Before building a scenario, I would recommend that you should have your end goal clear & don’t let AI dictate you for this.
You should know what modules will be used & how the data flow between them takes place.
Know what to avoid and what data to take from a particular module. This way, when you make your scenarios you would better know which step has a problem and resolve that first then build the module further.
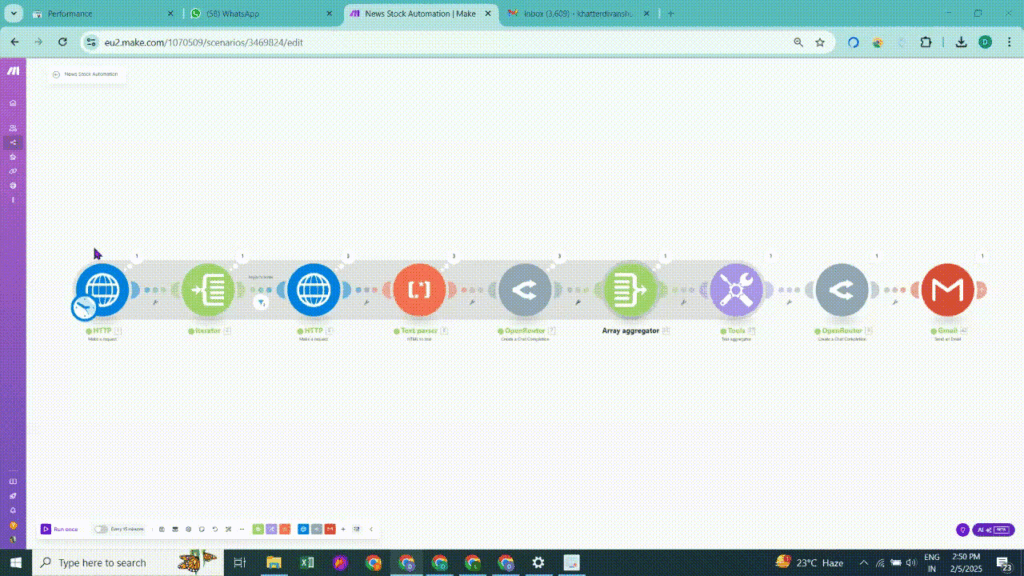
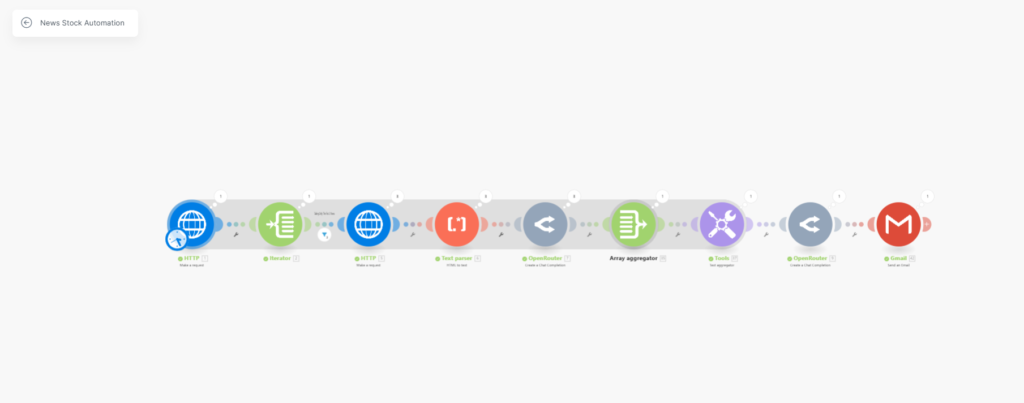
Now, when you open up your scenario, the first step is to scrape the top news for that particular keyword/stock.
