
In this post, we are going to learn the concept of Xpath Python for scraping web pages. I will also show you some special conditions in which we might actually need this particular concept because it might help us save a lot of effort and time.
So, this is what we are going to do in this particular tutorial. Let’s get started without any delay.
What is Xpath
Let’s talk a bit about Xpath first. So, Xpath stands for XML path language which is actually a query language for selecting nodes from an XML document.
Now, if you do not know about XML documents then this article covers everything for you. XML stands for Extensible Markup Language which is a bit like your hypertext markup language which is HTML but there is a very distinct difference between the two.
HTML has a predefined set of tags that have a special meaning for example you have a body tag or you have a head tag or a paragraph tag. So, all these tags have a special meaning to your browser, right? But for XML there is no such thing.
In fact, you can give any name to your tags and they do not have any special meaning there. So, the design goal of XML documents is that they emphasize simplicity, generality, and usability across the internet.
That’s why you can use any name for your tags and nowadays XML is generally used for the transfer of data from one web service to another. So, that is another main use of XML.
Coming back to Xpath, well it is a query language for XML documents and the special thing to note here is that it is used for selecting nodes.
Now, you might be thinking what are these nodes or this node terminal, right? Well, you can think of any XML document or even any HTML document like a tree.
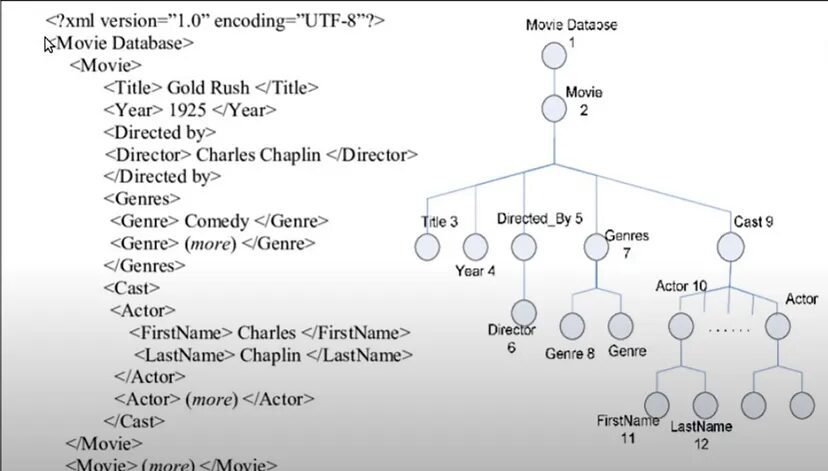
Now, why I am saying that is because if you try to see this particular XML document you have a tag called “Movie Database” in which you have multiple movie tags then in each movie you have a title tag, year tag, directed by tag, and so on.
So, in this way, we are creating a nested structure, and if you try to visualize a tree we can. We have a movie database tag in which we can have multiple movies in each movie we have a title, year, etc. Similarly, in the cast tag we have actors with different tags for first name and last name.
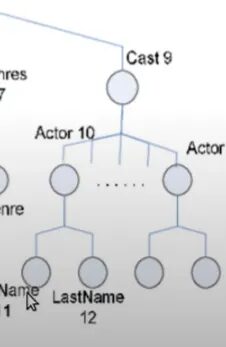
So, this nesting of the tags allows you to visualize the XML or HTML documents like trees. That’s why we have the concept of nodes in the trees. So, all these tag elements are the nodes of your tree. Similarly, HTML can be visualized and then parsed like a tree.
For parsing, we can use libraries like Beautifulsoup. So, HTML documents or XML documents can be visualized like a tree, and XML parts in a text can be used for querying and selecting some particular nodes that follow the pattern specified by the XPath syntax to select some particular nodes.
This is the concept behind Xpath and now let me show you some examples so that we can understand Xpath syntax a bit.
Example
We are not going to go into much detail about the Xpath syntax itself because in this video our main aim is to learn how to use Xpath for web scraping.

So, let’s say I have an XML document in which this is the code. I have a bookstore tag at the root in which I have multiple book tags and inside that, I have title and price tags. You can find this Xpath tester on this website. This is where I am testing this XML and Xpath expression.
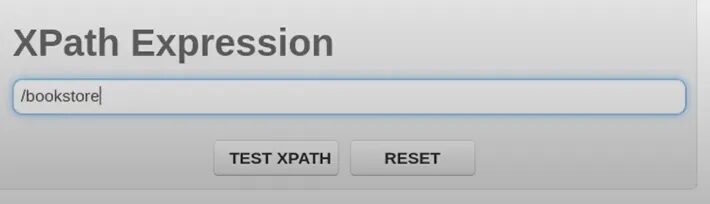
Now, if I type “/” in that then it means I want to search from the root of your tree and I will write bookstore. So, what it will do is it will search from the root for the bookstore. So, now if I click TEST XPATH I will get this.

This is the complete bookstore. Now, let’s say in the bookstore I want to get all the books that we have. So, for that, you will do this.

