
We’ve been covering a few web scraping techniques in this blog via Scrapy. We’ve covered some Javascript web scraping libraries key, among them being puppeteer. Python, one of the most popular programming languages in the data world, has not been left out.
Our walkthrough with BeautifulSoup and selenium Python libraries should get you on your way to becoming a data master.
In this blog post, we’ll be exploring the scrapy library with rotating proxy API and gain an understanding of the need for using these tools.
For this walkthrough, we’ll scrape data from the lonelyplanet which is a travel guide website. Specifically their experiences section. We’ll extract this data and store it in various formats such as JSON, CSV, and XML. The data can then be analyzed and used to plan our next trip!
What’s Scrapy and Why Should I Use It
Scrapy is a fast high-level web crawling and web scraping framework used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
Scrapy lets you crawl websites concurrently without having to deal with threads, processes, synchronization, or anything else. It handles your requests asynchronously, and it is really fast. If you wanted something like this in your custom crawler, you’d have to implement it yourself or use some async library; the best part is it’s open-source!
Let’s build a scrapy captcha solver for our target site to bypass captcha or Recaptcha:
Setup
To get started, we’ll need to install the scrapy library. Remember to separate your python dependencies by using virtual environments. Once you’ve set up a virtual environment and activated it, run:
pip install scrapy
Afterward, head over to the Scrapingdog’s website and get an API key. We’ll need this to access their services. We’ll get to this later on in the walkthrough.
Initializing the project
With the two steps complete, we should be ready to set up the web crawler.
Run the command scrapy startproject projectName
This creates a scrapy project with the project structure
├── scrapy.cfg
└── trips
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
We’ll create a file in the spiders folder and name it destinations.py.This will contain most of the logic for our web scraper.
The source code in the destinations.py file will appear like so:
from scrapy import Request, Spider
from ..items import TripsItem
class DestinationsCrawl(Spider):
name = 'destinations'
items = TripsItem()
allowed_domains = ['lonelyplanet.com']
url_link = f'<https://www.lonelyplanet.com/europe/activities>'
start_urls = [url_link]
def __init__(self, name,continent, **kwargs):
self.continent = continent
super().__init__(name=name, **kwargs)
def start_requests(self):
if self.continent: # taking input from command line parameters
url = f'<https://www.lonelyplanet.com/{self.continent}/activities>'
yield Request(url, self.parse)
else:
for url in self.start_urls:
yield Request(url, dont_filter=True)
def parse(self, response):
experiences = response.css("article.rounded.shadow-md")
items = TripsItem()
for experience in experiences:
items["name"] = experience.css(
'h2.text-xl.leading-tight::text').extract()
items["experience_type"] = experience.css(
'span.mr-4::text').extract()
items["price"] = experience.css("span.text-green::text").extract()
items["duration"] = experience.css(
"p.text-secondary.text-xs::text").extract()
items["description"] = experience.css(
"p.text-sm.leading-relaxed::text").extract()
items[
"link"] = f'https://{self.allowed_domains[0]}{experience.css("a::attr(href)").extract()[0]}'
yield items
The code might look intimidating at first, but don’t worry; we’ll go through it line by line.
The first three lines are library imports and items we’ll need to create a functional web scraper.
from scrapy import Request, Spider
from ..items import TripsItem
Setting up a custom proxy in scrapy
We’ll define a config in the same directory as the destinations.py. This will contain the essential credentials needed to access the rotating proxy service.
So let’s have a look at this file.
# don't keep this in version control, use a tool like python-decouple
# and store sensitive data in .env file
API_KEY='your_scraping_dog_api_key'
This is a file that will host the scraping dog API key. We’ll have to set up a custom middleware in scrapy to allow us to proxy our requests through the rotating proxy pool. From the tree folder structure, we notice there’s a [middlewares.py](<http://middlewares.py>) file. We’ll write our middleware here.
from w3lib.http import basic_auth_header
from .spiders.config import API_KEY
class CustomProxyMiddleware(object):
def process_request(self, request, spider):
request.meta['proxy'] = "<http://proxy.scrapingdog.com:8081>"
request.headers['Proxy-Authorization'] = basic_auth_header('scrapingdog', API_KEY)
Finally, we’ll register the middleware in our settings file.
# Enable or disable downloader middlewares
# See <https://docs.scrapy.org/en/latest/topics/downloader-middleware.html>
DOWNLOADER_MIDDLEWARES = {
'trips.middlewares.CustomProxyMiddleware': 350,
'trips.middlewares.TripsDownloaderMiddleware': 543,
}
With this configuration, all our scraping requests have access to the proxy pool.
Let’s take a deep dive of the destinations.py
class DestinationsCrawl(Spider):
name = 'destinations'
items = TripsItem()
allowed_domains = ['lonelyplanet.com']
url_link = f'<https://www.lonelyplanet.com/europe/activities>'
start_urls = [url_link]
def __init__(self, name,continent, **kwargs):
self.continent = continent
super().__init__(name=name, **kwargs)
def start_requests(self):
if self.continent: # taking input from command line parameters
url = f'<https://www.lonelyplanet.com/{self.continent}/activities>'
yield Request(url, self.parse)
else:
for url in self.start_urls:
yield Request(url,
dont_filter=True)
The DestinationsCrawl class inherits from scrapy’s Spider class. This class will be the blueprint of our web scraper and we’ll specify the logic of the crawler in it.
The name variable specifies the name of our web scraper and the name will be used later when we want to execute the web scraper later on.
The url_linkvariable points to the default URL link we want to scrape. The start_urls variable is a list of default URLs. This list will then be used by the default implementation start_requests() to create the initial requests for our spider. However, we’ll override this method to take in command line arguments to make our web scraper a little more dynamic. By doing so, we can extract data from the various contents that our target site has to offer without needing to write web scrapers for every resource.
Since we’re inheriting from the Spider class, we have access to the start_requests()method. This method returns an iterable of Requests (you can return a list of requests or write a generator function) which the Spider will begin to crawl from. Subsequent requests will be generated successively from these initial requests. In short, all requests start here in scrapy. Bypassing in the continent name in the command line, this variable is captured by the spider’s initializer and we can then use this variable in our target link. Essentially it creates a reusable web scraper.
Remember all our requests are being proxied as the CustomProxyMiddlewareis executed on every request.
Let’s get to the crux of the web crawler, the parse()method.
def parse(self, response):
experiences = response.css("article.rounded.shadow-md")
items = TripsItem()
for experience in experiences:
items["name"] = experience.css(
'h2.text-xl.leading-tight::text').extract()
items["experience_type"] = experience.css(
'span.mr-4::text').extract()
items["price"] = experience.css("span.text-green::text").extract()
items["duration"] = experience.css(
"p.text-secondary.text-xs::text").extract()
items["description"] = experience.css(
"p.text-sm.leading-relaxed::text").extract()
items[
"link"] = f'https://{self.allowed_domains[0]}{experience.css("a::attr(href)").extract()[0]}'
yield items
From Scrapy’s documentation.
The parse method is in charge of processing the response and returning scraped data and/or more URLs to follow.
What this means is that the parse method can manipulate the data received from the target website we want to manipulate. By taking advantage of patterns in the web page’s underlying code, we can gather unstructured data and process and store it in a structured format.
By identifying the patterns in the web page’s code, we can automate data extraction. These are typically HTML elements. So let’s do a quick inspection. We’ll use a browser extension called selectorGadget to quickly identify the HTML elements we need. Optionally, we can use the browser developer tools to inspect elements.
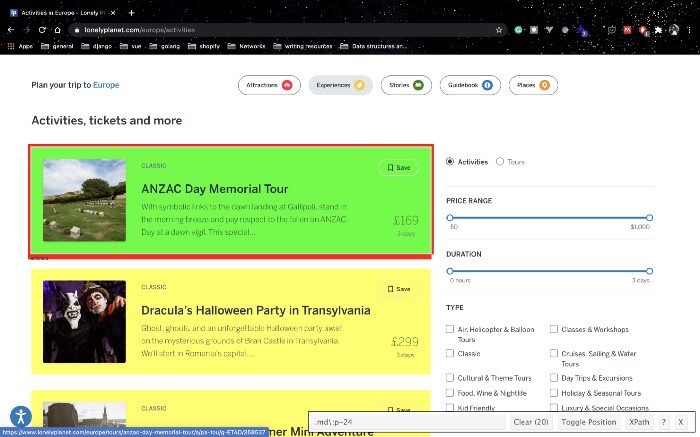
We’ll notice that the destinations contained in the article element of with classes rounded-shadow and shadow-md. Scrapy has some pretty cool CSS selectors that’ll ease the capturing of these targets. Hence, experiences = response.css("article.rounded.shadow-md")it equates to retrieving all the elements that meet these criteria.
We’ll then loop through all the elements extracting additional attributes from their child elements. Such as the name of the trip, type, price, description, and links to their main web page on lonely planet.
Before proceeding, let’s address the TripsItem()class we imported at the beginning of the script.
import scrapy
class TripsItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
experience_type = scrapy.Field()
description = scrapy.Field()
price = scrapy.Field()
duration = scrapy.Field()
link = scrapy.Field()
After successfully crawling the web page, we need to store the data in a structured format. These items objects are containers that collect the scraped data. We map the collected values to these fields, and from the field types in our items object, CSV, JSON, and XML files can be generated. For more information, please check out the scrapy documentation.
Finally, let’s run our crawler. To extract the data in CSV format, we can run
scrapy crawl destinations -a continent=asia -a name=asia -o asia.csv
-a flag means arguments, and these are used in our scraper’s init method, and this feature makes our scraper dynamic. However, one can do without this and can run the crawler as-is since the arguments are optional.
scrapy crawl destinations -o europe.csv
For other file types, we can run:
scrapy crawl destinations -a continent=africa -a name=africa -o africa.json
scrapy crawl destinations -a continent=pacific -a name=pacific -o pacific.xml
With this data, you can now automate your trip planning.
Some websites have a robots.txt which is a file that tells if the website allows scraping or if they do not. Scrapy allows you to ignore these rules by setting ROBOTSTXT_OBEY = Falsein their settings.py file. However, I’d caution against sending excessive requests to a target site while web scraping as it can ruin other people’s user experience on the platform.
Conclusion
Web scraping can be a great way to automate tasks or gather data for analysis. Scrapy and Beat Captcha can make this process easier and more efficient. With a little practice, anyone can learn to use these tools to their advantage.
In this article, we understood how we can scrape data using Python’s scrapy and the rotational proxy service.
Feel free to comment and ask our team anything. Our Twitter DM is welcome for inquiries and general questions.
Thank you for your time.
Additional Resources
And there’s the list! At this point, you should feel comfortable writing your first web scraper to gather data from any website. Here are a few additional resources that you may find helpful during your web scraping journey:
Web Scraping with Scrapingdog


