
C# Web scraping could be a go-to choice since the language offers a wide range of tools. In this tutorial, we will use this programming language with Selenium. We will be designing a simple web scraper in part 1 and in part 2 we will scrape a dynamic website.
Web Scraping with Selenium (Part-I)
I am going to explain everything with a very simple step-by-step approach. So, first of all, I am going to create a new project.
I have created a demo project by the name of web scraping then we will install the Selenium library. We can do this by clicking the Tools tab and then the NuGet package manager.
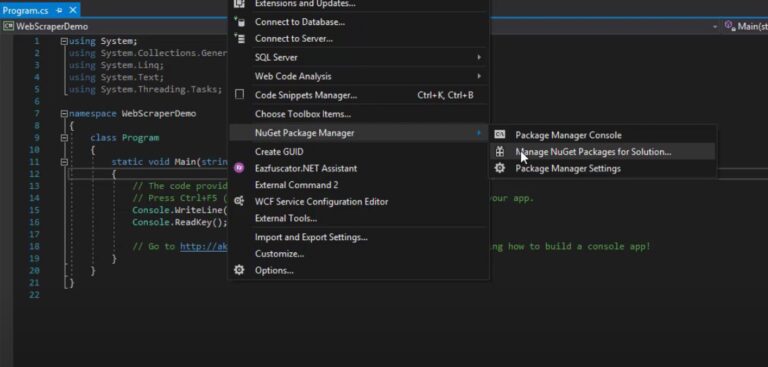
Then you can search for selenium and then I will pick the solution and install it.
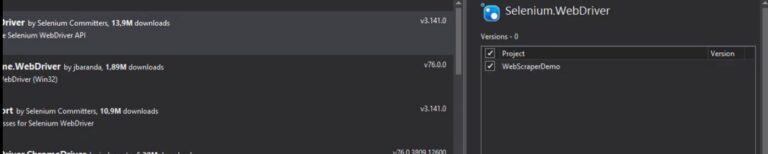
Now, we also need to download the web driver which you can download from here.
Now, I am going to put it inside the bin folder so that I don’t have to specify a path within the code. I am going to open the folder in File Explorer
bin > debug
And then you can just drag the chromedriver file to the debug folder. We are done with the installation. Now, we will start coding the scraper.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
IWebDriver driver = new ChromeDriver();
}
}
}
When you want to make a controllable browser you just have to create an instance of this webdriver and since I am using the chrome web driver I am going to make a chrome fiber and I am just going to import all the packages.
If I run this code it will open a new browser. For this post, we are going to make a Google search scraper.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
IWebDriver driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.google.com")
}
}
}
Now, here we are navigating our page to the Google home page.
Our scraper will scrape all those titles, descriptions, links, etc. So, to do that, we have to make it a search.
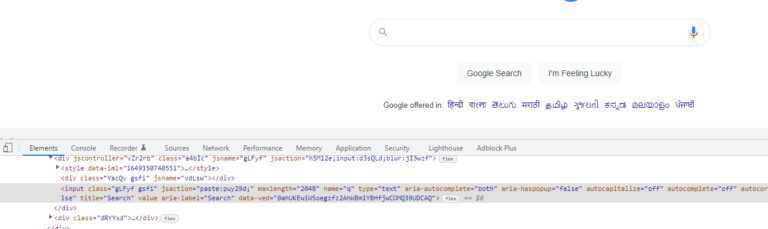
There are many ways by which you can detect this input field like class name, id, or even XPath. Here we are going to use the XPath.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
IWebDriver driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.google.com")
var element = driver.findElement(By.XPath("/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input"));
}
}
}
Then we have to type a keyword in that input field in order to make some Google searches. We are going to use the SendKeys function for that. Then we are going to submit the query using Submit function.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
IWebDriver driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.google.com")
var element = driver.findElement(By.XPath("/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input"));
element.SendKeys("webshop")
element.Submit();
}
}
}
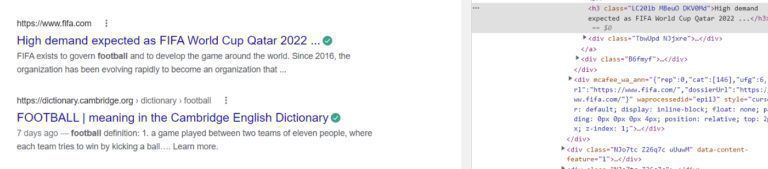
When we visit the above page we can do the same thing that we did with the input field, find some random element, and copy the XPath. Now, the problem in doing this is when you do it using XPath it will be for a very specific element and it might not apply to other elements.
