
In this article, we will learn web scraping through Rust. This programming language isn’t really popular and is not in much use.
This tutorial will focus on extracting data using this programming language and then I will talk about the advantages and disadvantages of using Rust.
reqwest and scraper. We will talk about these libraries in a bit.
At the end of this tutorial, you will have a basic idea of how Rust works and how it can be used for web scraping. What is Rust?
Rust is a high-level programming language designed by Mozilla. It is built with a main focus on software building. It works great when it comes to low-level memory manipulation like pointers in C and C++.
Concurrent connections are also quite stable in Rust. Multiple software components can run independently and simultaneously without putting too much stress on the server.
Error handling is also top-notch because concurrency errors are compile-time errors instead of run-time errors. This saves time, and a proper message about the error is shown.
This language is also used in game development and blockchain technology. Many big companies, such as AWS and Microsoft, already use it in their architecture.
Setting up The Prerequisites to Web Scrape with Rust
cargo new rust_tutorial
reqwest: It will be used for making an HTTP connection with the host website.scraper: It will be used for selecting DOM elements and parsing HTML.
cargo.toml file.
[dependencies]
reqwest = "0.10.8"
scraper = "0.12.0"
Both 0.10.8 and 0.12.0 are the latest versions of the libraries. Now finally you can access them in your main project file src/main.rs.
What Are We Scraping Using Rust?
It is always better to decide what you want to scrape. We will scrape titles and the prices of the individual books from this page.
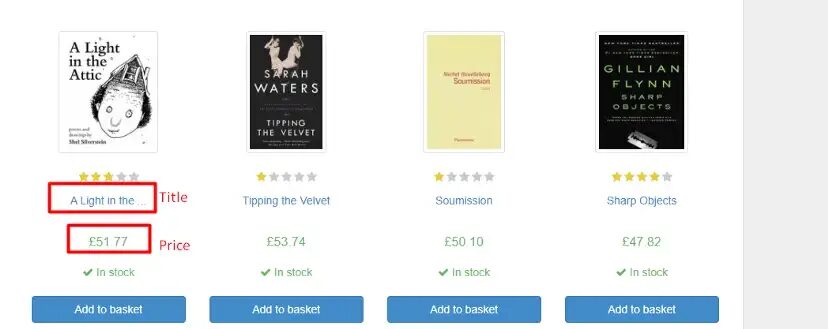
The process will be pretty straightforward. First, we will inspect chrome to identify the exact location of these elements in the DOM, and then we will use scraper library to parse them out.
Scraping Individual Book Data
Let’s scrape book titles and prices in a step-by-step manner. First, you have to identify the DOM element location.

As you can see in the above book title is stored inside the title attribute of a the tag. Now let’s see where is the price stored.

Price is stored under the p tag with class price_color. Now, let’s code it in rust and extract this data.
The first step would be to import all the relevant libraries in the main file src/main.rs.
use reqwest::Client;
use scraper::{Html, Selector};
Using reqwest we are going to make an HTTP connection to the host website and using scraper library we are going to parse the HTML content that we are going to receive by making the GET request through reqwest library.
Now, we have to create a client which can be used for sending connection requests using reqwest.
let client = Client::new();
Then finally we are going to send the GET request to our target URL using the client we just created above.
let mut res = client.get("http://books.toscrape.com/")
.send()
.unwrap();
Here we have used mut modifier to bind the value to the variable. This improves code readability and once you change this value in the future you might have to change other parts of the code as well.
So, once the request is sent you will get a response in HTML format. But you have to extract that HTML string from res variable using .text().unwrap(). .unwrap() is like a try-catch thing where it asks the program to deliver the results and if there is any error it asks the program to stop the execution asap.
let body = res.text().unwrap();
Here res.text().unwrap() will return an HTML string and we are storing that string in the body variable.
Now, we have a string through which we can extract all the data we want. Before we use the scraper library we have to convert this string into an scraper::Html object using Html::parse_document.
let document = Html::parse_document(&body);
Now, this object can be used for selecting elements and navigating to the desired element.