And then I will get this result. I got all the books inside the bookstore.
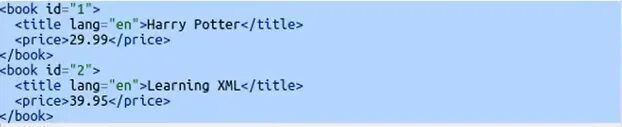
Now, let’s say you want to get only that book whose ID is 2. So, you will just put a square bracket, and inside that, you will pass ‘@id=”2”’.

When you use @ with some attribute then you are referring to a particular attribute inside your book tag in this case and you are saying hey! find all those book tags whose ID is 2. When we run it we get this.

Look at this, we are getting only that book whose ID is 2. Now, let’s say I want to get the price of that book whose ID is 2. For that, I will simply do this.

And in response, I get this.
So, this is how Xpath works. Now, if you want to learn more about Xpath syntax then you can just visit w3schools for more details. Other than that this is all we need to know in order to create a web scraper using it.
Why Learn Xpath
XPath is a crucial skill when it comes to extracting data from web pages. It is more versatile than CSS selectors, as it allows for referencing parent elements, navigating the DOM in any direction, and matching text within HTML elements.
While entire books have been written on the subject, this article serves as an introduction to XPath and provides practical examples for using it in web scraping projects.
Let’s Web Scrape with Xpath
For example purposes only I am going to go with this webpage which is a Wikipedia page. I was going through this page a few hours ago when I thought of using it for showing you the Xpath demo.
So, on this page, there is a table of feature films from the Marvel Cinematic Universe.
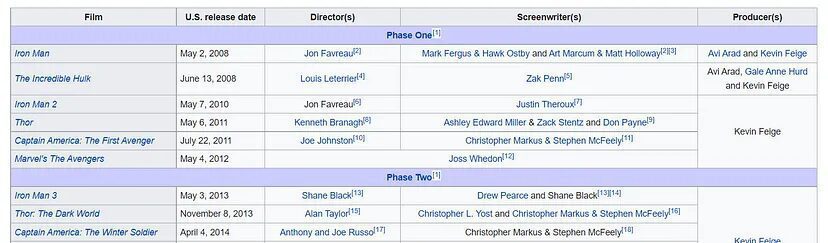
So, our target is to get the list of all the links to the Wikipedia page of these films. As you can see in the first column, there is a list of all the films. For Iron Man, it is actually a link to the Wikipedia page of Iron Man 2008.
So, I want this link. Similarly, I want to get the links to The Incredible Hulk, Thor, etc. Basically, I need all the links available in the first column only.
Now, I know I can use BeautifulSoup for that, right? But there is an even more compact and easier way to do the same thing by using the concept of Xpath.
Let’s start by inspecting elements. You can open it by Ctrl+Shift+I on our target Wikipedia web page. Once done you will have to go to the target element. Our target element is Iron Man and when I inspect it I get this.

On the right, you can see the HTML code of our target element. Now, I want to search for this element in my complete HTML tree. So, for that, you need to right-click on the HTML code and then go to copy and then copy Xpath.
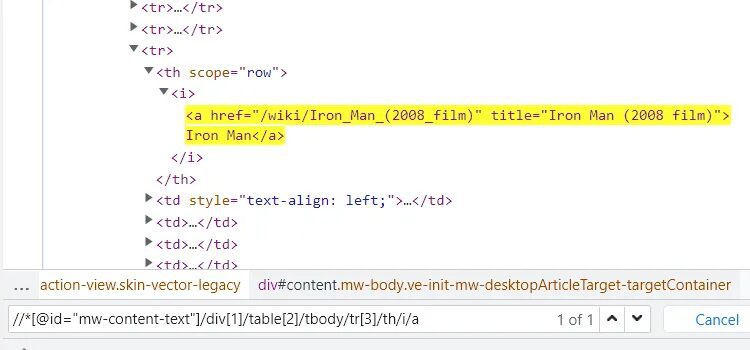
We have copied the Xpath of our target element. This is the Xpath of our target element Iron man — //*[@id=”mw-content-text”]/div[1]/table[2]/tbody/tr[3]/th/i/a
Let me explain this Xpath to you.
- Double slash means that you do not want to start from the root node, you want to start from any particular position in the tree.
- * means find any tag whose ID is mw-content-text and in that tag go to the first div then go to its second table body because we have used 2 over there inside the brackets.
- After entering the table go inside the third row of that table then go to its th and then to i and then finally a
You can even confirm this in the above image. So, this is the complete Xpath syntax that we have here for that particular element.
The Xpath is unique for each element in your tree. So, now I want to find all such elements. For that, we will search for a generic Xpath. Let us first see how we can search by Xpath on the chrome inspector. By pressing ctrl+F you will get an input field where you can search for any Xpath. So, let me just paste my Xpath here and see what happens.
This is what I get when I paste my Xpath. Now, let me replace tr[3] the third row with the fourth-row tr[4], and then see what happens.
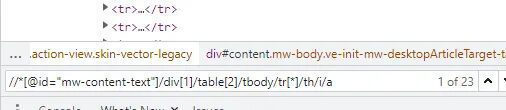
Now, we are getting The Incredible Hulk. So, this row number is our variable. Similarly, if I place 5 inside tr[5] then we will get Iron Man 2 and this will continue until the last film in the column. In this way, we are getting all the elements that we actually need if we just keep on changing the index value of the tr row.
Now, let me show you the power of XPath. We can just replace this index integer with an asterisk *and this will accept any value. Since it can accept any value then we can extract all our values from our target elements.

