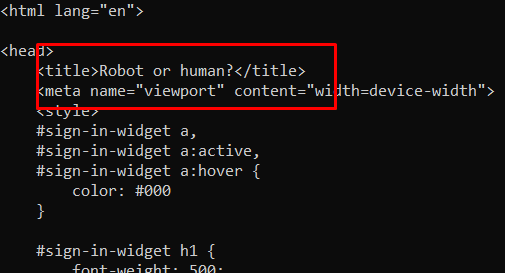
Oops!! We got a captcha.
Walmart loves throwing captchas when they think the request is coming from a script/crawler and not from a browser. To remove this barrier from our way we can simply send some metadata/headers which will make Walmart consider our request as a legit request from a legit browser.
Now, if you are new to web scraping then I would advise you to read more about headers and their importance in Python. For now, we will use seven different headers to bypass Walmart’s security wall.
- Accept
- Accept-Encoding
- Accept-Language
- User-Agent
- Referer
- Host
- Connection
import requests
from bs4 import BeautifulSoup
ac="text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"
target_url="https://www.walmart.com/ip/SAMSUNG-58-Class-4K-Crystal-UHD-2160P-LED-Smart-TV-with-HDR-UN58TU7000/820835173"
headers={"Referer":"https://www.google.com","Connection":"Keep-Alive","Accept-Language":"en-US,en;q=0.9","Accept-Encoding":"gzip, deflate, br","Accept":ac,"User-Agent":"Mozilla/5.0 (iPad; CPU OS 9_3_5 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13G36 Safari/601.1"}
resp = requests.get(target_url, headers=headers)
print(resp.text)
One thing you might have noticed is Walmart sends a 200 status code even when it returns a captcha. So, to tackle this problem you can use the if/else statement.
if("Robot or human" in resp.text):
print(True)
else:
print(False)
If it is True then Walmart has thrown a captcha otherwise our request was successful. Nest step is to extract our data of interest.
Here we will use BS4 and will scrape every value step by step. We have already determined the exact location of each of these data elements.
soup = BeautifulSoup(resp.text,'html.parser')
l=[]
obj={}
try:
obj["price"] = soup.find("span",{"itemprop":"price"}).text.replace("Now ","")
except:
obj["price"]=None
Here we have extracted the price and then replace “Now ” (garbage string) with an empty string. You can use try/except statements to catch any errors.
Now similarly, let’s get the name and the rating of the product. We will come to the product description later.
try:
obj["name"] = soup.find("h1",{"itemprop":"name"}).text
except:
obj["name"]=None
try:
obj["rating"] = soup.find("span",{"class":"rating-number"}).text.replace("(","").replace(")","")
except:
obj["rating"]=None
l.append(obj)
print(l)
We got all the data except “product detail”. Once you scroll down to your HTML data returned by your python script you will nowhere find this dangerous-html class.
The reason behind this is the framework used by the Walmart website. It uses the Nextjs framework which sends JSON data once the page has been rendered completely. So, when the socket connection was broken product description part of the website was not loaded.
But the solution to this problem is very easy and it can be scraped in just two steps. Every Nextjs-backed website has a script tag with id as __NEXT_DATA__.

This script will return all the JSON data that we need. Since this is done through Javascript we could not have scraped it with a simple HTTP GET request. So, first of all, you have to find it using BS4 and then load it using the JSON library.
import json
nextTag = soup.find("script",{"id":"__NEXT_DATA__"})
jsonData = json.loads(nextTag.text)
print(jsonData)
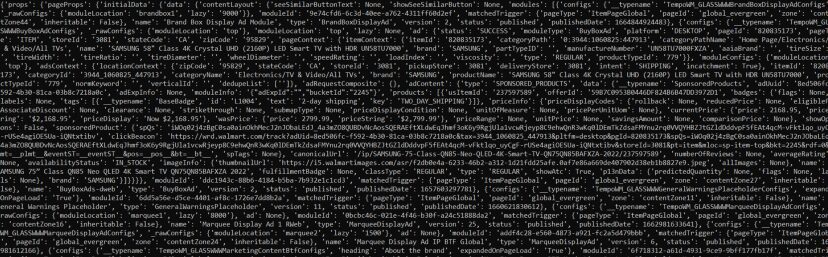
This is a huge JSON data which might be a little intimidating. You can use tools like JSON viewer to figure out the exact location of your desired object.
try:
obj["detail"] = jsonData['props']['pageProps']['initialData']['data']['product']['shortDescription']
except:
obj["detail"]=None
We got all the data we were hunting for. By the way, this huge JSON data also contains the data we scraped earlier. You just have to figure out the exact object where it is stored. I leave that part to you.
If you want to learn more about headers, requests, and other libraries of Python then I would advise you to read this web scraping with Python tutorial.
