
Today many websites cannot be scraped with a normal XHR request because they render data through Javascript execution.
Traditional web scraping libraries like requests and Scrapy are excellent for extracting data from websites where the content is directly embedded in the HTML of the page.
However, a growing number of modern websites use JavaScript to dynamically load and render content.
So, when you make a simple HTTP request (like an XHR request) using requests or similar libraries, you get the initial HTML, but it might lack the dynamically loaded content.
Headless browsers or browser automation tools can help. These tools simulate a browser environment and can execute JavaScript on a page.
In this tutorial, we will learn how to scrape dynamic websites using Selenium and Python. For this tutorial, we are going to scrape myntra.com.
Requirements
I am assuming that you already have Python 3.x installed on your machine. If not then you can install it from here. Let’s start with creating a folder in which we are going to keep our Python script.
mkdir seleniumtut
Then after creating the folder, we have to install two libraries that will be needed in the course of this tutorial.
- Selenium– It is used to automate web browser interaction from Python.
- Beautiful Soup is a Python library for parsing data from the raw HTML downloaded using Selenium.
- Chromium– It is a web browser that will be controlled through selenium. You can download it from here.
pip install bs4
pip install selenium
Remember that you will need the exact version of the Chromium driver as your Chrome browser. Otherwise, it will not run and throw an error.
Now, create a Python file where we can write our code. I am naming the file as tutorial.py.
What are we going to scrape?
For this tutorial, we are going to scrape this page.
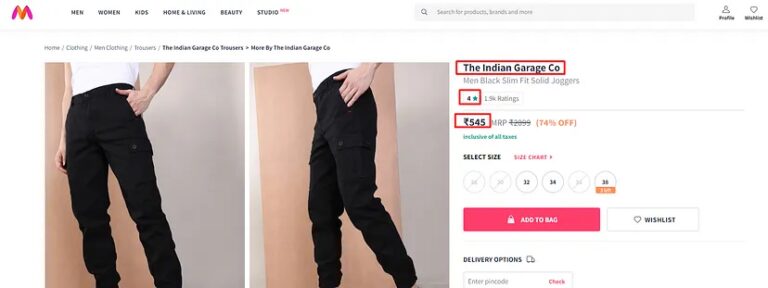
We are going to scrape three data points from this page.
- Name of the product
- Price of the product
- Rating of the product
First, we will download the raw HTML from this page using selenium, and then using BS4 we are going to parse the required data.
Downloading the data with Selenium
First step would be import all the required libries inside our file tutorial.py
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
Here we first imported the BeautifuSoup, webddriver module from selenium and the Service class from selenium
PATH = 'C:\Program Files (x86)\chromedriver.exe'
service = Service(executable_path=PATH)
options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=service, options=options)
The executable_path parameter is used to provide the path to the ChromeDriver executable on your system. This is necessary for Selenium to locate and use the ChromeDriver executable.
webdriver.ChromeOptions is a class in Selenium that provides a way to customize and configure the behavior of the Chrome browser.
webdriver.Chrome is a class in Selenium that represents the Chrome browser. The service parameter is used to specify the ChromeDriver service, which includes the path to the ChromeDriver executable.
The options parameter allows you to provide the ChromeOptions instance created earlier, customizing the behavior of the Chrome browser according to your needs.
driver.get("https://www.myntra.com/trousers/the+indian+garage+co/the-indian-garage-co-men-black-slim-fit-solid-joggers/9922235/buy")
html_content = driver.page_source
print(html_content)
# Close the browser
driver.quit()
The get method is used to navigate the browser to a specific URL, in this case, the URL of a Myntra product page for trousers.
driver.page_source is a property of the WebDriver that returns the HTML source code of the current page. After this step we are printing the result on the console.
driver.quit() closes the browser, ending the WebDriver session.
Once you run this code you will get this on your console.
Parsing the data with BS4
Since we have already decided what we are going to extract from this raw data let’s find out the DOM location of each of these data points.
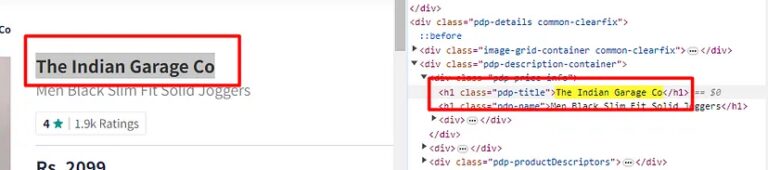
The title of the product is located inside the h1 tag with class pdp-title.
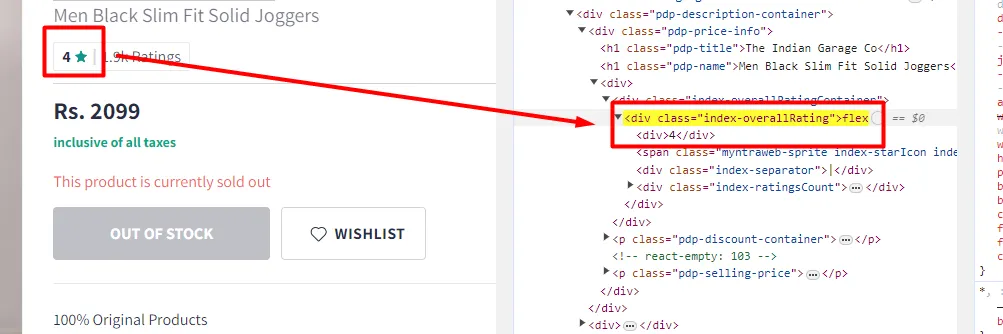
The rating is located inside the first div tag of the parent div with the class index-overallRating.
