
TL;DR
- Build a small job board: scrape LinkedIn, Indeed, and Glassdoor (Data Engineer in Texas) and save
JSON. - Stack: Python 3.8+,
requests+BeautifulSoup,Flask; provided project structure and scripts. - To avoid blocks at scale, use Scrapingdog (handles proxies, headless, CAPTCHAs); examples shown per site.
- The
Flaskapp merges the JSONs and renders a dashboard with titles, companies, locations, salaries, and links.
This guide will not only help streamline your job search but will also give you hands-on experience in web scraping and developing a web application.
From setting up your development environment and running your first web scraping script to deploying a Flask application that neatly displays all your job data, you will find it all.
Before creating a board, let’s see some of the reasons as to why a job board can be beneficial.
Some Compelling Reasons To Create a Job Board
Creating a job board can be a great idea for many simple and practical reasons:
1. Easier Job Search
A job board puts job listings from different sources all in one place. This makes it easier for people to find jobs without having to search multiple websites.
2. Focus on Specific Groups
You can design your job board to focus on specific industries, job types, or locations. This makes it more useful for a particular group of job seekers and helps your site stand out.
3. Make Money
There are several ways to make money with a job board:
Job Posting Fees: Charge companies to post their job listings.
Featured Listings: Offer premium spots for job posts to get more attention.
Affiliate Marketing: Earn money by partnering with other job sites or career services.
Advertising: Sell ad space to businesses that want to reach job seekers.
4. High Demand
With more people looking for jobs online, there’s a big opportunity for job boards. The job market has especially grown online after the pandemic, making it a good time to start a job board. Many users are actively seeking career transitions or training programs for tech jobs, so building a platform that also highlights these resources can add value and attract more traffic.
5. Valuable Insights
Running a job board gives you a lot of useful information about job trends and what job seekers are looking for. You can use this data to improve your site and offer better services.
The salary data you collect is especially valuable for companies setting competitive pay ranges using compensation planning software
6. Build a Community
A job board can help create a community of job seekers and employers. Adding features like forums, blogs, or events can make your site a place where people connect and help each other.
7. Trust and Authority
Successfully running a job board helps build your reputation as a reliable resource for job seekers and employers. This can lead to more opportunities like partnerships and media attention.
Now we have some good reasons to create a job board, let’s see how we can create one using web scraping.
Setting up the prerequisites
Before diving into the tutorial, ensure you have the necessary tools and libraries installed.
To get started, download the latest Python version from the official website and ensure it’s installed on your system.
Here are some necessary Python libraries:
- Flask: A lightweight web framework for building web applications in Python. We’ll use it to create a dashboard to display the scraped dog job data.
- BeautifulSoup4: A library that simplifies parsing HTML content. It helps us navigate the HTML structure and extract relevant job information efficiently when scraping websites.
- Requests: This library allows us to make HTTP requests to websites, essential for fetching the HTML content of the job boards we want to scrape.
Create a requirements.txt file listing the required libraries, then install them using the file.
Flask==3.0.2
beautifulsoup4==4.12.2
requests==2.31.0
pip install -r requirements.txt0
Set up project structure
Ensure your project directory follows this structure:
job_dashboard/
│
├── app.py # Flask application file
├── requirements.txt # Dependencies file
├── templates/
│ └── dashboard.html # HTML template for rendering the dashboard
├── data/
│ └── (Place to store scraped JSON files)
└── scripts # Directory for scraper scripts
├── linkedin_scraper.py
├── indeed_scraper.py
└── glassdoor_scraper.py
With these prerequisites in place, you are now ready to run the scripts and build your job board.
Choose target job sites
Identify job sites to scrape, considering factors like volume of job listing, frequency of updates, and reliability of data. Reliable sources enhance the credibility of your job board and improve user satisfaction. Popular options include Indeed, LinkedIn, and Glassdoor. Next, define your target audience by specifying the industries, job types, or locations your job board will focus on.
For this tutorial, we’ll extract data engineer jobs from LinkedIn, Glassdoor, and Indeed in the Texas region. We’ll then display these jobs on our dashboard, including essential details like title, company, location, salary, job description, and application link.
Scraping LinkedIn Jobs
The simplest way to scrape data from LinkedIn is to use the requests and BeautifulSoup libraries. As long as LinkedIn doesn’t detect any suspicious activity, you can retrieve any publicly accessible data without needing authorization. However, there is a significant risk of being blocked if LinkedIn does identify your actions as suspicious.
We already have a detailed blog on Web Scraping LinkedIn Jobs using Python. Give it a read to learn how to build a LinkedIn scraper from scratch.
When scraping small websites, you may not encounter blocking issues. However, scraping large websites, like LinkedIn, can lead to problems such as blocked requests, IP address blocking, blacklisting, and more.
To bypass these restrictions, adopt responsible scraping practices: Respecting the robots.txt file, rotating your IPs, configuring a real user agent, updating your request headers, using CAPTCHA solvers, minimizing your digital footprint, and using a headless browser.
Or, to avoid uncertainties and headaches, you can use a web scraping API, such as Scrapingdog. You no longer need to manually configure proxy rotation using open-source libraries which are less updated. Scrapingdog handles all of this for you with its user-friendly web scraping API. It takes care of rotating proxies, headless browsers, and CAPTCHAs, making the entire process effortless.
After successful free registration, you will get your API key from the dashboard.
Let’s explore the process of scraping LinkedIn Jobs. We’ll use Scrapingdog LinkedIn Job Search API to retrieve pages, eliminating the need for proxies and avoiding blocking issues. Let’s go to the job search page and see what data we can extract.
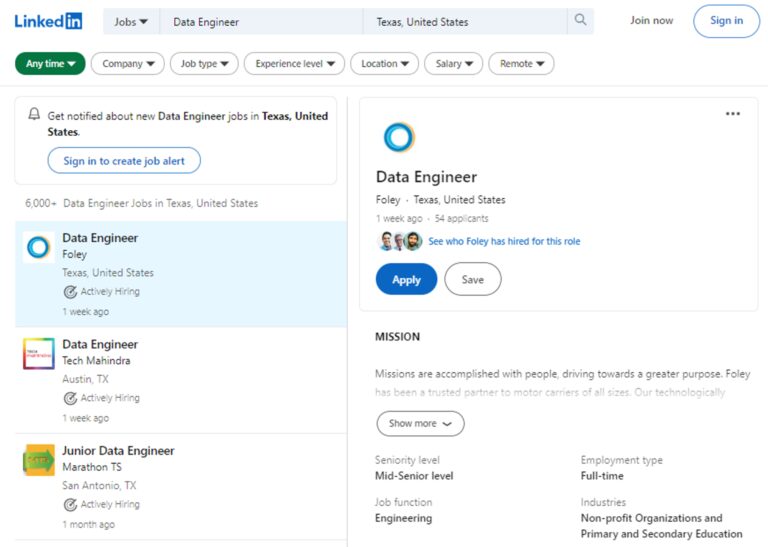
When you search for “Data Engineer” and choose the Texas location, the resulting LinkedIn URL will look something like this: https://www.linkedin.com/jobs/search/?currentJobId=3921441606&geoId=102748797&keywords=data%20engineer&location=Texas%2C%20United%20States&origin=JOB_SEARCH_PAGE_SEARCH_BUTTON&refresh=true
From this URL, we can extract two key pieces of information for our search: keywords and geoId.
Here’s a simple script using Scrapingdog LinkedIn job search API. First, grab your API key and then execute the code below.
import requests
import json
url = "https://api.scrapingdog.com/linkedinjobs/"
params = {
"api_key": "YOUR_API_KEY",
"field": "data%20engineer",
"geoid": "102748797",
"page": "1",
}
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
with open("data/linkedin_jobs.json", "w") as json_file:
json.dump(data, json_file, indent=4)
else:
print("Request failed with status code:", response.status_code)
Specify the field, which is the type of job you want to scrape, followed by the geoid, which is the location ID provided by LinkedIn itself (you can find it in the URL of the LinkedIn jobs page), and finally, the page number.
Once the code runs successfully, you will receive the parsed JSON data from the LinkedIn jobs page. A new file named “linkedin_jobs.json” will be created in the “data” directory.
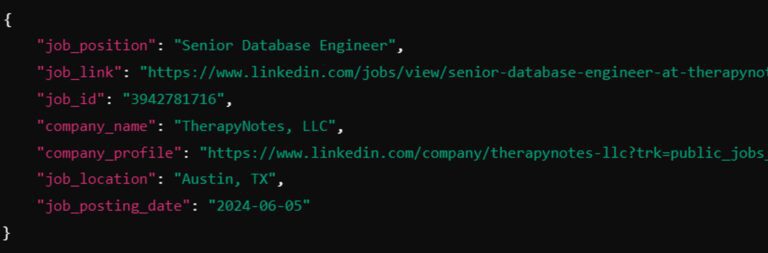
Scraping Indeed Jobs
Let’s proceed to the job search page to find all available data engineer positions in Texas.
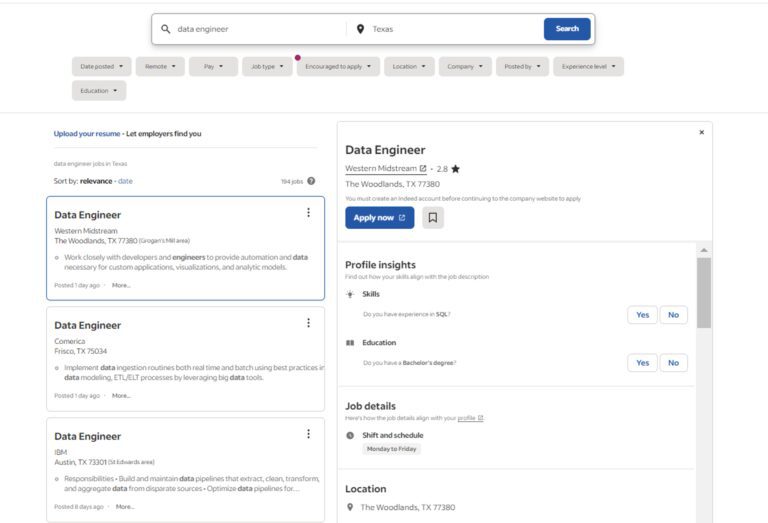
The job list provides a comprehensive overview of available positions. It offers summaries on the left and in-depth details on the right for each position. To gather information, you can either manually navigate to each job or rely on the summaries provided.
We have a complete guide on web scraping Indeed jobs using Python. Check it out to learn how to build an Indeed job scraper from scratch. But keep in mind, that running it at scale will trigger blocks as Indeed uses anti-scraping protection to block web scraper traffic.
To get around this, we can use Scrapingdog web scraping API. Let’s see how Scrapingdog integration can help you bypass these obstacles.
Scrapingdog provides a dedicated Indeed Scraping API with which you can scrape Indeed data at scale. You won’t even have to parse the data because you will already receive it in JSON form. Once you sign up, you will find your API key on your dashboard. You then need to send a GET request to https://api.scrapingdog.com/ indeed with your API key and the target Indeed URL.
When you search for Data Engineer jobs in Texas, you will get this URL: https://indeed.com/jobs?q=data+engineer&l=Texas. You can use this URL as the target Indeed URL in your code.
Here’s the code:
import requests
import json
url = "https://api.scrapingdog.com/indeed"
api_key = "YOUR_API_KEY"
job_search_url = "https://indeed.com/jobs?q=data+engineer&l=Texas"
params = {"api_key": api_key, "url": job_search_url}
response = requests.get(url, params=params)
if response.status_code == 200:
json_response = response.json()
with open("data/indeed_jobs.json", "w") as json_file:
json.dump(json_response, json_file, indent=4)
else:
print(f"Error: {response.status_code}")
print(response.text)
With this script, you will be able to scrape Indeed with a lightning-fast speed that too without getting blocked.
Once the code runs successfully, you will receive the parsed JSON data from the Indeed jobs page. A new file named “indeed_jobs.json” will be created in the “data” directory.
Scraping Glassdoor Jobs
In the same way, you can scrape the Glassdoor jobs. Let’s proceed to the job search page to find all available data engineer positions in Texas.
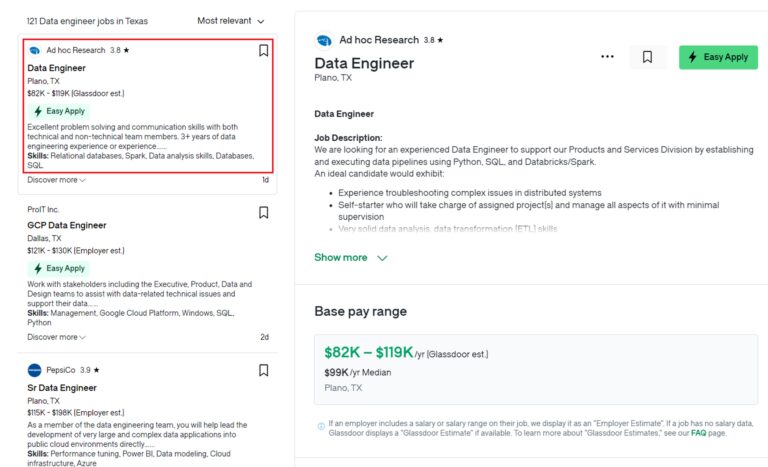
We have a complete guide on web scraping Glassdoor. Check it out to learn how to build a Glassdoor job scraper from scratch. However, when collecting all of this data at scale, you’re very likely to be blocked. So, let’s take a look at how we can avoid this by using the Scrapingdog API.
This is what the URL looks like when you search for data engineer jobs in Texas: https://www.glassdoor.com/Job/texas-us-data-engineer-jobs-SRCH_IL.0,8_IS1347_KO9,22.htm?includeNoSalaryJobs=true.
Now, let’s send an HTTP request to the Glassdoor job URL.
import requests
url = "https://www.glassdoor.com/Job/texas-us-data-engineer-jobs-SRCH_IL.0,8_IS1347_KO9,22.htm?includeNoSalaryJobs=true"
response = requests.get(url)
print(response.status_code)
Running the code will result in a 403 error, indicating Glassdoor’s anti-bot mechanism has flagged your automated data scraping request.

import requests
url = "https://api.scrapingdog.com/scrape?api_key=665eb0542739e1784a9213a2&url=https://www.glassdoor.com/Job/texas-us-data-engineer-jobs-SRCH_IL.0,8_IS1347_KO9,22.htm?includeNoSalaryJobs=true"
response = requests.get(url)
print(response.status_code)
import requests
from bs4 import BeautifulSoup
import json
# URL of the page to scrape
url = "https://api.scrapingdog.com/scrape?api_key=YOUR_API_KEY&url=https://www.glassdoor.com/Job/texas-us-data-engineer-jobs-SRCH_IL.0,8_IS1347_KO9,22.htm?includeNoSalaryJobs=true"
def fetch_page(url):
"""Fetch the content of the page."""
try:
response = requests.get(url)
response.raise_for_status() # Raise HTTPError for bad responses
return response.content
except requests.RequestException as e:
print(f"Error fetching the page: {e}")
return None
def parse_job_listings(html_content):
"""Parse the job listings from the HTML content."""
soup = BeautifulSoup(html_content, "html.parser")
job_listings = soup.select('li[data-test="jobListing"]')
return job_listings
def extract_data(job):
"""Extract data from a single job listing."""
def safe_extract(selector):
element = job.select_one(selector)
return element.get_text(strip=True) if element else None
company = safe_extract(".EmployerProfile_compactEmployerName__LE242")
rating = safe_extract(".EmployerProfile_ratingContainer__ul0Ef span")
job_title = safe_extract(".JobCard_jobTitle___7I6y")
location = safe_extract(".JobCard_location__rCz3x")
salary = safe_extract(".JobCard_salaryEstimate__arV5J")
description = safe_extract(
".JobCard_jobDescriptionSnippet__yWW8q > div:nth-child(1)"
)
skills_element = job.select_one(
".JobCard_jobDescriptionSnippet__yWW8q > div:nth-child(2)"
)
skills = (
skills_element.get_text(strip=True).replace("Skills:", "").strip()
if skills_element
else None
)
data = {
"company": company,
"rating": rating,
"job_title": job_title,
"location": location,
"salary": salary,
"description": description,
"skills": skills,
}
return data
def save_data_to_json(data, filename="data/glassdoor_jobs.json"):
"""Save scraped data to a JSON file."""
with open(filename, "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=4)
def main():
"""Main function to orchestrate the scraping process."""
html_content = fetch_page(url)
if not html_content:
return
job_listings = parse_job_listings(html_content)
if not job_listings:
print("No job listings found.")
return
all_jobs_data = []
for job in job_listings:
job_data = extract_data(job)
all_jobs_data.append(job_data)
save_data_to_json(all_jobs_data)
if __name__ == "__main__":
main()
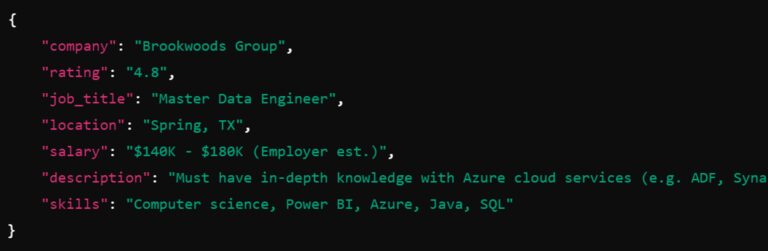
Building your Job Portal
The Flask web app sets up a web server using Flask that scrapes job data from LinkedIn, Glassdoor, and Indeed using separate Python scripts. It combines the scraped data, processes it, and then renders a web page (dashboard.html) displaying the job information.
Now, you can create your own job portal by building a web application using frameworks such as Flask, Django, or FastAPI. Alternatively, you can build a static website using HTML, CSS, and JavaScript. In this example, we will build a Flask web application to showcase job listings.
The web app will set up a web server using Flask and use separate Python scripts to scrape job data from LinkedIn, Glassdoor, and Indeed. It will then combine and process this data before rendering a web page (dashboard.html) to display the job information.
To set up your Flask app, create a new Python file named app.py if it doesn’t already exist, and paste the following code into it.
app.py:
from flask import Flask, render_template
import json
import subprocess
app = Flask(__name__)
def run_scrapers():
try:
subprocess.run(["python", "script/linkedin_scraper.py"])
subprocess.run(["python", "script/indeed_scraper.py"])
subprocess.run(["python", "script/glassdoor_scraper.py"])
except Exception as e:
print(f"Error running scrapers: {e}")
def combine_data():
linkedin_file = "data/linkedin_jobs.json"
with open(linkedin_file, "r", encoding="utf-8") as file:
linkedin_data = json.load(file)
for job in linkedin_data:
job["company_profile"] = job.get("company_profile").replace(
"?trk=public_jobs_jserp-result_job-search-card-subtitle", ""
)
glassdoor_file = "data/glassdoor_jobs.json"
with open(glassdoor_file, "r", encoding="utf-8") as file:
glassdoor_data = json.load(file)
for job in glassdoor_data:
job["salary"] = job.get("salary", "N/A")
job["skills"] = job.get("skills", "N/A")
indeed_file = "data/indeed_jobs.json"
with open(indeed_file, "r", encoding="utf-8") as file:
indeed_data = json.load(file)
for job in indeed_data:
job_descriptions = job.get("jobDescription", [])
job["Description"] = " ".join(
[desc.strip() for desc in job_descriptions if desc.strip()]
) if job_descriptions else "N/A"
with open(indeed_file, "w") as file:
json.dump(indeed_data, file, indent=4)
indeed_data.pop()
return linkedin_data, glassdoor_data, indeed_data
@app.route("/")
def index():
try:
run_scrapers()
linkedin_data, glassdoor_data, indeed_data = combine_data()
return render_template(
"dashboard.html",
linkedin_jobs=linkedin_data,
glassdoor_jobs=glassdoor_data,
indeed_jobs=indeed_data,
)
except Exception as e:
return f"An error occurred: {e}"
if __name__ == "__main__":
app.run(debug=True)
run_scrapers function executes three external Python scripts (linkedin_scraper.py, indeed_scraper.py, glassdoor_scraper.py) using subprocess.run to scrape job data. Any exceptions are caught and printed.The combine_data function reads JSON data from linkedin_jobs.json, glassdoor_jobs.json, and indeed_jobs.json, processing each dataset as follows: - LinkedIn: Cleans up
company_profile URLs. - Glassdoor: Ensures salary and skills fields are set, defaulting to “N/A” if absent.
- Indeed: Concatenates jobDescription entries into a single Description string, defaulting to “N/A” if no descriptions exist.
- The cleaned and combined data is then returned.
- LinkedIn: Cleans up
index Route handles the root URL (/). It runs the scrapers and combines the data. If successful, it renders dashboard.html with the job data from LinkedIn, Glassdoor, and Indeed. If an error occurs, it returns an error message.dashboard.html:
< !DOCTYPE html>
< html
lang="en">
< head>
< meta charset="UTF-8" />
< content="width=device-width, initial-scale=1.0" />
< title>Job Dashboard</title>
< link
rel="stylesheet"
href="{{ url_for('static', filename='styles.css') }}"
/>
< /head>
< body>
< div class="container">
< h2>Data Engineering Job Dashboard< /h2>
< h3 >LinkedIn Jobs< /h3>
< table id="linkedinJobsTable" >
< thead>
< tr>
< th>Job Title</th >
< th >Company< /th>
< th>Location< /th>
< th>Job Link< /th>
< th>Company Profile< /th>
< th>Job Posting Date< /th>
< /tr>
< /thead>
< tbody>
{ % for job in linkedin_jobs % }
< tr>
< td>{{ job['job_position'] }}< /td >
< td>{{ job['company_name'] }}</td>
<td>{{ job['job_location'] }}</td>
<td><a href="{{ job['job_link'] }}" target="_blank">Link</a></td>
< td>{{ job['company_profile'] }}< /td>
< td>{{ job['job_posting_date'] }}< /td>
< /tr>
{% endfor %}
< /tbody>
< /table>
< h3>Indeed Jobs< /h3>
< table id="indeedJobsTable" >
< thead >
< tr >
< th >Job Title< /th>
< th>Job ID</th >
<th>Company</th>
<th >Location</th>
<th>Job Link</th>
<th>Description</th>
<th>Job Posting Date</th>
</tr>
</thead>
<tbody>
{% for job in indeed_jobs %}
<tr>
<td>{{ job['jobTitle'] }}</td>
<td>{{ job['jobID'] }}</td>
<td>{{ job['companyName'] }}</td>
<td>{{ job['companyLocation'] }}</td>
<td><a href="{{ job['jobLink'] }}" target="_blank">Link</a></td>
<td>{{ job['Description'] }} </td>
< td> {{ job['jobPosting'] }} </td>
</tr>
{ % endfor % }
< /tbody >
</table>
< h3 >Glassdoor Jobs< /h3 >
< table id="glassdoorJobsTable">
< thead>
< tr>
< th>Job Title< /th>
< th>Company< /th>
< th>Location< /th>
< th>Salary< /th>
< th>Skills< /th>
<th> Description< /th>
< /tr>
< /thead>
< tbody>
{ % for job in glassdoor_jobs % }
< tr>
< td>{{ job['job_title'] }}</td>
< td>{{ job['company'] }}</td>
< td>{{ job['location'] }}</td>
< td>{{ job['salary'] }}</td>
< td>{{ job['skills'] }}</td>
< td>{{ job['description'] }}</td>
< /tr>
{ % endfor %}
< /tbody>
< /table>
< /div>
< /body>
< /html>
The dashboard.html file is an HTML template used by the Flask application to display job data from LinkedIn, Indeed, and Glassdoor. It leverages the Jinja2 templating engine to dynamically insert job data. The
section is populated with job data using a Jinja2 loop ({% for job in job_list %}), iterating over each job list provided by the Flask app.
Here’s the simple CSS we are using in our job dashboard.
styles.css
/* Reset default browser styles */
body, html {
font-family: Arial, sans-serif;
margin: 0;
padding: 0;
background-color: #f8f9fa; /* Light gray background */
color: #333; /* Dark text color */
}
.container {
max-width: 1200px;
margin: 20px auto;
padding: 20px;
background-color: #fff; /* White background */
/* box-shadow: 0 0 10px #666666; Shadow for container */
border-radius: 8px; /* Rounded corners */
}
h2, h3 {
text-align: center;
margin-bottom: 20px;
color: black; /* #0077FF color for headers */
}
/* Table styles */
table {
width: 100%;
border-collapse: collapse;
margin-bottom: 20px;
/* box-shadow: 0 4px 8px #666666; Shadow for tables */
border-radius: 8px; /* Rounded corners */
overflow: hidden; /* Hide overflow content */
background-color: #fff; /* White background */
}
/* Style for table headers */
table th {
background-color: #3399FF;
color: white;
padding: 12px;
text-align: left;
}
/* Style for table cells */
table td {
padding: 12px;
text-align: left;
vertical-align: top;
}
/* Alternate row colors */
table tbody tr:nth-child(even) {
background-color: #f2f2f2;
}
/* Style links within tables */
table a {
text-decoration: none;
color: #0077FF;
}
table a:hover {
text-decoration: underline;
}
/* Responsive design for tables */
@media screen and (max-width: 768px) {
table {
font-size: 14px;
}
}
@media screen and (max-width: 576px) {
table {
font-size: 12px;
}
}
This configuration allows the Flask application to send job data to the dashboard.html template, where it is presented as a well-organized and styled HTML page for the user to see. Now you can proceed to run your Flask application. You can execute the following command:
python app.py
Your job board is now live!
Go ahead and visit http://127.0.0.1:5000 in your browser to see your job board. It may take some time to load because it runs three scripts, stores data in a JSON file, and then fetches the data from the JSON file to display on the page.
Here’s what it looks like:
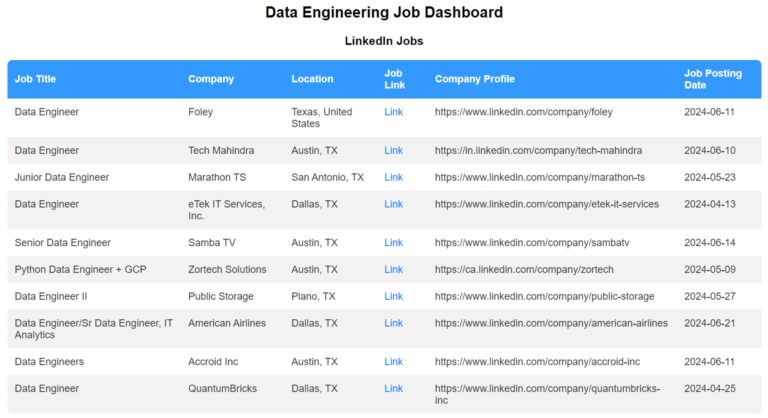
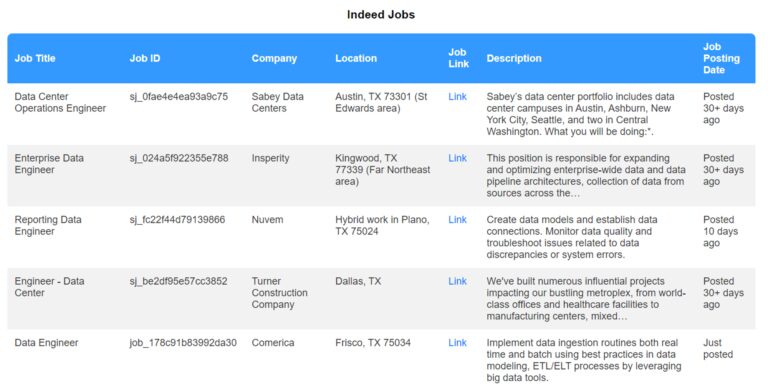
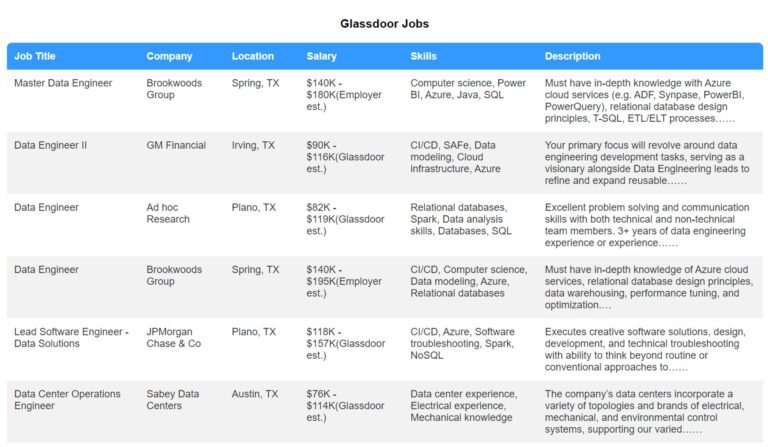
You can customize your job portal for an optimal user experience with features like:
- Responsive design: Ensures mobile-friendliness and seamless experience across devices.
- Search functionality: Allows users to search jobs by keywords, location, company, or other criteria.