Now, if you notice the XPath of two random titles, then you will find out that they are in a sequence and we can use a for loop to scrape those titles.
XPath1 — //*[@id=”rso”]/div[9]/div/div[1]/div[1]/a/h3 XPath2 — //*[@id=”rso”]/div[10]/div/div[1]/div[1]/a/h3
So, now we can do something like this to find the elements using those XPaths.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
IWebDriver driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.google.com")
var element = driver.findElement(By.XPath("/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input"));
element.SendKeys("webshop")
element.Submit();
var titles = driver.FindElements(By.XPath("//*[@id=”rso”]/div[1]/div/div[1]/div[1]/a/h3"))
}
}
}
Now, we can loop through these elements and each one of these will be contained within this collection of elements.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
IWebDriver driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.google.com")
var element = driver.findElement(By.XPath("/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input"));
element.SendKeys("webshop")
element.Submit();
var titles = driver.FindElements(By.XPath("//*[@id=”rso”]/div[1]/div/div[1]/div[1]/a/h3"))
foreach(var title in titles)
{
Console.WriteLine(title.Text)
}
}
}
}
When we run this we get this.
As you can notice we have managed to scrape all the titles and it has ignored the ads. This is one way you can do it. I did it using XPath but you can also do it using class names. Let’s try it with the class name as well.
When you inspect any element you will find the class name.
Our target class name is LC20lb, you can notice that in the above image. We will use Javascript to scrape it.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
IWebDriver driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.google.com")
var element = driver.findElement(By.XPath("/html/body/div[1]/div[3]/form/div[1]/div[1]/div[1]/div/div[2]/input"));
element.SendKeys("webshop")
element.Submit();
var titles = driver.FindElements(By.ClassName("LC20lb"))
foreach(var title in titles)
{
Console.WriteLine(title.Text)
}
}
}
}
When we run this code, we get the same results.
Web Scraping with Selenium C# (Part-II)
This purple area is dynamic content and that means that if I click on one of these menu items, the purple area will be changed to some other element but the navbar will remain the same.
So, we are going to scrape these collections. So, let’s get started.
First, we will scrape content names. Content name is stored under class card__contents

There are 19 elements with class card__contents. The first step is to grab all those elements using the FindElements function and create a list.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.reverbnation.com")
var collections = driver.FindElements(By.ClassName("card__contents"));
}
}
}
Now, we will loop through that list to get the text out of those elements.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.reverbnation.com")
var collections = driver.FindElements(By.ClassName("card__contents"));
foreach(var collection in collections)
Console.WriteLine(collection.Text)
}
}
}
We are going to open the home page and then we will click on the Discover button at the top of the page before finding any card contents.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.reverbnation.com") var discoverButton = driver.FindElement(By.Id("menu-item-discover"));
discoverButton.Click(); var collections = driver.FindElements(By.ClassName("card__contents"));
foreach(var collection in collections)
Console.WriteLine(collection.Text)
}
}
}
Now, actually, we have a C# web scraper right here but since it’s dynamic content we will not really get any elements or collection names. So, I am going to just run it and show you.
You can see nothing gets printed out.
Now, we will make a new method. If you were making a real web scraper you would probably want to have another class, and then instead of a static class or static method like I did, you would have a method on the web scraper class.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.reverbnation.com")var discoverButton = driver.FindElement(By.Id("menu-item-discover"));
discoverButton.Click();var collections = driver.FindElements(By.ClassName("card__contents"));
foreach(var collection in collections)
Console.WriteLine(collection.Text)
}
static IReadOnlyCollection<IWebElement> FindElements(By by)
{
return driver.FindElements(by);
}
}
}
Now, if I run this function, it will work the same as the above code (collections variable).
What I wanted to do is basically to run a loop and then for each iteration, it will try and find the elements by using this and if the collections contain elements then it will return them otherwise it will try again and again.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.reverbnation.com")var discoverButton = driver.FindElement(By.Id("menu-item-discover"));
discoverButton.Click();var collections = FindElements(By.ClassName("card__contents"));
foreach(var collection in collections)
Console.WriteLine(collection.Text)
}
static IReadOnlyCollection<IWebElement> FindElements(By by)
{
while(true)
{
var elements = driver.FindElements(by);
if(elements.Count > 0)
return elements;
Thread.Sleep(10);
}
}
}
}
You can see we are only returning when it contains elements otherwise it will not return anything. We have also created a thread that goes to sleep after 10 milliseconds.