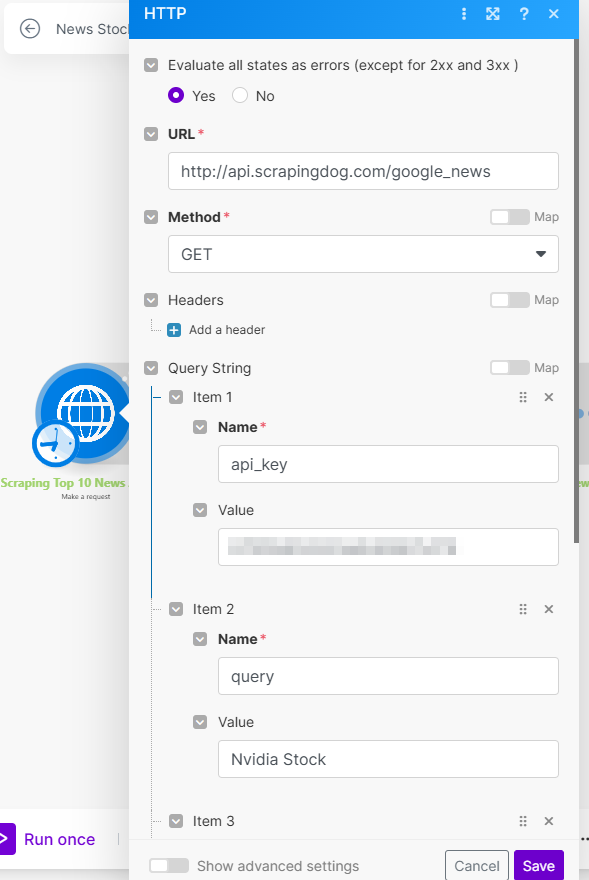
We are using an HTTP module here, the input parameters to scrape Google News from Scrapingdog, are the API_KEY & the query for which you want to get the data. The endpoint of the news API is — http://api.scrapingdog.com/google_news
In our case, the query is “NVIDIA stock”.
You can get your Scrapingdog’s API_KEY with 1000 Free credits to spin here.
In the setting below, check the box Yes to “Parse Content” This way we get the output data in JSON format, which would be easy for our modules to analyze & transfer through the scenario.
So here are the settings for our first HTTP Module in the image below⬇️
Okay, you can test this module now. If everything is okay, you will get the output.
See below the image, you will get similar output data from the News API ⬇️
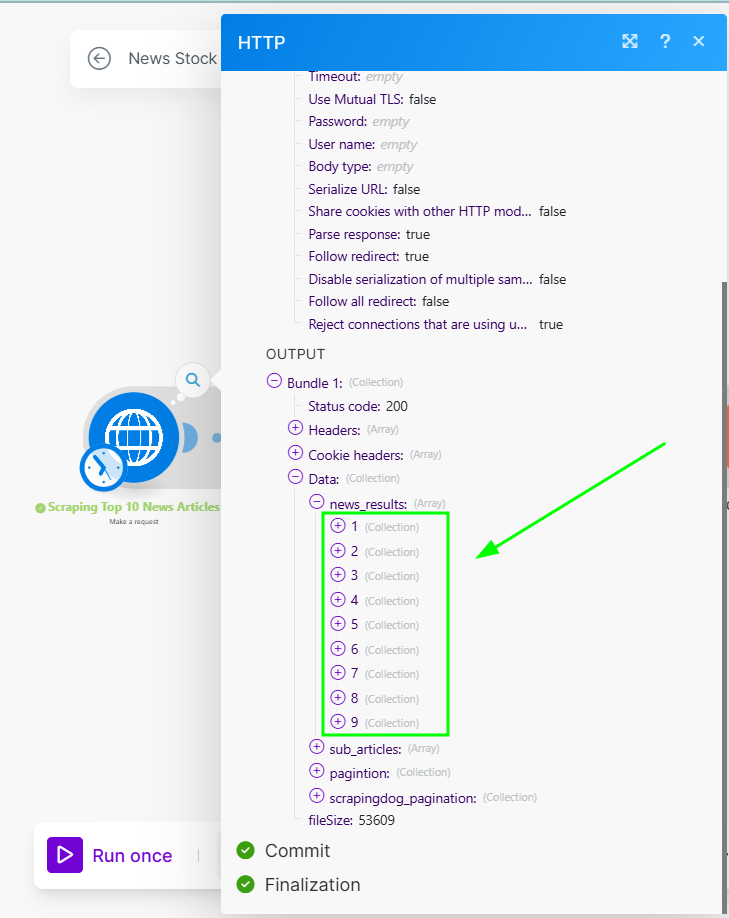
Since the module worked fine, the output data will have the first ~10 results (we got 9, nothing wrong with the API, this is what Google News has for us for this query).
Each of these collections has a URL of the source, and we would need the links to further extract the content.
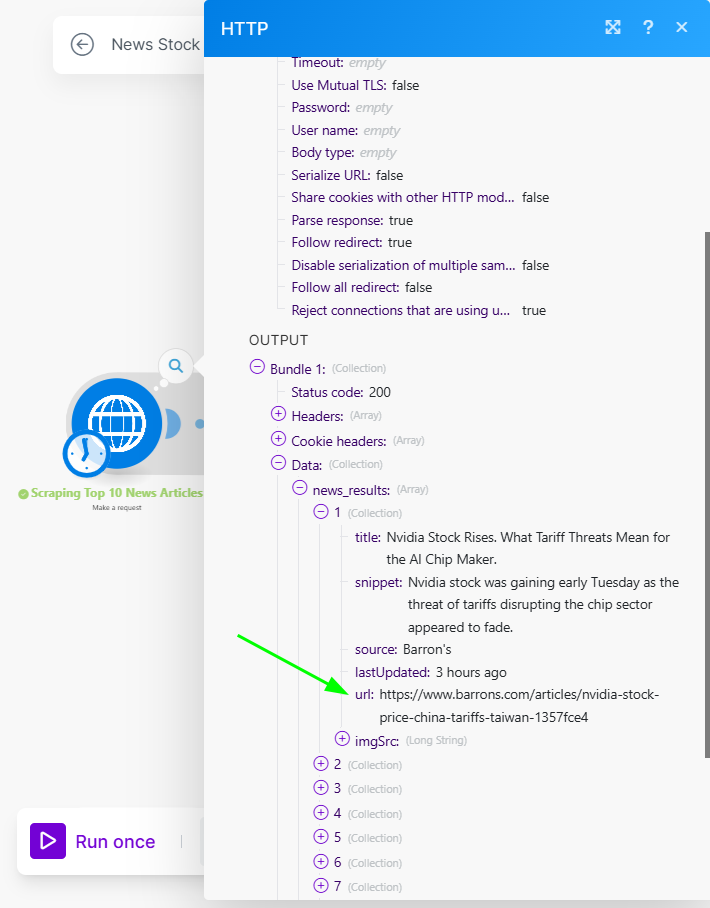
However, since they are under an array (news_results), we need to add an iterator module after it to take each unique URL.
The Iterator converts the array data into different bundles, that way it would be easy for us to take the URL data since each bundle will have unique URLs.
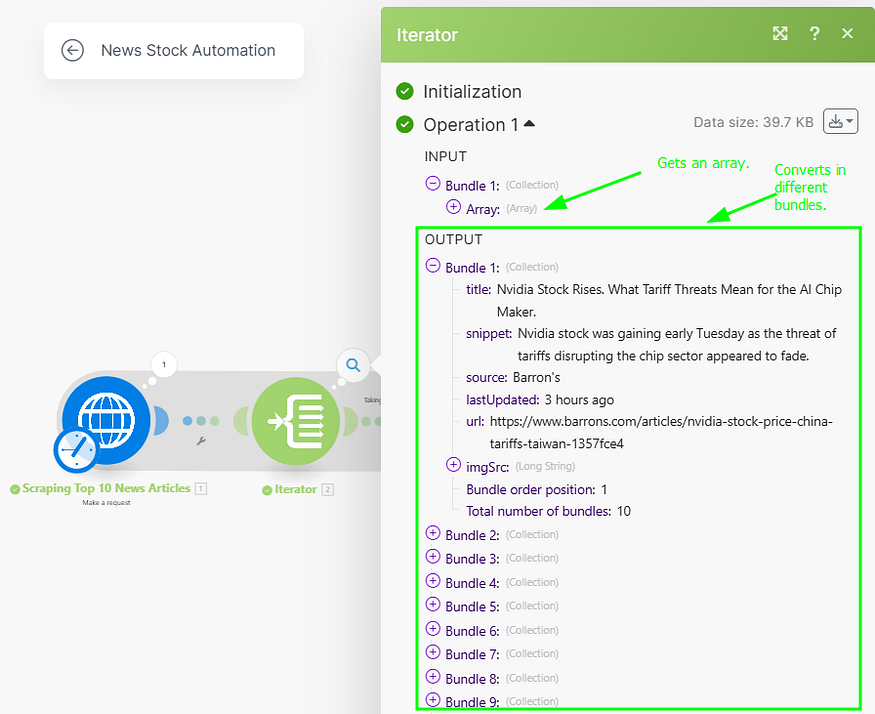
We will get the first 10 URLs, up to this module. Here to make our analysis optimized, I am taking the first 3 news to further module (where we will extract the page content) & hence one filter is applied.
After connecting the next module, which is again the HTTP Module (which we will explain) we are applying the following filter.
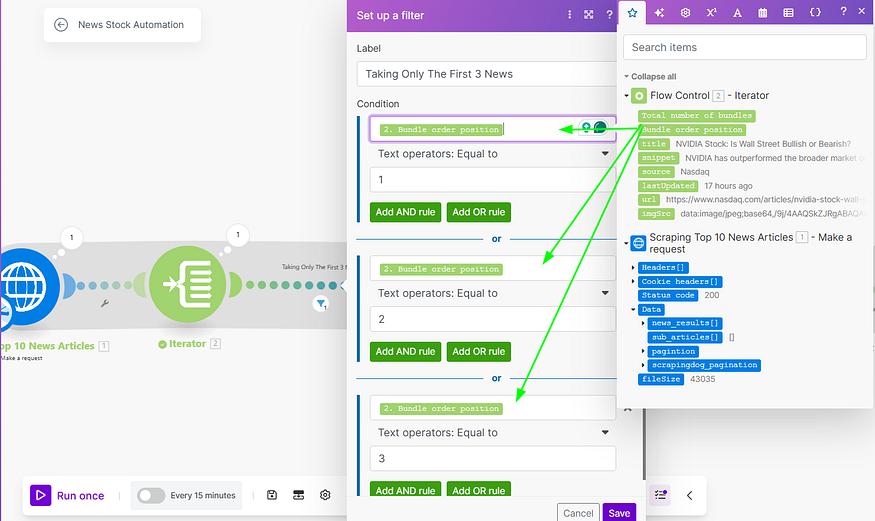
Each Bundle has a unique URL with other details, we are taking the top 3 bundles, by using the “OR” rule.
Don’t use the ‘AND’ rule here, as it would require all conditions to be met simultaneously, which is not possible in this context. The ‘AND’ rule would imply that a single item would need to simultaneously be in the first, second, and third position, which is logically impossible.
The next module will extract the content from 3 top URLs, as I said, we will be using the /scrape endpoint from Scrapingdog to extract the content.
Here are the inputs for this module:
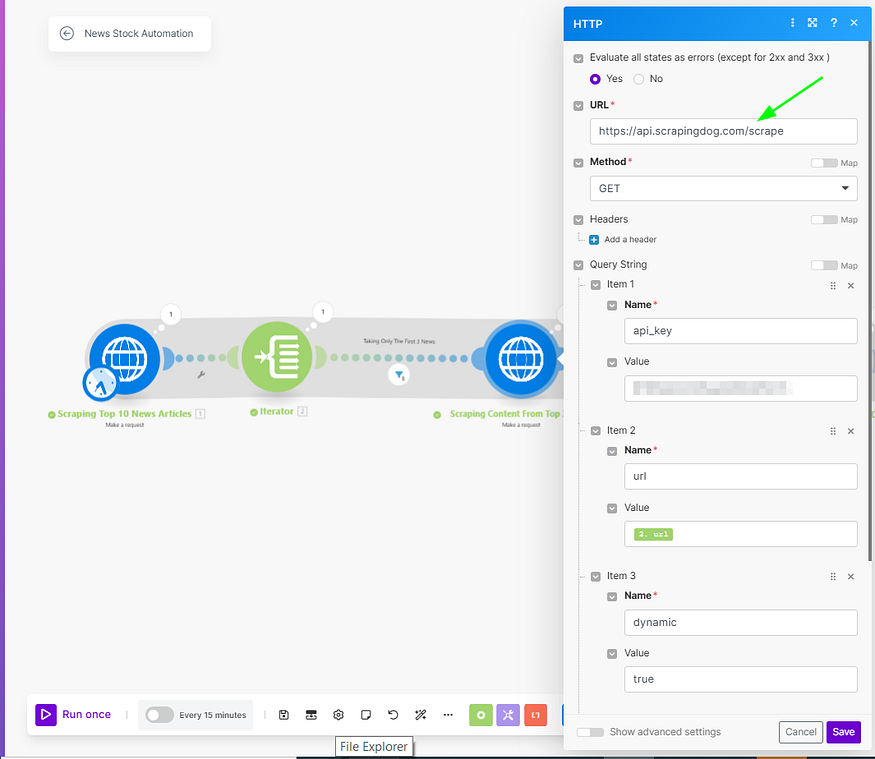
The URL parameter we are taking from our Iterator module. The output will be extracted content from each news article.
