
TL;DR
- Ways: manual, extensions, no-code tools, official APIs, services, or a custom script (pros / cons).
- Demo: Python (
requests+BS4) grabs book title, price, rating; code + output. - Workflow: choose targets → inspect DOM (SelectorGadget) → fetch & parse; watch for IP blocks.
- Scale: Scrapingdog handles proxies; AI scraper returns structured JSON; 1,000 free credits.
Extracting data from a website can be a useful skill for a wide range of applications, such as data mining, data analysis, and automating repetitive tasks.
With the vast amount of data available on the internet, being able to get fresh data and analyze it can provide valuable insights and help you make informed & data-backed decisions.
Pulling information can help finance companies whether to buy or sell.
The travel industry can scrape prices & track from their niche market to get a competitive advantage.
Restaurants can use the data as reviews and make necessary changes if some stuff is inappropriate.
Job seekers can scrape resume examples from various sites, which could help them format their resumes.
So, there are endless applications when you pull data from relevant websites.
In this article, we will see various methods for extracting data from a website and provide a step-by-step guide on how to do so.
Methods for extracting data from a website
There are several methods for extracting data from a website, and the best method for you will depend on your specific needs and the structure of the website you are working with.
Here are some common methods for extracting data:
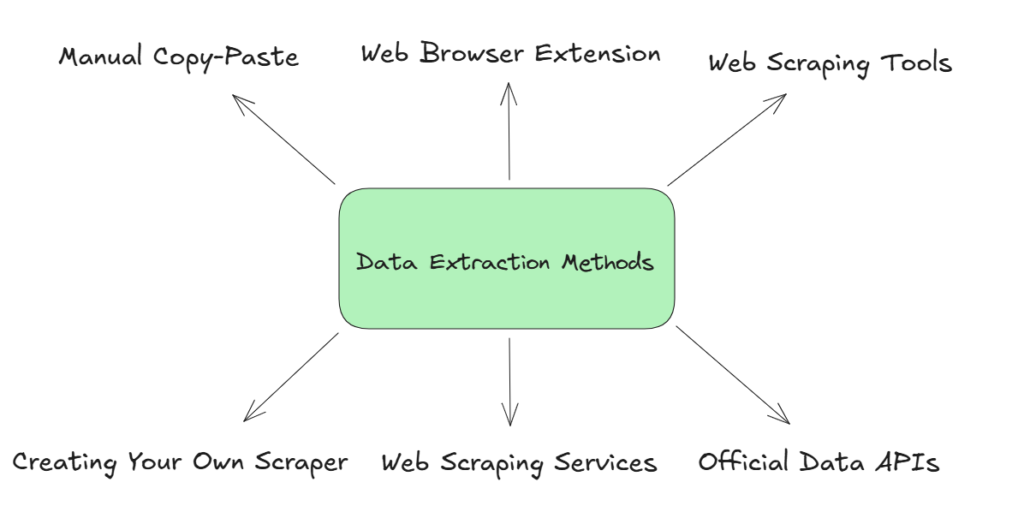
Manual copy and paste
One of the simplest methods for extracting data from a website is to simply copy and paste the data into a spreadsheet or other document. This method is suitable for small amounts of data and can be used when the data is easily accessible on the website.
| Pros | Cons |
|---|---|
| No risk of violating website terms of service | Prone to human error |
| Ideal for ad-hoc, one-time data extractions | Not scalable for ongoing or large tasks |
By Using Web browser extensions
Several web browser extensions can help you in this process.
Some AI Chrome extensions can also automatically identify patterns on a page and extract structured data without manual selector setup.
These extensions can be installed in your web browser and allow you to select and extract specific data points from a website.
| Pros | Cons |
|---|---|
| Easy to install and use directly in the browser | Limited customization options |
| Often free or low-cost solutions available | Can be blocked by websites or outdated with browser updates |
Web scraping tools
There are several no-code tools available that can help you extract data from a website. These tools can be used to navigate the website and extract specific data points based on your requirements.
| Pros | Cons |
|---|---|
| No coding skills required, making it accessible | Often requires a paid subscription |
| Can handle large amounts of data efficiently | Limited flexibility compared to custom scrapers |
Official Data APIs
Many websites offer APIs (Application Programming Interfaces) that allow you to access their data in a structured format. Using an API for web scraping can be a convenient way to extract data from a website, as the data is already organized and ready for use.