Complete Code
import requests
from bs4 import BeautifulSoup
ac="text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"
target_url="https://www.walmart.com/ip/SAMSUNG-58-Class-4K-Crystal-UHD-2160P-LED-Smart-TV-with-HDR-UN58TU7000/820835173"
headers={"Referer":"https://www.google.com","Connection":"Keep-Alive","Accept-Language":"en-US,en;q=0.9","Accept-Encoding":"gzip, deflate, br","Accept":ac,"User-Agent":"Mozilla/5.0 (iPad; CPU OS 9_3_5 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13G36 Safari/601.1"}
resp = requests.get(target_url)
# print(resp.text)
# if("Robot or human" in resp.text):
# print(True)
# else:
# print(False)
soup = BeautifulSoup(resp.text,'html.parser')
l=[]
obj={}
try:
obj["price"] = soup.find("span",{"itemprop":"price"}).text.replace("Now ","")
except:
obj["price"]=None
try:
obj["name"] = soup.find("h1",{"itemprop":"name"}).text
except:
obj["name"]=None
try:
obj["rating"] = soup.find("span",{"class":"rating-number"}).text.replace("(","").replace(")","")
except:
obj["rating"]=None
import json
nextTag = soup.find("script",{"id":"__NEXT_DATA__"})
jsonData = json.loads(nextTag.text)
Detail = jsonData['props']['pageProps']['initialData']['data']['product']['shortDescription']
try:
obj["detail"] = Detail
except:
obj["detail"]=None
l.append(obj)
print(l)
Limitation
The above approach is fine until you want to scrape a few hundred pages. However, this approach will not work if you’re going to scrape millions of pages because Walmart will block your IP, ultimately blocking your data pipeline.
To avoid this situation you must use web scraping APIs like Scrapingdog. Scrapingdog will handle proxy rotation, headers, retries, and headless browsers for you so that you can focus on data collection.
Scraping Walmart with Scrapingdog
Scrapingdog provides Walmart Scraper API that can help you create a seamless data pipeline in no time. The first 1000 credits are absolutely FREE and you can sign up for the free trial from here.
You can test the API directly from the dashboard.
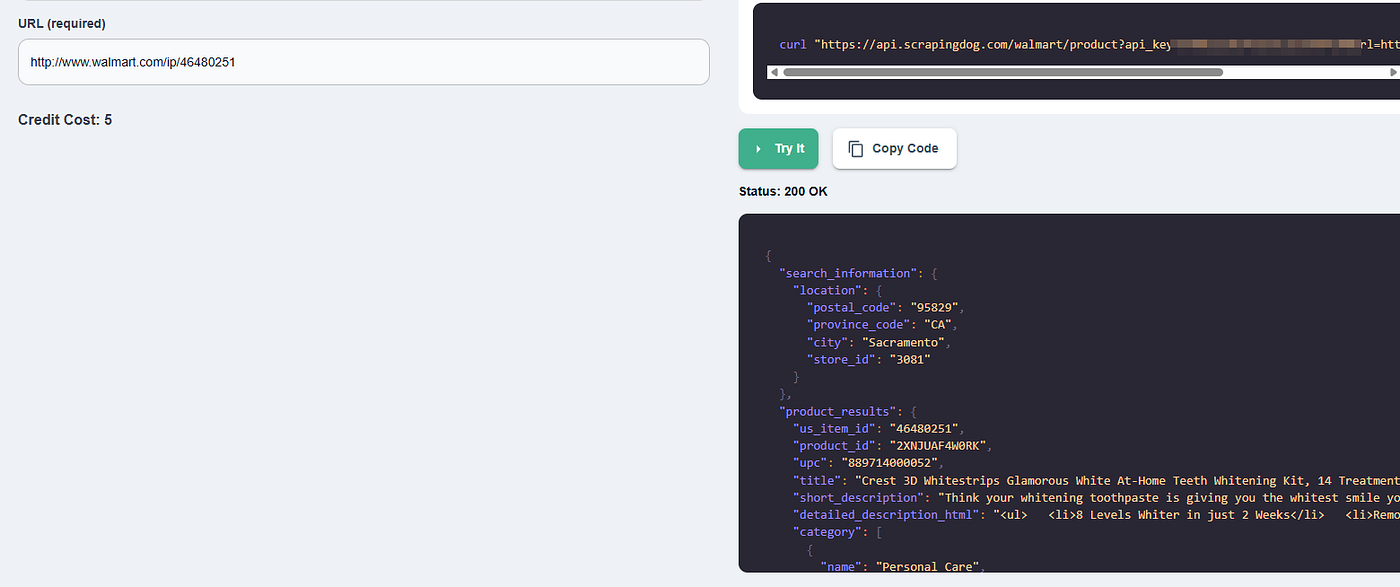
You can even copy the Python code from the right.