As you can see we are getting 23 such elements. You can go through all of them one by one by just clicking a downward button. Finally, we have managed to create a single search expression or a generic expression which is giving me 23 search results and all of them are from the first column of the table. This Xpath query can find any element in one go.
This is the power of Xpath which can be used for searching particular patterns inside the HTML. This is wherein Xpath comes in handy when you have a special pattern of different elements in your HTML document then you can think of using the Xpath instead of using the old BeautifulSoup.
I said old BeautifulSoup because it does not support the concept of Xpath. So, we will have to use something different.
Now, let’s see how we can use Xpath with Python for web scraping.
Xpath with Python
We will use lxml library to create a web scraper because as I said earlier beautifulSoup does not support Xpath. It is a third-party library that can help you to pass HTML documents or any kind of XML document and then you can search any node in it using the Xpath syntax. Let’s begin!
First, create a folder and install this library
mkdir scraper
pip install lxml
Once that is done, create a scraper.py file inside your folder scraper and start coding with me.
from lxml import html
import requests
We have imported the requests library to request because we have to get the HTML data of that web page as well.
url=”https://en.wikipedia.org/wiki/Outline_of_the_Marvel_Cinematic_Universe”
and then we will send an HTTP request to our URL.
resp = requests.get(url)
print(resp)
Now, if you will run it you will get 200 code which means we have successfully scraped our target URL.
Now, let’s create a parse tree for our HTML document.
tree = html.fromstring(resp.content)
html.fromstring is a function that takes your HTML content and creates a tree out of it and it will return you the root of that tree. Now, if you print the tree you will get this <Element html at 0x1e18439ff10>. So, it says we have got html elements at some position and as you know html tag is the root of any HTML document.
Now, I want to search certain elements using Xpath. We have already discovered the Xpath earlier in this article. Our Xpath is //*[@id=”mw-content-text”]/div[1]/table[2]/tbody/tr[*]/th/i/a
elements = tree.xpath(‘//*[@id=”mw-content-text”]/div[1]/table[2]/tbody/tr[*]/th/i/a’)
We have passed our Xpath inside the tree function. Do remember to use single or triple quotes while pasting your Xpath because Python will give you an error for double quotes because our Xpath already has them.
Let’s print and run it and see what happens.
On running the code we get all the elements which are matching with this particular Xpath. Due to *, we are getting all the available elements within that column. Now, if you will try to print the 0th element.
elements[0]
you will get this <Element a at 0x1eaed41c220>. As, you can see it is an anchor tag. Now, to get the data this tag contains we have two options.
- .text will return the text the contains. Like elements[0].text will return Iron Man
- .attrib will return a dictionary {‘href’: ‘/wiki/Iron_Man_(2008_film)’, ‘title’: ‘Iron Man (2008 film)’}. This will provide you with the href tag which is actually the link and that is what we need. We also get the title of the movie.
But since we only need href tag value so we will do this
elements[0].attrib[‘href’]
This will return the target link.
This is what we wanted. Now, let us collect all the href tags for all the movies.
base_url = “https://en.wikipedia.org”
links = [base_url + element.atrrib[‘href’] for element in elements]
This is a very simple list comprehension code that we have written and yes that’s it. Let us run it.

We have got all the links to all the Wikipedia pages of all the movies from the Marvel Cinematic Universe. This was our ultimate aim for this tutorial and we have successfully managed to complete the task in a very efficient manner.
Complete Code
from lxml import html
import requests
url=”https://en.wikipedia.org/wiki/Outline_of_the_Marvel_Cinematic_Universe"
resp= requests.get(url)
tree = html.fromstring(resp.content)
elements = tree.xpath(‘//*[@id=”mw-content-text”]/div[1]/table[2]/tbody/tr[*]/th/i/a’)
base_url = “https://en.wikipedia.org"
links = [base_url + element.attrib[‘href’] for element in elements]
print(links)
Conclusion
I hope now you have got the idea of how you can use the concept of XML and the Xpath for web scraping and how it can help you to extract data where a certain pattern can be seen. After analyzing that pattern you can create a compact Xpath query for yourself and I am pretty confident that you will be able to scrape the data in a very less amount of code. You may choose to build on this knowledge and create complex web scrapers that can crawl thousands of pages.
If you don’t want to code your own scraper then you can always use our API for Web Scraping.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:
Web Scraping with Scrapingdog



