Sitemaps and robots.txt are two files that almost every website exposes publicly, and together they can give you a near-complete picture of a site’s URL structure. Unlike Google search, you’re not dependent on what Google has chosen to index; you’re looking directly at what the site owner has declared. Here’s how to use each one.
Using sitemaps
A sitemap is an XML file listing all important website pages for search engine indexing. Webmasters use it to help search engines understand the website’s structure and content for better indexing.
Every decent website has a sitemap as it improves Google rankings and is considered a good SEO practice. To learn how to create and optimize one effectively, read the article for practical tips.
Here’s what a standard sitemap looks like:
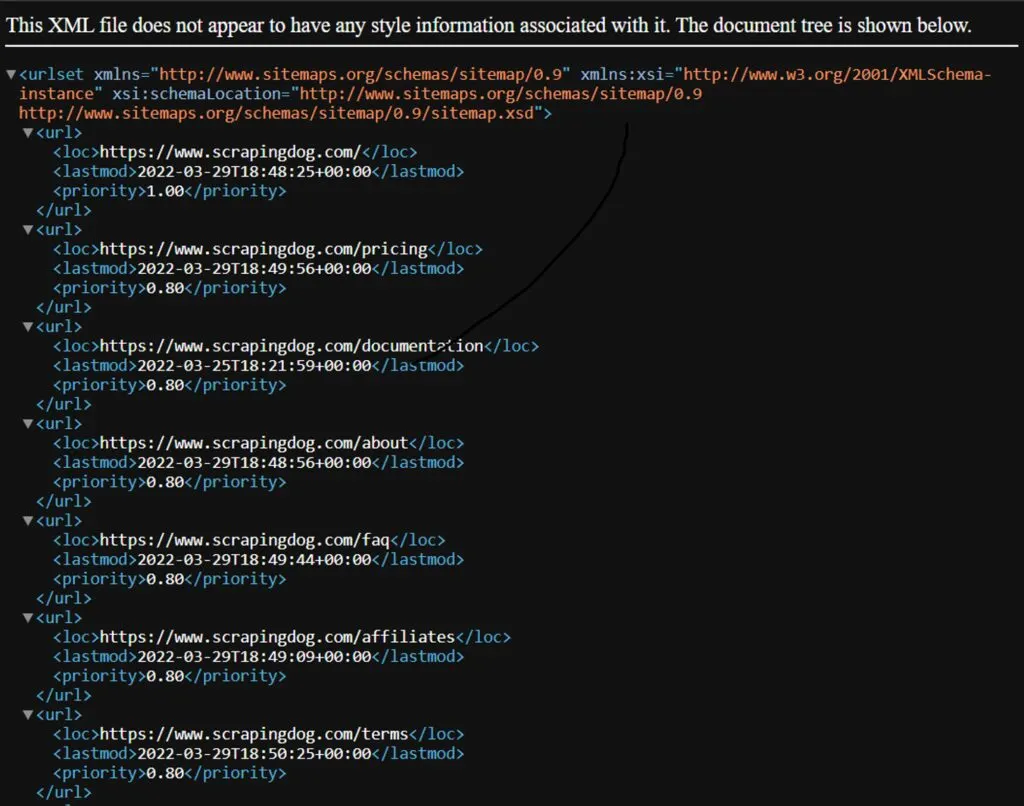
The <loc> element specifies the page URL, <lastmod> indicates the last modification time, and <priority> signifies the relative importance for search engines (higher priority means more frequent crawling).
Now, where to find a sitemap? Check for /sitemap.xml on the website (e.g., https://scrapingdog.com/sitemap.xml)
Websites can have multiple sitemaps in various locations, including: /sitemap.xml.gz, /sitemap_index.xml, /sitemap_index.xml.gz, /sitemap.php, /sitemapindex.xml, /sitemap.gz.
Most websites mention the number of sitemaps they have under the domain in the robots.txt file, which we are going to discuss next.
Using robots.txt
The robots.txt file instructs search engine crawlers on which pages to index and which ones to exclude from indexing. It can also specify the location of the website’s sitemap. The file is often located at the /robots.txt path (e.g., https://scrapingdog.com/robots.txt).
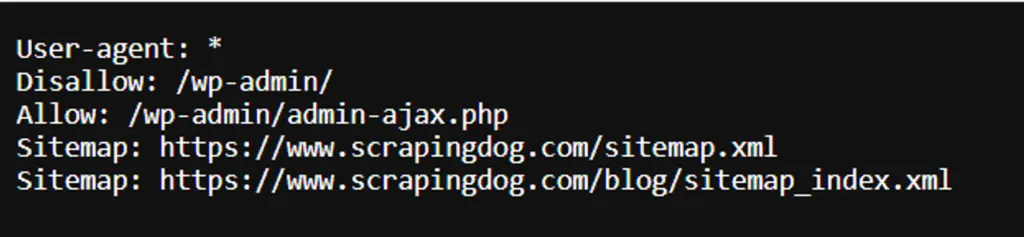
Here’s an example of a robots.txt file. Some routes are disallowed for indexing. The sitemap location is also present.
You need to visit both sitemaps and find all the URLs within the website. Note that, for smaller sitemaps, you can manually copy the URLs from each tag. But for larger sitemaps, consider using an online tool to convert the XML format to a more manageable format, such as CSV. There are free tools available, like the one Seowl sitemap extractor.
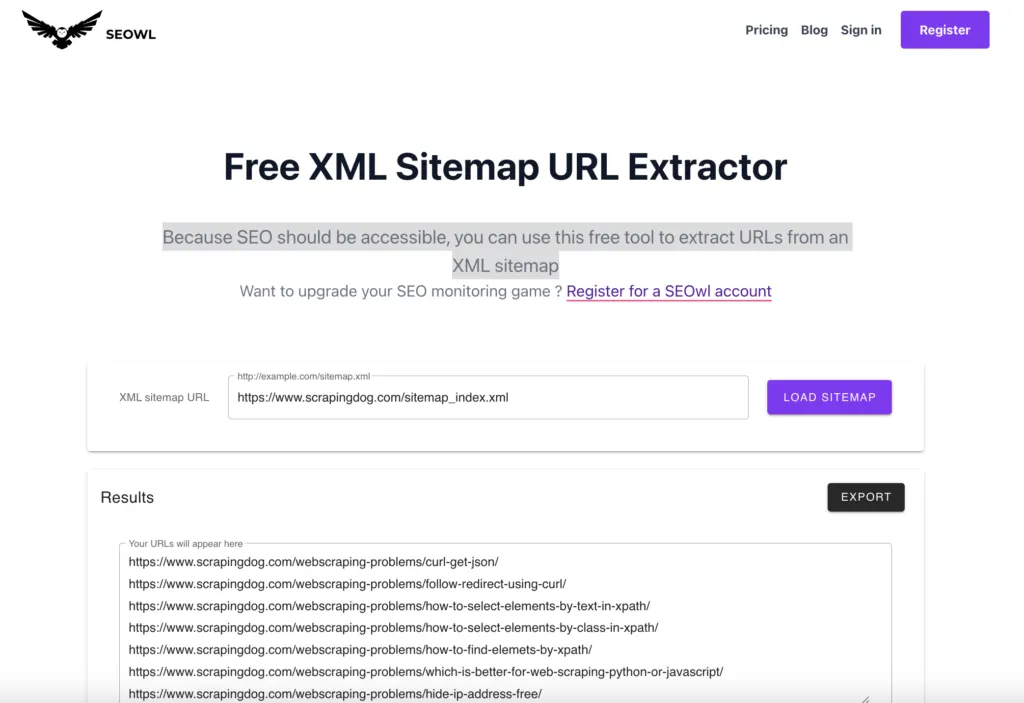
Now let’s see how SEO crawling tools help us find all website pages. There are various SEO crawlers in the market, we’ll explore the free tool XML-Sitemaps.com. Enter your URL and click “START” to create a sitemap. This tool is suitable when you need to quickly create a sitemap for a small website (up to 500) pages.
The process will start and you will see the number of pages scanned (167 in this case) and the number of pages indexed (127 in this case). This indicates that only around 127 of the scanned pages are currently indexed in Google Search.
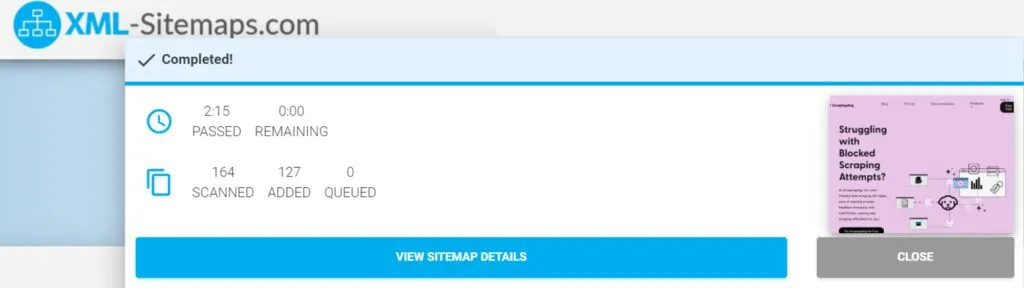
Once the crawling process is complete, the sitemap preview will display all the website’s indexed URLs, including the last modification date and time, as well as the priority of each URL.
You can download the XML sitemap file or receive it via email and put it on your website afterward.
Screamingfrog is another free tool that can help you with exporting URLs from a domain. Keep in mind that the free version allows you to get 500 URLs from a single domain. To use it, you have to download the software on your machine & unlike SaaS, it will crawl the domain from your setup only.
Next, let’s create a Python file (I am naming the file as main.py) and write the code.
If you paste your target website in the Scrapingdog scraper, you will get a ready to use python code.
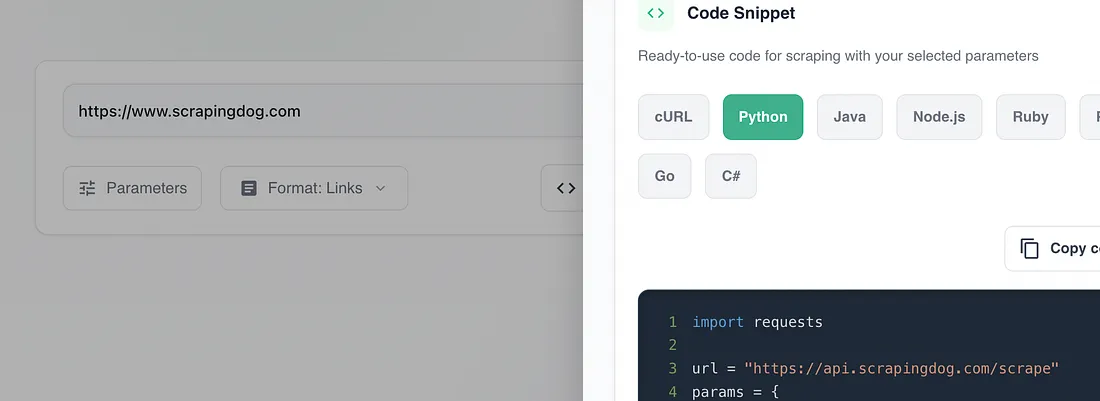
Just copy this code and paste it into the main.py file. I have used format as links, this ensures you get output as links only and not the whole HTML data.
Once you run this code, you will get this JSON response with all the links available on this page.
Now, you can continue making these GET requests to all these URLs using Scrapingdog to extract all the links on that particular domain.
Now, if you want to store all these URLs in a CSV file, you can use Python’s pandas library.
The crawled URLs will be stored in a CSV file, as shown below:

You can read our guide web scraping with python to get more idea on how a scraper can be built using Python.
With four methods on the table, the right choice comes down to your goal, technical comfort, and the size of the site you’re working with. Here’s a quick reference: