Today, we will be exploring how to scrape X (formerly Twitter) and extract valuable information by web scraping Twitter using Python programming language.
Social media, particularly Twitter, has become a rich and real-time source of information, opinions, and trends. Extracting data from Twitter can provide us with a ton of information, enabling us to analyze public sentiment, track market movements, and uncover emerging trends.
This comprehensive guide will walk you through the process of web scraping Twitter, step by step, so that even if you are a beginner, you’ll quickly gain the confidence and know-how to get valuable insights from the sea of tweets.
We will be using Python & Selenium to Scrape Twitter.com!
Setting up the prerequisites for scraping Twitter
In this tutorial, we are going to use Python 3.x. I hope you have already installed Python on your machine. If not then you can download it from here.
Also, create a folder in which you will keep the Python script. Then create a Python file where you will write the code.
mkdir twitter
Then create a Python file inside this folder. I am naming it twitter.py. You can use any name you like.
Along with this, we have to download third-party libraries like BeautifulSoup(BS4), Selenium, and a chromium driver. This setup is essential for tasks like scraping Twitter with Selenium.
Installation
For installing BeautifulSoup use the below-given command.
pip install beautifulsoup4
Selenium use the below-given command.
pip install selenium
Selenium is a popular web scraping tool for automating web browsers. It is often used to interact with dynamic websites, where the content of the website changes based on user interactions or other events.
Whereas BS4 will help us parse the data from the raw HTML we are going to download using Selenium
Remember that you will need the exact version of the Chromium driver as your Chrome browser. Otherwise, it will not run.
Testing the setup
Just to make sure everything works fine, we are going to set up our Python script and test it by downloading data from this page.
from bs4 import BeautifulSoup
from selenium import webdriver
import time
PATH = 'C:\Program Files (x86)\chromedriver.exe'
target_url = "https://twitter.com/scrapingdog"
driver=webdriver.Chrome(PATH)
driver.get(target_url)
time.sleep(5)
resp = driver.page_source
driver.close()
print(resp)
Let me explain step by step what each line means.
- The first three lines import the necessary libraries:
BeautifulSoupfor parsing HTML and XML,Seleniumfor automating web browsers, andtimefor setting a delay. - The fourth line sets the path to the chromedriver executable. This is the location where your Chrome driver is installed.
- Then the fifth line sets the target URL to the Scrapingdog Twitter page that we want to scrape.
- The sixth line creates a new instance of the ChromeDriver using the path specified in the
PATHvariable. - Then using
.get()method of the Selenium browser will navigate to the target page. - The next line sets a delay of 5 seconds to allow the page to fully load before continuing with the script.
- Using
.page_sourcefunction we get the HTML content of the current page and store it in therespvariable. - Then using
.close()method we are closing down the browser window. This step will save your server from crashing if you are going to make multiple requests at a time. - The last line prints the HTML content of the page to the console.
Once you run this code you will get raw HTML on the console. This test ensures our setup is ready for scraping Twitter with Beautiful Soup and Selenium.

What exactly are we going to extract from a Twitter page?
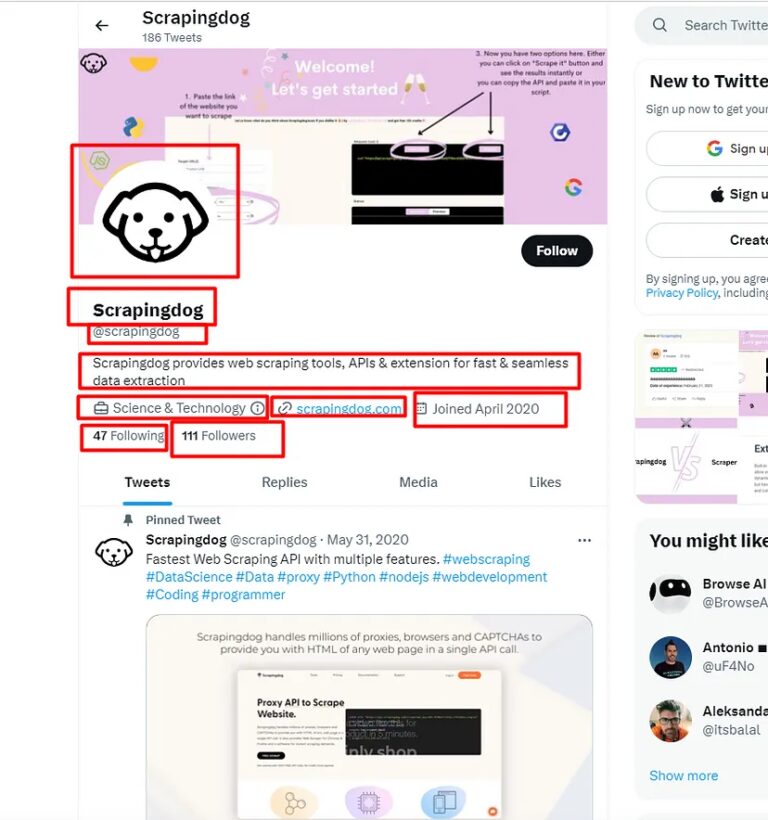
-
- Profile Name
- Profile Handle
- Profile Description
- Profile Category
- Website URL
- Joining date
- Number of Followers
- Following Count
Let’s start scraping Twitter
Continuing with the above code, we will first find the locations of each element and then extract them with the help of BS4. We will use .find() and .find_all() methods provided by the BS4. If you want to learn more about BS4 then you should refer to BeautifulSoup Tutorial.