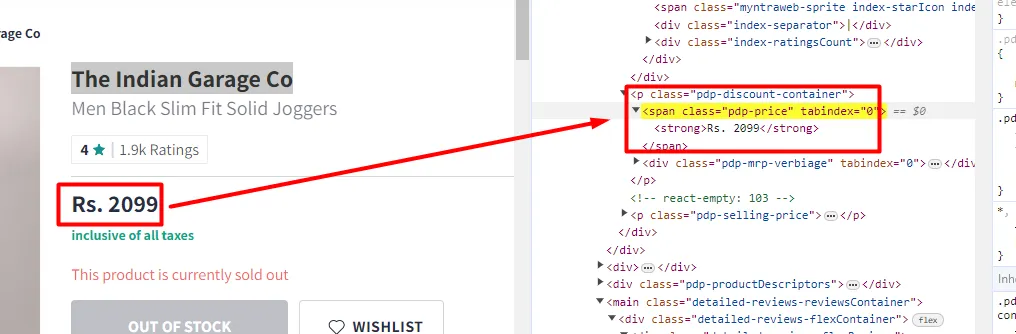
Similarly, you can see that the pricing text is located inside the span tag with class pdp-price.
We can now implement this into our code using BS4.
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
l=[]
o={}
PATH = 'C:\Program Files (x86)\chromedriver.exe'
# Set up the Selenium WebDriver
service = Service(executable_path=PATH)
options = webdriver.ChromeOptions()
# options.add_argument("--headless")
driver = webdriver.Chrome(service=service, options=options)
# Navigate to the home page
driver.get("https://www.myntra.com/trousers/the+indian+garage+co/the-indian-garage-co-men-black-slim-fit-solid-joggers/9922235/buy")
html_content = driver.page_source
soup=BeautifulSoup(html_content,'html.parser')
try:
o["title"]=soup.find('h1',{'class':'pdp-title'}).text.lstrip().rstrip()
except:
o["title"]=None
try:
o["rating"]=soup.find('div',{'class':'index-overallRating'}).find('div').text.lstrip().rstrip()
except:
o["rating"]=None
try:
o["price"]=soup.find('span',{'class':'pdp-price'}).text.lstrip().rstrip()
except:
o["price"]=None
l.append(o)
print(l)
# Close the browser
driver.quit()
soup = BeautifulSoup(html_content, ‘html.parser’) initializes a BeautifulSoup object (soup) by parsing the HTML content (html_content) using the HTML parser.
o[“title”] = soup.find(‘h1’, {‘class’: ‘pdp-title’}).text.lstrip().rstrip()finds an<h1>element with the class ‘pdp-title’ and extracts its text content after stripping leading and trailing whitespace. If not found, sets ‘title’ toNone.o[“rating”] = soup.find(‘div’, {‘class’: ‘index-overallRating’}).find(‘div’).text.lstrip().rstrip()finds a<div>element with the class ‘index-overallRating’, then finds another<div>inside it and extracts its text content. If not found, sets ‘rating’ toNone.o[“price”] = soup.find(‘span’, {‘class’: ‘pdp-price’}).text.lstrip().rstrip()finds a<span>element with the class ‘pdp-price’ and extracts its text content after stripping leading and trailing whitespace. If not found, sets ‘price’ toNone.
At the end, we pushed the complete object o to the list l using .append() method.
Once you run the code you will get this output.
At the end, we pushed the complete object o to the list l using .append() method.
Once you run the code you will get this output.
[{'title': 'The Indian Garage Co', 'rating': '4', 'price': '₹545'}]
Complete Code
You can of course extract many other data points from this page by finding the location of those elements. But for now, to keep the article concise the code looks like this.
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
l=[]
o={}
PATH = 'C:\Program Files (x86)\chromedriver.exe'
# Set up the Selenium WebDriver
service = Service(executable_path=PATH)
options = webdriver.ChromeOptions()
# options.add_argument("--headless")
driver = webdriver.Chrome(service=service, options=options)
# Navigate to the home page
driver.get("https://www.myntra.com/trousers/the+indian+garage+co/the-indian-garage-co-men-black-slim-fit-solid-joggers/9922235/buy")
html_content = driver.page_source
soup=BeautifulSoup(html_content,'html.parser')
try:
o["title"]=soup.find('h1',{'class':'pdp-title'}).text.lstrip().rstrip()
except:
o["title"]=None
try:
o["rating"]=soup.find('div',{'class':'index-overallRating'}).find('div').text.lstrip().rstrip()
except:
o["rating"]=None
try:
o["price"]=soup.find('span',{'class':'pdp-price'}).text.lstrip().rstrip()
except:
o["price"]=None
l.append(o)
print(l)
# Close the browser
driver.quit()
Conclusion
In this article, we learn how we can easily scrape JS-enabled websites using Selenium.
- Selenium is highlighted for its capability to automate browser interactions seamlessly.
- The focus was to parse HTML with elegance using Selenium to extract valuable insights.
- The scope of insights includes a wide range, from product details to user ratings.
- Overall, the article demonstrates how Selenium can be a powerful tool for web scraping tasks involving dynamic content and JavaScript execution.
- Some websites may force you to use a web scraping API for heavy scraping. Web Scraping APIs will take your headless browser and proxy management part on an autopilot mode and you will just have to focus on data collection.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on social media.
Web Scraping with Scrapingdog



