
TL;DR
- 4 Python options:
BeautifulSoup,requests_html,Selenium,Scrapy. - BeautifulSoup (BS4): simple HTML / XML parsing—great default.
- requests_html: easy HTTP + static parsing.
- Selenium: handles JS + clicks; slower / heavier.
- Scrapy: full crawler framework with pipelines / export—best for large projects.
In this article, we will look at some of the best Python web scraping libraries out there. Web scraping is the process or technique used for extracting data from websites across the internet.
Other synonyms for web scraping are web crawling or web extraction. It’s a simple process with a website URL as the initial target. Web Scraping with Python is widely used in many different fields.
Python is a general-purpose language. It has many uses ranging from web development, AI, machine learning, and much more.
It’s also widely adopted by many web development companies that build scalable applications and integrate data-driven solutions.
It has many uses, ranging from web development to AI and ML solutions, and much more.
You can perform Python web scraping by taking advantage of some libraries and tools available on the internet.
We will discuss the tools: Beautiful Soup, Requests, Selenium, and Scrapy. A web scraper written in Python 3 could be used to collect data from websites
The following are the prerequisites you will need to follow along with this tutorial:
● Installation of the latest version of Python.
● Install pip — Python package manager.
● A code editor of your choice.
Once you’ve checked with the prerequisites above, create a project directory and navigate into the directory. Open your terminal and run the commands below.
mkdir python_scraper
cd python_scraper
4 Python Web Scraping Libraries & Basic Scraping with Each
There are a number of great web scraping tools available that can make your life much easier. Here’s the list of top Python web scraping libraries that we choose to scrape:
- BeautifulSoup: This is a Python library used to parse HTML and XML documents.
- Requests: Best to make HTTP requests.
- Selenium: Used to automate web browser interactions.
- Scrapy Python: This is a Python framework used to build web crawlers.
Let’s get started.
Beautifulsoup
Beautiful Soup is one of the best Python libraries for parsing HTML and XML documents. It creates a parse tree for parsed pages that can be used to extract data from HTML, which is useful for web scraping. It is also used to extract data from some JavaScript-based web pages.
Open your terminal and run the command below:
pip install beautifulsoup4
With Beautiful Soup installed, create a new Python file, name it beautiful_soup.py
We are going to scrape (Books to Scrape)[https://books.toscrape.com/] website for demonstration purposes. The Books to Scrape website looks like this:
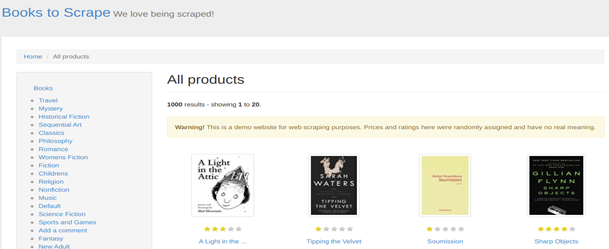
We want to extract the titles of each book and display them on the terminal. The first step in scraping a website is understanding its HTML layout. In this case, you can view the HTML layout of this page by right-clicking on the page, above the first book in the list. Then click Inspect.
Below is a screenshot showing the inspected HTML elements.