Now, we can test our script once again.
So, it works and it also prints out other stuff but that doesn’t matter. Now, the problem is we have a while true and while that might be okay in some cases in other cases it might not be.
Take for example you have a proxy, it runs, and all of a sudden it doesn’t work anymore. So, it’s just going to look in this while loop forever, or maybe the document doesn’t even contain these elements.
We have to put a limit on this to avoid problems. Hence, I am just going to use a stopwatch.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.reverbnation.com")var discoverButton = driver.FindElement(By.Id("menu-item-discover"));
discoverButton.Click();var collections = FindElements(By.ClassName("card__contents"));
foreach(var collection in collections)
Console.WriteLine(collection.Text)
}
static IReadOnlyCollection<IWebElement> FindElements(By by)
{
Stopwatch w = Stopwatch.StartNew();
while(w.ElapsedMilliseconds < 10 * 1000)
{
var elements = driver.FindElements(by);
if(elements.Count > 0)
return elements;
Thread.Sleep(10);
}
return null;
}
}
}
So, if the elapsed time is more significant than 10 seconds our scraper will return null. Let’s test it.
Now, what if we have a very slow internet connection? For that, we will use ChomeNetworkConditions.
Slow Internet Connection
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
ChromeNetworkConditions conditions = new ChromeNetworkConditions();
conditions.DownloadThroughput = 25 * 1000;
conditions.UploadThroughput = 10 * 1000;
conditions.Latency = TimeSpan.From.Milliseconds(1); driver = new ChromeDriver();
driver.Navigate().GoToUrl("https://www.reverbnation.com")var discoverButton = driver.FindElement(By.Id("menu-item-discover"));
discoverButton.Click();var collections = FindElements(By.ClassName("card__contents"));
foreach(var collection in collections)
Console.WriteLine(collection.Text)
}
static IReadOnlyCollection<IWebElement> FindElements(By by)
{
Stopwatch w = Stopwatch.StartNew();
while(w.ElapsedMilliseconds < 10 * 1000)
{
var elements = driver.FindElements(by);
if(elements.Count > 0)
return elements;
Thread.Sleep(10);
}
return null;
}
}
}
Since we have saved the chrome driver as a web driver so I’m just going to make the driver as ChromeDriver.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace webscraping
{
class Program
{
static void Main(string[] args)
{
ChromeNetworkConditions conditions = new ChromeNetworkConditions();
conditions.DownloadThroughput = 25 * 1000;
conditions.UploadThroughput = 10 * 1000;
conditions.Latency = TimeSpan.From.Milliseconds(1);driver = new ChromeDriver();
(driver as ChromeDriver).NetworkConditions = conditions; driver.Navigate().GoToUrl("https://www.reverbnation.com")var discoverButton =
driver.FindElement(By.Id("menu-item-discover"));
discoverButton.Click();var collections = FindElements(By.ClassName("card__contents"));
foreach(var collection in collections)
Console.WriteLine(collection.Text)
Console.WriteLine("done");
}
static IReadOnlyCollection<IWebElement> FindElements(By by)
{
Stopwatch w = Stopwatch.StartNew();
while(w.ElapsedMilliseconds < 10 * 1000)
{
var elements = driver.FindElements(by);
if(elements.Count > 0)
return elements;
Thread.Sleep(10);
}
return new ReadOnlyCollection<IWebElement>(new List<IWebElement>);
}
}
}
So, now it should simulate a slow connection. This is a very important part of creating a web scraper where we learned about handling slow connections as well.
Since you often want to have many proxies running and maybe some of the proxies could be slow.
Conclusion
In this tutorial, we created a very simple web scraper using selenium and C#. First, we created a scraper where we make a Google search and then scrape those results. In the second section, we focused on dynamic web scraping and slow connection proxies. Now, you are trained to create commercial scrapers for your new business,
Although C# web scraper can get most of your work done, some websites that have anti-scraping measures could block your IP after some time when you deploy your scrapers.
To scale the process of web scraping, and managing proxy/IP rotation I would recommend you use an API for web scraping API.
Feel free to message us to inquire about anything you need clarification on web scraping with C#.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:
Frequently Asked Questions
Yes, C# and Python are good for web scrapping. You need to select the right programming language as per your expertise level. You can also learn web scraping with python easily.
Web Scraping with Scrapingdog