First, let’s create a selector for the book title. We are going to use the Selector::parse function to create a scraper::Selector object.
let book_title_selector = Selector::parse("h3 > a").unwrap();
Now this object can be used for selecting elements from the HTML document. We have passed h3 > a as arguments to the parse function. That is a CSS selector for the elements we are interested in. h3 > a means it is going to select all the a tags which are the children of h3 tags.
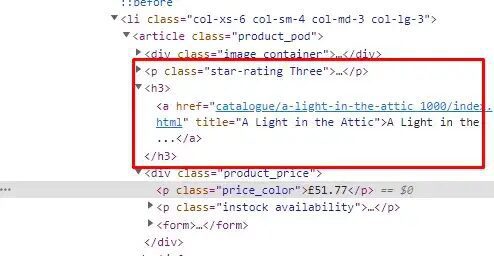
As you can see in the image the target a tag is the child of h3 tag. Due to this, we have used h3 > a in the above code.
Since there are so many books we are going to iterate over all of them using the for loop.
for book_title in document.select(&book_title_selector) {
let title = book_title.text().collect::<Vec<_>>();
println!("Title: {}", title[0]);
}
select method will provide us with a list of elements that matches the selector book_title_selector. Then we are iterating over that list to find the title attribute and finally print it.
Here Vec<_>> represents a dynamically sized array. It is a vector where you can access any element by its position in the vector.
The next and final step is to extract the price.
let book_price_selector = Selector::parse(".price_color").unwrap();
Again we have used Selector::parse function to create the scraper::Selector object. As discussed above price is stored under the price_color class. So, we have passed this as a CSS selector to the parse function.
Then again we are going to use for loop like we did above to iterate over all the price elements.
for book_price in document.select(&book_price_selector) {
let price = book_price.text().collect::<Vec<_>>();
println!("Price: {}", price[0]);
}
Once you find the match of the selector it will get the text and print it on the console.
Finally, we have completed the code which can extract the title and the price from the target URL. Now, once you save this and run the code using cargo run you will get output that looks something like this.
Title: A Light in the Attic
Price: £51.77
Title: Tipping the Velvet
Price: £53.74
Title: Soumission
Price: £50.10
Title: Sharp Objects
Price: £47.82
Title: Sapiens: A Brief History of Humankind
Price: £54.23
Title: The Requiem Red
Price: £22.65
Title: The Dirty Little Secrets of Getting Your Dream Job
Price: £33.34
Title: The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull
Price: £17.93
Title: The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics
Price: £22.60
Title: The Black Maria
Price: £52.15
Complete Code
You can make more changes to the code to extract other information like star ratings of books etc. You can use the same technique of first inspecting and finding the location of the element and then extracting them using the Selector function.
But for now, the code will look like this.
use reqwest::Client;
use scraper::{Html, Selector};
// Create a new client
let client = Client::new();
// Send a GET request to the website
let mut res = client.get("http://books.toscrape.com/")
.send()
.unwrap();
// Extract the HTML from the response
let body = res.text().unwrap();
// Parse the HTML into a document
let document = Html::parse_document(&body);
// Create a selector for the book titles
let book_title_selector = Selector::parse("h3 > a").unwrap();
// Iterate over the book titles
for book_title in document.select(&book_title_selector) {
let title = book_title.text().collect::<Vec<_>>();
println!("Title: {}", title[0]);
}
// Create a selector for the book prices
let book_price_selector = Selector::parse(".price_color").unwrap();
// Iterate over the book prices
for book_price in document.select(&book_price_selector) {
let price = book_price.text().collect::<Vec<_>>();
println!("Price: {}", price[0]);
}
Advantages of using Rust
- Rust is an efficient programming language like C++. You can build heavy-duty games and Software using it.
- It can handle a high volume of concurrent calls, unlike Python.
- Rust can even interact with languages like C and Python.
Disadvantages of using Rust
- Rust is a new language if we compare it to Nodejs and Python. Due to the small community, it becomes very difficult for a beginner to resolve even a small error.
- Rust syntax is not that easy to understand as compared to Python or Nodejs. So, it becomes very difficult to read and understand the code.
Conclusion
We learned how Rust can be used for web scraping purposes. Using Rust you can scrape other dynamic websites as well. Even in the above code, you can make a few more changes to scrape images and ratings. This will surely improve your web scraping skills with Rust.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on your social media.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:
Web Scraping with Scrapingdog



