
Google Jobs API
With Google Jobs API, you can easily extract job data like company name, title, location, apply link, and more from the Google job board. This is perfect for building job boards and analyzing the job market.
- 30-day free trial
- No credit card required
- 1000 credits free
- 30-day free trial
- No credit card required
- 1000 credits free

Features of our Google Job Search API
Real-time Job Data
Our Google Jobs API provides instant access to live job postings directly from Google, ensuring you always work with the most current listings.
Targeted Job Searches
Precisely filter job searches by location, vacancy, job type, salary & many more data points, empowering your users to find exactly what they’re looking for without hassle.
Seamless Integration
With easy-to-use endpoints and clear documentation, our Google Jobs scraper API integrates smoothly into your existing platforms or apps, saving you time and resources.
See how our API for Google Jobs gives the output data
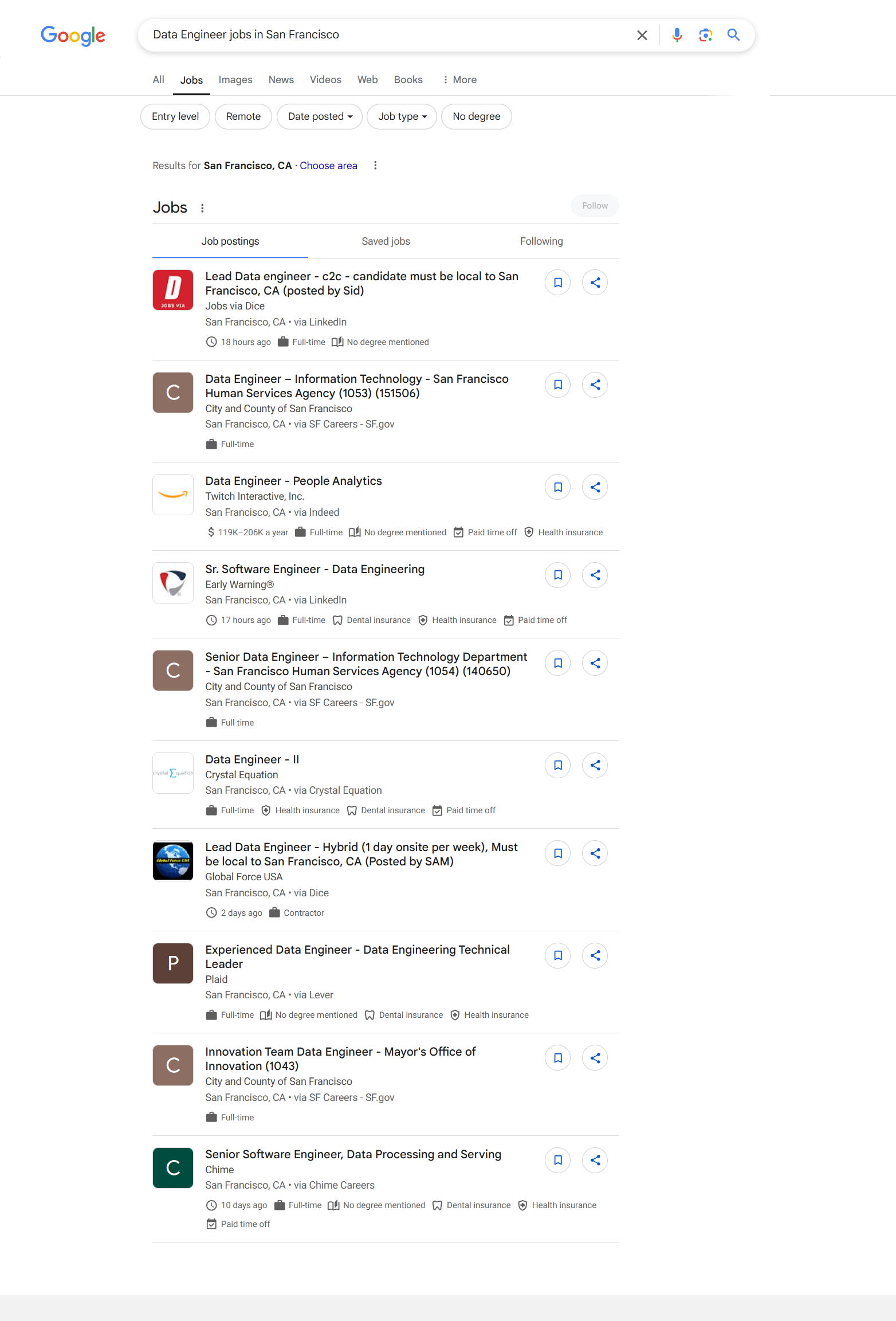
> curl "https://api.scrapingdog.com/google?api_key=5eaa61a6e562fc52fe763tr516e4653&query=new york&results=10&country=us&page=0"
{
"jobs_results": [
{
"title": "Lead Data engineer - c2c - candidate must be local to San Francisco, CA (posted by Sid)",
"company_name": "Jobs via Dice",
"location": "San Francisco, CA",
"via": "LinkedIn",
"share_link": "https://www.google.com/search?ibp=htl;jobs&q=Data+Engineer+jobs+in+San+Francisco&htidocid=A8f6AiYanEssXLwVAAAAAA%3D%3D&hl=en-US&shndl=37&shmd=H4sIAAAAAAAA_2WOMU7DQBBFlTZHSPVFRVCwUaQ0oUKJQELpcoBodnZkL1rPWJ4BhWNyI5w6zev--2_5t1jqSSjjSEEQ7YqKTHgGb_lG0lwyhWD49kASVGOqCMOZFO8TKRdn2-DwhsfRPCQj_eJc8nqef1qCC03cwxQfZl2V1WsfMfq-bd1r03lQFG7YhtZUkl3bL0t-w8V7mmSs8_tlu3u5NqN2Tw-z0vFTCMfCgqL3Hf-Hk9FX1AAAAA&shmds=v1_AQbUm97BcAbJyBE3H5t6cwXZXmzv3OO__xK7I_C0p305-zRb8Q&source=sh/x/job/uv/m5/1#fpstate=tldetail&htivrt=jobs&htidocid=A8f6AiYanEssXLwVAAAAAA%3D%3D&htiq=Data+Engineer+jobs+in+San+Francisco",
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR9CC1NlnLA7sshF1s1dqKvk8U495jsMwImnyPP&s=0",
"detected_extensions": {},
"description": "Dice is the leading career destination for tech experts at every stage of their careers. Our client, Global Force USA, is seeking the following. Apply via Dice today!\n\nRole: Lead Data Engineer c2c\n\nDuration: Long Term contract\n\nLocation: San Francisco, CA\n\nRequired Skills\n• Python and PySpark. Kafka and Kafka streams. MySQL and MySQL Heat. Azure Delta Lake. ETL processes. Kafka integrations using Spring Boot Java. Data streaming with Spark.\n\nAdditional Skills\n• Experience with Delta Lake on Azure Tableau or similar data visualization tools Unity Catalog in Databricks Airflow for pipeline management\n\nResponsibilities\n\nDevelopment Tasks:\n• Collect metrics based on user interactions.\n• Visualize data for business teams.\n• Develop and redesign data pipelines using Kafka streams.\n• Implement solutions using Spring Boot Java and Databricks Spark streaming.\n\nLeadership Duties:\n• Lead the measurement processes from requirements gathering to production delivery.\n• Collaborate with other team leads, business partners, and product managers.\n• Balance between hands-on engineering (50%) and team leadership (50%).\n\nCollaboration Structure:\n• Onsite: Lead role (this resource)\n• Nearshore: Senior developer.\n• Offshore: Data engineer role.\n\nLead Data Engineer - Job Description\n\nRequired Skills & Experience:\n• Hands-on code mindset with deep understanding in technologies / skillset and an ability to understand larger picture.\n• Sound knowledge to understand Architectural Patterns, best practices and Non-Functional Requirements\n• Overall, 8-10 years of experience in heavy volume data processing, data platform, data lake, big data, data warehouse, or equivalent.\n• 5+ years of experience with strong proficiency in Python and Spark (must-have).\n• 3+ years of hands-on experience in ETL workflows using Spark and Python.\n• 4+ years of experience with large-scale data loads, feature extraction, and data processing pipelines in different modes near real time, batch, realtime.\n• Solid understanding of data quality, data accuracy concepts and practices.\n• 3+ years of solid experience in building and deploying ML models in a production setup. Ability to quickly adapt and take care of data preprocessing, feature engineering, model engineering as needed.\n• Preferred: Experience working with Python deep learning libraries like any or more than one of these - PyTorch, Tensorflow, Keras or equivalent.\n• Preferred: Prior experience working with LLMs, transformers. Must be able to work through all phases of the model development as needed.\n• Experience integrating with various data stores, including:\n• SQL/NoSQL databases\n• In-memory stores like Redis\n• Data lakes (e.g., Delta Lake)\n• Experience with Kafka streams, producers & consumers.\n• Required: Experience with Databricks or similar data lake / data platform.\n• Required: Java and Spring Boot experience with respect to data processing - near real time, batch based.\n• Familiarity with notebook-based environments such as Jupyter Notebook.\n• Adaptability: Must be open to learning new technologies and approaches.\n• Initiative: Ability to take ownership of tasks, learn independently, and innovate.\n• With technology landscape changing rapidly, ability and willingness to learn new technologies as needed and produce results on job.\n\nPreferred Skills:\n• Ability to pivot from conventional approaches and develop creative solutions.",
"job_highlights": [
{
"title": "Qualifications",
"items": [
"Python and PySpark",
"Experience with Delta Lake on Azure Tableau or similar data visualization tools Unity Catalog in Databricks Airflow for pipeline management",
"Hands-on code mindset with deep understanding in technologies / skillset and an ability to understand larger picture",
"Sound knowledge to understand Architectural Patterns, best practices and Non-Functional Requirements",
"Overall, 8-10 years of experience in heavy volume data processing, data platform, data lake, big data, data warehouse, or equivalent",
"5+ years of experience with strong proficiency in Python and Spark (must-have)",
"3+ years of hands-on experience in ETL workflows using Spark and Python",
"4+ years of experience with large-scale data loads, feature extraction, and data processing pipelines in different modes near real time, batch, realtime",
"Solid understanding of data quality, data accuracy concepts and practices",
"3+ years of solid experience in building and deploying ML models in a production setup",
"Ability to quickly adapt and take care of data preprocessing, feature engineering, model engineering as needed",
"Must be able to work through all phases of the model development as needed",
"Experience integrating with various data stores, including:",
"SQL/NoSQL databases",
"In-memory stores like Redis",
"Data lakes (e.g., Delta Lake)",
"Experience with Kafka streams, producers & consumers",
"Required: Experience with Databricks or similar data lake / data platform",
"Required: Java and Spring Boot experience with respect to data processing - near real time, batch based",
"Familiarity with notebook-based environments such as Jupyter Notebook",
"Adaptability: Must be open to learning new technologies and approaches",
"Initiative: Ability to take ownership of tasks, learn independently, and innovate",
"With technology landscape changing rapidly, ability and willingness to learn new technologies as needed and produce results on job"
]
},
{
"title": "Benefits",
"items": null
},
{
"title": "Responsibilities",
"items": [
"Kafka integrations using Spring Boot Java",
"Collect metrics based on user interactions",
"Visualize data for business teams",
"Develop and redesign data pipelines using Kafka streams",
"Implement solutions using Spring Boot Java and Databricks Spark streaming",
"Lead the measurement processes from requirements gathering to production delivery",
"Collaborate with other team leads, business partners, and product managers",
"Balance between hands-on engineering (50%) and team leadership (50%)",
"Onsite: Lead role (this resource)",
"Offshore: Data engineer role"
]
}
],
"apply_options": [
{
"title": "LinkedIn",
"link": "https://www.linkedin.com/jobs/view/lead-data-engineer-c2c-candidate-must-be-local-to-san-francisco-ca-posted-by-sid-at-jobs-via-dice-4198748840?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Dice",
"link": "https://www.dice.com/job-detail/b6e7b0a8-fdbe-44fd-a490-0abcade5389c?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
}
],
"job_id": "eyJqb2JfdGl0bGUiOiJMZWFkIERhdGEgZW5naW5lZXIgLSBjMmMgLSBjYW5kaWRhdGUgbXVzdCBiZSBsb2NhbCB0byBTYW4gRnJhbmNpc2NvLCBDQSAocG9zdGVkIGJ5IFNpZCkiLCJjb21wYW55X25hbWUiOiJKb2JzIHZpYSBEaWNlIiwiYWRkcmVzc19jaXR5IjoiU2FuIEZyYW5jaXNjbywgQ0EiLCJodGlkb2NpZCI6IkE4ZjZBaVlhbkVzc1hMd1ZBQUFBQUE9PSIsImhsIjoiZW4ifQ=="
},
{
"title": "Data Engineer – Information Technology - San Francisco Human Services Agency (1053) (151506)",
"company_name": "City and County of San Francisco",
"location": "San Francisco, CA",
"via": "SF Careers - SF.gov",
"share_link": "https://www.google.com/search?ibp=htl;jobs&q=Data+Engineer+jobs+in+San+Francisco&htidocid=jGn5jQBMMb1erIS5AAAAAA%3D%3D&hl=en-US&shndl=37&shmd=H4sIAAAAAAAA_11OO27CQBAVLUegmjJEwTaJliJUyAkJtKRH42VYb2TPWDtrhLvcITek5RJZStK8nzTz3vg6GvdvGBHe2XkmCnD5-YUNHyW0GL0wfJGtWRpxA8xghwzrgGy9WoHPvk1-R-HkLSmsHLEd4GFemJdpIjM3xWKarrZSgRIGW0N6-CHiGpos6xg7fc1z1SZzGlObzay0uTBVcs6_pdIb7LXGQF2DkfbPpjhnHbtHU_o4APIBSuk5STn-2-b5PniCcvUHb_k4B-4AAAA&shmds=v1_AQbUm94vxf5MLx5-eGGy2dLmLiED76invqGX0xmZk6Vnw8F7oQ&source=sh/x/job/uv/m5/1#fpstate=tldetail&htivrt=jobs&htidocid=jGn5jQBMMb1erIS5AAAAAA%3D%3D&htiq=Data+Engineer+jobs+in+San+Francisco",
"detected_extensions": {},
"job_highlights": [],
"apply_options": [
{
"title": "SF Careers - SF.gov",
"link": "https://careers.sf.gov/role/?id=3743990005631428&utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
}
],
"job_id": "eyJqb2JfdGl0bGUiOiJEYXRhIEVuZ2luZWVyIOKAkyBJbmZvcm1hdGlvbiBUZWNobm9sb2d5IC0gU2FuIEZyYW5jaXNjbyBIdW1hbiBTZXJ2aWNlcyBBZ2VuY3kgKDEwNTMpICgxNTE1MDYpIiwiY29tcGFueV9uYW1lIjoiQ2l0eSBhbmQgQ291bnR5IG9mIFNhbiBGcmFuY2lzY28iLCJhZGRyZXNzX2NpdHkiOiJTYW4gRnJhbmNpc2NvLCBDQSIsImh0aWRvY2lkIjoiakduNWpRQk1NYjFlcklTNUFBQUFBQT09IiwiaGwiOiJlbiJ9"
},
{
"title": "Data Engineer - People Analytics",
"company_name": "Twitch Interactive, Inc.",
"location": "San Francisco, CA",
"via": "Indeed",
"share_link": "https://www.google.com/search?ibp=htl;jobs&q=Data+Engineer+jobs+in+San+Francisco&htidocid=G8UuKjIEj0zaAXcbAAAAAA%3D%3D&hl=en-US&shndl=37&shmd=H4sIAAAAAAAA_xWMuwoCQQxFsd1PsEot-xBBBK0WX2glaL9khzA7MibDJPj4IP_TtblwDodbfCfFaoeGsGcfmChDBReSFAlaxvix4HRUZ-lBCbMbQBiOIj7SdDOYJV03jWqsvRqOce3k0QhTL-_mLr3-p9MBM6WIRt1iOX_Xif2sur2CjXcnNsroLDypHMHVEBiuyHDIyC6okxK27Q-ADPJnqAAAAA&shmds=v1_AQbUm969pMZpS93sMlE1cvTmE_7Y9Dw0yAx1Axc4T2orAOuJJA&source=sh/x/job/uv/m5/1#fpstate=tldetail&htivrt=jobs&htidocid=G8UuKjIEj0zaAXcbAAAAAA%3D%3D&htiq=Data+Engineer+jobs+in+San+Francisco",
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSJpHPsPCtT7v0dsfLzY7WalItl5ZK269S36ESB&s=0",
"detected_extensions": {
"paid_time_off": true,
"health_insurance": true
},
"description": "- 2+ years of experience working in a data engineering or software engineering capacity - Extensive experience in developing and optimizing data pipelines using Python - Proficient in working with AWS services such as EMR, Redshift, Glue, and S3 - Demonstrates expertise in schema management, data lineage, and auditability, coupled with a strong command of data modeling, ETL processes, and data warehousing principles - Proven experience implementing data integrity practices in ETL/ELT pipelines, ensuring accuracy, consistency, and reliability\nIf you are interested in this position, please apply on Twitch's Career site https://www.twitch.tv/jobs/en/ About Us: Twitch is the world’s biggest live streaming service, with global communities built around gaming, entertainment, music, sports, cooking, and more. It is where thousands of communities come together for whatever, every day. We’re about community, inside and out. You’ll find coworkers who are eager to team up, collaborate, and smash (or elegantly solve) problems together. We’re on a quest to empower live communities, so if this sounds good to you, see what we’re up to on LinkedIn and X, and discover the projects we’re solving on our Blog. Be sure to explore our Interviewing Guide to learn how to ace our interview process. About the Role As the Data Engineer in the People & Places organization, you will be responsible for building and managing the core data pipelines and analytics tooling that power critical HR reporting functionality. This highly sensitive work requires the utmost care and discretion to ensure the security and integrity of confidential employee data as you develop the systems that HR relies on for important decision-making. Your role will involve partnering closely with an Analyst and Program Manager to design, implement, and optimize a robust data infrastructure to support the organization's talent management and workforce analytics initiatives. We are a distributed HR team with team members all over the country. You can work from Twitch’s headquarters in San Francisco, CA; or from one of our hub locations in Seattle, WA; Irvine, CA; or New York City, NY. You Will - Develop and manage scalable data pipelines to extract, transform, and load HR data from various sources - Ensure the security, reliability, and performance of the data infrastructure - Collaborate with stakeholders to understand business requirements and translate them into data-driven solutions - Automate data processing and reporting workflows to improve efficiency and data integrity - Implement data quality checks and monitor processes to maintain high data accuracy Perks - Medical, Dental, Vision & Disability Insurance - 401(k) - Maternity & Parental Leave - Flexible PTO - Amazon Employee Discount\n• Proven experience implementing data integrity practices in ETL/ELT pipelines, ensuring accuracy, consistency, and reliability\n\nWe are an equal opportunity employer and value diversity at Twitch. We do not discriminate on the basis of race, religion, color, national origin, gender, gender identity, sexual orientation, age, marital status, veteran status, or disability status, or other legally protected status.\n\nLos Angeles County applicants: Job duties for this position include: work safely and cooperatively with other employees, supervisors, and staff; adhere to standards of excellence despite stressful conditions; communicate effectively and respectfully with employees, supervisors, and staff to ensure exceptional customer service; and follow all federal, state, and local laws and Company policies. Criminal history may have a direct, adverse, and negative relationship with some of the material job duties of this position. These include the duties and responsibilities listed above, as well as the abilities to adhere to company policies, exercise sound judgment, effectively manage stress and work safely and respectfully with others, exhibit trustworthiness and professionalism, and safeguard business operations and the Company’s reputation. Pursuant to the Los Angeles County Fair Chance Ordinance, we will consider for employment qualified applicants with arrest and conviction records.\n\nPursuant to the San Francisco Fair Chance Ordinance, we will consider for employment qualified applicants with arrest and conviction records.\n\nOur inclusive culture empowers Amazonians to deliver the best results for our customers. If you have a disability and need a workplace accommodation or adjustment during the application and hiring process, including support for the interview or onboarding process, please visit https://amazon.jobs/content/en/how-we-hire/accommodations for more information. If the country/region you’re applying in isn’t listed, please contact your Recruiting Partner.\n\nOur compensation reflects the cost of labor across several US geographic markets. The base pay for this position ranges from $118,900/year in our lowest geographic market up to $205,600/year in our highest geographic market. Pay is based on a number of factors including market location and may vary depending on job-related knowledge, skills, and experience. Amazon is a total compensation company. Dependent on the position offered, equity, sign-on payments, and other forms of compensation may be provided as part of a total compensation package, in addition to a full range of medical, financial, and/or other benefits. For more information, please visit https://www.aboutamazon.com/workplace/employee-benefits. This position will remain posted until filled. Applicants should apply via our internal or external career site.",
"job_highlights": [
{
"title": "Qualifications",
"items": [
"2+ years of experience working in a data engineering or software engineering capacity - Extensive experience in developing and optimizing data pipelines using Python - Proficient in working with AWS services such as EMR, Redshift, Glue, and S3 - Demonstrates expertise in schema management, data lineage, and auditability, coupled with a strong command of data modeling, ETL processes, and data warehousing principles - Proven experience implementing data integrity practices in ETL/ELT pipelines, ensuring accuracy, consistency, and reliability",
"Los Angeles County applicants: Job duties for this position include: work safely and cooperatively with other employees, supervisors, and staff; adhere to standards of excellence despite stressful conditions; communicate effectively and respectfully with employees, supervisors, and staff to ensure exceptional customer service; and follow all federal, state, and local laws and Company policies",
"Criminal history may have a direct, adverse, and negative relationship with some of the material job duties of this position",
"These include the duties and responsibilities listed above, as well as the abilities to adhere to company policies, exercise sound judgment, effectively manage stress and work safely and respectfully with others, exhibit trustworthiness and professionalism, and safeguard business operations and the Company’s reputation"
]
},
{
"title": "Benefits",
"items": [
"The base pay for this position ranges from $118,900/year in our lowest geographic market up to $205,600/year in our highest geographic market",
"Dependent on the position offered, equity, sign-on payments, and other forms of compensation may be provided as part of a total compensation package, in addition to a full range of medical, financial, and/or other benefits"
]
},
{
"title": "Responsibilities",
"items": [
"Be sure to explore our Interviewing Guide to learn how to ace our interview process",
"About the Role As the Data Engineer in the People & Places organization, you will be responsible for building and managing the core data pipelines and analytics tooling that power critical HR reporting functionality",
"This highly sensitive work requires the utmost care and discretion to ensure the security and integrity of confidential employee data as you develop the systems that HR relies on for important decision-making",
"Your role will involve partnering closely with an Analyst and Program Manager to design, implement, and optimize a robust data infrastructure to support the organization's talent management and workforce analytics initiatives",
"You Will - Develop and manage scalable data pipelines to extract, transform, and load HR data from various sources - Ensure the security, reliability, and performance of the data infrastructure - Collaborate with stakeholders to understand business requirements and translate them into data-driven solutions - Automate data processing and reporting workflows to improve efficiency and data integrity - Implement data quality checks and monitor processes to maintain high data accuracy Perks - Medical, Dental, Vision & Disability Insurance - 401(k) - Maternity & Parental Leave - Flexible PTO - Amazon Employee Discount",
"Proven experience implementing data integrity practices in ETL/ELT pipelines, ensuring accuracy, consistency, and reliability"
]
}
],
"apply_options": [
{
"title": "Indeed",
"link": "https://www.indeed.com/viewjob?jk=65d908893a5f09a4&utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Built In San Francisco",
"link": "https://www.builtinsf.com/job/data-engineer-people-analytics/4334077?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Wellfound",
"link": "https://wellfound.com/jobs/3233693-data-engineer-people-analytics?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Teal",
"link": "https://www.tealhq.com/job/data-engineer-people-analytics_f382b07e-483d-4f75-bcd7-2110f46d85ef?target_titles=analytics+engineer&page=3&utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Built In",
"link": "https://builtin.com/job/data-engineer-people-analytics/4334077?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "AbilityLinks",
"link": "https://abilitylinks.org/jobs/120582136-data-engineer-people-analytics?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "ZipRecruiter",
"link": "https://www.ziprecruiter.com/c/Amazon/Job/Data-Engineer-People-Analytics/-in-San-Francisco,CA?jid=8f1d37a5640de70a&utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "LinkedIn",
"link": "https://www.linkedin.com/jobs/view/data-engineer-people-analytics-at-twitch-4174499945?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
}
],
"job_id": "eyJqb2JfdGl0bGUiOiJEYXRhIEVuZ2luZWVyIC0gUGVvcGxlIEFuYWx5dGljcyIsImNvbXBhbnlfbmFtZSI6IlR3aXRjaCBJbnRlcmFjdGl2ZSwgSW5jLiIsImFkZHJlc3NfY2l0eSI6IlNhbiBGcmFuY2lzY28sIENBIiwiaHRpZG9jaWQiOiJHOFV1S2pJRWowemFBWGNiQUFBQUFBPT0iLCJobCI6ImVuIn0="
},
{
"title": "Sr. Software Engineer - Data Engineering",
"company_name": "Early Warning®",
"location": "San Francisco, CA",
"via": "LinkedIn",
"share_link": "https://www.google.com/search?ibp=htl;jobs&q=Data+Engineer+jobs+in+San+Francisco&htidocid=fj1yH8Z_uPF8hEq6AAAAAA%3D%3D&hl=en-US&shndl=37&shmd=H4sIAAAAAAAA_z2NMQrCQBAAsc0TrLawEr0TwUYLEY2CbQrLsDnOy8m5G3YPjP-x9hG-zNjYDMw0U7xGxbYSAxVf8wPFQ0khkvcCczhgxr9HCkM6cwPqUVwLTHBiDsmPN23Ona6tVU0maMYcnXF8t0y-4d7euNEfam2HQ5cw-3q5WvSmozCdlCjpCRcUGhafN0SCCgmOguSiOp7BfvcFAG0McqcAAAA&shmds=v1_AQbUm97gr1phb2O0U7-SGZpRAytBazff6i3EVrQbe-HGckwztg&source=sh/x/job/uv/m5/1#fpstate=tldetail&htivrt=jobs&htidocid=fj1yH8Z_uPF8hEq6AAAAAA%3D%3D&htiq=Data+Engineer+jobs+in+San+Francisco",
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRUNrREC5c2GGePGeFp23qP3rH0WnSUYAFWepFI&s=0",
"detected_extensions": {
"health_insurance": true,
"paid_time_off": true,
"dental_coverage": true
},
"description": "At Early Warning, we’ve powered and protected the U.S. financial system for over thirty years with cutting-edge solutions like Zelle®, Paze℠, and so much more. As a trusted name in payments, we partner with thousands of institutions to increase access to financial services and protect transactions for hundreds of millions of consumers and small businesses.\n\nPositions located in Scottsdale, San Francisco, Chicago, or New York follow a hybrid work model to allow for a more collaborative working environment.\n\nCandidates responding to this posting must independently possess the eligibility to work in the United States, for any employer, at the date of hire. This position is ineligible for employment Visa sponsorship.\n\nSome of the Ways We Prioritize Your Health and Happiness\n• Healthcare Coverage – Competitive medical (PPO/HDHP), dental, and vision plans as well as company contributions to your Health Savings Account (HSA) or pre-tax savings through flexible spending accounts (FSA) for commuting, health & dependent care expenses.\n• 401(k) Retirement Plan – Featuring a 100% Company Safe Harbor Match on your first 6% deferral immediately upon eligibility.\n• Paid Time Off – Unlimited Time Off for Exempt (salaried) employees, as well as generous PTO for Non-Exempt (hourly) employees, plus 11 paid company holidays and a paid volunteer day.\n• 12 weeks of Paid Parental Leave\n• Maven Family Planning – provides support through your Parenting journey including egg freezing, fertility, adoption, surrogacy, pregnancy, postpartum, early pediatrics, and returning to work.\n\nAnd SO much more! We continue to enhance our program, so be sure to check our Benefits page here for the latest. Our team can share more during the interview process!\n\nPursuant to the San Francisco Fair Chance Ordinance, we will consider for employment qualified applicants with arrest and conviction records.\n\nEarly Warning Services, LLC (“Early Warning”) considers for employment, hires, retains and promotes qualified candidates on the basis of ability, potential, and valid qualifications without regard to race, religious creed, religion, color, sex, sexual orientation, genetic information, gender, gender identity, gender expression, age, national origin, ancestry, citizenship, protected veteran or disability status or any factor prohibited by law, and as such affirms in policy and practice to support and promote equal employment opportunity and affirmative action, in accordance with all applicable federal, state, and municipal laws. The company also prohibits discrimination on other bases such as medical condition, marital status or any other factor that is irrelevant to the performance of our employees.",
"job_highlights": [],
"apply_options": [
{
"title": "LinkedIn",
"link": "https://www.linkedin.com/jobs/view/sr-software-engineer-data-engineering-at-early-warning%C2%AE-4200298659?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Taro",
"link": "https://www.jointaro.com/jobs/apple/software-application-support-engineer-retail-engineering/?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Recruiter Jobs",
"link": "https://jobs.recruiter.com/jobs/18953049533-sr-software-engineer-data-engineering?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Learn4Good",
"link": "https://www.learn4good.com/jobs/san-francisco/california/software_development/4086919890/e/?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "WhatJobs",
"link": "https://www.whatjobs.com/gfj/1918182717?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "JoPilot",
"link": "https://jobs.jopilot.net/job/EMnN7ZUB_CyF9o_0g5eE0325?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Jobilize",
"link": "https://www.jobilize.com/job/us-ca-san-francisco-sr-software-engineer-data-engineering-early-warning?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Recruit.net",
"link": "https://www.recruit.net/job/software-engineer-data-engineering-jobs/FFF12B7096505EF7?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
}
],
"job_id": "eyJqb2JfdGl0bGUiOiJTci4gU29mdHdhcmUgRW5naW5lZXIgLSBEYXRhIEVuZ2luZWVyaW5nIiwiY29tcGFueV9uYW1lIjoiRWFybHkgV2FybmluZ8KuIiwiYWRkcmVzc19jaXR5IjoiU2FuIEZyYW5jaXNjbywgQ0EiLCJodGlkb2NpZCI6ImZqMXlIOFpfdVBGOGhFcTZBQUFBQUE9PSIsImhsIjoiZW4ifQ=="
},
{
"title": "Senior Data Engineer – Information Technology Department - San Francisco Human Services Agency (1054) (140650)",
"company_name": "City and County of San Francisco",
"location": "San Francisco, CA",
"via": "SF Careers - SF.gov",
"share_link": "https://www.google.com/search?ibp=htl;jobs&q=Data+Engineer+jobs+in+San+Francisco&htidocid=-mCmFTc6bLBRLG_TAAAAAA%3D%3D&hl=en-US&shndl=37&shmd=H4sIAAAAAAAA_11OO27CQBAVLUdINWWIwHYiTJFUyOTbOj0aL8N6kT1j7QwR7ug4QG6Yg0TZlEnzftLMe9PvyfQyqYmDRNigITyyD0wU4ev8Ca-8l9ijBWF4J9eydOJH2NCA0XpigwXUyPAUkV1QJ_By7JOvKX4ERwprT-xGuL4tyuUs0bJYlcUsXb1JA0oYXQvp97OI7-jqoTUb9D7PVbvMq6Vilznpc2Fq5JQfpNFf2GqLkYYOjbZ3ZXHKBvY3ZRVsBOQdVHLkJGX_b1vgv8EcqvUPq4Pj9QEBAAA&shmds=v1_AQbUm95KM_nmEvi_bGPg9Y-xzpPEj4zeBhSBCSr083RjvWXSbg&source=sh/x/job/uv/m5/1#fpstate=tldetail&htivrt=jobs&htidocid=-mCmFTc6bLBRLG_TAAAAAA%3D%3D&htiq=Data+Engineer+jobs+in+San+Francisco",
"detected_extensions": {},
"job_highlights": [],
"apply_options": [
{
"title": "SF Careers - SF.gov",
"link": "https://careers.sf.gov/role/?id=3743990003650788&utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
}
],
"job_id": "eyJqb2JfdGl0bGUiOiJTZW5pb3IgRGF0YSBFbmdpbmVlciDigJMgSW5mb3JtYXRpb24gVGVjaG5vbG9neSBEZXBhcnRtZW50IC0gU2FuIEZyYW5jaXNjbyBIdW1hbiBTZXJ2aWNlcyBBZ2VuY3kgKDEwNTQpICgxNDA2NTApIiwiY29tcGFueV9uYW1lIjoiQ2l0eSBhbmQgQ291bnR5IG9mIFNhbiBGcmFuY2lzY28iLCJhZGRyZXNzX2NpdHkiOiJTYW4gRnJhbmNpc2NvLCBDQSIsImh0aWRvY2lkIjoiLW1DbUZUYzZiTEJSTEdfVEFBQUFBQT09IiwiaGwiOiJlbiJ9"
},
{
"title": "Lead Data Engineer - Hybrid (1 day onsite per week), Must be local to San Francisco, CA (Posted by SAM)",
"company_name": "Global Force USA",
"location": "San Francisco, CA",
"via": "Dice",
"share_link": "https://www.google.com/search?ibp=htl;jobs&q=Data+Engineer+jobs+in+San+Francisco&htidocid=4rp07Vmotfvfi1QbAAAAAA%3D%3D&hl=en-US&shndl=37&shmd=H4sIAAAAAAAA_2WOMUsDQRBGsc1PsPoaIQnJXRTSxOowJiIJCEfqMLs33K2uO8fOiLnGX-sP8azTvObB401-byY_B6YGWzLCc2pDYs5Y4mVwOTSY3qOhAZI0GKMf1Tfzx2yB45caHCOKpwgT1JSwy5R8UC8LPFWYvokaN3AD6uo4G6Ov4qBM2XdjEXuRNvLtY2fW66YsVWPRqpEFX3j5LCWxk0v5Lk7_cdaOMveRjM8P69Wl6FM7v9tHcePATrJnnOoKIV2v_AHGFhAj5wAAAA&shmds=v1_AQbUm96KMznA1UNQTRkwRk4Q8Jiu-0B7ip_4LLISo6pnpZzM0g&source=sh/x/job/uv/m5/1#fpstate=tldetail&htivrt=jobs&htidocid=4rp07Vmotfvfi1QbAAAAAA%3D%3D&htiq=Data+Engineer+jobs+in+San+Francisco",
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSduqqh5VLaTRx08FrSigm-Xo4sjQODeRYd5OOi&s=0",
"detected_extensions": {},
"description": "Required Skills & Experience:\n• Hands-on code mindset with deep understanding in technologies / skillset and an ability to understand larger picture.\n• Sound knowledge to understand Architectural Patterns, best practices and Non-Functional Requirements\n• Overall, 8-10 years of experience in heavy volume data processing, data platform, data lake, big data, data warehouse, or equivalent.\n• 5+ years of experience with strong proficiency in Python and Spark (must-have).\n• 3+ years of hands-on experience in ETL workflows using Spark and Python.\n• 4+ years of experience with large-scale data loads, feature extraction, and data processing pipelines in different modes near real time, batch, realtime.\n• Solid understanding of data quality, data accuracy concepts and practices.\n• 3+ years of solid experience in building and deploying ML models in a production setup. Ability to quickly adapt and take care of data preprocessing, feature engineering, model engineering as needed.\n\nPreferred: Experience working with Python deep learning libraries like any or more than one of these - PyTorch, Tensorflow, Keras or equivalent.\n\nPreferred: Prior experience working with LLMs, transformers. Must be able to work through all phases of the model development as needed.\n\nExperience integrating with various data stores, including:\n• SQL/NoSQL databases\n• In-memory stores like Redis\n• Data lakes (e.g., Delta Lake)\n• Experience with Kafka streams, producers & consumers.\n\nRequired: Experience with Databricks or similar data lake / data platform.\n\nRequired: Java and Spring Boot experience with respect to data processing - near real time, batch based.",
"job_highlights": [
{
"title": "Qualifications",
"items": [
"Hands-on code mindset with deep understanding in technologies / skillset and an ability to understand larger picture",
"Sound knowledge to understand Architectural Patterns, best practices and Non-Functional Requirements",
"Overall, 8-10 years of experience in heavy volume data processing, data platform, data lake, big data, data warehouse, or equivalent",
"5+ years of experience with strong proficiency in Python and Spark (must-have)",
"3+ years of hands-on experience in ETL workflows using Spark and Python",
"4+ years of experience with large-scale data loads, feature extraction, and data processing pipelines in different modes near real time, batch, realtime",
"Solid understanding of data quality, data accuracy concepts and practices",
"3+ years of solid experience in building and deploying ML models in a production setup",
"Ability to quickly adapt and take care of data preprocessing, feature engineering, model engineering as needed",
"Must be able to work through all phases of the model development as needed",
"Experience integrating with various data stores, including:",
"SQL/NoSQL databases",
"In-memory stores like Redis",
"Data lakes (e.g., Delta Lake)",
"Experience with Kafka streams, producers & consumers",
"Required: Experience with Databricks or similar data lake / data platform",
"Required: Java and Spring Boot experience with respect to data processing - near real time, batch based"
]
},
{
"title": "Benefits",
"items": null
},
{
"title": "Responsibilities",
"items": null
}
],
"apply_options": [
{
"title": "Dice",
"link": "https://www.dice.com/job-detail/48c2f4f4-3a50-48c8-a061-1d8bd5889cfb?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
}
],
"job_id": "eyJqb2JfdGl0bGUiOiJMZWFkIERhdGEgRW5naW5lZXIgLSBIeWJyaWQgKDEgZGF5IG9uc2l0ZSBwZXIgd2VlayksIE11c3QgYmUgbG9jYWwgdG8gU2FuIEZyYW5jaXNjbywgQ0EgKFBvc3RlZCBieSBTQU0pIiwiY29tcGFueV9uYW1lIjoiR2xvYmFsIEZvcmNlIFVTQSIsImFkZHJlc3NfY2l0eSI6IlNhbiBGcmFuY2lzY28sIENBIiwiaHRpZG9jaWQiOiI0cnAwN1Ztb3RmdmZpMVFiQUFBQUFBPT0iLCJobCI6ImVuIn0="
},
{
"title": "Data Engineer - II",
"company_name": "Crystal Equation",
"location": "San Francisco, CA",
"via": "Crystal Equation",
"share_link": "https://www.google.com/search?ibp=htl;jobs&q=Data+Engineer+jobs+in+San+Francisco&htidocid=rVZspvN3Kurj048KAAAAAA%3D%3D&hl=en-US&shndl=37&shmd=H4sIAAAAAAAA_xXMMQ7CMAxAUbH2CExeGEDQICQWmFApqKwcoHIjKw0KdoiDVE7BlQnL396vvrNqecaM0LLzTJRgA11XcpMBlDDZEYThKuICzY9jzlEPxqiG2mnG7G1t5WmEaZDJPGTQf3odMVEMmKnf7bdTHdmtFk36FBKgfb0LLFfPcEeGS0K2Xq2soTn9AMjKFjGSAAAA&shmds=v1_AQbUm94gJU4-MkjKzozu6llOQ1PhWZjqjWVC-Z26Re5KspIIpw&source=sh/x/job/uv/m5/1#fpstate=tldetail&htivrt=jobs&htidocid=rVZspvN3Kurj048KAAAAAA%3D%3D&htiq=Data+Engineer+jobs+in+San+Francisco",
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQGz49qrwVnpPXXvgvseF3bgkx72u7AB253tU-L&s=0",
"detected_extensions": {
"health_insurance": true,
"dental_coverage": true,
"paid_time_off": true
},
"description": "***Cloud Data Engineer***\n\nLocation: San Francisco\n\nPosition type: Hybrid (2+ days in office)\n\n• Expert in developing and analyzing complex SQL on a variety of RDBMS (Microsoft SQL Server, Oracle)\n\n• Expert knowledge of data modeling and understanding of different data structures and their benefits and limitations under particular use cases\n\n• Experience with ETL tools (Informatica)\n\n• Ability to create quality ERD’s (entity-relationship diagrams)\n\n• Excellent writing skills for writing user and system documentation\n\n• AWS Cloud Data Warehousing Technologies\n\n• Experience using core AWS services to build and support data warehouse solutions leveraging AWS architecture best practices (S3, DMS, Glue, Lambda)\n\n• Development/modeling experience with Amazon Redshift\n\n• Experience using the AWS service APIs, AWS CLI, and SDKs to build applications\n\n• Proficiency in developing, deploying, and debugging cloud-based applications using AWS\n\n• Ability to use a CI/CD pipeline to deploy applications on AWS (GitLab, Terraform, DBMaestro)\n\n• Ability to apply a basic understanding of cloud-native applications to write code\n\n• Proficiency writing code for serverless applications\n\n• Ability to write code using AWS security best practices (e.g., not using secret and access keys in the code, instead using IAM roles)\n\n• Ability to author, maintain, and debug code modules on AWS\n\n• Database: AWS Aurora Postgres\n\n• Data Access: AWS Athena\n\n• Data Analytics: AWS Quicksight\n\n• Familiarity working with or knowledge of Alteryx, Collibra, Immuta, Okta a plus.\n\n• Experience with visualization tools (Tableau)\n\n• Experience creating scripts with Python\n\n• Experience working on an Agile team\n\n• Understanding of application lifecycle management\n\n• Understanding of the use of containers in the development process\n\nQualifications\n\n• 5 to 9+ years of experience in data engineering, data science, and software engineering.\n\n• Bachelor’s degree in computer science, Information Systems, or another related field\n\n• Must be a US Citizen or a Green Card holder.\n\nResponsibilities:\n\nDesigns, develops, modifies, tests and automation used to provide data warehouse and business intelligence applications solutions. This includes design, development, architecture recommendations, quality management, metadata and repository creation, trouble-shooting problems and tuning warehouse applications. Develops transition and implementation plans. Recommends changes in development, maintenance and standards.\n\n• Advanced analytical ability and technical skill as well as the ability to provide innovative solutions to technical needs and business requirements\n\n• Ability to exercise independent judgment in making complex business decisions\n\n• Acute attention to detail with a high level of data integrity and accuracy\n\n• Excellent verbal and written communication, with interpersonal skills to work with people at all levels of the organization\n\n• Ability to translate highly technical information into non-technical terms\n\n• Excellent computer skills including Microsoft Office along with various other software applications as needed for the role\n\n• Broad knowledge of the programming tools, concepts, practices, and principles including design, implementation, and testing\n\n• Position requires continuous visual concentration and manual dexterity to operate PC\n\n• Requires prolonged sitting and minimal standing/walking\n\n• Minor lifting and carrying, not likely to exceed ten pounds (laptop + charger)\n\n• May require extended work hours and/or schedule flexibility as unexpected situations and/or workflow dictate\n\n• May require on-call status\n\n• Rare domestic travel including overnight stays may be necessary\n\n• 5 to 9+ years of relevant work experience\n\n• Bachelor’s degree or equivalent experience\n\n• Contributes to the design, development, testing, implementation, and review of complex data warehouse and business intelligence solutions\n\n• Develops all or part of complex data warehouse applications, develops software from established requirements, builds reports and dashboards, plans and coordinates work of lower level programmers to meet delivery commitments, creates prototypes; offers insight on the feasibility of system designs\n\n• Contributes to the design of technology infrastructure and configurations, recommends process improvements\n\n• Reviews complex patches and new versions of data warehouse applications. Implements complex software packages and deploys code\n\n• Key participant in cross-functional team initiatives and process improvement projects\n\nPay range is $79.38/hr - $84.38/hr - with full benefits available, including paid time off, medical/dental/vision/life insurance, 401K, parental leave, and more. Our compensation reflects the cost of labor across several US geographic markets. Pay is based on several factors including market location and may vary depending on job-related knowledge, skills, and experience.\n\nTHE PROMISES WE MAKE:\n\nAt Crystal Equation, we empower people and advance technology initiatives by building trust. Your recruiter will prep you for the interview, obtain feedback, guide you through any necessary paperwork and provide everything you need for a successful start. We will serve to empower you along the way and provide the path for your professional journey.\n\nFor more information regarding our Privacy Policy, please visit crystalequation.com/privacy.",
"job_highlights": [
{
"title": "Qualifications",
"items": [
"Expert in developing and analyzing complex SQL on a variety of RDBMS (Microsoft SQL Server, Oracle)",
"Expert knowledge of data modeling and understanding of different data structures and their benefits and limitations under particular use cases",
"Experience with ETL tools (Informatica)",
"Ability to create quality ERD’s (entity-relationship diagrams)",
"Excellent writing skills for writing user and system documentation",
"AWS Cloud Data Warehousing Technologies",
"Experience using core AWS services to build and support data warehouse solutions leveraging AWS architecture best practices (S3, DMS, Glue, Lambda)",
"Development/modeling experience with Amazon Redshift",
"Experience using the AWS service APIs, AWS CLI, and SDKs to build applications",
"Proficiency in developing, deploying, and debugging cloud-based applications using AWS",
"Ability to use a CI/CD pipeline to deploy applications on AWS (GitLab, Terraform, DBMaestro)",
"Ability to apply a basic understanding of cloud-native applications to write code",
"Proficiency writing code for serverless applications",
"Ability to write code using AWS security best practices (e.g., not using secret and access keys in the code, instead using IAM roles)",
"Ability to author, maintain, and debug code modules on AWS",
"Database: AWS Aurora Postgres",
"Data Access: AWS Athena",
"Data Analytics: AWS Quicksight",
"Experience with visualization tools (Tableau)",
"Experience creating scripts with Python",
"Experience working on an Agile team",
"Understanding of application lifecycle management",
"5 to 9+ years of experience in data engineering, data science, and software engineering",
"Bachelor’s degree in computer science, Information Systems, or another related field",
"Must be a US Citizen or a Green Card holder",
"Advanced analytical ability and technical skill as well as the ability to provide innovative solutions to technical needs and business requirements",
"Ability to exercise independent judgment in making complex business decisions",
"Acute attention to detail with a high level of data integrity and accuracy",
"Excellent verbal and written communication, with interpersonal skills to work with people at all levels of the organization",
"Ability to translate highly technical information into non-technical terms",
"Excellent computer skills including Microsoft Office along with various other software applications as needed for the role",
"Broad knowledge of the programming tools, concepts, practices, and principles including design, implementation, and testing",
"Minor lifting and carrying, not likely to exceed ten pounds (laptop + charger)",
"5 to 9+ years of relevant work experience",
"Bachelor’s degree or equivalent experience",
"Contributes to the design, development, testing, implementation, and review of complex data warehouse and business intelligence solutions",
"Key participant in cross-functional team initiatives and process improvement projects"
]
},
{
"title": "Benefits",
"items": [
"Pay range is $79.38/hr - $84.38/hr - with full benefits available, including paid time off, medical/dental/vision/life insurance, 401K, parental leave, and more",
"Our compensation reflects the cost of labor across several US geographic markets",
"Pay is based on several factors including market location and may vary depending on job-related knowledge, skills, and experience"
]
},
{
"title": "Responsibilities",
"items": [
"Understanding of the use of containers in the development process",
"Designs, develops, modifies, tests and automation used to provide data warehouse and business intelligence applications solutions",
"This includes design, development, architecture recommendations, quality management, metadata and repository creation, trouble-shooting problems and tuning warehouse applications",
"Develops transition and implementation plans",
"Recommends changes in development, maintenance and standards",
"Position requires continuous visual concentration and manual dexterity to operate PC",
"Requires prolonged sitting and minimal standing/walking",
"May require extended work hours and/or schedule flexibility as unexpected situations and/or workflow dictate",
"May require on-call status",
"Rare domestic travel including overnight stays may be necessary",
"Develops all or part of complex data warehouse applications, develops software from established requirements, builds reports and dashboards, plans and coordinates work of lower level programmers to meet delivery commitments, creates prototypes; offers insight on the feasibility of system designs",
"Contributes to the design of technology infrastructure and configurations, recommends process improvements",
"Reviews complex patches and new versions of data warehouse applications",
"Implements complex software packages and deploys code"
]
}
],
"apply_options": [
{
"title": "Crystal Equation",
"link": "https://jobs.crystalequation.com/jb/Data-Engineer-II-Jobs-in-San-Francisco-CA/12173625?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Jobrapido.com",
"link": "https://us.jobrapido.com/jobpreview/4531705987844800512?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
}
],
"job_id": "eyJqb2JfdGl0bGUiOiJEYXRhIEVuZ2luZWVyIC0gSUkiLCJjb21wYW55X25hbWUiOiJDcnlzdGFsIEVxdWF0aW9uIiwiYWRkcmVzc19jaXR5IjoiU2FuIEZyYW5jaXNjbywgQ0EiLCJodGlkb2NpZCI6InJWWnNwdk4zS3VyajA0OEtBQUFBQUE9PSIsImhsIjoiZW4ifQ=="
},
{
"title": "Innovation Team Data Engineer - Mayor's Office of Innovation (1043)",
"company_name": "City and County of San Francisco",
"location": "San Francisco, CA",
"via": "SF Careers - SF.gov",
"share_link": "https://www.google.com/search?ibp=htl;jobs&q=Data+Engineer+jobs+in+San+Francisco&htidocid=RPr_RF-Vin5ZzqkkAAAAAA%3D%3D&hl=en-US&shndl=37&shmd=H4sIAAAAAAAA_1WNuwrCQBBFsfUTrKbzgSY-G60kPlAQC61sZLJOkpU4E3ZW0b_0k1w7bS6Xwz3c-rtWP22Y5YHeCsOR8AYL9AhLzi0TOejBDl_imgr7LLOGQDL4MVqD_njUDqutpKCEzhQQ8FokL6kxK7yvdBrHqmWUqw-OiYzcYmFK5RlfJdVvnLVAR1WJns7DSf8ZVZx3Jon1L0C-QCJ3DjU8H5Bh5ZCNVSNg-R90IZl_APnTBsTTAAAA&shmds=v1_AQbUm94bj57AwEQPboFy0SwifQ19-SEwbiLjSfVyny7Av7pBWg&source=sh/x/job/uv/m5/1#fpstate=tldetail&htivrt=jobs&htidocid=RPr_RF-Vin5ZzqkkAAAAAA%3D%3D&htiq=Data+Engineer+jobs+in+San+Francisco",
"detected_extensions": {},
"job_highlights": [
{
"title": "Qualifications",
"items": [
"Removing barriers and making it easier for all people to access services or knowledge is a core part of any role with DataSF and the Innovation Team",
"Beyond any technical skill set or prior work history, accomplishing this ambitious task requires an empathetic understanding of the diverse array of experiences embodied in San Francisco"
]
},
{
"title": "Benefits",
"items": null
},
{
"title": "Responsibilities",
"items": [
"However, your position is based within Digital Services under DataSF, and will collaborate closely with the Chief Data Officer and the Chief Digital Services Officer",
"You will work directly with the Mayor’s policy staff and Department leadership, as well as community providers to identify existing data, gaps in reporting, and develop outcomes-based reporting structures",
"As a small and agile team, you will work together to deliver prototypes and solutions that will help address the city’s most pressing challenges",
"As the Data Engineer, you will be the technical lead on the program, working with stakeholders in departments to understand data sources and pipelines and building these out in a pragmatic way",
"You will advise the Mayor’s Office on the most feasible deliverables that are both technically possible, and high impact",
"You will be supported throughout by the rest of the Innovation team, the Chief Data Officer, and the Chief Digital Services Officer",
"Work with departmental staff to develop extract, transform, load (ETL) requirements for individual datasets",
"Consult with various departments on the best way to automate and publish datasets within their data ecosystems",
"Apply an ethical lens to the appropriate use of data",
"Create new analytics pipelines using ETL/ELT approaches according to standards and patterns you help develop and refine",
"Serve as the technical lead for database exports, manipulation, and procedures used to create and update data incorporated into the data platform",
"Implement analytics pipelines and/or data models to support analytics work",
"Migrate existing ETLs to newer infrastructure to improve data quality and reliability as needed",
"Standardize and improve existing pipelines to adhere to best practices",
"As needed help iterate and refine best practices",
"You will also identify ways in which data standardization, and data access, can contribute to the City’s commitment to equitable and ethical service delivery and analytics",
"In collaboration with departments, you will identify data gaps that hinder equity analysis"
]
}
],
"apply_options": [
{
"title": "SF Careers - SF.gov",
"link": "https://careers.sf.gov/role/?id=3743990003453766&utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
}
],
"job_id": "eyJqb2JfdGl0bGUiOiJJbm5vdmF0aW9uIFRlYW0gRGF0YSBFbmdpbmVlciAtIE1heW9yJ3MgT2ZmaWNlIG9mIElubm92YXRpb24gKDEwNDMpIiwiY29tcGFueV9uYW1lIjoiQ2l0eSBhbmQgQ291bnR5IG9mIFNhbiBGcmFuY2lzY28iLCJhZGRyZXNzX2NpdHkiOiJTYW4gRnJhbmNpc2NvLCBDQSIsImh0aWRvY2lkIjoiUlByX1JGLVZpbjVaenFra0FBQUFBQT09IiwiaGwiOiJlbiJ9"
},
{
"title": "Experienced Data Engineer - Data Engineering Technical Leader",
"company_name": "Plaid",
"location": "San Francisco, CA",
"via": "Lever",
"share_link": "https://www.google.com/search?ibp=htl;jobs&q=Data+Engineer+jobs+in+San+Francisco&htidocid=RTekcfo2uCb9bvkRAAAAAA%3D%3D&hl=en-US&shndl=37&shmd=H4sIAAAAAAAA_1XKsQrCQAyAYVz7CE6ZRXsiuOgkWgVxEOxe0jTcnZxJudzQt_IVRTeXHz74q_esaptp5BxZiAc4YUFoxEdhzrD6dxQPLVOQSJjgxjj8nqv2YIyZAqjARdUnnu9DKaPtnDNLtbeCJVJN-nIq3OvkntrbN50FzDwmLNxttuupHsUv5veEcYAo8ECBc0ahaKRLOB4-XWRqWLIAAAA&shmds=v1_AQbUm96Xy9FHuLWc3tiiWyW0W25Hjc2POTExTSyEebhQ3CPCEQ&source=sh/x/job/uv/m5/1#fpstate=tldetail&htivrt=jobs&htidocid=RTekcfo2uCb9bvkRAAAAAA%3D%3D&htiq=Data+Engineer+jobs+in+San+Francisco",
"detected_extensions": {
"dental_coverage": true,
"health_insurance": true
},
"job_highlights": [
{
"title": "Qualifications",
"items": [
"10+ years of experience in data engineering, with a proven track record of building scalable data systems and pipelines",
"Experience working with massive datasets (500TB to petabytes) and developing robust data models and pipelines on top of them",
"Lead major data modeling, schema design, and data architecture efforts in past roles",
"Deep appreciation for schema design and the ability to evolve analytics schemas on top of unstructured data",
"Advanced knowledge of SQL as a flexible, extensible tool and experience with modern orchestration tools like DBT, Mode, and Airflow",
"Hands-on experience with performant data warehouses and lakes such as Redshift, Snowflake, and Databricks",
"Building and maintaining both batch and real-time pipelines using technologies like Spark and Kafka",
"Excited about exploring new technologies and building proof-of-concepts that balance technical innovation with user experience and adoption",
"Enjoy getting into the technical details to manage, deploy, and optimize low-level data infrastructure",
"Champion for data privacy and integrity, and always act in the best interest of consumers"
]
},
{
"title": "Benefits",
"items": [
"$204,120 - $360,000 a year",
"Target base salary for this role is between $204,120 and $360,000 per year",
"Additional compensation in the form(s) of equity and/or commission are dependent on the position offered",
"Plaid provides a comprehensive benefit plan, including medical, dental, vision, and 401(k)",
"Pay is based on factors such as (but not limited to) scope and responsibilities of the position, candidate's work experience and skillset, and location",
"Pay and benefits are subject to change at any time, consistent with the terms of any applicable compensation or benefit plans"
]
},
{
"title": "Responsibilities",
"items": [
"Data Engineers heavily leverage SQL and Python to build data workflows that integrate with our Golang applications",
"We use tools like DBT, Airflow, Redshift, Atlan, and Retool to orchestrate data pipelines and define workflows",
"Drive Data Standards and Culture @ Plaid: You will play a high-impact role in defining and promoting data standards and fostering a strong data-driven culture across Plaid",
"Deliver and Scale Golden Datasets: You will own the creation and future iterations of Golden Datasets for all major Plaid data models, driving their adoption across key data use cases to empower teams with reliable and actionable insights",
"Shape Unified Data Architecture: You will collaborate with other data practitioners and leaders to design a unified data architecture and conventions, making data at Plaid more accessible and intuitive",
"You’ll also enhance data exploration tools to enable efficient and effective usage of data across the organization",
"Mentor and Build Technical Excellence: You will mentor junior engineers on the team, providing guidance on designs and implementations",
"You’ll play a key role in fostering a strong technical culture, empowering the team to deliver high-quality, scalable solutions",
"Serving as the primary technical DRI, defining and executing the long-term technical roadmap to build and sustain a data-driven culture at Plaid",
"Working closely with senior leadership and executives to shape Plaid’s data engineering strategy and roadmap, ensuring alignment with the company’s data-focused product goals and overall vision",
"Deep understanding of Plaid's products and strategy in order to inform the design of Golden Datasets, set data usage principles, and ensure data is structured for maximum impact and usability",
"Focus on delivering well-documented datasets with clearly defined quality metrics, uptime guarantees, and demonstrable usefulness",
"Leading critical data engineering projects that foster collaboration across teams, driving innovation and efficiency throughout the company",
"Mentoring engineers, operations, and data practitioners on best practices for data organization",
"Advocating for the adoption of emerging industry tools and practices, evaluating their fit and implementing them at the right time to keep Plaid at the forefront of data engineering",
"Owning core SQL and Python data pipelines that power our data lake and data warehouse, ensuring their reliability, scalability, and efficiency",
"Upholding Plaid’s commitment to data quality and privacy, embedding these principles into every aspect of data work"
]
}
],
"apply_options": [
{
"title": "Lever",
"link": "https://jobs.lever.co/plaid/8537110d-bfcc-4d81-8070-73e31b0a47f8?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Indeed",
"link": "https://www.indeed.com/viewjob?jk=38644af304eebebc&utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Built In San Francisco",
"link": "https://www.builtinsf.com/job/experienced-data-engineer-data-engineering-technical-leader/3669254?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Built In",
"link": "https://builtin.com/job/experienced-data-engineer-data-engineering-technical-leader/3669254?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "ZipRecruiter",
"link": "https://www.ziprecruiter.com/c/Plaid/Job/Experienced-Data-Engineer-Data-Engineering-Technical-Leader/-in-San-Francisco,CA?jid=61d7f9ca17daa8d3&utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Glassdoor",
"link": "https://www.glassdoor.com/job-listing/experienced-data-engineer-data-engineering-technical-leader-plaid-JV_IC1147401_KO0,59_KE60,65.htm?jl=1009558536939&utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "The Org",
"link": "https://theorg.com/org/plaid/jobs/experienced-data-engineer-6a3a6a4?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Local Job Network",
"link": "https://jobs.localjobnetwork.com/job/detail/82020678/SW-Engineering-Technical-Leader-Nexus-HyperFabric-SaaS-QA-Automation?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
}
],
"job_id": "eyJqb2JfdGl0bGUiOiJFeHBlcmllbmNlZCBEYXRhIEVuZ2luZWVyIC0gRGF0YSBFbmdpbmVlcmluZyBUZWNobmljYWwgTGVhZGVyIiwiY29tcGFueV9uYW1lIjoiUGxhaWQiLCJhZGRyZXNzX2NpdHkiOiJTYW4gRnJhbmNpc2NvLCBDQSIsImh0aWRvY2lkIjoiUlRla2NmbzJ1Q2I5YnZrUkFBQUFBQT09IiwiaGwiOiJlbiJ9"
},
{
"title": "Senior Software Engineer, Data Processing and Serving",
"company_name": "Chime",
"location": "San Francisco, CA",
"via": "Chime Careers",
"share_link": "https://www.google.com/search?ibp=htl;jobs&q=Data+Engineer+jobs+in+San+Francisco&htidocid=C36qWU5u49y3E2t-AAAAAA%3D%3D&hl=en-US&shndl=37&shmd=H4sIAAAAAAAA_xXNTQrCMBBAYdz2CF3NWmojghtdSf0BcSHkAGUaxyTSzpRM0N7Ia2o3j2_3iu-iuFniKAmsPPMHE8GJfWSiVMERM8I9iSPVyB6QH2ApvWev4CodKGFyAYThIuJ7Kvch51F3xqj2tdeMObrayWCEqZPJvKTTOa2G_2vsMVO72a6nemS_LJsQB4LIYJHhnJBdVCcVNIcfvuMsp6oAAAA&shmds=v1_AQbUm942-FzVsDhKykLbq-7YGOs8AqxOmBr0-0kA7LKWPCDAzQ&source=sh/x/job/uv/m5/1#fpstate=tldetail&htivrt=jobs&htidocid=C36qWU5u49y3E2t-AAAAAA%3D%3D&htiq=Data+Engineer+jobs+in+San+Francisco",
"detected_extensions": {
"dental_coverage": true,
"paid_time_off": true,
"health_insurance": true
},
"job_highlights": [
{
"title": "Qualifications",
"items": [
"3+ years experience transforming data to governed and lucid datasets",
"3+ years of hands-on experience to build and deploy production-quality data pipelines",
"3+ years of experience working with stakeholders to provide business insights",
"3+ years of experience writing Spark, AWS Glue, EMR, Airflow, Python",
"1+ years of hands-on experience using any MPP database system like Snowflake, AWS Redshift or Teradata",
"Track record of successful partnerships with Analytics, Data Science and DevOps teams",
"Understanding of key metrics for data pipelines and has built solutions to provide visibility to partner teams"
]
},
{
"title": "Benefits",
"items": [
"The base salary offered for this role and level of experience will begin at $176,490 and up to $245,100",
"Full-time employees are also eligible for a bonus, competitive equity package, and benefits",
"The actual base salary offered may be higher, depending on your location, skills, qualifications, and experience",
"🏢 A thoughtful hybrid work policy that combines in-office days and trips to team and company-wide events depending on location to ensure you stay connected to your work and teammates, whether you’re local to one of our offices or remote",
"💻 Hybrid work perks like backup child, elder and/or pet care, as well as a subsidized commuter benefit",
"💰 Competitive salary based on experience",
"✨ 401k match plus great medical, dental, vision, life, and disability benefits",
"🏝 Generous vacation policy and company-wide Chime Days, bonus company-wide paid days off",
"🫂 1% of your time off to support local community organizations of your choice",
"👟 Annual wellness stipend to use towards eligible wellness related expenses",
"👶 Up to 24 weeks of paid parental leave for birthing parents and 12 weeks of paid parental leave for non-birthing parents",
"👪 Access to Maven, a family planning tool, with $15k lifetime reimbursement for egg freezing, fertility treatments, adoption, and more",
"🎉 In-person and virtual events to connect with your fellow Chimers—think cooking classes, guided meditations, music festivals, mixology classes, paint nights, etc., and delicious snack boxes, too!"
]
},
{
"title": "Responsibilities",
"items": [
"As a core member of the team, you will have the opportunity to build scalable data pipelines and frameworks",
"Additionally, you will have the unique opportunity to architect and build workflows that could potentially become de facto standards for the fintech industry",
"Be a hands-on data engineer, building, scaling and optimizing ETL pipelines",
"Design data warehouse schemas and scale data warehouse process data for 10x data growth",
"Ownership of all aspects of data - data quality, data governance, data and schema design, data quality and security",
"Own schema registry and dependency chart for persistent data",
"Own the ETL workflows and make sure the pipeline meets data quality and availability requirements",
"Work closely with partner teams, like Data Science, Analytics and DevOps",
"To thrive in this role, you have"
]
}
],
"apply_options": [
{
"title": "Chime Careers",
"link": "https://careers.chime.com/en/jobs/7842539002/senior-software-engineer-data-processing-and-serving/?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Wellfound",
"link": "https://wellfound.com/jobs/3217399-senior-software-engineer-data-processing-and-serving?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Built In San Francisco",
"link": "https://www.builtinsf.com/job/senior-software-engineer-data-processing-and-serving/4040153?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Built In",
"link": "https://builtin.com/job/senior-software-engineer-data-processing-and-serving/4040153?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Homebrew Job Board",
"link": "https://careers.homebrew.co/companies/chime-2/jobs/45960979-senior-software-engineer-data-processing-and-serving?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "LinkedIn",
"link": "https://www.linkedin.com/jobs/view/senior-software-engineer-data-processing-and-serving-at-chime-4151533476?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Aijobs.net",
"link": "https://aijobs.net/job/1011787-senior-software-engineer-data-processing-and-serving/?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
},
{
"title": "Taro",
"link": "https://www.jointaro.com/jobs/chime/senior-software-engineer-data-processing-and-serving/?utm_campaign=google_jobs_apply&utm_source=google_jobs_apply&utm_medium=organic"
}
],
"job_id": "eyJqb2JfdGl0bGUiOiJTZW5pb3IgU29mdHdhcmUgRW5naW5lZXIsIERhdGEgUHJvY2Vzc2luZyBhbmQgU2VydmluZyIsImNvbXBhbnlfbmFtZSI6IkNoaW1lIiwiYWRkcmVzc19jaXR5IjoiU2FuIEZyYW5jaXNjbywgQ0EiLCJodGlkb2NpZCI6IkMzNnFXVTV1NDl5M0UydC1BQUFBQUE9PSIsImhsIjoiZW4ifQ=="
}
],
"scrapingdog_pagination": {
"next_page_token": "eyJmYyI6IkVvd0VDc3dEUVVFdFMxUm9abWhTYzI5TU1XbFZWRjl0UVhSbE1tUkhSVVpzYUhKMldrRjRNbU5LVFdWb2FXRnZSa3hxYkVwdmRESkdkVU5EYUhCYVkybEtiVlZNYUY5Sk1rTmxRM2RCTW5KbVowUldWakoxTm10dVl5MVRTV1ZVWlRoWU0yUTBWSGMwZGtOSU9Xa3hSbGd3VEV3eGQxSlFOSHBmTkcxSVdESXdTRFpTYUVJM1lVTlRVMlk1ZFZaclEwUnNVRU5UTUhWWVdqSmFTV0owU0ZCamVWSnNWRkZuWjB4TE1FRmFha05OY2t4bmVWRkdZVXRWTFZaQ2MwcGpSemhvTFdkaFVFNDBYMXBrYUU1NldsQmlhRWMzU1MxRWExRlRRM2RuWmtObFRHUk9MV2w0U25kU1dtUmhNelpQZGtjeFRUZGFkRFl0WjIxb01FdDJWMUE1VUd0RFlsQjVSSFF5UVZvNFJsZDZVR3BYTVhKNFExWmxRM0ZqT0hoVmJVNDJhemxWWkdOYVpXWnBWalpsUVhSWFZXeG9jMjAzWlVaMVUzSnBVbU5VVG5KelZUWmpTVUZOVUhKNWNreFRZM0o1UmpGYVpuaHBORE5LUTBRNU9WVkhNRTkwYmxOd2FtTktaMmxSTFY4eFgzZHpabkowY1VsSGNITTVjRzVaWVhoWU5IWmpOR3QyUXpJeVRXRjVUMGxhY0c5V1RUQmZNMHBwVkMxMVZVUkVjVmhDZEROTWNqQjVZMWc1VXpSUVRGTkRRM00yTVRZd1ZIRnJkVmt5YkZoV1JsSkZOVk4xVkdKVFJsaDFaQzFWYlJJWE1HVXpkbG8wZWtoQ2RYRjBhVXhOVUdoTFdGaHpVV3NhSWtGRFJGaE1OR3h3ZHpObE9IRlJlVXN5UWtkQ1pWZGxXa05NTWxrMVRrUnVMVUUiLCJmY3YiOiIzIn0=",
"next": "https://api.scrapingdog.com/google_jobs?query=Data+Engineer+jobs+in+San+Francisco&google_domain=google.com&language=en&next_page_token=eyJmYyI6IkVvd0VDc3dEUVVFdFMxUm9abWhTYzI5TU1XbFZWRjl0UVhSbE1tUkhSVVpzYUhKMldrRjRNbU5LVFdWb2FXRnZSa3hxYkVwdmRESkdkVU5EYUhCYVkybEtiVlZNYUY5Sk1rTmxRM2RCTW5KbVowUldWakoxTm10dVl5MVRTV1ZVWlRoWU0yUTBWSGMwZGtOSU9Xa3hSbGd3VEV3eGQxSlFOSHBmTkcxSVdESXdTRFpTYUVJM1lVTlRVMlk1ZFZaclEwUnNVRU5UTUhWWVdqSmFTV0owU0ZCamVWSnNWRkZuWjB4TE1FRmFha05OY2t4bmVWRkdZVXRWTFZaQ2MwcGpSemhvTFdkaFVFNDBYMXBrYUU1NldsQmlhRWMzU1MxRWExRlRRM2RuWmtObFRHUk9MV2w0U25kU1dtUmhNelpQZGtjeFRUZGFkRFl0WjIxb01FdDJWMUE1VUd0RFlsQjVSSFF5UVZvNFJsZDZVR3BYTVhKNFExWmxRM0ZqT0hoVmJVNDJhemxWWkdOYVpXWnBWalpsUVhSWFZXeG9jMjAzWlVaMVUzSnBVbU5VVG5KelZUWmpTVUZOVUhKNWNreFRZM0o1UmpGYVpuaHBORE5LUTBRNU9WVkhNRTkwYmxOd2FtTktaMmxSTFY4eFgzZHpabkowY1VsSGNITTVjRzVaWVhoWU5IWmpOR3QyUXpJeVRXRjVUMGxhY0c5V1RUQmZNMHBwVkMxMVZVUkVjVmhDZEROTWNqQjVZMWc1VXpSUVRGTkRRM00yTVRZd1ZIRnJkVmt5YkZoV1JsSkZOVk4xVkdKVFJsaDFaQzFWYlJJWE1HVXpkbG8wZWtoQ2RYRjBhVXhOVUdoTFdGaHpVV3NhSWtGRFJGaE1OR3h3ZHpObE9IRlJlVXN5UWtkQ1pWZGxXa05NTWxrMVRrUnVMVUUiLCJmY3YiOiIzIn0=&api_key=APIKEY"
}
} We Streamline Google Jobs Scraping for You
Comprehensive Job Market Insights
Gain a complete overview of job market trends by effortlessly accessing and analyzing millions of Google job postings, helping you make informed hiring decisions.
Competitive Analysis
Monitor and analyze job postings from competitors or industry leaders directly from Google Jobs, empowering your strategic decisions with data-backed insights.
Real-time Job Post Monitoring
Scrape live Google Jobs data to instantly track and respond to new job postings, changes, or removals, enabling proactive hiring and recruiting strategies.
Detailed Job Data Extraction
Extract detailed job information such as roles, salaries, locations, company details, and descriptions from Google Jobs, facilitating precise job matching and data-driven market research.
Use Cases of Scraping data from the Google Job Board
Competitor Hiring Analysis
Analyze the hiring patterns and job trends of your competitors by scraping their latest job postings, revealing insights into their strategic moves and expansion plans.
Academic Research
Collect extensive data from Google Jobs to support research in labor economics, employment trends, industry growth, and job market dynamics.
Employment Trend Forecasting
Detect and forecast emerging employment trends by regularly scraping Google Jobs, allowing proactive adjustment of recruitment or training strategies.
Job Market Reporting
Automate the collection of comprehensive job listings data for market reports, industry analyses, and informative content, streamlining your reporting processes.
Salary Benchmarking
Scraped salary information from job postings to establish accurate salary benchmarks within industries or geographic regions, supporting data-driven compensation strategies.
Regional Job Market Mapping
Map job availability across cities, regions, or countries by scraping geo-specific job listings from Google Jobs, aiding regional economic analysis and targeted workforce planning.
Testimonial
Transparent & Simple Pricing
LITE
$40/month
- 40000 Google Requests
- $1/1k Google Requests
- 5 Concurrency
- No Email Support
STANDARD
$90/month
- 200000 Google Requests
- $0.45/1k Google Requests
- 50 Concurrency
- Email Support
PRO
$200/month
- 600000 Google Requests
- $0.33/1k Google Requests
- 100 Concurrency
- Priority Email Support
Popular
PREMIUM
$350/month
- 1200000 Google Requests
- $0.29/1k Google Requests
- 150 Concurrency
- Priority Email Support
LITE
$33.33/month
- 40000 Google Requests
- $0.83/1k Google Requests
- 5 Concurrency
- No Email Support
STANDARD
$75/month
- 200000 Google Requests
- $0.375/1k Google Requests
- 50 Concurrency
- Email Support
PRO
$166.66/month
- 600000 Google Requests
- $0.277/1k Google Requests
- 100 Concurrency
- Priority Email Support
Popular
PREMIUM
$291.66/month
- 1200000 Google Requests
- $0.24/1k Google Requests
- 150 Concurrency
- Priority Email Support
Need a bigger plan?
Frequently Asked Questions
Yes, the API has a rate limit depending on your chosen subscription plan. For detailed information on request limits and how to manage them efficiently, please refer to documentation or message us on live chat.
Yes, other then the data from search results, we have dedicated APIs for Google Scholar, Google Images, Google Lens etc, You can check them out in the product section in the header section for more info.
Google officially shut down the Jobs API in 2021. You can use third-party providers like Scrapingdog Google Jobs API.
Each API request consumes a certain number of credits based on the dedicated API you’re using.
For example the Google Search API costs 5 credits per request. So, if you make one request to the Google Search API, it will deduct 5 credits from the available credits in your account. The number of credits required per request can vary depending on the specific API you’re using.
You can find more details about the credit usage for each API in the documentation.
