


In a similar manner, we will extract the address.

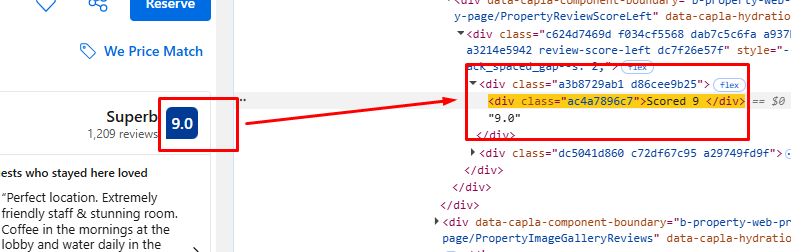
Once again we will inspect and find the DOM location of the rating and facilities element.
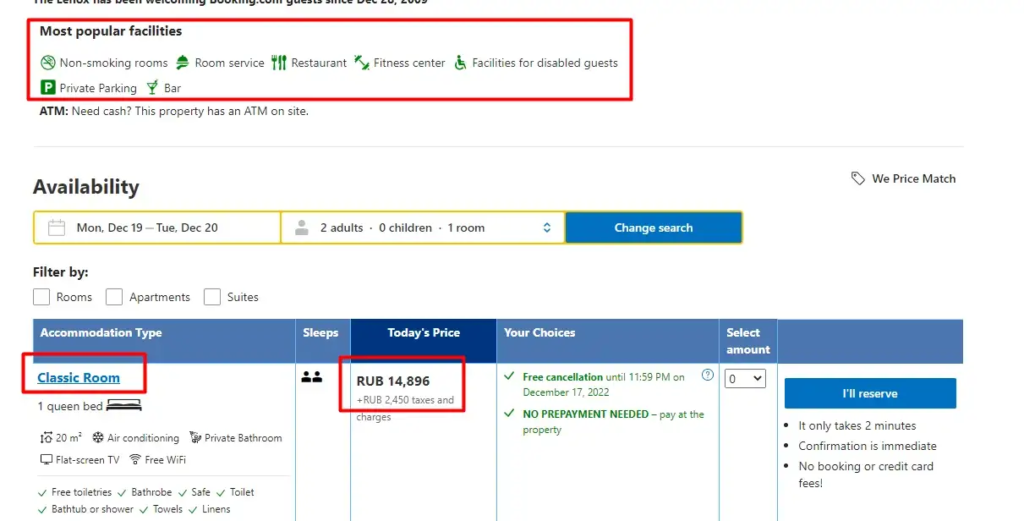
Extracting facilities is a bit tricky. We will create a list in which we will store all the facilities HTML elements. After that, we will run a for loop to iterate over all the elements and store individual text in the main array.

This is the trickiest part of the entire tutorial. Booking.com’s DOM structure is quite intricate and requires careful inspection before you can reliably extract price and room type details.
The <tbody> tag contains all the relevant data. Inside it, each <tr> tag represents a row and holds all the information for a single listing or item, typically starting from the first column.

Next, as you dive deeper into the DOM, you’ll encounter multiple <td> tags within each <tr>. These <td> tags contain essential details like room type, pricing, taxes, and other booking information.
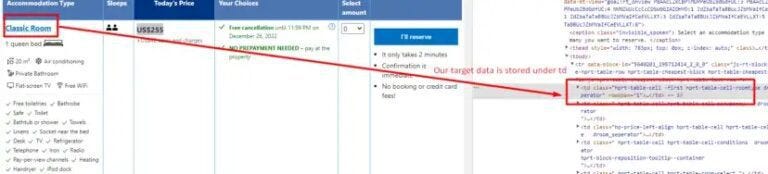
First, let’s find all the tr tags.
allData variable will store all the HTML data for a particular data-block-id.
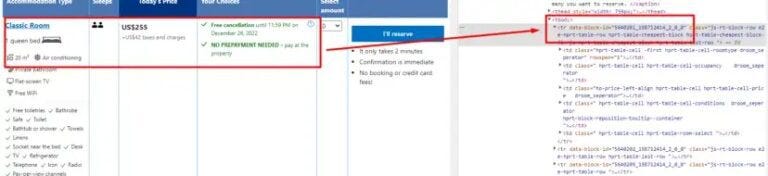
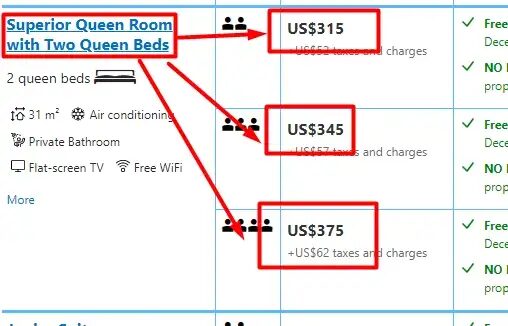
Here last_room will store the last value of rooms until we receive a new value.
Let’s extract the price now.
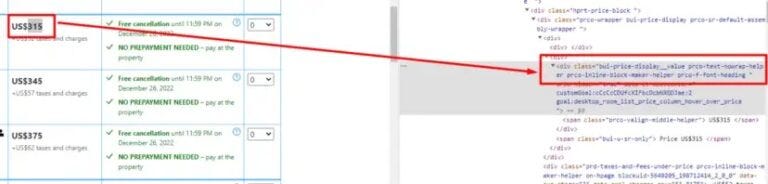
Keep in mind, that this technique is good for small-scale scraping — perhaps a few hundred requests. However, once you cross that threshold, Booking.com will likely detect the pattern and block further requests due to IP bans.
The first step would be to sign up for the free pack. The free pack will provide you with 1000 API credits.

Click on General Scraper and enter your target booking.com link. This step will create a ready Python snippet on the right.
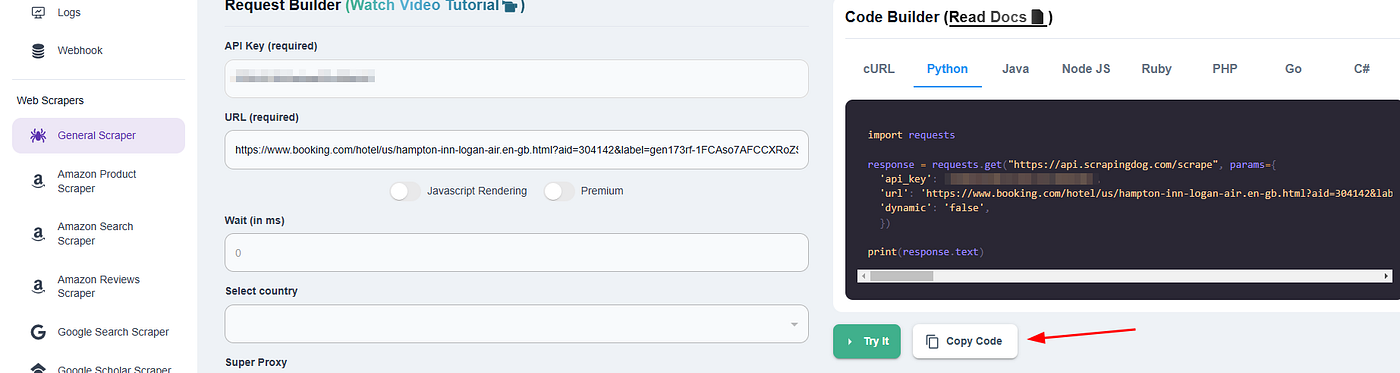
Now just copy this Python code and paste it into your working environment. Of course, your parsing code will remain the same as earlier.