However, not all websites offer APIs, and those that do may have restrictions on how the data can be used.
| Pros | Cons |
|---|---|
| Provides structured and reliable data access | Limited to data the API provider chooses to share |
| Typically complies with website terms of service | Often has usage restrictions and rate limits |
Web scraping services
If you don’t want to handle proxies and headless browsers, you can use a web scraping service to extract data from a website. These services handle the technical aspects of web scraping and can provide you with data in your desired output format.
| Pros | Cons |
|---|---|
| Outsources technical complexities, saving time | Can be costly for large-scale projects |
| Handles proxies and IP rotation automatically | Limited control over scraping process |
Creating your own scraper
You can even code your own scraper. Then you can use libraries like BS4 to extract necessary data points out of the raw data.
But this process has a limitation and that is IP blocking. If you want to use this process for heavy scraping then your IP will be blocked by the host in no time. But for small projects, this process is cheaper and more manageable. Many developers combine this approach with ETL tools to efficiently extract, transform, and load data at scale while avoiding common scraping limitations.
Using any of these methods you can extract data and further can do data analysis.
| Pros | Cons |
|---|---|
| Highly customizable to specific data needs | Requires programming skills and maintenance |
| Can bypass limitations of pre-built tools | Risk of IP blocking or website detection |
Creating Our Scraper Using Python to Extract Data
Now that you have an understanding of the different methods for extracting data from a website, let’s take a look at the general steps you can follow to extract data from a website.
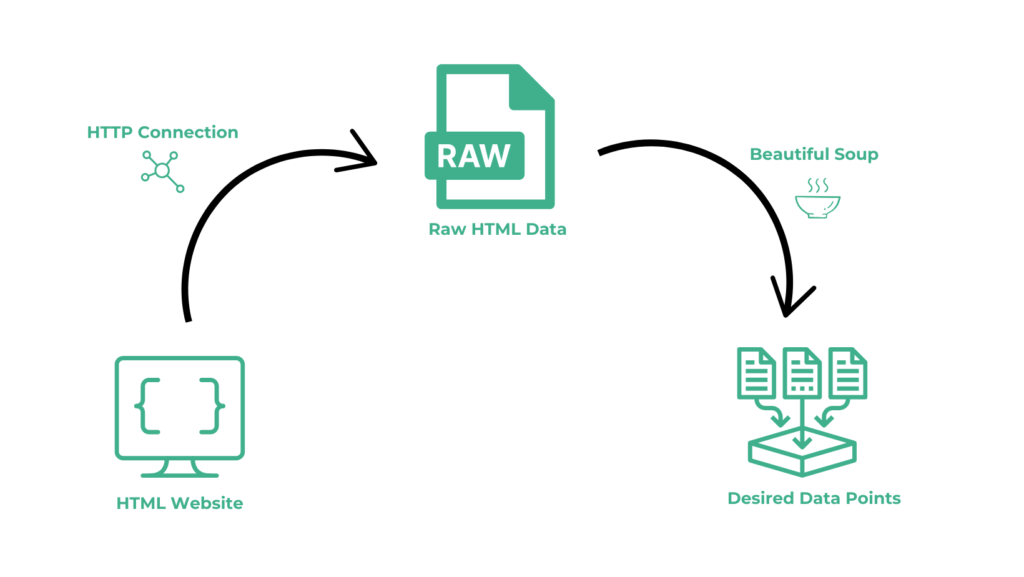
- Identify the data you want: Before you start with the process, it is important to have a clear idea of what data you want to extract and why. This will help you determine the best approach for extracting the data.
- Inspect the website’s structure: You will need to understand how the website is structured and how the data is organized. You can use extensions like Selectorgadget to identify the location of any element.
- Script: After this, you have to prepare a script through which you are going to automate this process. The script is mainly divided into two parts. First, you have to make an HTTP GET request to the target website and in the second part, you have to extract the data out of the raw HTML using some parsing libraries like BS4 and Cheerio.
Let’s understand with an example. We will use Python for this example.
Also if you are new to Web scraping or Python, I have a dedicated guide on it. Do check it out!!
I am assuming that you have already installed Python on your machine.
The reason behind selecting Python is that it is a popular programming language that has a large and active community of developers, and it is well-suited for web scraping due to its libraries for accessing and parsing HTML and XML data.
For this example, we are going to install two Python libraries.
- Requests will help us to make an HTTP connection with Bing.
- BeautifulSoup will help us to create an HTML tree for smooth data extraction.
At the start, we are going to create a folder where we will store our script. I have named the folder “dataextraction”.