- User accounts and personalization: Allows users to create accounts, save search preferences, and receive personalized recommendations.
- Email alerts: Informs users of new listings matching their interests or saved searches.
There are many different options for hosting your Python website, but one of the easiest would be Render.
Additional Considerations
- Ethical Scraping: Check a website’s terms and robots.txt file before scraping it to avoid breaking their rules and getting in trouble.
- Limitations and Challenges: Websites often deploy anti-scraping measures. To overcome these challenges, you might need techniques like headless browsing, rotating proxies, and varying user agents, or leverage specialized scraping tools like Scrapingdog.
- Data Storage: As you continue to scrape job sites, your job listing data will grow. Implement measures to ensure efficient storage, retrieval, and regular updates to keep the data current. This may include setting up scheduled scraping tasks or using caching mechanisms.
- Scalability: As your job portal gains traction, ensure it scales to handle growing traffic and data. Consider implementing load balancing, caching, or migrating to the cloud for increased robustness.
Here are Some Key Takeaways:
The guide explains how to aggregate job listings from platforms like LinkedIn, Indeed, and Glassdoor into one centralized job board.
It demonstrates using Python tools such as
requests,BeautifulSoup, and Flask to scrape and display job data.Scraping at scale requires handling blocks, proxies, and CAPTCHA challenges.
Extracted job data is structured into fields like title, company, location, and salary for easy filtering and display.
A niche job board built through scraping can create monetization opportunities and provide targeted value to specific audiences.
Conclusion
And there you have it—a fully functional job portal, built from scratch, tailored to your audience’s needs. HireTech, is one such website that are scraping job platforms.
This project is more than just a technical exercise. If you feel like having difficulties anywhere in between, you can connect with me through the chat on the website.
Also, this tutorial is perfect if you are building a job scraper, I have tried to cover all major sources in it. If you liked this tutorial, do share it on social media.
Happy Scraping!!