(Note: While it’s possible to directly use a GET request on URLs & avoid /scrape endpoint to fetch content from URLs, this approach might not always succeed due to some websites requiring JavaScript to render their pages. This can prevent a straightforward GET request from retrieving all necessary data. For a safer execution, we are utilizing Scrapingdog’s /scrape endpoint)
This module will give the HTML of the URLs.⬇️
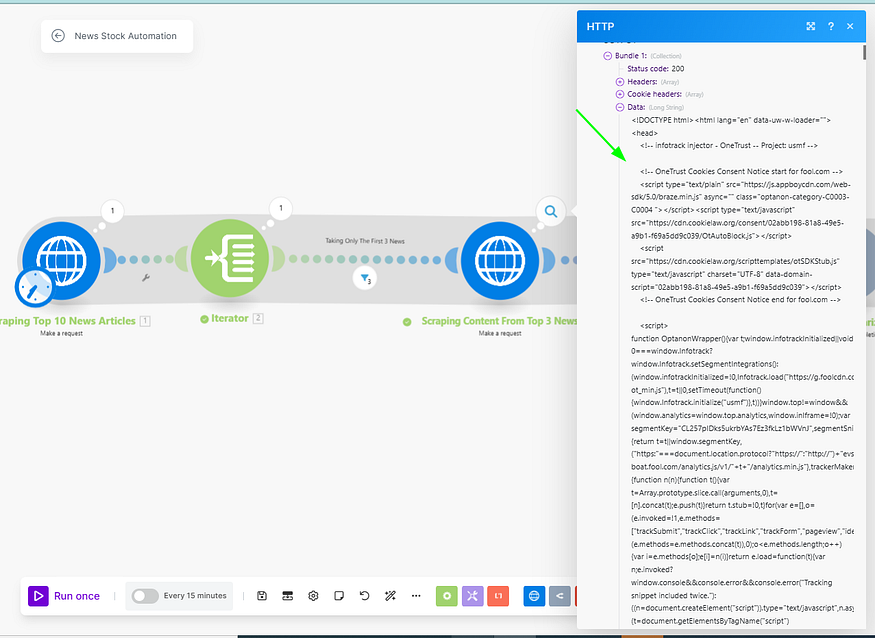
Now this HTML needs to be cleaned into text & therefore the next module we use (HTML To Text Parser) will clean this HTML.
After applying this module, we will map the data to be parsed.
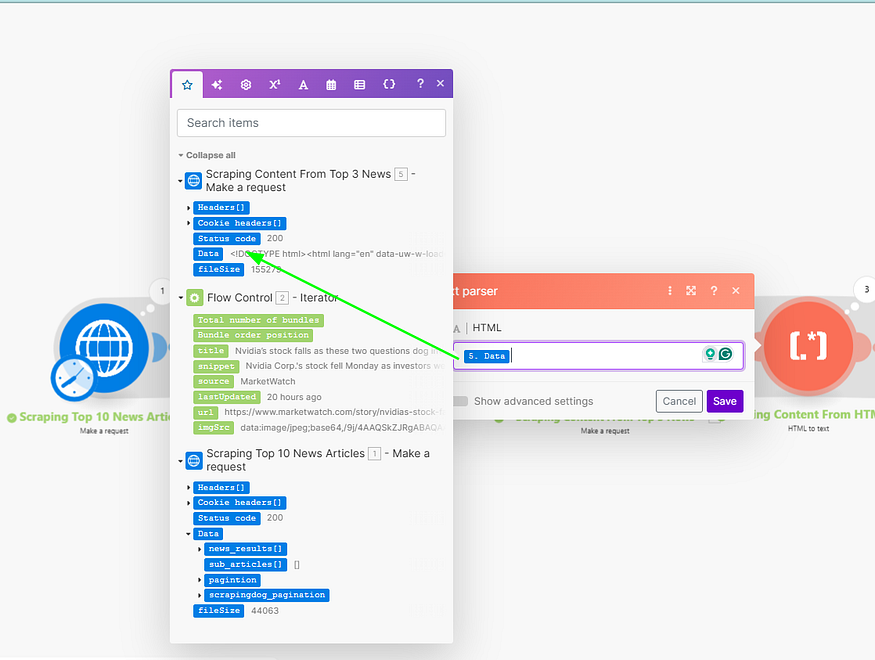
When the data passes through this module, the output is a cleaned text string.
Next, we are giving this cleaned data to an AI module, I am using Openrouter. It is a platform that provides access to AI models, including large language models (LLMs).
So no need to sign up for different AI models, you can access them all from here. There are free models that you can use, for our tutorial we will be summarizing our content with “DeepSeek R1 Distill Llama 70B” which in my tests using all the different models seems to be best for summarizing the content.
You are free to use your choice of AI models. Also, note that the models we are using are paid ones and if you wish to access paid AI models you need to top-up your account in openrouter and generate an API_KEY.