First, let’s start by finding the position of the profile name.
Extracting Profile name
As usual, we have to take support of our Chrome developer tools over here. We have to inspect the element and then find the exact location.
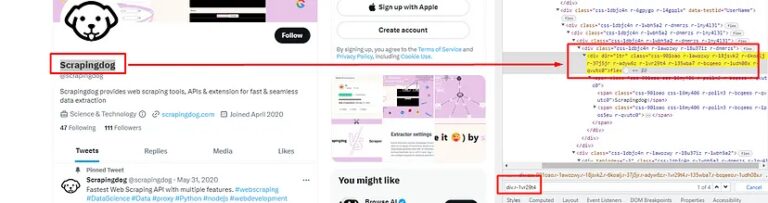
div tag and class r-1vr29t4 but the name of the profile is the first one on the list. As you know .find() function of BS4 is a method used to search for and retrieve the first occurrence of a specific HTML element within a parsed document.
With the help of this, we can extract the name of the profile very easily.
l=list()
o={}
soup=BeautifulSoup(resp,'html.parser')
try:
o["profile_name"]=soup.find("div",{"class":"r-1vr29t4"}).text
except:
o["profile_name"]=None
- Here we have declared one empty list l and one empty object o.
- Then we created a BeautifulSoup object. The resulting
soupthe object is an instance of theBeautifulSoupclass, which provides several methods for searching and manipulating the parsed HTML document - Then using
.find()method we are extracting the text.
Nothing complicated as of now. Pretty straightforward.
Extracting profile handle
For extracting the profile handle we are going to use the same technique we just used above while extracting the name.
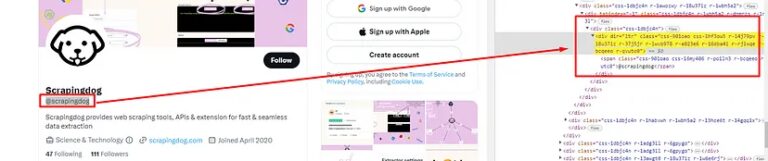
div tag with class r-1wvb978. But again there are almost 10 elements with the same tag and class.
Once you will search for this class in the Chrome developer tool you will find that the element where the handle is stored is first in the list of those 10 elements. So, using .find() method we can extract the first occurrence of the HTML element. 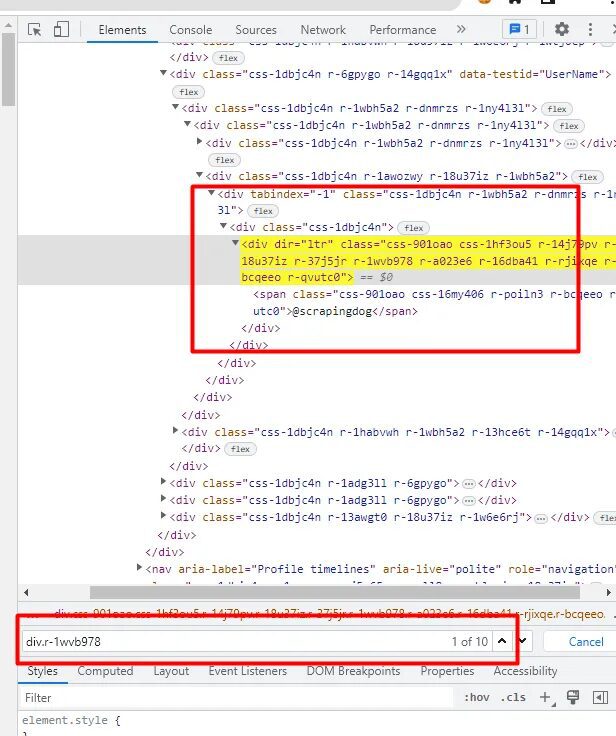
try:
o["profile_handle"]=soup.find("div",{"class":"r-1wvb978"}).text
except:
o["profile_handle"]=None
With this code, we can easily scrape the handle name.
