
Today with a lot of web data out there, finding and organizing the desired data is tough. That’s where web crawlers come in. These are tools that go through the internet to find and collect data for us like the ones search engines use to know what’s on the web.
JavaScript, a prevalent programming language, especially with Node.js, makes building these web crawlers easier and more effective.
Setting Up the Environment
Before you start to build a JavaScript web crawler, you need to set up a few things on your system. For starters, you will need to have Node.js and npm set up locally to create and develop the project.
Once you have these in place, you can start by creating a new project. Run the following commands to create a new directory for your project and initialize a new Node.js project in it:
mkdir js-crawler
cd js-crawler
npm init -y
Once the NPM project is initialized, you can now start by creating a new file named app.js in the project directory. This is where you will write the code for the JavaScript web crawler.
Before you start to write the code, you should install two key dependencies you will use for this tutorial: Axios for HTTP requests and Cheerio for HTML parsing. You can do that by running the following command:
npm install axios cheerio
Crawling Basics
In this section, you will learn how to set up a Node.js script that crawls through all the pages under the scraping sandbox https://quotes.toscrape.com/.
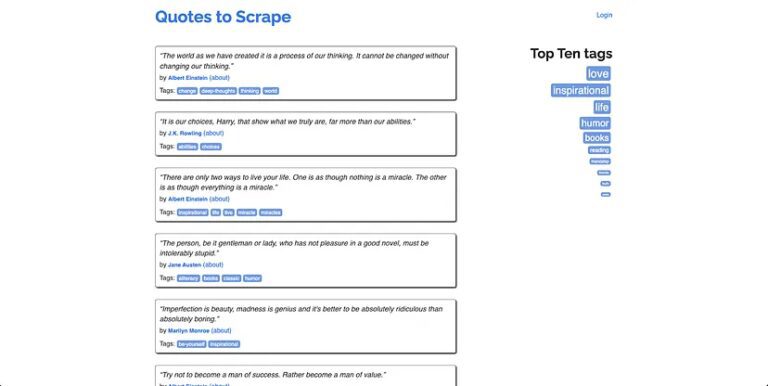
This page lists quotes from famous people and links to their about pages. There are multiple quotes from the same people, so you will learn how to handle duplicate links and there is a link to the source of the quotes (GoodReads) as well to help you understand how to handle external links.
Here’s what the homepage looks like:
Fetching a Web Page
const axios = require("axios")
const baseURL = "https://quotes.toscrape.com"
function main() {
const pageHTML = await axios.get(baseURL + "/")
}
main()
This will retrieve the HTML of the page at https://quotes.toscrape.com/ and store it in pageHTML. You can now use Cheerio to traverse through the DOM and extract the data that you need. To initialize Cheerio with the HTML of the quotes page update the code in app.js to look like the following:
const axios = require("axios")
// Add the import for Cheerio
const cheerio = require("cheerio");
const baseURL = "https://quotes.toscrape.com"
function main() {
const pageHTML = await axios.get(baseURL + "/")
// Initialize Cheerio with the page's HTML
const $ = cheerio.load(pageHTML.data)
}
main()
You can now use the $ variable to access and extract HTML elements similar to how you would work with jQuery. You will learn more about how to extract links and text in the following sections.
Extracting Links
The next step is to start extracting links from the page. There are three types of links that you will extract from this website:
- author: These are URLs for author profile pages. You will collect these from quotes and use these to extract author information.
- tag: These are URLs for tag pages. You will find quotes that are related to a particular tag on these pages. You can use these to extract lists of related quotes.
- page: These are URLs to help you navigate through the pagination of the website. You will need to collect and use these to navigate through the website and collect all quotes.
First of all, create two arrays to store pagination URLs and visited URLs and two Sets to store author page URLs and tag URLs in the main() function:
const paginationURLs = ["/"]
const visitedURLs = []
const authorURLs = new Set()
const tagURLs = new Set()
The visitedURLs array will help avoid crawling the same URL twice. The reason for using Sets instead of arrays for author and tag URLs is to avoid storing the same URL twice in the list. Set automatically removes duplicate elements from the list.
The next step is to identify the locators for the links from the page. You will need to inspect the HTML of the webpage in a web browser and find the appropriate class names, IDs, and elements to locate the elements.
As mentioned before, you will be extracting author profile links and tags from quotes and tag links from the “Top Ten tags” list on each page:
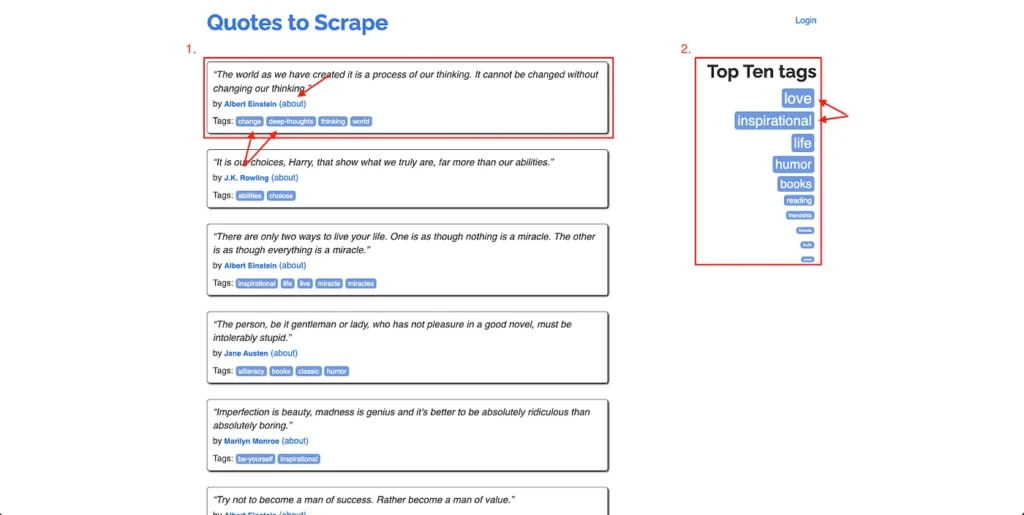
To write the selector for extracting the author profile link from a quote, right anywhere on the webpage and click Inspect. The developer tools window will open. On this window, click on the Sources tab and click on the Inspect button at the top:
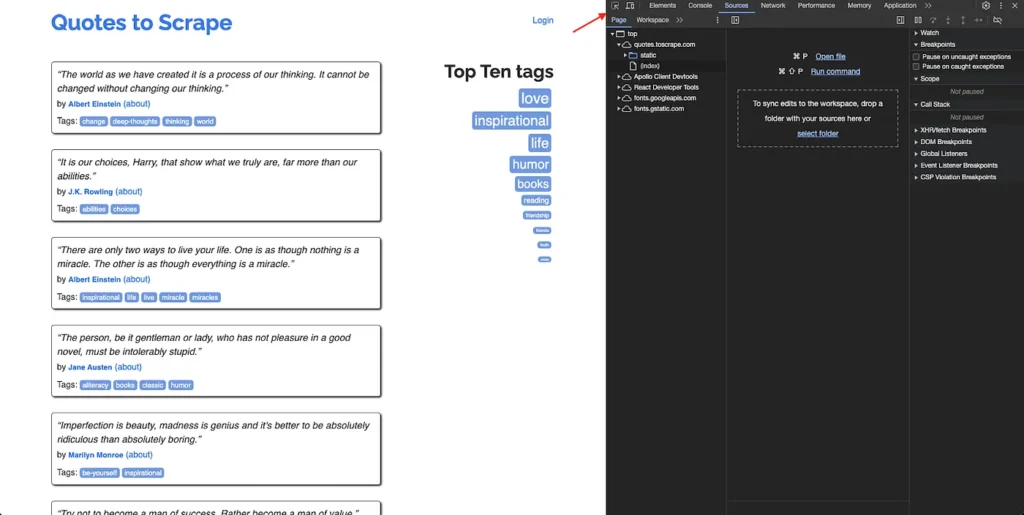
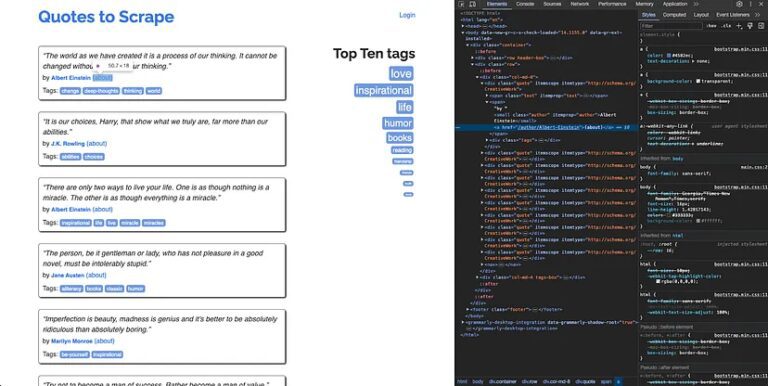
You can now use the DOM structure to write a selector query for this element. For instance, a selector query that works for this element would be .quote a. However, this will also extract links from the tags as well. It is not possible to make the query more specific since the target anchor element does not have any ID or class added to it. Therefore, you will need to filter out the tags’ URLs while processing the results of the extraction from Cheerio.
Following a similar process, you will need to write the selector queries for the top ten tags and pagination as well. A selector query that works for Top Ten tags is .tag-item a and one that works for pagination is .pager > .next a. You can use these to write the logic for extracting and filtering the links.
Next, create a new function named crawlQuotes and define it as the following:
const crawlQuotes = async (paginationURLs, visitedURLs, authorURLs, tagURLs) => {
let currentURLIndex = 0
while (visitedURLs.length !== paginationURLs.length) {
const pageHTML = await axios.get(baseURL + paginationURLs[currentURLIndex])
const $ = cheerio.load(pageHTML.data)
// Whenever a URL is visited, add it to the visited URLs list
visitedURLs.push(paginationURLs[currentURLIndex])
// Extracting all author links and tag links from each quote
$(".quote a").each((index, element) => {
const URL = $(element).attr("href")
if (URL.startsWith("/tag")){
if (URL.endsWith("/page/1/"))
tagURLs.add(URL.split("/page/1/")[0])
else
tagURLs.add(URL)
} else if (URL.startsWith("/author"))
authorURLs.add(URL)
})
// Extracting all tag links from the top ten tags section on the website
$(".tag-item a").each((index, element) => {
const URL = $(element).attr("href")
if (URL.startsWith("/tag")) {
if (URL.endsWith("/page/1/"))
tagURLs.add(URL.split("/page/1/")[0])
else
tagURLs.add(URL)
} else if (URL.startsWith("/author"))
authorURLs.add(URL)
})
// Extracting the links from the "next" button at the bottom of the page
$("li.next a").each((index, element) => {
const URL = $(element).attr("href")
if (URL.startsWith("/page"))
paginationURLs.push(URL)
})
// Once the processing is complete, move to the next index
currentURLIndex += 1
}
}
This function takes care of extracting all tags, authors, and page links from the homepage. It also takes care of iterating over all page links to extract all data from the website, and the use of Sets in the URL queues for author and tag pages ensures that any link encountered twice does not end up creating duplicate entries in the queue.
You can run this function by updating your main() function to look like this:
async function main() {
const paginationURLs = ["/"]
const visitedURLs = []
const authorURLs = new Set()
const tagURLs = new Set()
await crawlQuotes(paginationURLs, visitedURLs, authorURLs, tagURLs)
console.log(authorURLs)
console.log(tagURLs)
console.log(paginationURLs)
}
You can run the script by running the command node app.js in a terminal window. You should see the extracted author, tag, and pagination URLs in the output:
Set(50) {
'/author/Albert-Einstein',
'/author/J-K-Rowling',
'/author/Jane-Austen',
'/author/Marilyn-Monroe',
'/author/Andre-Gide',
... 45 more items
}
[
'/', '/page/2/',
'/page/3/', '/page/4/',
'/page/5/', '/page/6/',
'/page/7/', '/page/8/',
'/page/9/', '/page/10/'
]
Set(147) {
'/tag/change',
'/tag/deep-thoughts',
'/tag/thinking',
'/tag/world',
'/tag/abilities',
... 142 more items
}
Scheduling and Processing
While you have a working web crawler already, there are good chances it will run into errors and rate limits in real-world use cases. You need to prepare for such cases as well.
