
Google Lens is a free image recognition tool that uses deep machine learning and advanced artificial intelligence to help users identify any surrounding objects, including plants, animals, clothes, random places, etc.
In this article, we will automate image recognition by scraping Google Lens using Python and Scrapingdog’s Google Lens API.
Where Can You Use this Scraped Data from Google Lens?
Scraped Data from Google Lens can be used in various places:
- For identification of products from images for price comparisons, or inventory management.
- In training machine learning models for image classification, facial and object recognition.
- To search for related products similar to the object in the image on the internet.
- To create interactive applications that can identify objects in the surroundings and provide information about them.
Preparing The Food
Before starting the tutorial, I am assuming that you have already installed Python on your device.
Our first step is to create our project folder. You can run the below command in your terminal, which will automatically create the project folder named “lens.”
mkdir lens
After that, create a project file where we will write our code. Then, in the project terminal, run the below command to install the library, which will help us complete our work.
pip install requests
requests will be used to make an HTTP connection with the data source.
Moving forward with the most important part, we will sign up for Scrapingdog’s Google Lens API to get our API Key.
Signing up would give you free 1000 API credits which is more than enough to test the API.
Now that everything is in place, it’s time to start building our Google Lens Scraper.
Let’s get cooking 🍳
Making the First Request
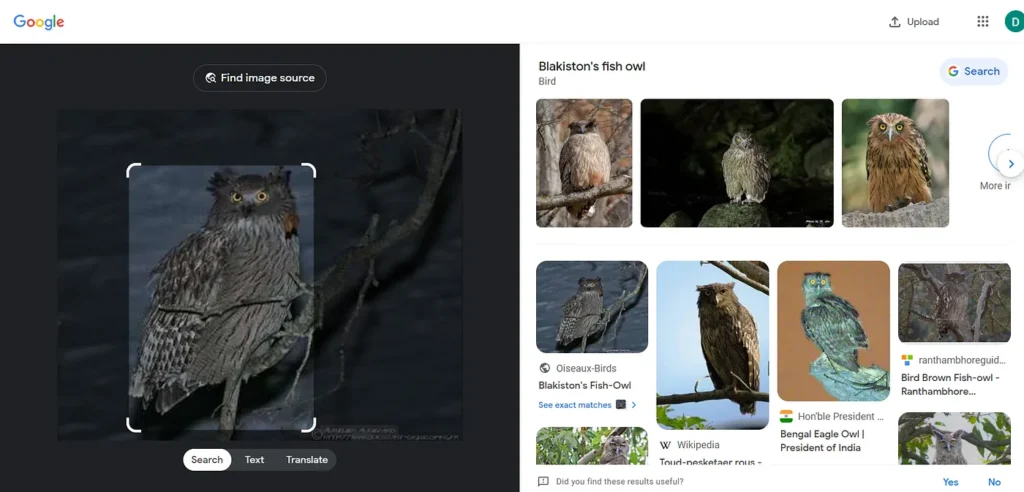
A Blakiston’s Fish Owl is the most rarest species of Owl in the world. What if you roam the Russian Far East and find this strange species? As a tourist, you may want to get some information about it🧐.
This is where we can leverage our Google Lens API to get information about this unique species.
Moving next, our first step would be to import the required libraries.
import requests
Afterward, we will initialize the API URL to scrape the Google Lens Results.
payload = {'api_key': 'APIKEY', 'url':'https://lens.google.com/uploadbyurl?url=https://www.oiseaux-birds.com/strigiformes/strigides/ketoupa-blakiston/ketoupa-blakiston-aa2.jpg'}
resp = requests.get('https://api.scrapingdog.com/google_lens', params=payload)
data = resp.json()
print(data["lens_results"])
I hope you have signed up already and can put your API Key into the URL. Otherwise, it will return you a 404 error.
After initializing the API URL, we used requests library to make a GET request on the API endpoint.
Let’s run this code in our terminal to check if we can get the results around the Blakiston’s Fish Owl🦉.
{
"lens_results": [
{
"position": 1,
"title": "Plumage Collection of Photo Prints and Gifts",
"source": "natureplprints.com",
"source_favicon": "https://encrypted-tbn0.gstatic.com/favicon-tbn?q=tbn:ANd9GcQL2WxhmsfzbB8Gm8aPwROSnz-pyXNGJB56pKYtU4-xh8p0XQ5ng076OkMw0l3wk4b8TlL0fxbNWm-tX4vfQ3zKRd7ddOvLha864a5WW9IVFlk5-3opae8LP8Lc",
"link": "https://www.natureplprints.com/galleries/plumage",
"thumbnail": "https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcTvvI1nnyPKj5jH4HA_PoubQqzTs-L_iS1LriDg0NgefLBpV0DA"
},
{
"position": 2,
"title": "Toud-pesketaer rous - Wikipedia",
"source": "wikipedia.org",
"source_favicon": "https://encrypted-tbn3.gstatic.com/favicon-tbn?q=tbn:ANd9GcS6qyk_Yke0XN4TCZQ7s8Rs6jxLY-ZU7k9Hc0gOkTaQ7KmWFDsx6UzGuwQ2Ytpm4RsqF6Xfg4A0aog77VOp-Ogzy8mehpPgeOb0ZKy5mgeFB6Vpo4uh",
"link": "https://br.wikipedia.org/wiki/Toud-pesketaer_rous",
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRAyCkbxmqIC6qhA7F-tdtTftU991D6BeRvHDufmfuzorsXMQs5"
},
.......
Scrapingdog has been in the market for a long time. It has set up its infrastructure to handle the CAPTCHAs and blocking issues at its backend using its large infrastructure of rotating residential and data center proxies.
The consistent management of the API allows users to get quick responses and real-time data from Google without any problem.
If you like this article please do share it on your social media accounts. If you have any questions, please contact me at [email protected].
Additional Resources