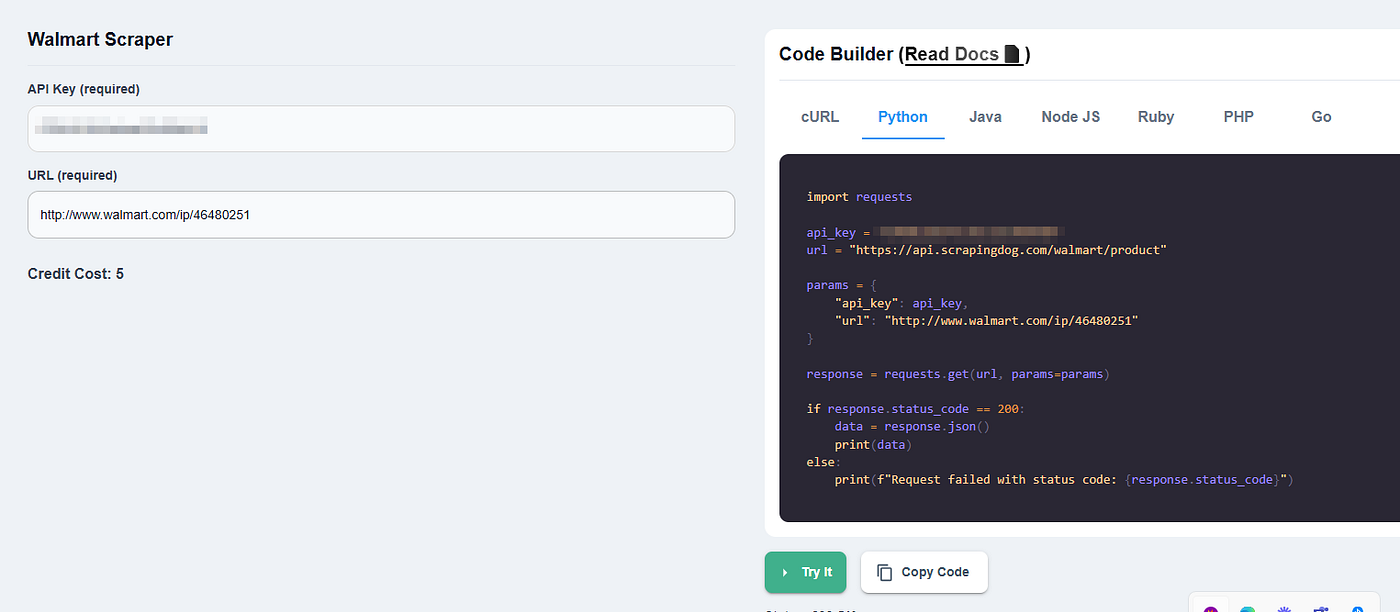
import requests
api_key = "Your-API-key"
url = "https://api.scrapingdog.com/walmart/product"
params = {
"api_key": api_key,
"url": "http://www.walmart.com/ip/46480251"
}
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
print(data)
else:
print(f"Request failed with status code: {response.status_code}")
Remember to use your own API key in the above Python code. Once you run this code you will get beautiful parsed JSON data with all the valuable data from the Walmart product page.
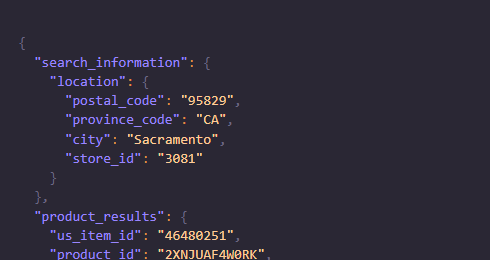
I have also created a video tutorial on scraping Walmart at scale with Scrapingdog. Do check it out
Conclusion
As we know Python is too great when it comes to web scraping. We just used two basic libraries to scrape Walmart product details and print results in JSON. But this process has certain limits and as we discussed above, Walmart will block you if you do not rotate proxies or change headers timely.
If you want to scrape thousands and millions of pages then using Scrapingdog will be the best approach.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on social media.
Additional Resources
- Amazon Price Scraping using Python
- Building A Price Tracker for Amazon Products using Python
- Automating Amazon Price Tracking using Scrapingdog’s Amazon Scraper API & Make.com
- How to Scrape Flipkart Indian e-commerce Brand using Python
- How To Scrape Google Shopping using Python
- Web Scraping eBay Product Details using Python
- Web Scraping Myntra with Selenium & Python
- Web Scraping Yelp Reviews using Python
- Web Scraping Yellow Pages using Python
- What is User-Agent in Web Scraping & How To Use Them
Web Scraping with Scrapingdog



