If you are an investor, a trader, an analyst, or just curious about the overall stock market. You’ve probably already stumbled on Google Finance. It provides up-to-date stock quotes from indexes, historical financial data, news, and currency conversion rates.
Knowing how to scrape the Google Finance website, can be advantageous when it comes to:
- Data Aggregation: Google Finance hosts data from different sources, minimizing the need to look for data elsewhere.
- Sentiment Analysis: The website displays news from several sources. These can be scraped to gather insights about the market’s sentiment.
- Market Predictions: It provides historical data and real-time information from several stock market indexes. Resulting in a very effective source for price predictions.
- Risk Management: Google Finance minimizes arbitrage, thanks to its accurate and up-to-date data, which is crucial for assessing the risk associated with specific investment strategies. For example, this data can be used in developing AML screening solutions to identify suspicious financial activities and ensure compliance with regulatory standards.
Web scraping Google Finance can be achieved using Beautiful Soup and Requests Python’s libraries.
Why Beautiful Soup as the scraping tool?
Beautiful Soup is one of the most used web scraping libraries in Python. It comprises extensive documentation, it’s easy to implement and to integrate with other libraries. To use it, you first need to set your Python’s virtual environment, then you can easily install it using the following command.
pip install beautifulsoup4
pip.
pip install requests
How to extract information from stocks?
To extract stock information from Google Finance, we first need to understand how to play with the website’s URL to
crawl the desired stock. Let’s take for instance the NASDAQ index, which hosts several stocks from where we can grab
information. To have access to the symbols of each stock, we can use NASDAQ’s stock screener in this link. Now let’s take META as our target stock. With both the index and stock we can build the first code snippet of our script.
import requests
from bs4 import BeautifulSoup
BASE_URL = "https://www.google.com/finance"
INDEX = "NASDAQ"
SYMBOL = "META"
LANGUAGE = "en"
TARGET_URL = f"{BASE_URL}/quote/{SYMBOL}:{INDEX}?hl={LANGUAGE}"
TARGET_URL and create a Beautiful Soup instance to crawl the HTML content.
# make an HTTP request
page = requests.get(TARGET_URL)
# use an HTML parser to grab the content from "page"
soup = BeautifulSoup(page.content, "html.parser")
TARGET_URL). 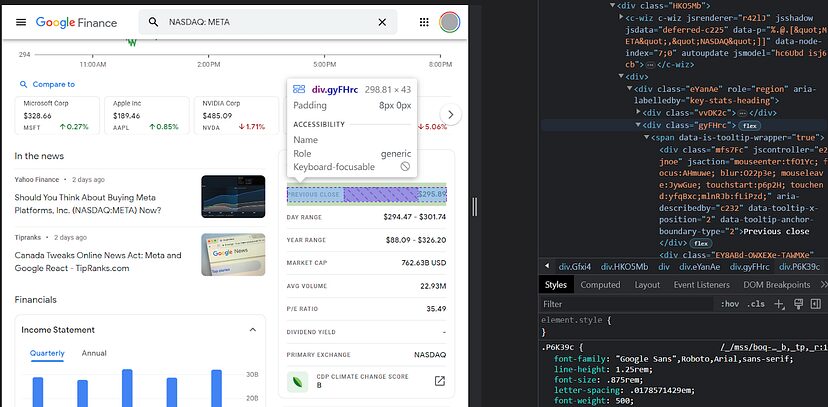
The items that describe the stock are represented by the class gyFHrc. Inside each one of these elements, there’s a class that represents the title of the item (Previous close for instance) and the value ($295.89). The first can be grabbed from the mfs7Fc class, and the second from the P6K39c respectively. The complete list of items to be scraped is the following:
- Previous Close
- Day Range
- Year Range
- Market Cap
- AVG Volume
- P/E Ratio
- Dividend Yield
- Primary Exchange
- CEO
- Founded
- Website
- Employees
Let’s now see how we can crawl these items with Python code.
# get the items that describe the stock
items = soup.find_all("div", {"class": "gyFHrc"})
# create a dictionary to store the stock description
stock_description = {}
# iterate over the items and append them to the dictionary
for item in items:
item_description = item.find("div", {"class": "mfs7Fc"}).text
item_value = item.find("div", {"class": "P6K39c"}).text
stock_description[item_description] = item_value
print(stock_description)
The function .find_all() was used to target all the elements containing the class gyFHrc. Unlike .find_all(), the function .find() only retrieves one element. That’s why it is used inside the for loop because in this case, we know that there’s only one mfs7Fc and P6K39c for each iterable item. The .text() attribute, concatenates all the pieces of text that are inside each element which is the information displayed on the webpage.
The loop in the code snippet above serves to build a dictionary of items that represent the stock. This is a good practice because the dictionary structure can easily be converted to other file formats such as a .json file or a .csv file, depending on the use case.
The output:
{'Previous close': '$295.89', 'Day range': '$294.47 - $301.74', 'Year range': '$88.09 - $326.20', 'Market cap': '762.63B USD', 'Avg Volume': '22.93M', 'P/E ratio': '35.49', 'Dividend yield': '-', 'Primary exchange': 'NASDAQ', 'CEO': 'Mark Zuckerberg', 'Founded': 'Feb 2004', 'Website': 'investor.fb.com', 'Employees': '71,469'}
Complete Code
You can scrape many more data attributes from the page but for now, the complete code will look somewhat like this.
import requests
from bs4 import BeautifulSoup
BASE_URL = "https://www.google.com/finance"
INDEX = "NASDAQ"
SYMBOL = "META"
LANGUAGE = "en"
TARGET_URL = f"{BASE_URL}/quote/{SYMBOL}:{INDEX}?hl={LANGUAGE}"
# make an HTTP request
page = requests.get(TARGET_URL)
# use an HTML parser to grab the content from "page"
soup = BeautifulSoup(page.content, "html.parser")
# get the items that describe the stock
items = soup.find_all("div", {"class": "gyFHrc"})
# create a dictionary to store the stock description
stock_description = {}
# iterate over the items and append them to the dictionary
for item in items:
item_description = item.find("div", {"class": "mfs7Fc"}).text
item_value = item.find("div", {"class": "P6K39c"}).text
stock_description[item_description] = item_value
print(stock_description)
Limitations while scraping Google Finance
Using the above method you can create a small scraper but this scraper will not continue to supply you with data if you are going to do mass scraping. Google is very sensitive to data crawling and it will ultimately block your IP.
Once your IP is blocked you will not be able to scrape anything and your data pipeline will finally break. Now, how to overcome this issue? Well, there is a very easy solution for this and that is to use a Google Scraping API.
Let’s see how we can use this API to crawl limitless data from Google Finance.
Using Scrapingdog for scraping Google Finance
Once you sign up for Scrapindog you will get your API key(available on the dashboard). Now, just copy that API key to the below-provided code.
import requests
from bs4 import BeautifulSoup
BASE_URL = "http://api.scrapingdog.com/google/?api_key=YOUR-API-KEY&query=https://www.google.com/finance"
INDEX = "NASDAQ"
SYMBOL = "META"
LANGUAGE = "en"
TARGET_URL = f"{BASE_URL}/quote/{SYMBOL}:{INDEX}?hl={LANGUAGE}"
# make an HTTP request
page = requests.get(TARGET_URL)
# use an HTML parser to grab the content from "page"
soup = BeautifulSoup(page.content, "html.parser")
# get the items that describe the stock
items = soup.find_all("div", {"class": "gyFHrc"})
# create a dictionary to store the stock description
stock_description = {}
# iterate over the items and append them to the dictionary
for item in items:
item_description = item.find("div", {"class": "mfs7Fc"}).text
item_value = item.find("div", {"class": "P6K39c"}).text
stock_description[item_description] = item_value
print(stock_description)
In place of YOUR-API-KEY you have to paste your API key. One thing you might have noticed is that apart from theBASE_URL nothing has changed in the code. This is the beauty of using the web scraping APIs.
Using this code you can scrape endless Google Finance pages. If you want to crawl this then I would advise you to read web crawling with Python.
Conclusion
With the combination of requests and bs4, we were able to scrape Google Finance. Of course, if the scraper needs to survive then you have to use a proxy scraping APIs.
We have explored the fascinating world of web scraping Google Finance using Python. Throughout this article, we have learned how to harness the power of various Python libraries, such as BeautifulSoup and Requests, to extract valuable financial data from one of the most trusted sources on the internet.
Scraping financial data from Google Finance can be a valuable skill for investors, data analysts, and financial professionals alike. It allows us to access real-time and historical information about stocks, indices, currencies, and more, enabling us to make informed decisions in the world of finance.
I hope you like this tutorial and if you do then please do not forget to share it with your friends and on your social media.
Additional Resources
Web Scraping with Scrapingdog