Extracting Profile Bio
This one is pretty simple.

try:
o["profile_bio"]=soup.find("div",{"data-testid":"UserDescription"}).text
except:
o["profile_bio"]=None
Extracting Profile Category, website link, and joining date
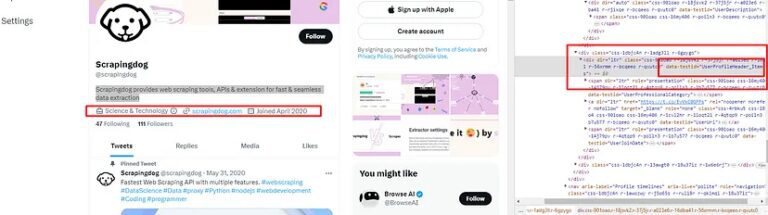
As you can see all the there data elements are stored inside this div tag with attribute data-testid and value UserProfileHeader_Items. So, our first job would be to find this.
profile_header = soup.find("div",{"data-testid":"UserProfileHeader_Items"})
Now you will notice that the profile category is stored inside a span tag with attribute data-testid and value UserProfessionalCategory.
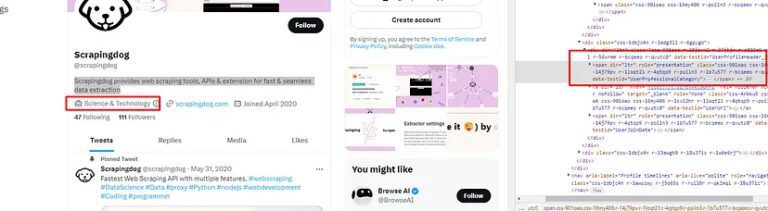
We can use .find() method on the element profile_header to search for this element.
try:
o["profile_category"]=profile_header.find("span",{"data-testid":"UserProfessionalCategory"}).text
except:
o["profile_category"]=None
Similarly, you can see that the website link is stored inside a a tag. So, I just have to find the a tag inside profile_header.
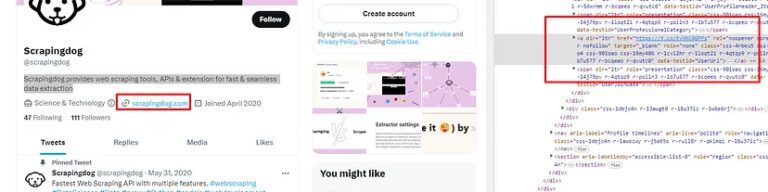
try:
o["profile_website"]=profile_header.find('a').get('href')
except:
o["profile_website"]=None
I have used .get() method of BS4 to retrieve the value of an attribute from a tag object.
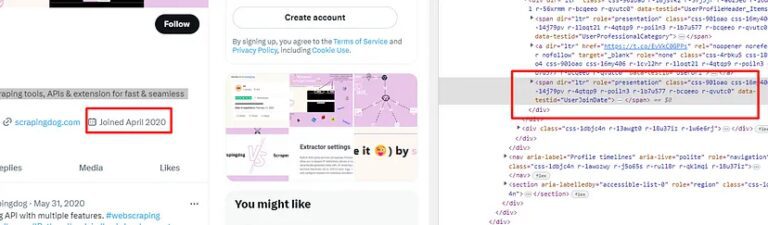
The joining date can also be found inside profile_header with span tag and attribute data-testid and value as UserJoinDate.
try:
o["profile_joining_date"]=profile_header.find("span",{"data-testid":"UserJoinDate"}).text
except:
o["profile_joining_date"]=None
Extracting following and followers count
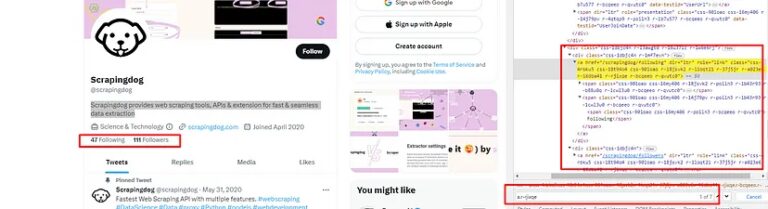
The following and followers elements can be found under a tag with class r-rjixqe. You will find seven such elements. I have even highlighted that in the above image. But following count and followers count are the first two elements. So, all we have to do is use .find_all() method of BS4. Remember .find_all() will always return a list of elements matching the given criteria.
try:
o["profile_following"]=soup.find_all("a",{"class":"r-rjixqe"})[0].text
except:
o["profile_following"]=None
try:
o["profile_followers"]=soup.find_all("a",{"class":"r-rjixqe"})[1].text
except:
o["profile_followers"]=None
I have used 0 for the following count because it is the first one on the list and 1 for followers because it is the second one on the list.
With this, our process of scraping Twitter and extracting multiple data points is over.
Complete Code
You can of course extract more data like tweets, profile pictures, etc. But the complete code for all the information we have scraped in this tutorial will look like this.
from bs4 import BeautifulSoup
from selenium import webdriver
import time
PATH = 'C:\Program Files (x86)\chromedriver.exe'
l=list()
o={}
target_url = "https://twitter.com/scrapingdog"
driver=webdriver.Chrome(PATH)
driver.get(target_url)
time.sleep(2)
resp = driver.page_source
driver.close()
soup=BeautifulSoup(resp,'html.parser')
try:
o["profile_name"]=soup.find("div",{"class":"r-1vr29t4"}).text
except:
o["profile_name"]=None
try:
o["profile_handle"]=soup.find("div",{"class":"r-1wvb978"}).text
except:
o["profile_handle"]=None
try:
o["profile_bio"]=soup.find("div",{"data-testid":"UserDescription"}).text
except:
o["profile_bio"]=None
profile_header = soup.find("div",{"data-testid":"UserProfileHeader_Items"})
try:
o["profile_category"]=profile_header.find("span",{"data-testid":"UserProfessionalCategory"}).text
except:
o["profile_category"]=None
try:
o["profile_website"]=profile_header.find('a').get('href')
except:
o["profile_website"]=None
try:
o["profile_joining_date"]=profile_header.find("span",{"data-testid":"UserJoinDate"}).text
except:
o["profile_joining_date"]=None
try:
o["profile_following"]=soup.find_all("a",{"class":"r-rjixqe"})[0].text
except:
o["profile_following"]=None
try:
o["profile_followers"]=soup.find_all("a",{"class":"r-rjixqe"})[1].text
except:
o["profile_followers"]=None
l.append(o)
print(l)
Using Scrapingdog for scraping Twitter
The advantages of using Scrapingdog Twitter Scraper API are:
- You won’t have to manage headers anymore.
- Every request will go through a new IP. This keeps your IP anonymous.,
- Our API will automatically retry on its own if the first hit fails.
Scrapingdog uses residential proxies to scrape Twitter. This increases the success rate of scraping Twitter or any other such website.

Once you sign up, you will be redirected to your dashboard. The dashboard will look somewhat like this.
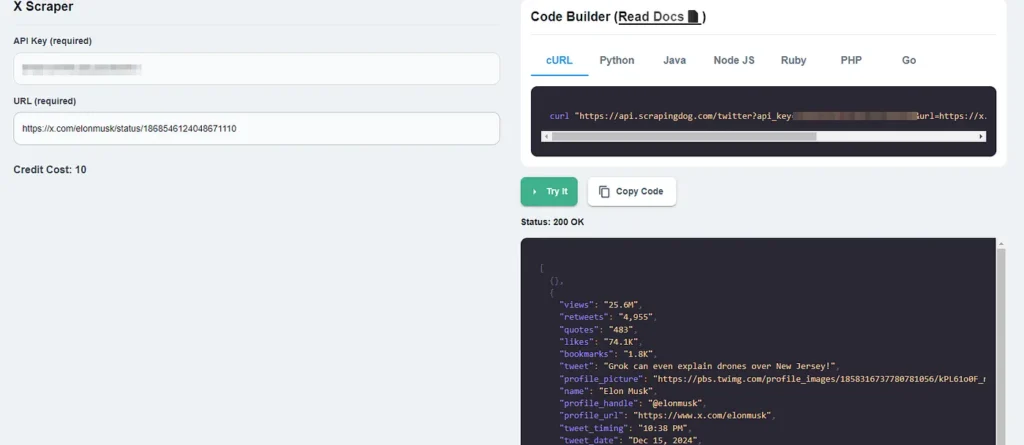
In the above screenshot, I have scraped this tweet from Elon Musk. Let’s do the same with simple Python code. By the way, you can just copy the code from the dashboard itself and run it in your working environment.
import requests
api_key = "Your-API-Key"
url = "https://api.scrapingdog.com/twitter"
params = {
"api_key": api_key,
"url": "https://x.com/elonmusk/status/1868546124048671110",
"parsed": true
}
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
print(data)
else:
print(f"Request failed with status code: {response.status_code}")
Once you run this code you get a beautiful JSON response that contains the tweet text, views, likes, shares, comments, etc.
I have prepared a quick video demo tutorial too ⬇️
Conclusion
In this article, we managed to scrape certain Twitter profile data. With the same scraping technique, you can scrape publicly available tweets and profile information from Twitter.
You can take advantage of some Twitter Python libraries with which you can scrape any tweet in normal text. You won’t even have to parse the data.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on your social media.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:
Web Scraping with Scrapingdog