>> mkdir dataextraction
>> pip install requests
>> pip install beautifulsoup4
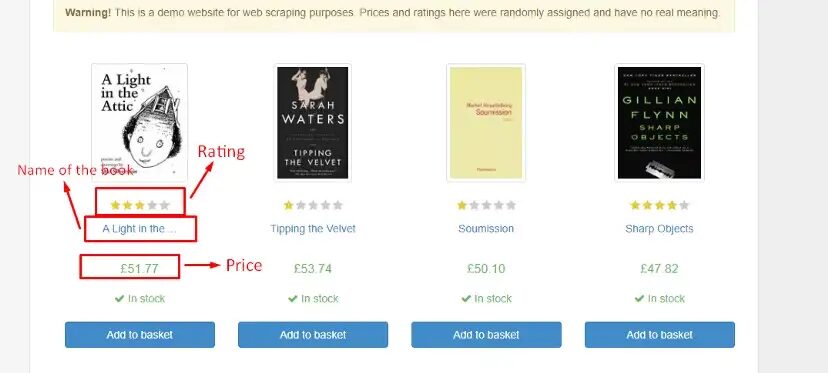
We will scrape this webpage. We will extract the following data from it:
- Name of the book
- Price
- Rating
Let’s import the libraries that we have installed.
import requests
from bs4 import BeautifulSoup
The next step would be to fetch HTML data from the target webpage. You can use the requests library to make an HTTP request to the web page and retrieve the response.
l=[]
o={}
target_url="http://books.toscrape.com/"
resp = requests.get(target_url)
Now let’s parse the HTML code using Beautiful Soup. You can use the BeautifulSoup constructor to create a Beautiful Soup object from the HTML, and then use the object to navigate and extract the data you want.
soup = BeautifulSoup(resp.text,'html.parser')
Before moving ahead let’s find the DOM location of each element by inspecting them.
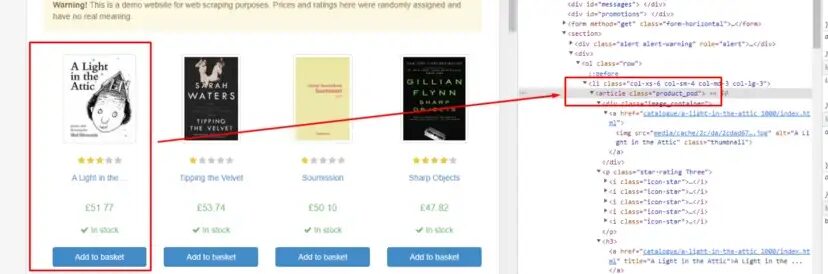
article tag holds all the book data. So, it will be better for us to extract all these tags inside a list. Once we have this we can extract all the necessary details for any particular book.

Rating is stored under the class attribute of tag p. We will use .get() method to extract this data.
o["rating"]=allBooks[0].find("p").get("class")[1]

The name of the book is stored inside the title attribute under the h3 tag.
o["name"]=allBooks[0].find("h3").find("a").get("title")

Similarly, you can find the price data stored inside the p tag of class price_color.
o["price"]=allBooks[0].find("p",{"class":"price_color"}).text
Complete Code
Using a similar technique you can find data from all the books. Obviously, you will have to run for a loop for that. But the current code will look like this.
import requests
from bs4 import BeautifulSoup
l=[]
o={}
target_url="http://books.toscrape.com/"
resp = requests.get(target_url)
soup = BeautifulSoup(resp.text,'html.parser')
allBooks = soup.find_all("article",{"class":"product_pod"})
o["rating"]=allBooks[0].find("p").get("class")[1]
o["name"]=allBooks[0].find("h3").find("a").get("title")
o["price"]=allBooks[0].find("p",{"class":"price_color"}).text
l.append(o)
print(l)
The output will look like this.
[{'rating': 'Three', 'name': 'A Light in the Attic', 'price': '£51.77'}]
How Scrapingdog can help you extract data from a website?
You can scrape data using any programming language. We used Python in this blog, however, if you want to scale up this process you would need proxies.
Scrapingdog solves the hassle of integrating proxies and gives you a pretty straightforward Web Scraping API.
You can watch the video tutorial below to understand more on how Scrapingdog can help you pull the data from any website. ⬇️
Using the API you can create a seamless unbreakable data pipeline that can deliver you data from any website. We use a proxy pool of over 10M IPs which rotates on every request, this helps in preventing any IP blocking.
We offer 1000 free credits to spin it for testing purpose. You can sign up from here and check the API on your desired website.
How To Use Scrapingdog’s AI Web Scraping API To Extract Structured Data
With the general web scraping, Scrapingdog also provides an AI-enabled web scraper that can be used to feed data to LLMs. The data it gives is in structured JSON or Markdown format.
You can easily test this API on Scrapingdog’s dashboard. ⬇️
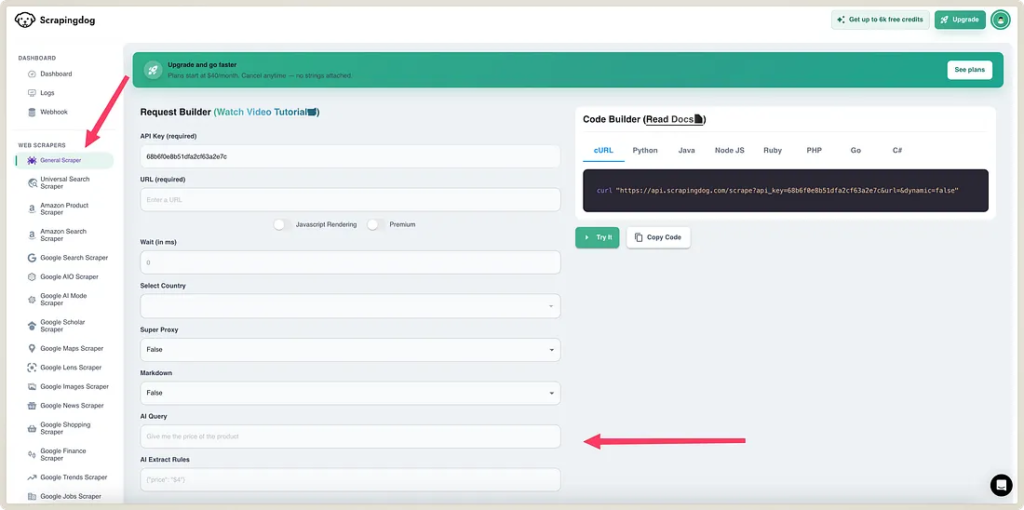
In the general scraper section, you can put in a URL as an input from which you want to take structured data out. And in the parameter “AI Query” you can tell AI to get you the desired data. (I am hoping you are signed up for Scrapingdog to test it)
To better understand this, suppose I want to extract a summary of a webpage, I will put the URL (in URL Parameter)— https://www.searchenginejournal.com/google-says-gsc-sitemap-uploads-dont-guarantee-immediate-crawls/554747/
And in the AI query param, I will write “Give the summary of the webpage in JSON, summarize the page in 5 points.”
The output returned is JSON as we asked: –
{
"points": [
"Google's John Mueller explained that uploading sitemaps does not guarantee immediate crawling of URLs and there are no fixed timelines for recrawling.",
" Submitting the main sitemap.xml file is sufficient; individual granular sitemaps are not necessary according to Mueller.",
"Using the URL Inspection tool can help request crawling for specific pages, but it only supports one URL at a time.",
" While uploading all sitemaps containing changed URLs may provide reassurance, it is not mandatory for indexing.",
" There is no guarantee or specific timeframe for when Google will crawl URLs listed in sitemaps."
]
}
Below is a quick video that shows how our dashboard works while using this scraper ⬇️
Via this way, you can summarize web pages at scale, and each time you can get structured data in the output.
You can further add rules by using “AI Extract Rules” to get data with desired data points. This feature can also be used to keep an eye on competitors for price monitoring.
Here are 5 Key Takeaways:
- Demonstrates how to extract structured data from websites using web scraping techniques.
- Explains handling HTML parsing and navigating the site’s DOM structure.
- Shows how to manage common scraping challenges like pagination and dynamic content.
- Highlights the use of tools/APIs to handle proxies and bot-protection.
- Provides example code (e.g., Python) to automate data extraction workflows.
FAQ (Frequently Asked Questions)
1. What is the easiest way to extract data from a website for beginners?
For beginners, the simplest methods are manual copy-paste or using browser extensions. These approaches require no coding and work well for small datasets or one-time tasks. However, they are not scalable, can be error-prone, and are impractical for large websites or repeated extraction.
2. How to extract company name and address from a webpage?
You can extract company name and address by locating their HTML elements and using a scraper or parser. For small projects, Python libraries like BeautifulSoup can fetch text from specific tags or classes. For dynamic or large-scale sites, tools like Scrapingdog can automatically extract structured company details in JSON or Markdown, handling JavaScript and proxies for reliable results.
3. When should you use web scraping tools instead of writing your own scraper?
Web scraping tools are ideal when you need consistent, large-scale data extraction without worrying about proxies, IP rotation, or JavaScript rendering. Writing your own scraper works for small projects, but tools and services like Scrapingdog save time, reduce maintenance, and provide structured output for analytics or automation.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:


