First the Builder class from the Selenium WebDriver library is imported to create a new WebDriver instance for browser automation. Then a new WebDriver instance is created to automate Google Chrome. The browser instance is launched using the build() method. In the next step, the driver navigates to scrapingdog.com.
After the browser launches a message is printed for confirmation. Then we are closing the driver using .quit() method.

Using .getPageSource() function we are extracting the raw HTML of the target website. Then finally before closing the browser, we print the raw HTML on the console.
Once you run this code you will see this as a result.
Now, if I want to parse the title and rating of the movies on this page, I have to use the By class to search for a particular CSS selector.

In the above image, you can see that the title of the movie is located inside .ipc-title — title a
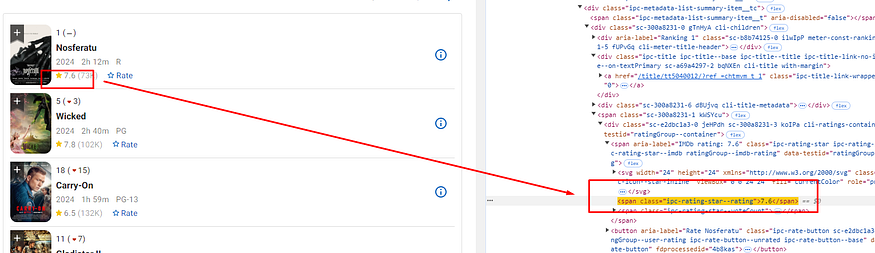
The rating part is stored inside the span tag with the CSS selector .ipc-rating-star — imdb span:nth-child(2)
Let’s parse this data using By.
In the above code, I am using .findEements() in order to search for those CSS selectors in the DOM.
Then with the help of a for loop, I am iterating over all the movies and printing their names and ratings. Once you run this code you should see this.

There is a while loop in the above code which keeps running until the height of the page no longer changes after scrolling, which indicates that no more content is being loaded.
Once the currentHeight becomes equal to lastHeight then only the loop will break.

Once you run the code you will see the browser will navigate to google.com and then it will type the input search query and hit the enter button on its own. Read more about sendKeys here.