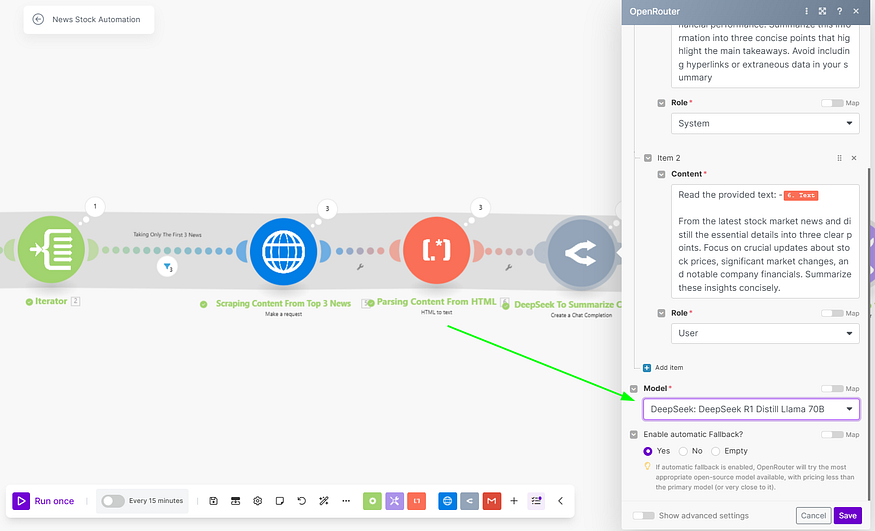
Enable automatic Fallback to Yes, this will help us with the continuous execution of our scenario.
We will give the output of our text parser here.
The System & the User Prompts I have used are here to summarize the points below.
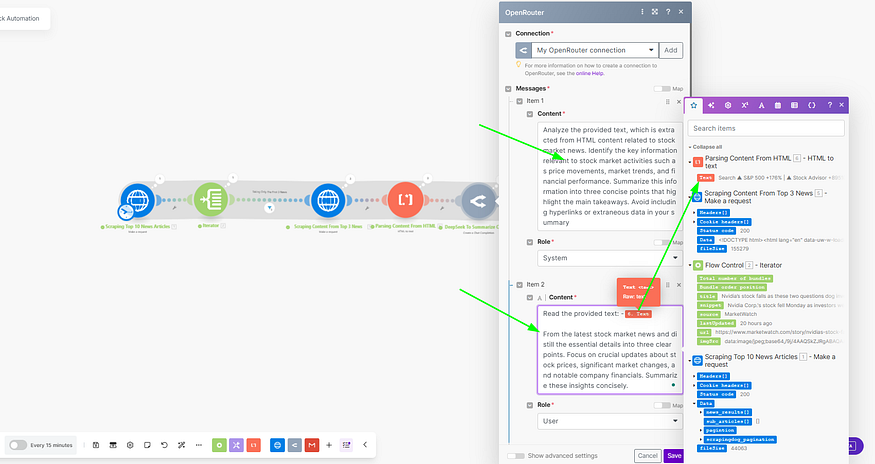
We use these system and user prompts in our AI model to summarize the parsed text obtained from the previous module. Specifically, the model condenses the text from each article into three key points. This approach ensures that the most relevant information is highlighted, making it easier to understand the essential insights of each article.
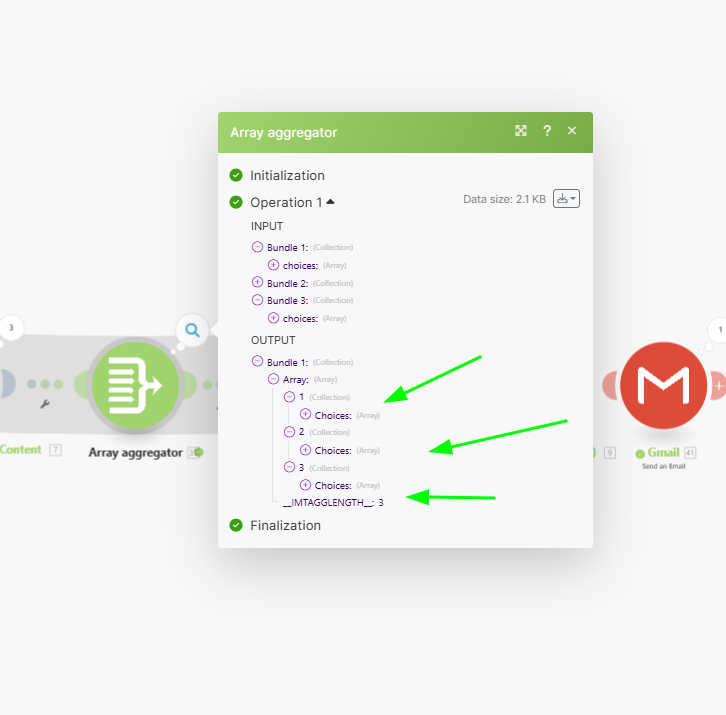
Each news will have 3 different bundles for their summaries, the task now would be to combine them into 1.
For this, we will use an aggregator module. Here are the inputs we used in our Aggregator module.
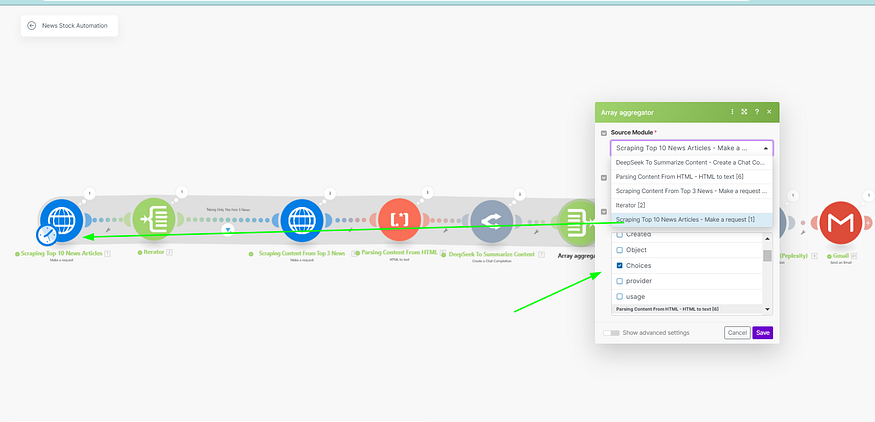
In the source module we are choosing our first HTTP request, since this way our aggregator would only run when all the summaries is prepared, and ready.
And for the Aggregated fields, we are selecting “Choices” as this array has the summary of our article (i.e. output of our AI model)
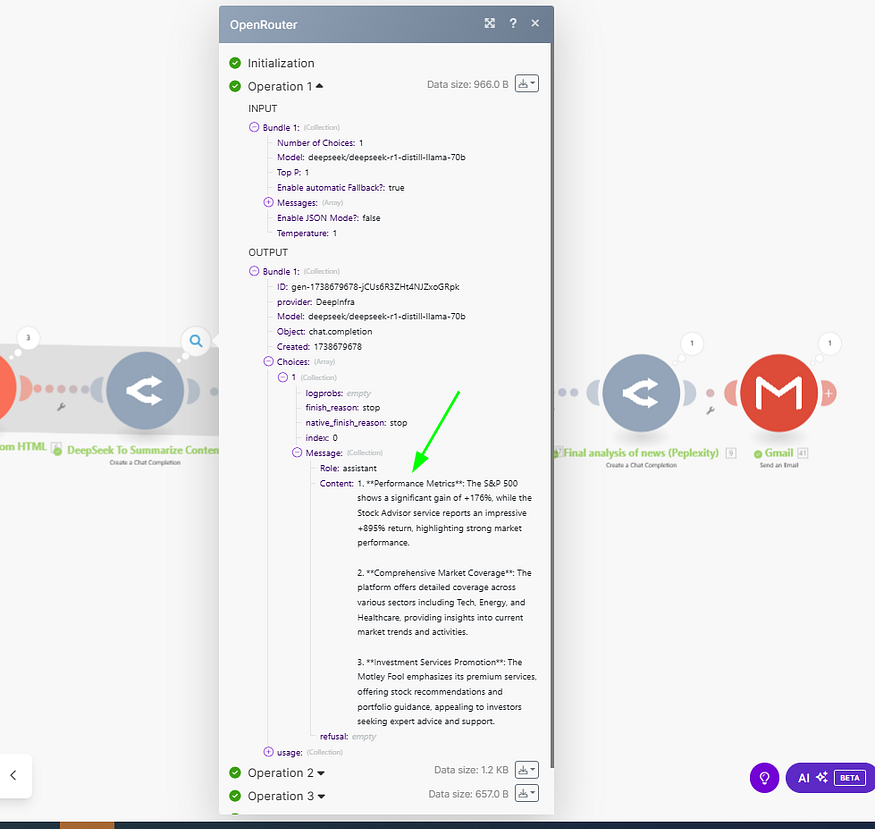
The output of our Array Aggregator will be an array of 3 Choices, see the image below
Now we will combine the text strings in one using “Text aggregator”. We will be using join, mand ap array functions here.
