
In this article, we are going to scrape this page. Of course, you can pick any Google query. Before writing the code let’s first see what the page looks like and what data we will parse from it.
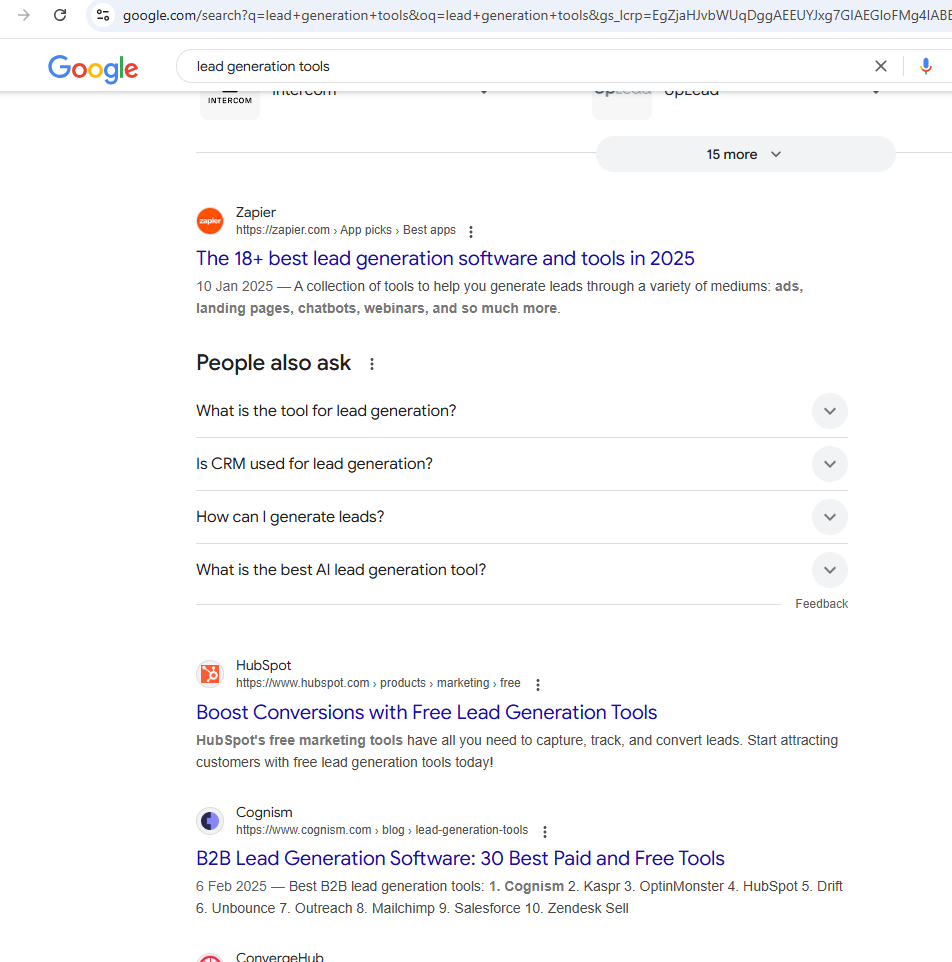
The page will look different in different countries.
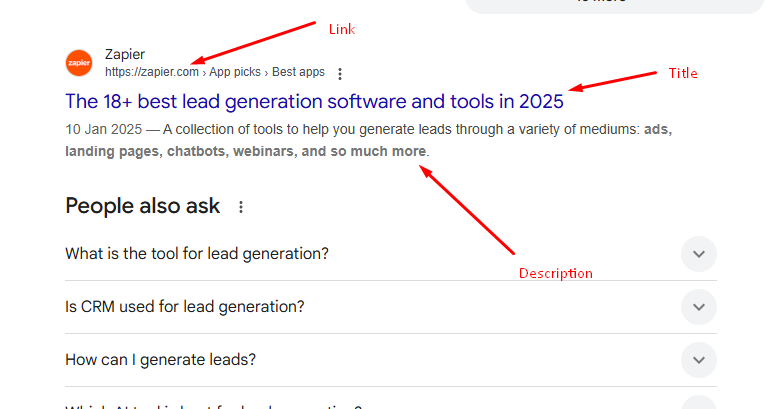
We are going to extract the link, title, and description from the target Google page. Let’s first create a basic Python script that will open the target Google URL and extract the raw HTML from it.
Let me briefly explain the code
- First, we have imported all the required libraries. Here
selenium.webdriveris controlling the web browser andtimeis for sleep function. - Then we have defined the location of our chromedriver.
- Created an instance of
chromedriverand declared a few options. - Then using
.get()function we open the target link. - Using
.sleep()function we are waiting for the page to load completely. - Then finally we extract the HTML data from the page.
Let’s run this code.
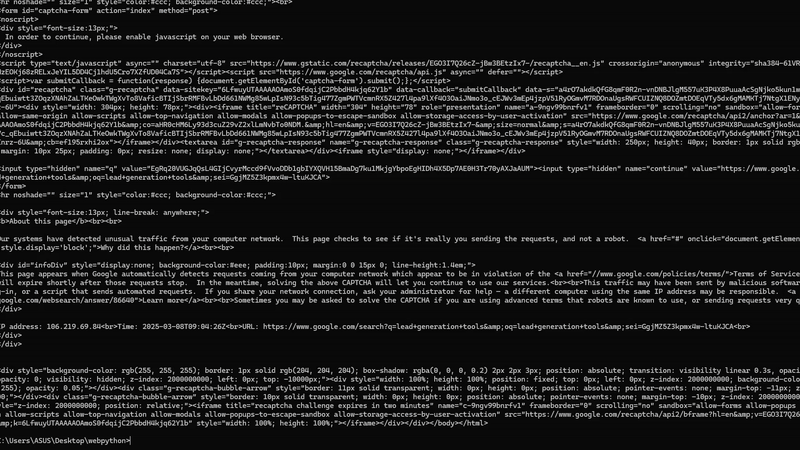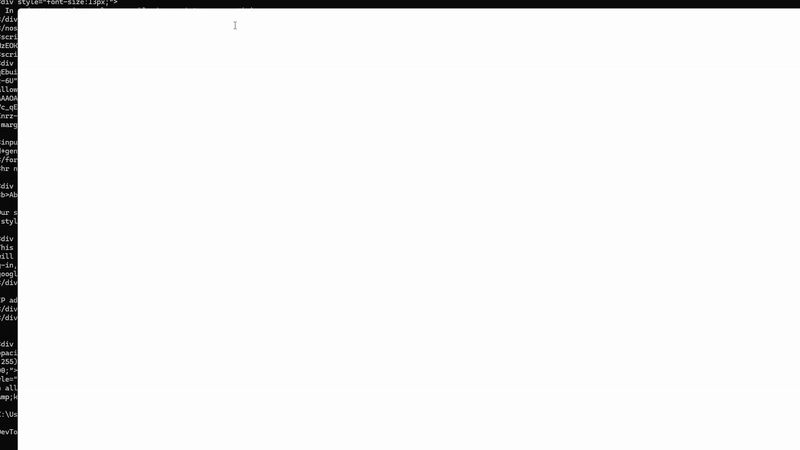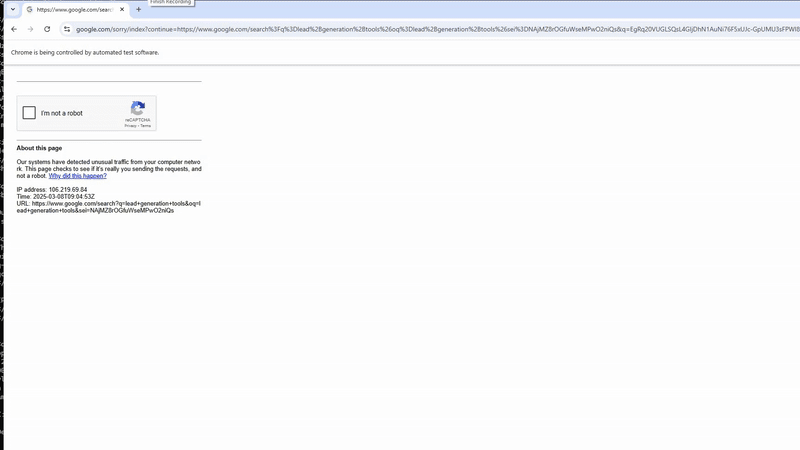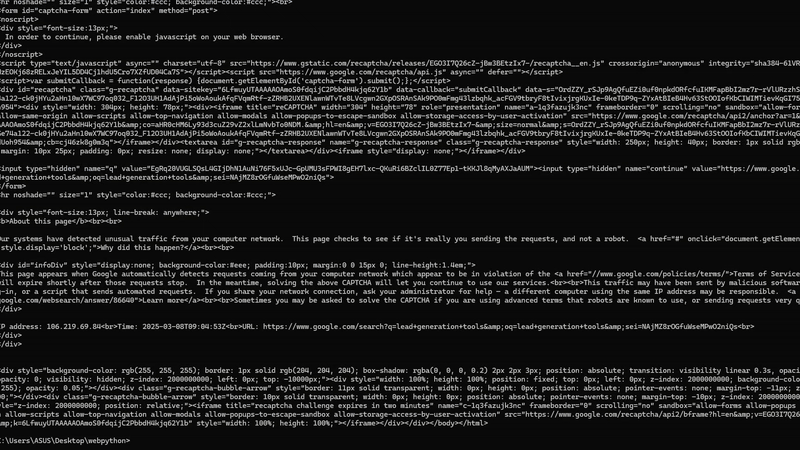
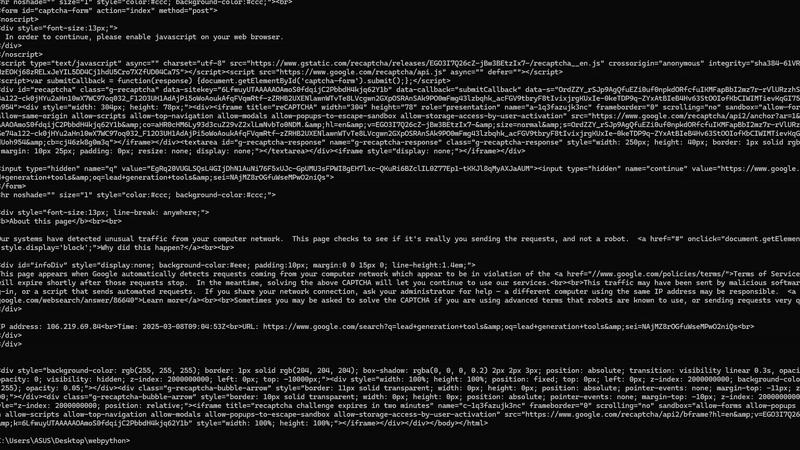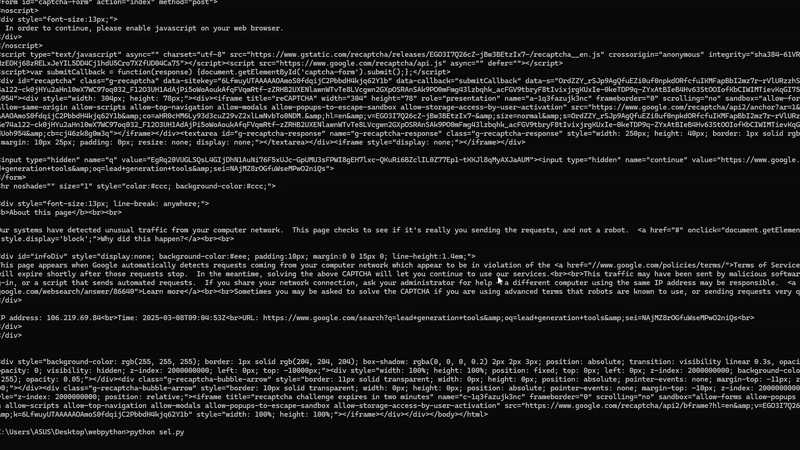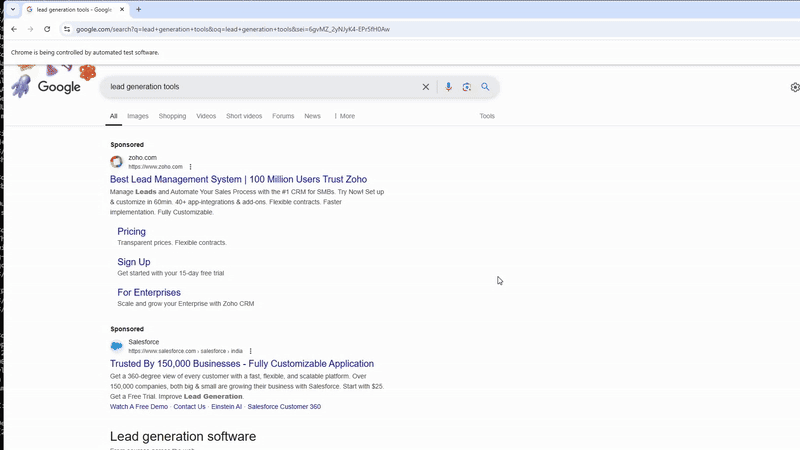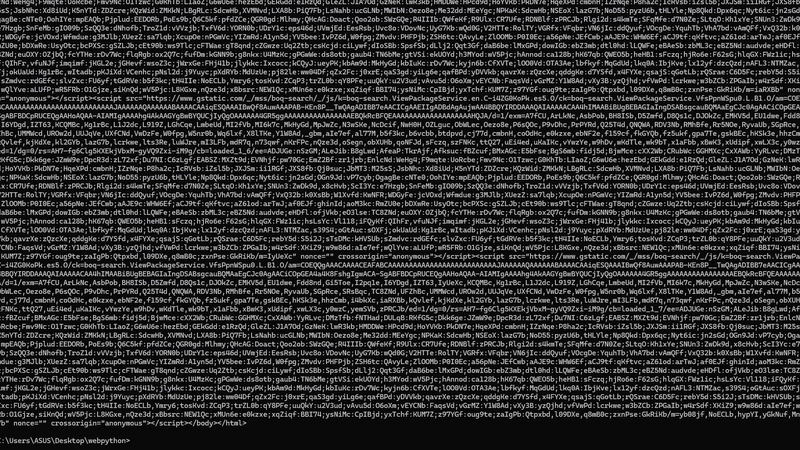
As expected we were able to scrape Google with that argument. Now, let’s parse it.
Before parsing the data we have to find the DOM location of each element.
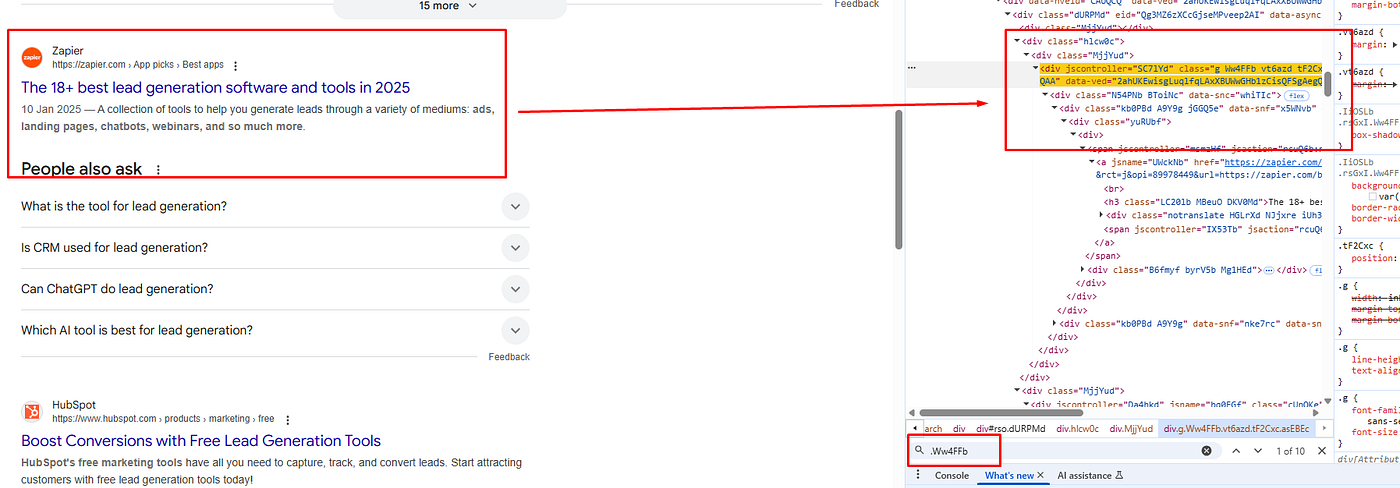
All the organic results have a common class Ww4FFb. All these organic results are inside the div tag with the class dURPMd.

The link is located inside the a tag.

The title is located inside the h3 tag.

The description is located inside the div tag with the class VwiC3b. Let’s code it now.
In the allData variable, we have stored all the organic results present on the page. Then using the for loop we are iterating over all the results. Lastly, we are storing the data inside the object obj and printing it.
Once you run the code you will get a beautiful JSON response like this.
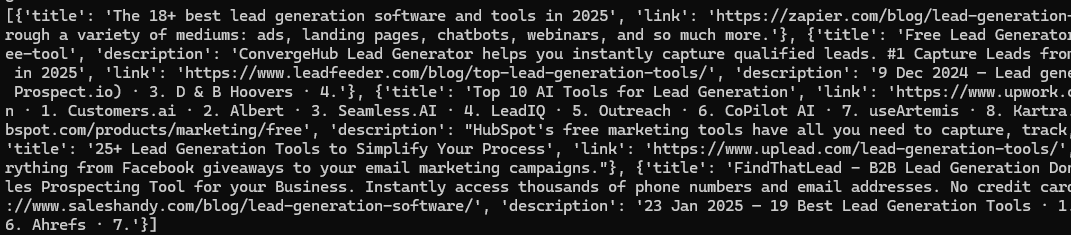
Finally, we were able to scrape Google and parse the data.
Again once you run the code you will find a CSV file inside your working directory.

The code is pretty simple. We are sending a GET request to https://api.scrapingdog.com/google/ along with some parameters. For more information on these parameters, you can again refer to the documentation.
Once you run this code you will get a beautiful JSON response.
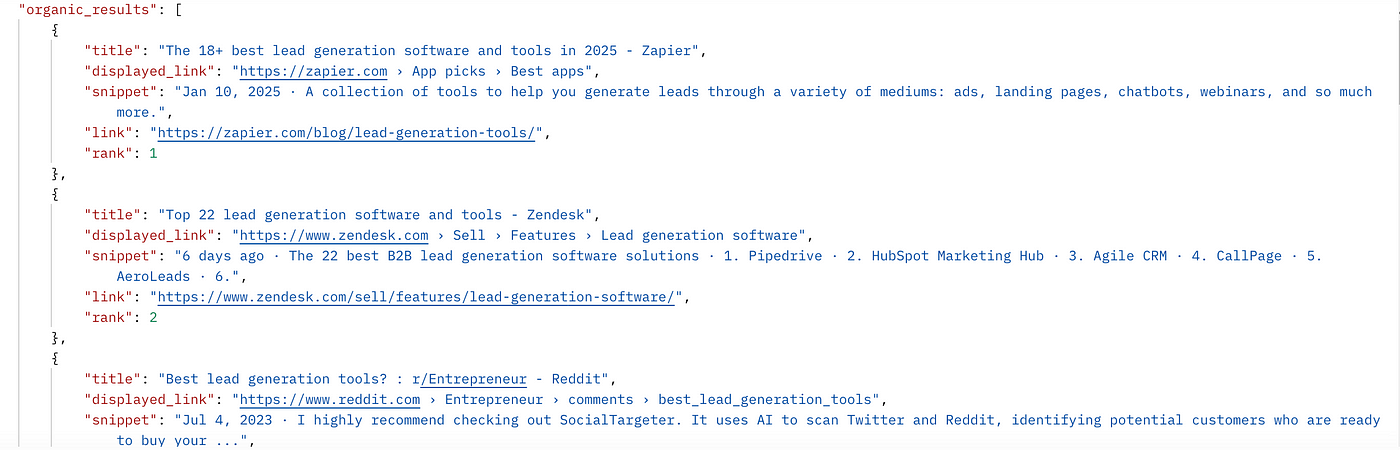
In this JSON response, you will get People also ask for data & related search data as well. So, you are getting full data from Google not just organic results.
What if I need results from a different country?
As you might know, Google shows different results in different countries for the same query. Well, I just have to change the country parameter in the above code.
Let’s say you need results from the United Kingdom. For this, I just have to change the value of the country parameter to gb(ISO code of UK).
You can even extract 100 search results instead of 10 by just changing the value of the results parameter.
Here’s a video tutorial on how to use Scrapingdog’s Google SERP API.⬇️


