
TL;DR
- Java scraping basics with three libraries:
HtmlUnit(headless client),Jsoup(HTML parser),WebMagic(crawler). - Example: scrape the Scrapingdog blog and print post titles.
- Includes setup / deps and step-by-step for each, plus troubleshooting (proxies, Fiddler / Wireshark).
- Conclusion: all open-source;
WebMagicscales; GitHub code link included.
Java is one of the most widely used programming languages in the world, and for good reason. It’s fast, scalable, and has a mature ecosystem of libraries that make it well-suited for building robust web scrapers and data pipelines. If you’re looking to do web scraping with Java, you’re in the right place.
In this tutorial, we’ll walk you through how to scrape a website using Java, from setting up your project to extracting real data from a live webpage. We’ll cover three of the best Java web scraping libraries available today: Jsoup, HtmlUnit, and WebMagic, and help you understand when to use each one.
By the end of this guide, you’ll be able to:
- Set up a Java project with Maven for web scraping
- Send HTTP requests and parse HTML using Jsoup
- Handle JavaScript-heavy pages with HtmlUnit
- Build a scalable multi-page crawler with WebMagic
- Extract, clean, and print structured data from a real website
Whether you’re a Java developer just getting started with web scraping or looking to level up from basic HTTP calls to a full crawler, this guide has you covered.
Why Use Java for Web Scraping?
Before we dive into the code, it’s worth asking, why choose Java over Python for web scraping?
Python is often the first choice for scraping because of its simplicity, but Java has some real advantages depending on your use case. Java is significantly faster at processing large volumes of data, making it a strong choice for enterprise-scale scraping pipelines. It also integrates naturally into existing Java-based backend systems, so if your data pipeline already runs on the JVM, adding a Java scraper requires no additional infrastructure. And with libraries like WebMagic, you can build distributed, multi-threaded crawlers that would require considerably more setup in Python.
That said, if you’re hitting a website with strong anti-bot protection, no library alone will fully protect you. We’ll cover how to handle that later in this guide, and when it makes sense to use a dedicated scraping API like Scrapingdog instead.
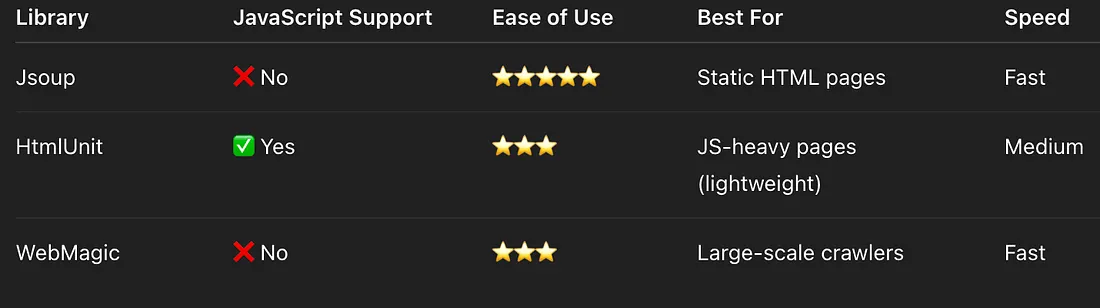
Which Java Library Should You Use for Web Scraping?
Before we dive into each library in detail, here’s a quick overview of all 3 libraries we’ll cover, so you can jump directly to the one that fits your use case.
Prerequisite
Before we start writing code, make sure you have the following installed:
- Java JDK 11 or higher — Download from Oracle or use OpenJDK
- Apache Maven — for dependency management (installation guide)
- An IDE — IntelliJ IDEA or Eclipse works great; VS Code with the Java extension pack also works
Once you have these set up, create a new Maven project. You’ll be adding library-specific dependencies to your pom.xml as we go through each section.
Web Scraping with Java
We are going to scrape the Scrapingdog blog page. We shall obtain the header text from the blog list. After fetching this list, we shall proceed to output it in our program.
Before you scrape a website, you must understand the structure of the underlying HTML. Understanding this structure gives you an idea of how to traverse the HTML tags as you implement your scraper.
In your browser, right-click above any element on the blog list. From the menu that will be displayed, select” Inspect Element.” Optionally, you can press Ctrl + Shift + I to inspect a web page. The list below shows the list elements as they occur repetitively on this page.
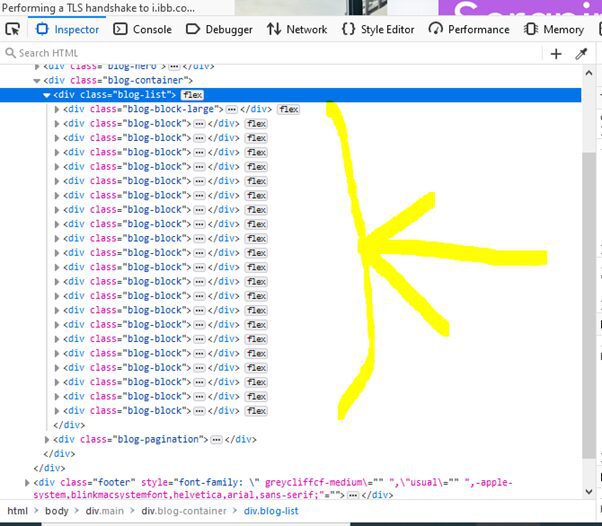
The image below shows the structuring of a single blog list div element. Our point of interest is the <h2> tag that contains the blog title. To access the h2 tag, we will have to use the following CSS querydiv.blog-content div.blog-header a h2.
This tutorial assumes you have basic knowledge of Java and dependency Management in Maven/Gradle.
Web Scraping Using HTMLUnit
Dependencies
HtmlUnit is a GUI-less Java library for accessing websites. It is an open-source framework with 21+ contributors actively participating in its development. To use HtmlUnit, you can download it from Sourceforge, or add it as a dependency in your pom.xml. Add the following dependency code to your maven-based project.
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.48.0</version>
</dependency>
Moreover, you have to add the following code to your pom.xml repositories section.
<repositories>
<repository>
<id>sonatype-nexus-snapshots</id>
<url>https://oss.sonatype.org/content/repositories/snapshots</url>
</repository>
</repositories>
Procedure
The base URL that we shall be scraping is ’https://scrapingdog.com/blog/‘
1. First, we are going to define a web client that we are going to use. HtmlUnit enables you to simulate a web client of your choice, such as Chrome, Mozilla, Safari, etc. In this case, we shall choose Chrome.
//create a chrome web client
WebClient chromeWebClient = new WebClient(BrowserVersion.CHROME);
2. Next, we shall set up configurations for the web client. Defining some of the configurations optimizes the speed of scraping.
This line makes it possible for the web client to use insecure SSL
chromeWebClient.getOptions().setUseInsecureSSL(true);
Next, we disable JavaScript exceptions that may arise while scraping the site.
chromeWebClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
chromeWebClient.getOptions().setThrowExceptionOnScriptError(false);
We will also disable CSS. This optimizes and speeds up the scraping process.
chromeWebClient.getOptions().setCssEnabled(false);
3. After configuring the web client, we are now going to fetch the HTML page. In our case, we are going to fetch https://scrapingdog.com/blog/.
// Fetch the blog page
HtmlPage htmlPage = chromeWebClient.getPage("https://scrapingdog.com/blog/");
4. Fetch the DOM Elements of interest using CSS queries. When selecting elements in CSS, we use selectors. Selector references are used to access DOM elements in the page for styling.
As we had previously concluded, the selector reference that will give us access to the blog titles in the list is div.blog-header a h2.
Using HtmlUnit we shall select all the elements and store them in a DomNodeList.
//fetch the given elements using CSS query selector
DomNodeList<DomNode> blogHeadings = htmlPage.querySelectorAll("div.blog-header a h2");
5. Since the individual elements are contained in a DomNode data structure, we shall iterate through the DomNodeList printing out the output of the process.
//loop through the headings printing out the content
for (DomNode domNode : blogHeadings) {
System.out.println(domNode.asText());
}
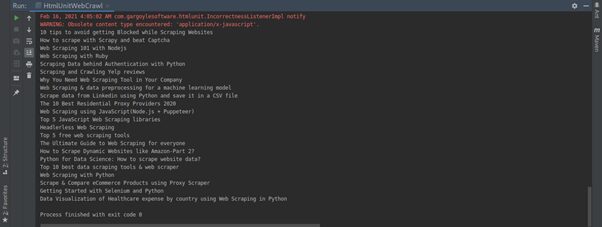
Complete Code
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.util.UrlUtils;
import com.gargoylesoftware.htmlunit.xml.XmlPage;
import com.gargoylesoftware.htmlunit.html.DomNode;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
public class ScrapingdogScraper {
public static void main(String[] args) throws Exception {
// Initialize the WebClient with Chrome browser version
WebClient chromeWebClient = new WebClient(BrowserVersion.CHROME);
// Configure client options
chromeWebClient.getOptions().setUseInsecureSSL(true);
chromeWebClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
chromeWebClient.getOptions().setThrowExceptionOnScriptError(false);
chromeWebClient.getOptions().setCssEnabled(false);
// Fetch the Scrapingdog blog page
HtmlPage htmlPage = chromeWebClient.getPage("https://scrapingdog.com/blog/");
// Select all blog heading elements using a CSS selector
DomNodeList<DomNode> blogHeadings = htmlPage.querySelectorAll("div.blog-header a h2");
// Iterate over the headings and print each title
for (DomNode domNode : blogHeadings) {
System.out.println(domNode.asText());
}
// Close the client to free up resources
chromeWebClient.close();
}
}
Using JSOUP Java Html Parser To Web Scrape
JSOUP is an open-source Java HTML parser for working with HTML. It provides an extensive set of APIs for fetching and manipulating fetched data using DOM methods and Query selectors. JSOUP has an active community of 88+ contributors on GitHub.
Dependencies
To use Jsoup, you will have to add its dependency in your pom.xml file.
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
Procedure
1. Firstly, we will fetch the web page of choice and store it as a Document data type.
// Fetch the web page
Document page = Jsoup.connect("https://scrapingdog.com/blog/").get();
2. Select the individual page elements using a CSS query selector. We shall select these elements from the page (Document) that we had previously defined.
//selecting the blog headers from the page using CSS query
Elements pageElements = page.select("div.blog-header a h2");
3. Declare an ArrayList to store the blog headings.
//ArrayList to store the blog headings
ArrayList<String> blogHeadings = new ArrayList<>();
4. Create an enhanced for loop to iterate through the fetched elements, pageElements, storing them in the array list.
for (Element e : pageElements) {
blogHeadings.add("Heading: " + e.text());
}
5. Finally, print the contents of the array list.
//print out the array list
for (String s : blogHeadings) {
System.out.println(s);
}
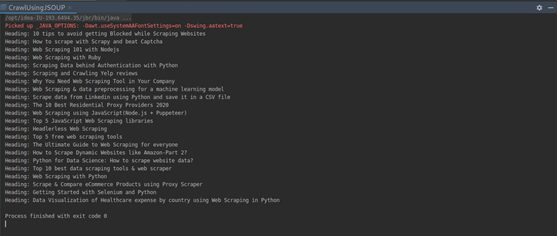
Complete Code
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.io.IOException;
public class JsoupScraper {
public static void main(String[] args) {
try {
// Fetch the Scrapingdog blog page
Document page = Jsoup.connect("https://scrapingdog.com/blog/").get();
// Select all blog heading elements using a CSS selector
Elements pageElements = page.select("div.blog-header a h2");
// Initialize a list to store the extracted headings
ArrayList<String> blogHeadings = new ArrayList<>();
// Iterate over the elements and add each title to the list
for (Element e : pageElements) {
blogHeadings.add("Heading: " + e.text());
}
// Print each heading to the console
for (String s : blogHeadings) {
System.out.println(s);
}
} catch (IOException e) {
System.err.println("Error fetching the page: " + e.getMessage());
}
}
}
Web scraping with Webmagic
Webmagic is an open-source, scalable crawler framework developed by code craft. The framework boasts developer support of 40+ contributors — the developers based this framework on Scrapy architecture, Scrapy is a Python scraping library. Moreover, the team has based several features on Jsoup library.
Dependencies
Add the following dependencies to your pom.xml to include WebMagic in your project. WebMagic is split into two modules — webmagic-core which provides the core scraping framework, and webmagic-extension which adds additional utilities such as annotation-based configuration and pipeline support:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.4</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.4</version>
</dependency>
In case you have customized your Simple Logging Facade for Java (SLF4J) implementation, you need to add the following exclusions in your pom.xml.
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.4</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
Procedure
1. WebMagic works a little differently from the libraries we’ve covered so far. Rather than writing a standalone procedural script, you need to implement WebMagic’s PageProcessor interface in your class. This interface is responsible for defining how the fetched page should be processed, including what data to extract and which links to follow. Once implemented, WebMagic’s internal crawler engine takes care of fetching, scheduling, and pipeline management for you.
// Implement PageProcessor
public class WebMagicCrawler implements PageProcessor {
@Override
public void process(Page page) {
// Define data extraction logic here
}
@Override
public Site getSite() {
// Return site configuration here
}
}
The WebMagicCrawler class implements the PageProcessor interface, which requires you to override two methods — process(), which defines the extraction logic for each fetched page, and getSite(), which returns the site configuration such as retry times, sleep time, and encoding:
2. We define a Site configuration object that tells WebMagic how to handle retries and the delay between requests. Here we set the scraper to retry failed requests up to 3 times, with a 1000ms (1 second) pause between each request to avoid overwhelming the target server:
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
3. After declaring the Site variable, in the overridden getSite() method, add the following piece of code. This makes the method return the previously defined class variable, site.
@Override
public Site getSite() {
return site;
}
4. In the processPage() method, we shall fetch the choice elements and store them in a List.
//fetch all blog headings storing them in a list
List<String> rs = page.getHtml().css("div.blog-header a h2").all();
5. Like in the previous library implementations, we shall print out the contents from our web scraping process by iterating through the string list.
//loop through the list printing out its contents
for (String s : rs) {
System.out.println("Heading: " + s);
}
6. Finally, we bootstrap the crawler using WebMagic’s Spider class. We pass in an instance of our WebMagicCrawler, specify the target URL, and configure it to run across 5 concurrent threads:
//define the url to scrape
// Runs the crawler across 5 concurrent threads
Spider.create(new WebMagicCrawler())
.addUrl("https://scrapingdog.com/blog/")
.thread(5)
.run();
In the above code, we define the URL to scrape by creating an instance of our class. Moreover, the instance runs in a separate thread.
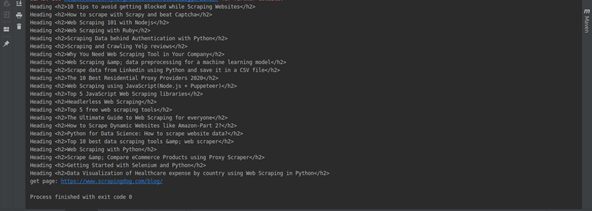
Complete Code
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.util.List;
public class WebMagicCrawler implements PageProcessor {
// Configure site settings: 3 retries and a 1 second delay between requests
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
@Override
public void process(Page page) {
// Select all blog heading elements using a CSS selector
List<String> rs = page.getHtml().css("div.blog-header a h2").all();
// Iterate over the extracted headings and print each to the console
for (String s : rs) {
System.out.println("Heading: " + s);
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
// Bootstrap the crawler with 5 concurrent threads
Spider.create(new WebMagicCrawler())
.addUrl("https://scrapingdog.com/blog/")
.thread(5)
.run();
}
}
Limitations of this approach
The three libraries covered in this tutorial are excellent starting points for web scraping with Java. But once you move beyond simple, static pages, you’ll run into a set of problems that no library alone can solve.
No JavaScript support. Jsoup and WebMagic fetch raw HTML only; they don’t execute JavaScript. Any website that loads content dynamically (Amazon product listings, LinkedIn profiles, React or Vue apps) will return an empty or incomplete response. HtmlUnit attempts to handle this but it frequently breaks on modern JavaScript frameworks and is too slow for any meaningful scale.
IP blocks and rate limiting. When you scrape at scale, websites will start blocking your requests. They detect repeated calls from the same IP and respond with 403 errors, CAPTCHAs, or silent honeypot traps. Building and maintaining a rotating proxy pool yourself is significant engineering work that has nothing to do with the data you’re actually trying to collect.
Bot detection and fingerprinting. Modern websites use tools like Cloudflare, Akamai, and Imperva that analyze browser fingerprints, TLS signatures, and request headers. A vanilla Jsoup or HtmlUnit request fails these checks immediately, and they simply don’t look like a real browser.
Ongoing maintenance. Websites change their HTML structure regularly. A scraper that works today may break next week when a site updates its CSS classes or migrates to a JavaScript-rendered layout.
When to Use Scrapingdog Instead
If any of the above apply to your use case, Scrapingdog’s Data Extraction API is the practical solution. It handles JavaScript rendering, proxy rotation, and bot detection bypass automatically. You just need to send a URL, and you get back clean HTML. No proxy management, no fingerprint tuning, no maintenance overhead.
And the best part is you can still use Jsoup for parsing. Scrapingdog handles the fetch, Jsoup handles the extraction:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLEncoder;
public class ScrapingdogExample {
public static void main(String[] args) throws Exception {
String apiKey = "YOUR_API_KEY";
String targetUrl = "https://www.amazon.com/dp/B09V3KXJPB";
String requestUrl = "https://api.scrapingdog.com/scrape?api_key="
+ apiKey
+ "&url=" + URLEncoder.encode(targetUrl, "UTF-8")
+ "&dynamic=true"; // true for JS-rendered pages
URL url = new URL(requestUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
BufferedReader in = new BufferedReader(
new InputStreamReader(conn.getInputStream())
);
StringBuilder rawHtml = new StringBuilder();
String line;
while ((line = in.readLine()) != null) {
rawHtml.append(line);
}
in.close();
// Pass rendered HTML into Jsoup for parsing as normal
Document doc = Jsoup.parse(rawHtml.toString());
Elements title = doc.select("span#productTitle");
System.out.println(title.text());
}
}
Key Takeaways:
- The guide introduces the basics of web scraping using Java, helping you fetch and parse webpage content programmatically.
- It shows how to set up a Java project and use libraries like Jsoup to send HTTP requests and handle HTML responses.
- You learn how to select and extract data from page elements (e.g., titles, links, text) using DOM selectors.
- The tutorial explains how to loop through multiple pages or items to build larger datasets.
- It emphasizes best practices like respecting robots.txt, adding delays between requests, and handling errors gracefully.
Conclusion
In this tutorial, we guided you through developing a basic web scraper in Java. To avoid reinventing the wheel, there are several scraping libraries that you can use or customize to build your own web scraper. In this tutorial, we developed the scrapers based on the three top Java web scraping libraries.
All of these libraries are feature-rich, boasting sizeable active community support. Moreover, they are all open source as well. Webmagic happens to be extremely scalable. If you would access the source code for this tutorial, you can follow this link to Github.
If you want to learn more about web scraping with Java, I recommend checking out the following resources:
– The Jsoup website: https://jsoup.org/
– The HtmlUnit website: http://htmlunit.sourceforge.net/
Frequently Asked Questions
Can you web scrape with Java?
Of course, there are many Java libraries that can be used in web scraping. JSoup and HtmlUnit are mostly used libraries for web scraping with Java.
Is Python or Java better for web scraping?
Python is more versatile language and hence is better for web scraping. Scraping simple website with a simple HTTP request is very easy with Python.
Is Python easier than Java?
Java and Python are both most popular programming languages. Java is faster but Python is easier and simpler. To tell which one is better all together depends on how you are using them.
Additional Resources
And there’s the list! At this point, you should feel comfortable writing your first web scraper to gather data from any website using Java. Here are a few additional resources that you may find helpful during your web scraping journey:


