
TL;DR
- The top 5 web scraping tools in 2026, based on real-world tests on Amazon, Google, and Idealista, are:
- Scrapingdog – Best overall for scalable, cost-efficient, and highly reliable scraping with 100% success rates.
- ScraperAPI – Strong general-purpose scraper with dedicated APIs, but slower response times and higher costs.
- Scrapingbee – Good choice for Google-focused scraping with clean documentation, though less reliable on Idealista.
- Zenrows – Proxy-based scraper with flexible setup, but inconsistent success rates.
- Firecrawl – Very fast and reliable extraction, but prohibitively expensive for production.
Web Scraping as the name suggests is the process of extracting data from a source on the internet. With so many tools, use cases, and a large market demand, there are a couple of web scraping tools to cater to this market size with different capabilities and functionality.
I have been web scraping for the past 8 years and have vast experience in this domain. In these years, I have tried and tested many web scraping tools (& finally, have made a tool myself too).
In this blog, I have handpicked some of the best web scraping tools, tested them separately, and ranked them.
I am going to test each API on Amazon, Google, & Idealista. Specifically, I have checked the success rate, their pricing, the documentation design, and their response time and depicted my results at the very last.
Let’s Jump in!!
The 5 Best Web Scraping Tools: Quick Comparison
To scrape data reliably from modern websites, you need more than just a basic scraper. Performance, stability, and cost quickly become critical as soon as you move beyond small experiments.
Before choosing a web scraping tool, these are the key factors you should consider:
Speed & efficiency – How fast does the tool respond under real-world conditions?
Scalability – Can it handle thousands or millions of requests without breaking?
Pricing – Is the cost sustainable as your usage grows?
Ease of use – How simple is it to get started and integrate into workflows?
Error handling – Does it retry, rotate IPs, and recover from blocks gracefully?
Customer support – Is help available when things break?
Customization – Can it adapt to specific websites, formats, or use cases?
All the tools listed below were evaluated with these criteria in mind so you can quickly shortlist the right solution based on your needs.
Overview of popular web scraping tools:
The tests success rate is by testing these APIs on Amazon, Idealista and Google.
| Provider | Starting price subscriptions | Success Rate | Avg. Response Time | Cost per Request |
|---|---|---|---|---|
| Scrapingdog | $40/month | 100% (All) | 2.71–7.97s | $0.000067 |
| ScraperAPI | $49/month | 100% (All) | 2.89–20.35s | $0.0000997 |
| Scrapingbee | $49/month | 73–100% | 7.58–9.46s | $0.000083 |
| Zenrows | $69/month | 0–100% | 0.3–12.84s | $0.00008 |
| Firecrawl | $16/month | 100% (All) | 3.26–6.11s | $0.566 |
Testing Script
I am going to use this Python code to test all the products in the list.
We will test these APIs on Amazon, Google, and Idealista. Will calculate their success rate, average response time, and per-request credit cost.
In total, 50 requests will be made to each API for each domain. This study will you a clear hint on selecting a web scraping API while starting any data-related project.
import requests
import time
import random
# List of random words to use in the search query
search_terms_amazon = ["https://www.amazon.com/dp/B0CTKXMQXK", "https://www.amazon.com/dp/B0D1ZFS9GH", "https://www.amazon.com/dp/B0CXG3HMX1", "https://www.amazon.com/dp/B0CKM9JVJB/", "https://www.amazon.com/dp/B0BYX1XT81"]
search_terms_idealista = ['https://www.idealista.com/venta-viviendas/torrelavega/inmobiliaria-barreda/','https://www.idealista.com/venta-viviendas/torrelavega/inmobiliaria-barreda/','https://www.idealista.com/venta-viviendas/torrelavega/inmobiliaria-barreda/','https://www.idealista.com/venta-viviendas/torrelavega/inmobiliaria-barreda/','https://www.idealista.com/alquiler-viviendas/malaga-malaga/con-solo-pisos%2Caticos/']
search_terms_google = [
"pizza", "burger", "sushi", "coffee", "tacos", "salad", "pasta", "steak",
"sandwich", "noodles", "bbq", "dumplings", "shawarma", "falafel",
"pancakes", "waffles", "curry", "soup", "kebab", "ramen"
];
# base_url = Your-API-URL
total_requests = 50
success_count = 0
total_time = 0
for i in range(total_requests):
try:
# Pick a random search term from the list
search_term = random.choice(search_terms)
url = base_url.format(query=search_term)
start_time = time.time() # Record the start time
response = requests.get(url)
end_time = time.time() # Record the end time
# Calculate the time taken for this request
request_time = end_time - start_time
total_time += request_time
# Check if the request was successful (status code 200)
if response.status_code == 200:
success_count += 1
print(f"Request {i+1} with search term '{search_term}' took {request_time:.2f} seconds, Status: {response.status_code}")
except Exception as e:
print(f"Request {i+1} with search term '{search_term}' failed due to {str(e)}")
# Calculate the average time taken per request
average_time = total_time / total_requests
success_rate = (success_count / total_requests) * 100
# Print the results
print(f"\nTotal Requests: {total_requests}")
print(f"Successful Requests: {success_count}")
print(f"Average Time per Request: {average_time:.2f} seconds")
print(f"Success Rate: {success_rate:.2f}%")
List of All Best Web Scraping Tools
Scrapingdog
- Scrapingdog‘s Web scraping API provides a general scraper through which you can scrape any website and in return, you get raw HTML data from that particular website. It also provides dedicated APIs for scraping Amazon, Google, X, Instagram, Indeed, etc. Dedicated APIs provide parsed JSON data.
- Once you sign you get free 1000 credits which are more than enough for testing any API. Of course, the credit cost of each API is different.
- The dashboard is designed so that even a non-developer can scrape the data. The documentation is user-friendly, and integrating their APIs is super simple.
- Per request, the cost is around $0.000067 in their PRO plan and it goes down with the increase in volume.
- Custom support is super active and you will get a response within a few minutes.
Test Results of Scrapingdog
I tested Scrapingdog on Idealista, Amazon, and Google, and here are the test results.
Amazon
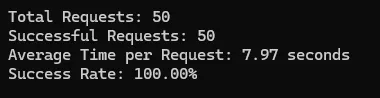
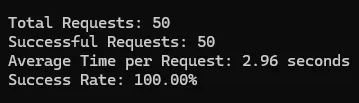
Idealista
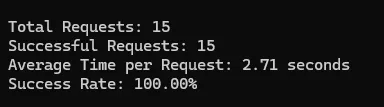
Summary
| Platform | Success Rate | Average Response Time (seconds) | Credit Cost |
|---|---|---|---|
| Amazon | 100% | 7.97 | 1 |
| 100% | 2.96 | 5 | |
| Idealista | 100% | 2.71 | 1 |
ScraperAPI
- ScraperAPI also provides robust web scraping and dedicated APIs. It provides dedicated APIs for Google Amazon, etc.
- The free trial comes with a generous 5000 credits. ScraperAPI also has different credit costs for many websites. So, the pricing will change according to that.
- You can easily integrate the API into your production environment. You can even test the API directly from the dashboard.
- Per request, the cost is around $0.0000997 in their Business plan and it goes down with the increase in volume.
- They do not offer a chat widget but you can mail them to resolve your queries.
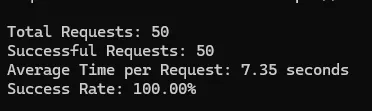
Test Results of ScraperAPI
Amazon
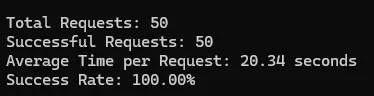
Idealista
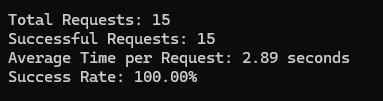
Summary
| Platform | Success Rate | Average Response Time (seconds) | Credit Cost |
|---|---|---|---|
| Amazon | 100% | 7.35 | 5 |
| 100% | 20.35 | 25 | |
| Idealista | 100% | 2.89 | 1 |
Scrapingbee
- Scrapingbee provides scraping APIs extracting raw HTML data and JSON data through its dedicated APIs. Although it only provides a dedicated API for Google only.
- The trial pack will provide you with 1000 credits.
- Documentation is very clear and developers can easily integrate the API in any working environment.
- Per API credit cost is around $0.000083 in their Business pack.
- You can contact them via chat widget or email.
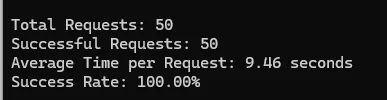
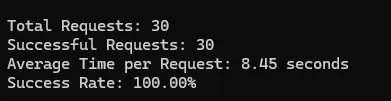
Test Results of Scrapingbee
Amazon
Idealista
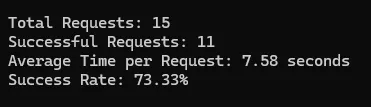
Summary
| Platform | Success Rate | Average Response Time (seconds) | Credit Cost |
|---|---|---|---|
| Amazon | 100% | 9.46 | 1 |
| 100% | 8.45 | 25 | |
| Idealista | 73% | 7.58 | 1 |
Zenrows
- Zenrows is in web scraping proxies but also provides web scraping APIs.
- They provide $1 worth of free credits when you sign up. However, they do not follow a credit system, so analyzing the per-request credit is difficult.
- Documentation is quite informative; any developer could integrate their proxy or API.
- Per API credit cost is $0.00008.
- Both email and chat support are available on the website.
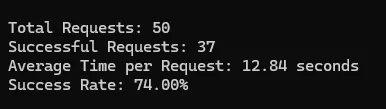
Test Results of Zenrows
Amazon
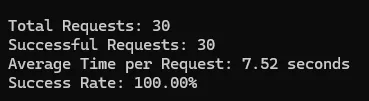
Idealista
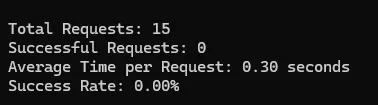
Summary
| Platform | Success Rate | Average Response Time (seconds) | Credit Cost |
|---|---|---|---|
| Amazon | 74% | 12.84 | 10 |
| 100% | 7.52 | 125 | |
| Idealista | 0% | 0.3 | 10 |
Firecrawl

- Firecrawl is a new web scraping product which povides a general endpoint for scraping websites.
- They provide 500 credits for free on signup. These credits can be used for testing the service quality.
- Documentation is well written and can be easily integrated with any working environment.
- Per credit cost starts from $0.566 and drops below $0.072 with high volume.
- You can contact them via chat support or email.
Test Results of Firecrawl
Amazon

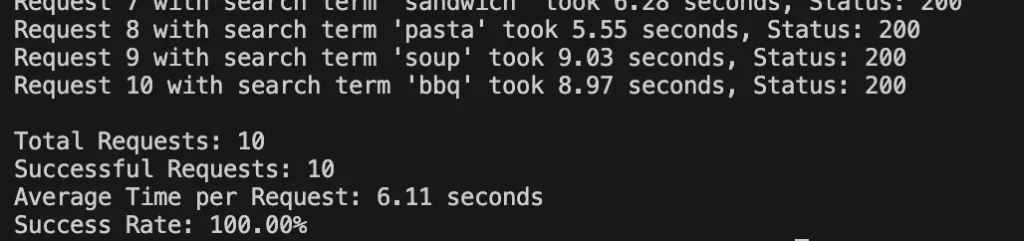
Idealista
Summary
| Platform | Success Rate | Avg. Response Time | Credit Cost per Call |
|---|---|---|---|
| Amazon | 100% | 3.26 seconds | 1 credit |
| 100% | 6.11 seconds | 1 credit | |
| Idealista | 100% | 4.43 seconds | 1 credit |
Final Verdict
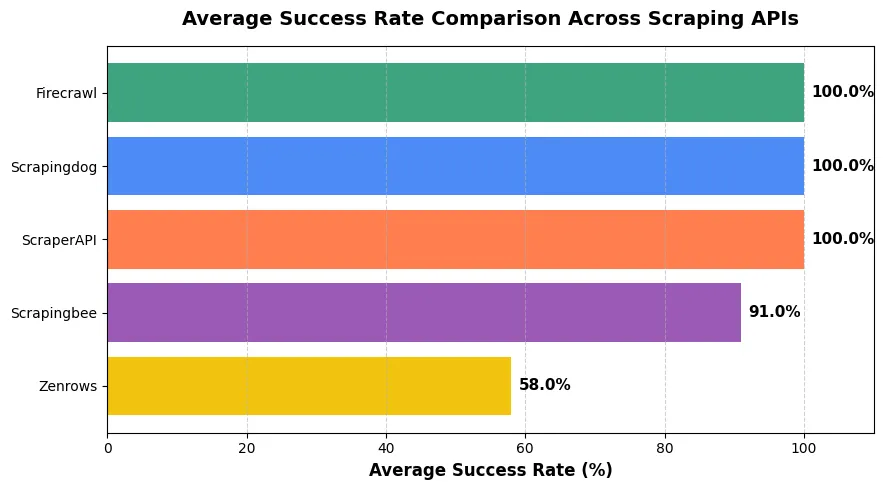
This graph is showing the overall success rate offered by each API. Clearly Scrapingdog, ScraperAPI and Firecrawl provides the best scraping solution.
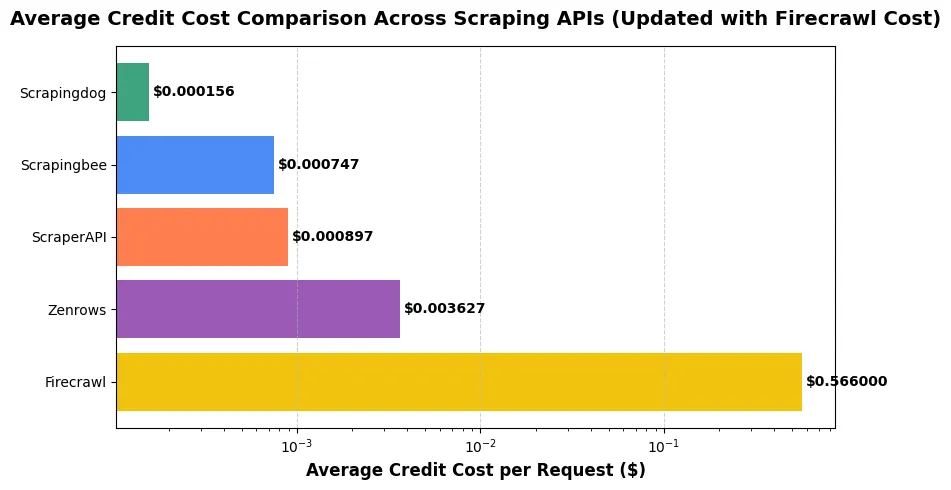
But if you consider the cost as well then the clear choice would be Scrapingdog. Across all three platforms Amazon, Google, and Idealista, Scrapingdog consistently outperformed every other scraping API in both reliability and cost efficiency. While Firecrawl delivered fast responses, its pricing at $0.566 per credit makes it commercially impractical. ScraperAPI and Scrapingbee maintained good success rates but were notably slower and significantly more expensive, especially on Google where response times exceeded 8–20 seconds. Zenrows, on the other hand, struggled with reliability, failing entirely on Idealista and showing poor consistency across tests.
Scrapingdog achieved 100% success rates, the fastest average time on Google (2.96s), and did so at a fraction of the cost. As low as $0.000067 per request. Overall, it clearly delivers the best balance of performance, stability, and affordability among all tested providers.
Conclusion
There were many other web scraping APIs, however to keep the article concise and knowledgeable we kept it to the best of what we found.
The comparisons we have done are for you to dig down into when you would scale any scraping process. On the surface, each API mentioned here would work as well.
If you would scale the process to some millions, then the stats given here would help you determine the choice as per your needs.
And if you are already looking to deploy one of these tools to your tech stack, it would be worth comparing them head-to-head. The following guides may help you clear the confusion more
1. Scrapingbee vs Scraperapi vs Scrapingdog: How Do We Compare Against Them
2. Zenrows vs Scrapingbee vs Scrapingdog: Which Is Better Web Scraping API
3. SerpAPI vs SearchAPI vs Scrapingdog: Pick the Better API for Scraping Google Search
Happy Scraping!!
Frequently Asked Questions (FAQs)
1. What is the best web scraping tool for developers?
The best web scraping tool for developers is one that provides a clean API, good documentation, and flexible output formats like JSON or HTML. Developer-focused tools usually allow easy integration with Python, JavaScript, or other backend frameworks and give more control over scraping logic.
2. Can these tools also be used for scraping prices?
Yes, with all of the APIs mentioned here, you can build a price scraper as per your needs. Scrapingdog does have APIs for scraping e-commerce websites that you can check out.
3. Which web scraping tool is reliable?
Since we have tested these tools, all of these are reliable tools & you can use them in production.
4. What features should I look for when choosing a web scraping tool?
When choosing a web scraping tool, you should look for features such as proxy management, CAPTCHA handling, scalability, API support, data formatting options, and reliability. Ease of use, documentation quality, and pricing are also important factors to consider.