It is considered a good practice to avoid overloading target servers by sending too many requests simultaneously. To do that, consider introducing a delay in your pagination loop. You can use a “waiting” function like the following:
function halt(duration) {
return new Promise(r => setTimeout(r, duration))
}
Calling the halt function with a duration like 300 or 400 will help you slow down the rate at which your code crawls through the entire target website. The duration can be adjusted based on the estimated number of URLs to be crawled and any known rate limits of the target website.
Error handling is important to ensure the smooth functioning of your web crawlers. Make sure to always wrap network requests in try-catch blocks and provide appropriate error handling logic for known issues, like HTTP 403 (forbidden) or HTTP 429 (rate limit exceeded).
Data Extraction and Storage
Now that you have a set of URLs extracted from the target website, it becomes very easy to extract information from those pages using Cheerio. For instance, if you want to extract the details of each author and store it in a JSON file locally, you can do that with a few lines of code with Cheerio.
First of all,open an author page to understand its structure and figure out the right Cheerio selectors.
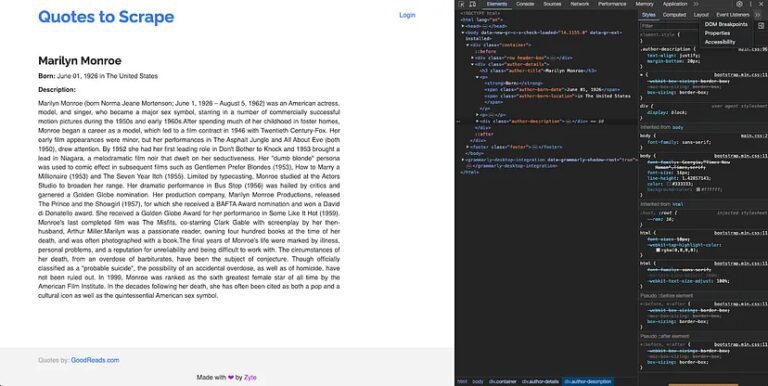
You will notice that the name, date of birth, location of birth, and a description of the author can be found under an H3 with the class “author-title”, a span with the class “author-born-date”, a span with the class “author-born-location”, and a div with the class “author-description” respectively. You can use these selectors to write a new function in the same index.js file that iterates over all author URLs and extracts this information:
const scrapeAuthors = async (authorURLs) => {
const authors = []
for (let url of authorURLs) {
const pageHTML = await axios.get(baseURL + url)
const $ = cheerio.load(pageHTML.data)
const author = {
name: $("h3.author-title").text(),
dateOfBirth: $("span.author-born-date").text(),
locationofBirth: $("span.author-born-location").text(),
description: $("div.author-description").text()
}
authors.push(author)
}
return authors
}
You can then update your main() function to call this function right after the crawlQuotes function:
async function main() {
const paginationURLs = ["/"]
const visitedURLs = []
const authorURLs = new Set()
const tagURLs = new Set()
await crawlQuotes(paginationURLs, visitedURLs, authorURLs, tagURLs)
// console.log(authorURLs)
// console.log(paginationURLs)
// console.log(tagURLs)
let authors = await scrapeAuthors(authorURLs)
console.log(authors)
}
Now when you run the app (using node index.js), you will be able to view the information for all authors printed as an array of author objects in the terminal. You can now choose to store this in a database or a JSON file as you require.
You can find the complete code developed in this tutorial in this GitHub repo.
Conclusion
This article has shown you the basics of building a web crawler using JavaScript and Node.js. Web crawlers are essential for sorting through massive amounts of data online, and with JavaScript and Node.js, you have a powerful set of tools to do just that.
Keep practicing and experimenting with what you’ve learned. The more you work with these tools, the better you’ll get at managing and making sense of the web’s enormous resources.
Additional Resources
Web Scraping with Scrapingdog



