Flipkart is the second largest e-commerce giant in India, following Amazon, with a market share of 39.5% in India’s mammoth-sized e-commerce market. It was founded by Sachin and Binny Bansal in 2007 in the Silicon Valley of India, i.e., Bengaluru.
As of data from 2023, Flipkart has more than 150 million products registered on its platform (source), giving neck-to-neck competition to Amazon India with 168 million products. It also makes Flipkart as a significant data center for tracking competitors and their products.
In this article, we will scrape Flipkart product details using Python, including pricing, ratings, features, and much more. We will also discuss the need for a Flipkart price tracker and how it can benefit consumers and online businesses.
The Importance of Having a Flipkart Price Tracker
As we know, Flipkart has a significant presence in India, boasting a vast customer base of 400 million. It receives 3.5 million orders/day, showcasing its immense popularity and market reach, and we must take advantage of this extensive market by deploying a Flipkart Price Tracker. Here are some benefits of having a Flipkart Price Tracker:
- Real-time Price Updates — A Flipkart price tracker will provide real-time updates on your competitor’s products and keep you informed about any price drops and discounts. This way, you can optimize the product pricing accordingly to help customers avail, the best deals available in the market.
- Product Research — We can gather a wealth of product information, including product specifications, features, and customer reviews using a Flipkart scraper for market research and trend analysis.
- Sales and Marketing — You may have often seen retailers running different promotional schemes, discounts, and sales events on e-commerce platforms. A Flipkart scraper can track these promotional events, which businesses can use to plan their sales and marketing strategies accordingly.
Let’s begin scraping Flipkart
Our first step in this tutorial is to install the libraries that we will be using later.
Set Up
Create a file named flipkartscraper.py in your respective project folder and run the following command to install the required libraries.
pip install requests
pip install beautifulsoup4- Beautiful Soup — A powerful third-party library for parsing raw HTML data.
- Requests — A powerful third-party library for extracting the raw HTML data from the web page.
Now, return to your project file and start the scraping process.
Scraping the Flipkart.com Product Page
Next, we will use the Requests library in Python to get raw HTML data from the Flipkart product page to parse and filter out the required data. import requests
url = "https://www.flipkart.com/apple-iphone-15-pro-max-blue-titanium-256-gb/p/itm4a0093df4a3d7"
html = requests.get(url)
print(html.text)Run this script in your terminal. You will get the data in the below format.
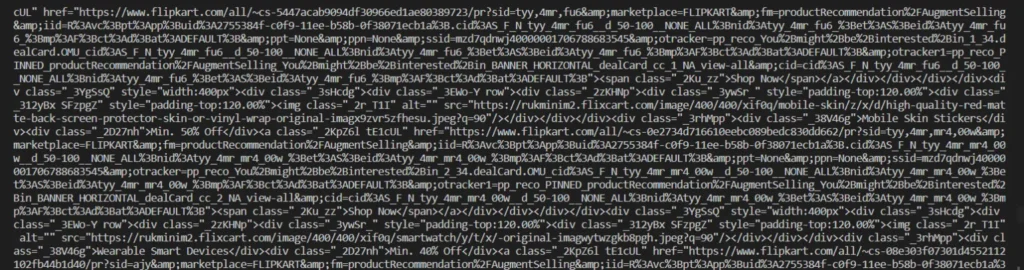
Of course, it is not in readable format. We will clean and parse this data using the Beautiful Soup library.
However, if you run the above script frequently, your IP might get blocked by Flipkart’s anti-bot mechanism. To delay this or to save our IP from getting blocked to some extent, we will pass custom request headers with the GET request.
import requests
url = "https://www.flipkart.com/apple-iphone-15-pro-max-blue-titanium-256-gb/p/itm4a0093df4a3d7"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9"
}
resp = requests.get(url, headers=headers)
print(resp.text)Okay  , so for now, we are safe to proceed. Let’s take a look at how we can extract the product details in a readable format.
, so for now, we are safe to proceed. Let’s take a look at how we can extract the product details in a readable format.
Extracting Product Details From Flipkart
We are going to extract the following data points from the Flipkart product page:
- Name
- Price
- Rating
- Highlights
- Description
- Images
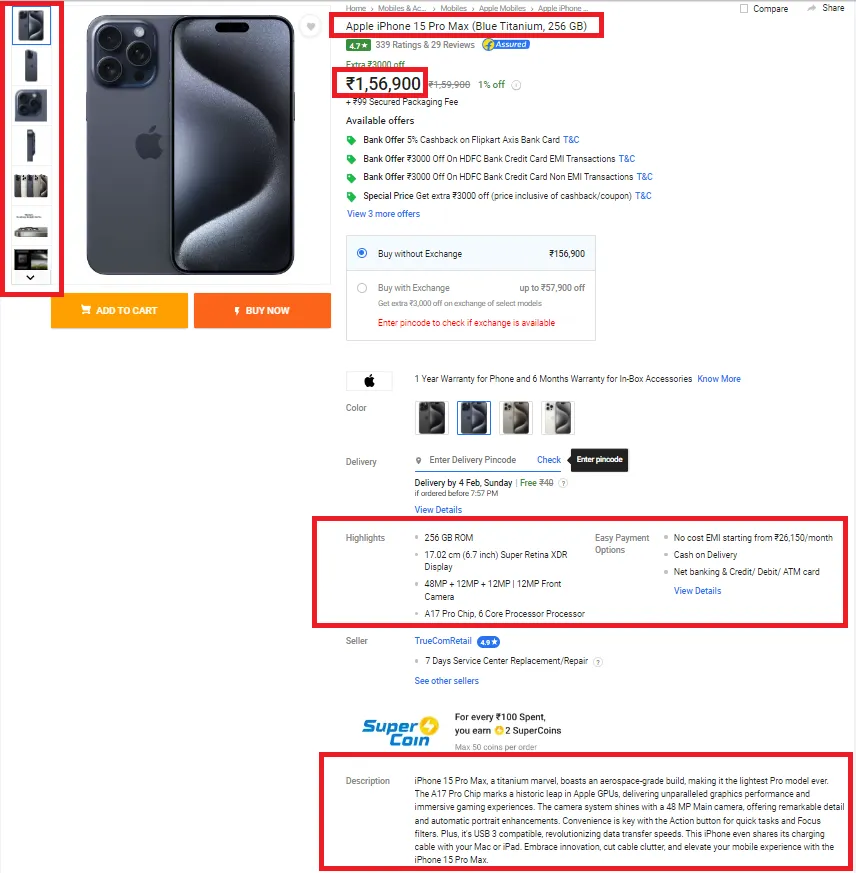
Next, we will take the help of the developer tools in the browser to get the location of the respective data points in the HTML.
Point your mouse to the title and right-click on it. This will open a menu, and scrolling to the bottom will give you an “Inspect” option. Click on it, and there you go!
Simple isn’t it?
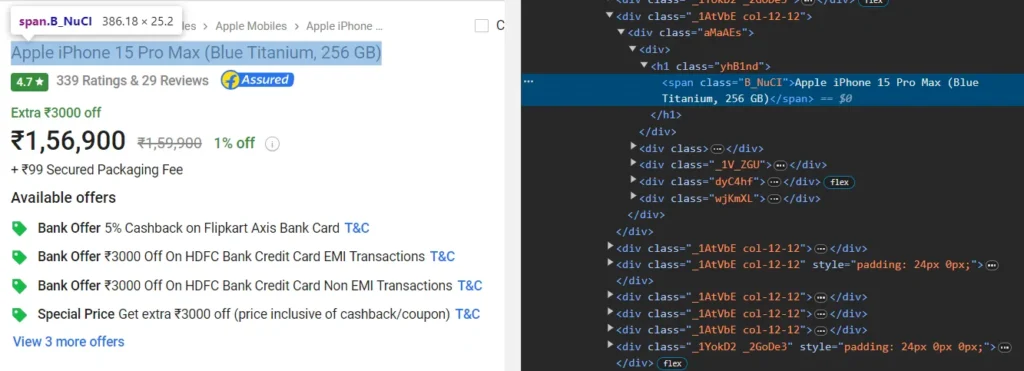
So, we got the HTML tag for the title, i.e., h1 which we will integrate into our code to extract it.
import requests
url = "https://www.flipkart.com/apple-iphone-15-pro-max-blue-titanium-256-gb/p/itm4a0093df4a3d7"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9"
}
resp = requests.get(url, headers=headers)
print(resp.status_code)
soup = BeautifulSoup(resp.text,'html.parser')
title = soup.find('h1').text.strip()
print(title)We also created an instance of BeautifulSoup to parse the text from the retrieved response.
Then, using soup.find() method, we navigated to the given HTML path and extracted the product name in text format. We used the strip() method to remove any white trailing spaces from the text.
Before moving further, we should test this code to confirm the correct output. Apple iPhone 15 Pro Max (Blue Titanium, 256 GB)
Next, we will get the product pricing.

From the above image, we can say that the pricing is under the div tag with class _30jeq3 _16Jk6d.
pricing = soup.find("div", {"class": "_30jeq3 _16Jk6d"}).text.strip()After that, we will find the product rating.

The product rating is present under the tag span with the id productRating_LSTMOBGTAGP4SVJGGH6BVMLK2_MOBGTAGP4SVJGGH6_.
Let us integrate this into our code. rating = soup.find(“span”, {“id”: “productRating_LSTMOBGTAGP4SVJGGH6BVMLK2_MOBGTAGP4SVJGGH6_”}).text.strip()
After the rating, we will target specifications or highlights of the product.
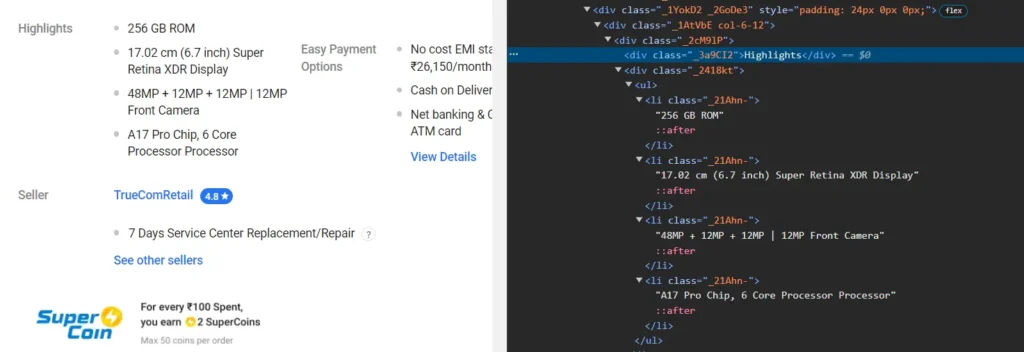
The product highlights are contained inside a list with the tag li and the class _21Ahn-.
highlights = []
ul_elements = soup.select('ul li._21Ahn-')
for ul_element in ul_elements:
highlights.append(ul_element.get_text(strip=True))In the above code, first, we created a highlights array that will store our product feature information. Then, we used the soup.select() method to select the highlights list. After that, we looped through that list to target the individual element from that list and extract text data from it.
Following the same approach we learned in previous methods, we can get the product description also.

So, the product description is contained inside the div tag with class _1mXcCf RmoJUa.description = soup.find(“div”, class_=”_1mXcCf RmoJUa”).text.strip()
Finally, we will target the product images.
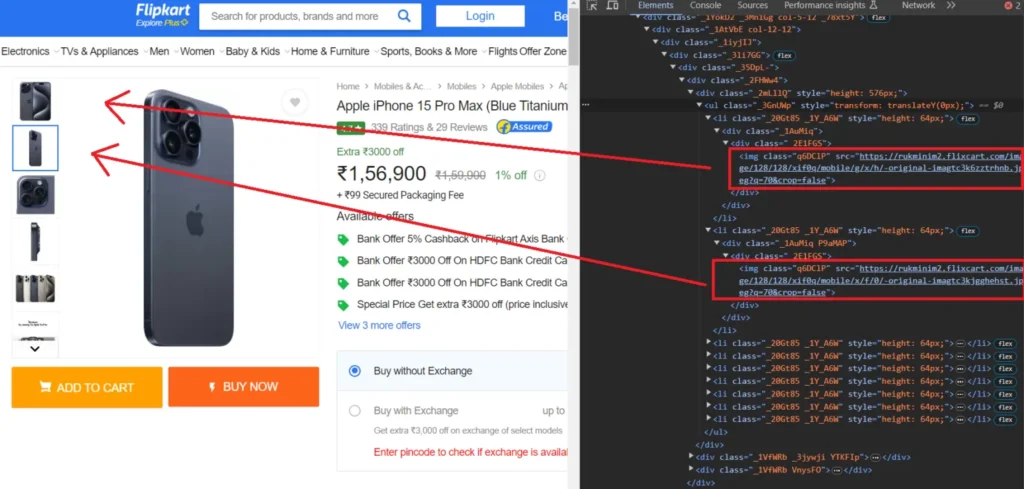
After inspecting the images, we discovered that the li tags with the class _20Gt85 _1Y_A6W are holding the individual images.
li_elements = soup.find_all('li', class_='_20Gt85 _1Y_A6W')
for li_element in li_elements:
img_src = li_element.find('img')['src']
images.append(img_src)
print(images)We have covered all the data points mentioned in the above section.
Here is the complete code:
import requests
from bs4 import BeautifulSoup
url = "https://www.flipkart.com/apple-iphone-15-pro-max-blue-titanium-256-gb/p/itm4a0093df4a3d7"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9"
}
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text,'html.parser')
title = soup.find('h1').text.strip()
pricing = soup.find("div", {"class": "_30jeq3 _16Jk6d"}).text.strip()
rating = soup.find("span", {"id": "productRating_LSTMOBGTAGP4SVJGGH6BVMLK2_MOBGTAGP4SVJGGH6_"}).text.strip()
highlights = []
ul_elements = soup.select('ul li._21Ahn-')
for ul_element in ul_elements:
highlights.append(ul_element.get_text(strip=True))
description = soup.find("div", class_="_1mXcCf RmoJUa").text.strip()
images = []
li_elements = soup.find_all('li', class_='_20Gt85 _1Y_A6W')
for li_element in li_elements:
img_src = li_element.find('img')['src']
images.append(img_src)
print(title)
print(pricing)
print(rating)
print(highlights)
print(description)
print(images)Run this code in your terminal. You will get the desired output.
Apple iPhone 15 Pro Max (Blue Titanium, 256 GB)
₹1,56,900
4.6
[
'256 GB ROM', '17.02 cm (6.7 inch) Super Retina XDR Display',
'48MP + 12MP + 12MP | 12MP Front Camera',
'A17 Pro Chip, 6 Core Processor Processor'
]
iPhone 15 Pro Max, a titanium marvel, boasts an aerospace-grade build, making it the lightest Pro model ever. The A17 Pro Chip marks a historic leap in Apple GPUs, delivering unparalleled graphics performance and immersive gaming experiences. The camera system shines with a 48 MP Main camera, offering remarkable detail and automatic portrait enhancements. Convenience is key with the Action button for quick tasks and Focus filters. Plus, it's USB 3 compatible, revolutionizing data transfer speeds. This iPhone even shares its charging cable with your Mac or iPad. Embrace innovation, cut cable clutter, and elevate your mobile experience with the iPhone 15 Pro Max.
[
'https://rukminim2.flixcart.com/image/128/128/xif0q/mobile/g/x/h/-original-imagtc3k6zztrhnb.jpeg?q=70&crop=false',
'https://rukminim2.flixcart.com/image/128/128/xif0q/mobile/x/f/0/-original-imagtc3kjgghehst.jpeg?q=70&crop=false',
'https://rukminim2.flixcart.com/image/128/128/xif0q/mobile/l/a/t/-original-imagtc3kfrghczmq.jpeg?q=70&crop=false',
'https://rukminim2.flixcart.com/image/128/128/xif0q/mobile/7/e/s/-original-imagtc3kknyq2b95.jpeg?q=70&crop=false',
'https://rukminim2.flixcart.com/image/128/128/xif0q/mobile/g/b/t/-original-imagtc3kkzh3yf2x.jpeg?q=70&crop=false',
'https://rukminim2.flixcart.com/image/128/128/xif0q/mobile/4/e/r/-original-imagtc3kugbc22hu.jpeg?q=70&crop=false',
'https://rukminim2.flixcart.com/image/128/128/xif0q/mobile/1/w/r/-original-imagtc3kkgr9nqxe.jpeg?q=70&crop=false',
'https://rukminim2.flixcart.com/image/128/128/xif0q/mobile/t/y/4/-original-imagtc3kfsrgguwa.jpeg?q=70&crop=false',
'https://rukminim2.flixcart.com/image/128/128/xif0q/mobile/o/x/q/-original-imagtc3k4g2bpahb.jpeg?q=70&crop=false'
]Hurray , we got the results!! Extracting product details from Flipkart was relatively simple compared to scraping Amazon.
, we got the results!! Extracting product details from Flipkart was relatively simple compared to scraping Amazon.
Also, if you want to add more information to this scraper, feel free to do that with the above-discussed methods.
Conclusion
Retailers who want to master competitor and price monitoring and seek more information about their industry, customers, and market demands can extract data from this Indian E-Commerce giant to stay relevant in the market.
In this tutorial, we learned to scrape Amazon Product Data using Python. Please do not hesitate to message me if I missed something.
If you think we can complete your custom scraping projects, feel free to contact us.
Additional Resources