See the image below:
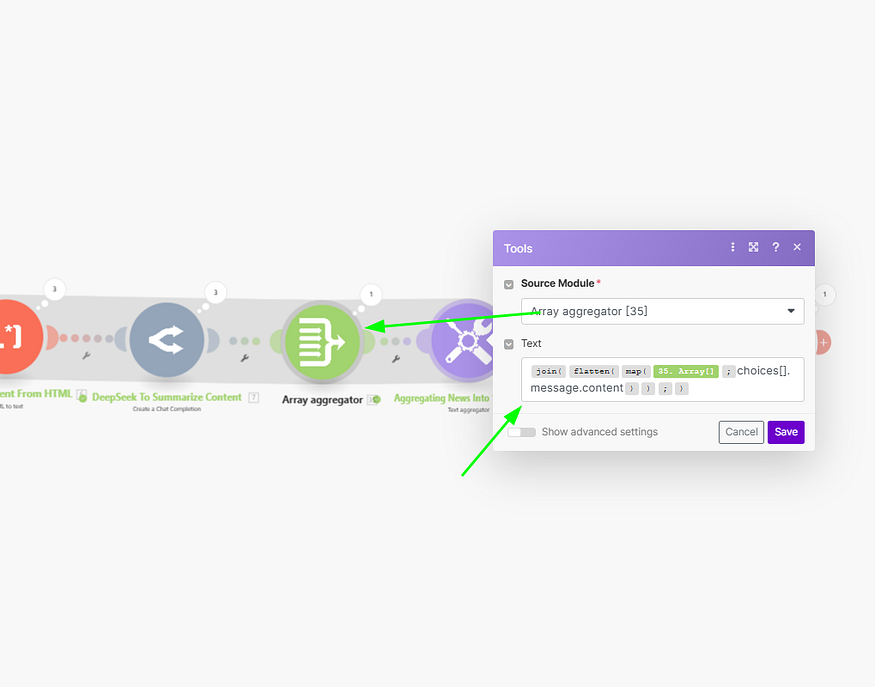
Here’s an explanation of each array function used: –
join(): This function concatenates elements of an array into a single string. We use this function to combine all the individual summaries into one text block.
flatten(): Sometimes, data arrays can have nested arrays due to the structure of the input data. flatten() helps in un-nesting these arrays, turning them into a simple list that can be easily joined. This ensures that all summaries are treated as individual elements of a single-level array, regardless of their original structure.
map(): This function applies a transformation to each element of an array. In our case, we ensure that each summary is formatted correctly before joining. It could be used to trim excess whitespace, append additional text, or standardize the summaries’ format.
Once this text aggregates into one string, we can pass this again to an AI model.
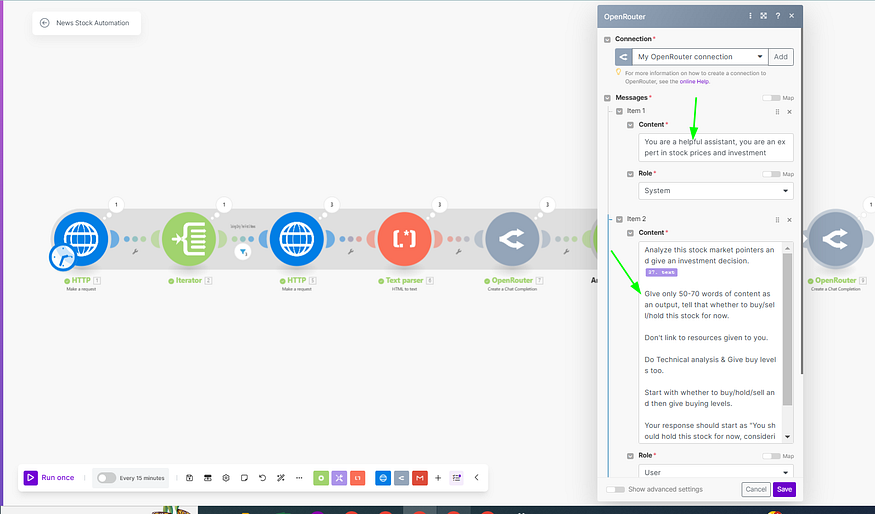
Now in the final AI module, where we have all the summaries of the news, we are promoting it to tell us whether to buy/sell/hold the stock & give buy levels based on the summary it gets.
I am using the perplexity sonar model here.
Finally, a Gmail Module to send this summary to your subscribers.
You can then schedule the whole scenario to run at a specific time of the day.
(Note – To add more stocks into the pipeline you can use Google Sheets or Airtable, to differentiate both of them via separate modules some changes in the Gmail module will be needed, or else this setup is bound to work with ’n’ no. of stocks you provide it.)