You can see that the list is inside the <ol class=”row”> element. The next direct child is the <li> element.
What we want is the book title, which is inside the <a>, inside the <h3>, inside the <article>, and finally inside the <li> element.
To scrape and get the book title, let’s create a new Python file and call it beautiful_soup.py
When done, add the following code to the beautiful_soup.py file:
from urllib.request import urlopen
from bs4 import BeautifulSoup
url_to_scrape = “https://books.toscrape.com/"
request_page = urlopen(url_to_scrape)
page_html = request_page.read()
request_page.close()
html_soup = BeautifulSoup(page_html, ‘html.parser’)
# get book title
for data in html_soup.select(‘ol’):
for title in data.find_all(‘a’):
print(title.get_text())
In the above code snippet, we open our webpage with the help of the urlopen() method. The read() method reads the whole page and assigns the contents to the page_html variable. We then parse the page using html.parser to help us understand HTML code in a nested fashion.
Next, we use the select() method provided by the BS4 library to get the <ol class=” row”> element. We loop through the HTML elements inside the <ol class=”row”> element to get the <a> tags which contain the book names. Finally, we print out each text inside the <a> tags on every loop it runs with the help of the get_text() method.
You can execute the file using the terminal by running the command below.
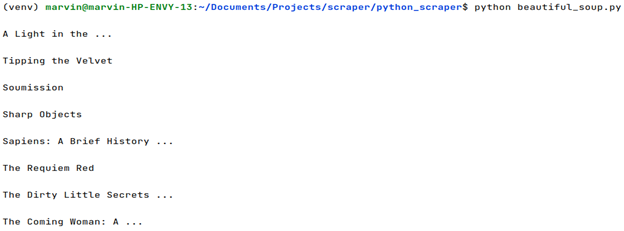
python beautiful_soup.py
This should display something like this:
Now let’s get the prices of the books too.
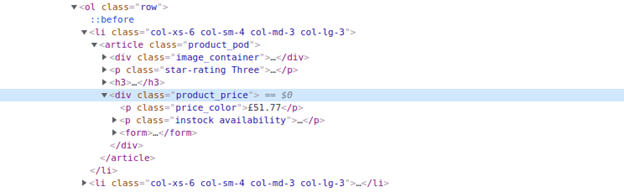
The price of the book is inside a <p> tag, inside a <div> tag. As you can see there is more than one <p> tag and more than one <div> tag. To get the right element with the book price, we will use CSS class selectors; lucky for us; each class is unique for each tag.
Below is the code snippet to get the prices of each book; add it at the bottom of the file:
# get book prices
for price in html_soup.find_all(“p”, class_=”price_color”):
print( price.get_text())
If you run the code on the terminal, you will see something like this:

Your completed code should look like this:
from urllib.request import urlopen
from bs4 import BeautifulSoup
url_to_scrape = “https://books.toscrape.com/"
request_page = urlopen(url_to_scrape)
page_html = request_page.read()
request_page.close()
html_soup = BeautifulSoup(page_html, ‘html.parser’)
# get book title
for data in html_soup.select(‘ol’):
for a in data.find_all(‘a’):
print(a.get_text())
# get book prices
for price in html_soup.find_all(“p”, class_=”price_color”):
print(price.get_text())
Pros
- It makes parsing and navigating HTML and XML documents straightforward, even for those with limited programming experience.
- BeautifulSoup can handle poorly formatted HTML or XML documents gracefully.
- It has comprehensive documentation and an active community, which means you can find plenty of resources and examples to help you learn and troubleshoot any issues you encounter.
Cons
- There is no major disadvantage of using this library but it might get a little slow when using it on big documents.
Requests
Requests is an elegant HTTP library. It allows you to send HTTP requests without the need to add query strings to your URLs.
To use the requests library, we first need to install it. Open your terminal and run the command below
pip3 install requests_html
Once you have installed it, create a new Python file for the code. We will prevent naming a file with reserved keywords such as requests. Let’s name the file
requests_scrape.py
Now add the code below inside the created file:
from requests_html import HTMLSession
session = HTMLSession()
r= session.get(‘https://books.toscrape.com/')
get_books = r.html.find(‘.row’)[2]
# get book title
for title in get_books.find(‘h3’):
print(title.text)
# get book prices
for price in get_books.find(‘.price_color’):
print(price.text)
In this code snippet. In the first line, we imported HTMLSession from the request_html library. And instantiated it. We use the session to perform a get request from the BooksToScrape URL.
After performing the get request. We get the unicorn representation of HTML content from our BooksToScrape website. From the HTML content, we get the class row. Located at index 2 contains the list of books and is assigned to the get_books variable.
We want the book title. Like in the first example, the book title is inside the <a>, inside the <h3>. We loop through the HTML content to find each <h3> element and print the title as text.
To get the prices of each book, we only change what element the find method should search for in the HTML content. Luckily, the price is inside a <p> with a unique class price_color that’s not anywhere else. We loop through the HTML content and print out the text content of each <p> tag.
Execute the code by running the following command in your terminal:
python requests_scrape.py
Below is the output of the book titles:
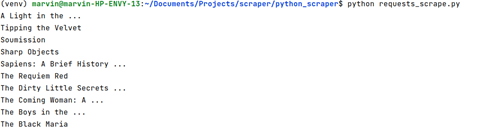
Below is the output of the book titles:

You can visit Requests HTML scraping with Python to learn more about many things you can do with it.
Pros
- Requests provide a straightforward and user-friendly API for sending HTTP requests, making it easy for developers to work with web services and retrieve data.
- You can pass headers, cookies, etc which makes web scraping super simple.
Cons
- Requests is a synchronous library, meaning that it can block the execution of your program while waiting for a response.
Selenium
Selenium is a web-based automation tool. Its primary purpose is for testing web applications, but it can still do well in web scraping.
We are going to import various tools to help us in scraping.
First, we are going to install selenium. There are several ways to install it:
● You can install using pip with the command:
pip install selenium
● You can also install using Conda with the command:
conda install –c conda –forge selenium
Alternatively, you can download the PyPI source archive (selenium-x.x.x.tar.gz) and install it using setup.py with the command below:
python setup.py install
We will be using the chrome browser, and for this, we need the chrome web driver to work with Selenium.
Download chrome web driver using either of the following methods:
1. You can either download it directly from the link below
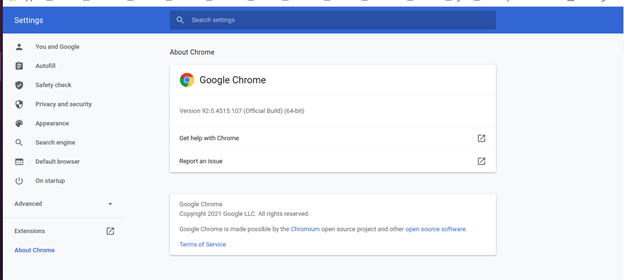
Chrome driver download link You will find several download options on the page depending on your version of Chrome. To locate what version of Chrome you have, click on the three vertical dots at the top right corner of your browser window, and click ‘Help’ from the menu. On the page that opens, select “About Google Chrome.”
The screenshot below illustrates how to go about it:
After clicking, you will see your version. I have version 92.0.4515.107, shown in the screenshots below:
2. Or by running the commands below, if you are on a Linux machine:
wget https://chromedriver.storage.googleapis.com/2.41/chromedriver_linux64.zip
unzip chromedriver_linux64.zip
After installing. You need to know where you saved your web driver download on your local computer. This will help us get the path to the web driver. Mine is in my home directory.
To get the path to the web driver. Open your terminal and drag the downloaded Chrome driver right into the terminal. An output of the web driver path will be displayed.
When you’re done, create a new Python file; let’s call it selenium_scrape.py.
Add the following code to the file:
from selenium import webdriver
from selenium.webdriver.common.by import By
url = ‘https://books.toscrape.com/'
driver = webdriver.Chrome(‘/home/marvin/chromedriver’)
driver.get(url)
container =
driver.find_element_by_xpath(‘//[@id=”default”]/div/div/div/div/section/div[2]/ol’)
# get book titles
titles = container.find_elements(By.TAG_NAME, ‘a’)
for title in titles:
print(title.text)
We first import a web driver from Selenium to control Chrome in the above code. Selenium requires a driver to interface with a chosen browser.
We then specify the driver we want to use, which is Chrome. It takes the path to the Chrome driver and goes to the site URL. Because we have not launched the browser in headless mode. The browser appears, and we can see what it is doing.
The variable container contains the XPath of the <a> tag with the book title. Selenium provides methods for locating elements, tags, class names, and more. You can read more from selenium location elements
To get the XPath of <a> tag. Inspect the elements, find the <a> tag with the book title, and right-click on it. A dropdown menu will appear; select Copy, then select Copy XPath.
Just as shown below:
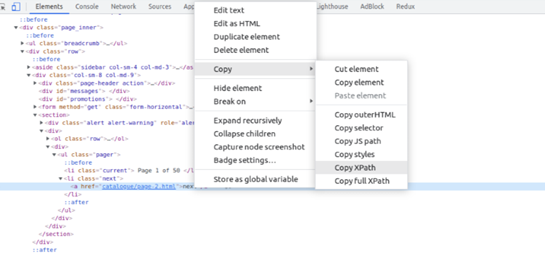
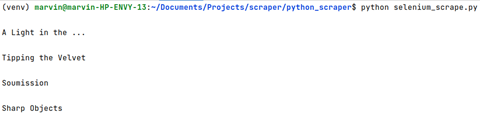
From the variable container. We can then find the titles by the tag name <a> and loop through to print all titles in the form of text.
The output will be as shown below:
Now, let’s change the file to get book prices by adding the following code after the get book titles code.
prices = container.find_elements(By.CLASS_NAME, ‘price_color’)
for price in prices:
print(price.text)
In this code snippet. We get the prices of each book using the class name of the book price element. And loop through to print all prices in the form of text. The output will be like the screenshot below:

Next, we want to access more data by clicking the next button and collecting the other books from other pages.
Change the file to resemble the one below:
from selenium import webdriver
from selenium.webdriver.common.by import By
url = ‘https://books.toscrape.com/'
driver = webdriver.Chrome(‘/home/marvin/chromedriver’)
driver.get(url)
def get_books_info():
container =driver.find_element_by_xpath(‘//[@id=”default”]/div/div/div/div/section/div[2]/ol’)
titles = container.find_elements(By.TAG_NAME, ‘a’)
for title in titles:
print(title.text)
prices = container.find_elements(By.CLASS_NAME, ‘price_color’)
for price in prices:
print(price.text)
next_page = driver.find_element_by_link_text(‘next’)
next_page.click()
for x in range(5):
get_books_info()
driver.quit()
We have created the get_books_info function. It will run several times to scrape data from some pages, in this case, 5 times.
We then use the element_by_link_text() method. to get the text of the <a> element containing the link to the next page.
Next, we add a click function to take us to the next page. We scrape data and print it out on the console; we repeat this 5 times because of the range function. After 5 successful data scrapes, the driver.quit() method closes the browser.
You can choose a way of storing the data either as a JSON file or in a CSV file. This is a task for you to do in your spare time.
You can dive deeper into selenium and get creative with it. I have a detailed guide on web scraping with Selenium & Python, do check out it too!!
Pros
- You can use selenium to scrape Javascript-enabled websites like Duckduckgo, myntra, etc.
- Selenium can handle complex tasks like navigating through multiple pages, dealing with JavaScript-based interactions, and filling out forms. It can even automate CAPTCHA solving using third-party tools.
Cons
- Scraping with selenium is very slow and it can it too much hardware. This just increases the total cost.
- If the browser updates then selenium code might even break and stop scraping.
Scrapy
Scrapy is a powerful multipurpose tool used to scrape the web and crawl the web. Web crawling involves collecting URLs of websites plus all the links associated with the websites. Finally, store them in a structured format on servers.
Scrapy provides many features but is not limited to:
● Selecting and extracting data from CSS selectors
● Support for HTTP, crawl depth restriction, and user-agent spoofing features,
● Storage of structured data in various formats such as JSON, Marshal, CSV, Pickle, and XML.
Let’s dive into Scrapy. We need to make sure we have scrapy installed; install it by running the command below:
sudo apt-get update
sudo apt install python3-scrapy
We will have to set up a new Scrapy project. Enter a directory where you’d like to store your code and run the command below:
scrapy startproject tutorial
cd tutorial
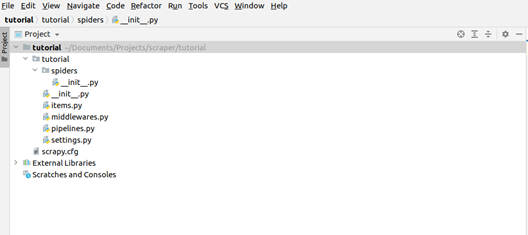
This will create a tutorial directory with the following contents:
spiders/ __init__.py # a directory where you’ll later put your spiders
tutorial/scrapy.cfg # deploy configuration file
tutorial/__init__.py # project’s Python module, you’ll import your code from here
items.py # project items definition file
Middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
The screenshot below shows the project structure:
Before we add code to our created project. The best way to learn how to extract data with Scrapy is by using the Scrapy Shell.
Scraping using the Scrapy Shell
The shell comes in handy. Because it quickens debugging of our code when scrapping, without the need to run the spider. To run Scrapy shell, you can use the shell command below:
scrapy shell <url>
On your terminal, run :
scrapy shell ‘https://books.toscrape.com/’
If you don’t get any data back, you can add the user agent with the command below:
scrapy shell –s USER_AGENT=’ ’ ‘https://books.toscrape.com/’
To get USER_AGENT, open your dev tools with ctrl+shift+i. Navigate to the console, clear the console; type navigator.userAgent, then hit enter.
An example of a USER AGENT can be: Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Mobile Safari/537.36.
The screenshot below shows how to get the name of your USER_AGENT in the dev tools:

If you’re successful in getting output from the shell command, you will see a resemblance to the one below:
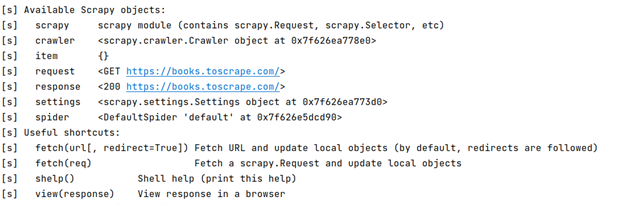
Using the shell, you can try selecting elements using CSS. The shell returns a response object.
Let us get the response object containing the titles and prices of the books from our test
website Bookstoscrape. The book title is inside element <a> element, inside the <h3>, inside <article>, inside <li>, inside <ol> with a class row. And, finally inside a <div> element.
We create a variable container and assign it to the response object containing the <ol> element with a class of rows inside a <div> element.
To see the container output in our Scrapy shell, type in a container and hit enter; the output will be like below:
Now, let us find the book title of each book, using the response object we got above
Create a variable called titles; this will hold our book titles. Using the container with the response object we got above.
We will select <a> inside the <h3> element, using the CSS selectors that scrapy provides.
We then use the CSS extension provided by scrapy to get the text of the <a> element.
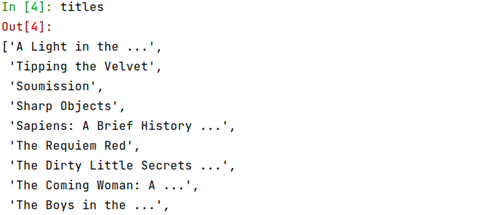
Finally, we use the getall() method to get all the titles. As shown below:

Run titles to get the output of all the book titles. You should see an output like the one below:
That went well.
Now, let us get prices for each book.
In the same scrapy shell, create a price variable to hold our prices. We use the same container response object. With CSS, we select <p> element with a class of price_color.
We use the CSS extension provided by scrapy to get the text from the <p> element.
Finally, the getall() method gets all the prices.
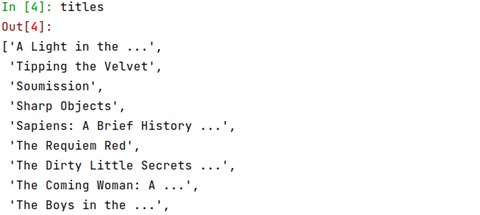
As shown below:

Run the prices; your output should look like the below:
That was quick, right? A scrapy shell saves us a lot of time debugging as it provides an interactive shell.
Now let’s try using a spider.
Scraping using spider
Let’s go back to the tutorial folder we created; we will add a spider.
A spider is what scrapy uses to scrape information from a website or a group of websites.
Create a new file. Name it books_spider.py under the tutorial/spiders directory in your project.
Add the following code to the file:
import scrapy
class BooksSpider(scrapy.Spider):
name = “books”
start_urls = [
‘https://books.toscrape.com/'
]
def parse(self, response):
for book in response.css(‘div ol.row’):
title = book.css(‘h3 a::text’).getall()
price = book.css(‘p.price_color::text’).getall()
yield {
‘title’: book.css(‘h3 a::text’).getall(),
‘price’: book.css(‘p.price_color::text’).getall()
}
The BooksSpider subclasses scapy.Spider. It has a name attribute, the name of our spider, and the start_urls attribute, which has a list of URLs.
The list with URLs will make the initial requests for the spider.
It can also define how to follow links in the pages and parse the downloaded page content to extract data.
The parse method parses the response, extracting the scraped data as dictionaries. It also finds new URLs to follow and creates new requests from them.
To get output from our code, let’s run a spider. To run a spider, you can run the command with the syntax below:
scrapy crawl <spider name>
On your terminal, run the command below:
scrapy crawl books
You will get an output resembling the one below:

We can store the extracted data in a JSON file. We can use Feed exports which scrapy provides out of the box. It supports many serialization formats, including JSON, XML, and CSV, just to name a few.
To generate a JSON file with the scraped data, run the command below:
scrapy crawl books –o books.json
This will generate a books.json file with contents resembling the one below:

Following links with scrapy
Let’s follow the link to the next page and extract more book titles. We inspect the elements and get the link to the page we want to follow.
The link is <a> tag <li> with a class next, inside <ul> tag with class pager, finally inside a <div> tag
Below is a screenshot of the inspected element with a link to our next page:
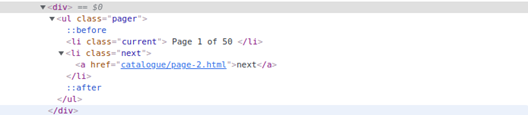
Let’s use the scrapy shell to get the link to the next page first. Run the scrapy shell command with the books to scrape Url.
We get the href attribute to determine the specific URL the next page goes to, just like below:

Let’s now use our spider, and modify the books_spider.py file to repeatedly follow the link to the next page, extracting data from each page.
import scrapy
class BooksSpider(scrapy.Spider):
name = “books”
start_urls = [
‘https://books.toscrape.com/'
]
def parse(self, response):
for book in response.css(‘div ol.row’):
title = book.css(‘h3 a::text’).getall()
price = book.css(‘p.price_color::text’).getall()
yield {
‘title’: book.css(‘h3 a::text’).getall(), ‘price’: book.css(‘p.price_color::text’).getall()
}
next_page = response.css(‘li.next a::attr(href)’).get()
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
In this code snippet. We create a variable next_page that holds the URL to the next page. We then check if the link is not empty. Next, we use the response.follow method, and pass the URL and a callback; this returns a Request instance. Finally, we yield this Request.
We can go back to the terminal and extract a list of all books and titles into an allbooks.json file.
Run the command below:
scrapy crawl books –o allbooks.json
After it’s done scraping, open the newly created allbooks.json file. The output is like below:

You can do many things with scrapy, including pausing and resuming crawls and a wide range of web scraping tasks. I have made a separate guide on web scraping with scrapy, Do check it out too!
Pros
- Scrapy supports asynchronous processing, which enables concurrent requests, reducing the time required for scraping large websites with many pages.
- Scrapy is highly extensible and allows you to create reusable custom middlewares, extensions, and item pipelines.
Cons
- It can be intimidating at first. There the learning curve is steep.
- For small scale web scraping scrapy might be too heavy weight.
Key Takeaways:
The blog compares popular Python web scraping libraries and explains where each one fits based on project complexity and scale.
It highlights that simple libraries work well for static pages, while dynamic or JavaScript-heavy sites require more advanced tools.
The article explains the trade-offs between ease of use, performance, and control when choosing a scraping library.
It shows that no single library is perfect—most real-world scraping projects use a combination of tools.
The post emphasizes that for large-scale or blocked websites, using scraping APIs can be more reliable than relying only on open-source libraries.
The code for this tutorial is available from this GitHub Repository.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:


