TL;DR
- Playwright + Node.js setup, launch, and first run.
- Scrape flow: load page → grab HTML → parse with
Cheerio(IMDb demo). - Techniques:
waitForSelector, infinite scroll loop, type / click flows. - Use proxies for scale; Playwright is powerful, but for hands-off scaling the article recommends Scrapingdog.
Playwright has quickly become the go-to browser automation library for web scraping in Node.js. Unlike simple HTTP clients, it runs a real browser — meaning it handles JavaScript-rendered pages, dynamic content, infinite scroll, and complex user interactions out of the box.
In this guide, you will learn how to scrape websites using Playwright and Node.js from scratch. We’ll cover everything from basic setup to advanced techniques like waiting for elements, handling infinite scroll, form interactions, stealth mode, and using proxies at scale.
By the end, you’ll have a complete scraping toolkit ready to use on any website.
What is Playwright?
Playwright is an open-source browser automation library developed by Microsoft. It allows you to control real browsers like Chromium, Firefox, and WebKit programmatically using Node.js, Python, Java, or .NET.
Unlike traditional HTTP scraping libraries, Playwright renders pages exactly like a real user’s browser does. This makes it capable of handling JavaScript-heavy websites, dynamic content, single-page applications (SPAs), and complex user interactions like clicks, form fills, and infinite scroll.
It was built as a successor to Puppeteer, with broader browser support and a more reliable auto-waiting mechanism that eliminates most timing-related scraping failures.
Why Use Playwright for Web Scraping?
Here’s why developers prefer Playwright over other scraping tools:
- Handles dynamic content — Renders JavaScript before extracting data, so you never miss content that loads after the initial page request.
- Auto-waiting — Automatically waits for elements to be visible and ready before interacting, eliminating most timing errors and flaky scripts.
- Multi-browser support — Run the same scraping code across Chromium, Firefox, and WebKit without any modification.
- Multiple languages — Works with Node.js, Python, Java, and .NET, so it fits whatever stack you’re already using.
- Request interception — Block images, CSS, and unnecessary resources to speed up scraping significantly.
- Built-in stealth capabilities — Harder to detect than older tools like Selenium, with better fingerprint handling out of the box.
- Screenshot & PDF support — Capture page screenshots or generate PDFs natively, useful for visual debugging.
Setup
Make sure you have Node.js installed on your machine. If not, download it from the official Node.js website.
Once Node.js is ready, create a new project folder and initialize it:
mkdir playwright-scraper
cd playwright-scraper
npm init -y
Then install Playwright and Cheerio. Cheerio will be used for parsing the raw HTML extracted by Playwright:
npm install playwright cheerio
Once Playwright is installed you have to install a browser as well.
npx playwright install
Next, install the browsers Playwright needs to run:
npx playwright install
That’s all the setup you need. Let’s run a quick test to confirm everything is working.
How to run Playwright with Nodejs
Create a new file test.js and add the following code:
const { chromium } = require('playwright');
async function playwrightTest() {
const browser = await chromium.launch({ headless: false });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://scrapingdog.com');
console.log(await page.title());
await browser.close();
}
playwrightTest();
Here’s what each step does:
chromium.launch()launches a Chromium browser instance and settingheadless: falseopens a visible browser window, useful for debugging.browser.newContext()creates an isolated browser context, similar to a fresh browser profile.context.newPage()opens a new tab inside that context.page.goto()navigates to the target URLpage.title()fetches the page title and logs it to the consolebrowser.close()shuts down the browser and frees up resources.
Run it with:
node test.js

This completes the testing of our setup.
How to scrape with Playwright and Nodejs
In this section we are going to scrape the IMDb Most Popular Movies page and extract movie titles and ratings.
First, let’s grab the raw HTML of the page using page.content():
const { chromium } = require('playwright');
async function playwrightTest() {
const browser = await chromium.launch({
headless: false, // Set to true in production
args: ['--disable-blink-features=AutomationControlled']
});
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://www.imdb.com/chart/moviemeter/');
console.log(await page.content());
await browser.close();
}
playwrightTest();
With page.content() method we are extracting the raw HTML from our target webpage. Once you run the code you will see this on your console.

You must be thinking that this data is just garbage. Well, you are right we have to parse the data out of this raw HTML and this can be done with a parsing library like Cheerio.
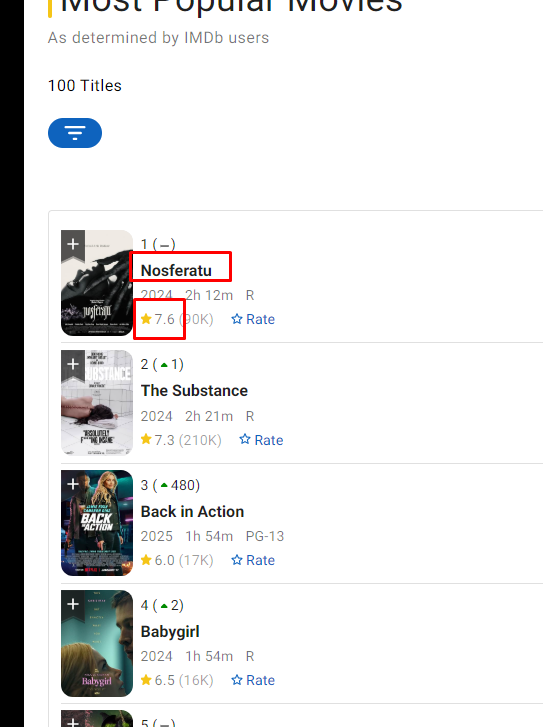
We are going to parse the name of the movie and the rating. Let’s find out the DOM location of each element.
Every movie data is stored inside a li tag with the class ipc-metadata-list-summary-item.

If you go inside this li tag you will see that the title of the movie is located inside a h3 tag with class ipc-title__text.

The rating is located inside the span tag with class ipc-rating-star — rating.
const { chromium } = require('playwright');
const cheerio = require('cheerio');
async function playwrightTest() {
let obj = {};
let arr = [];
const browser = await chromium.launch({ headless: false });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://www.imdb.com/chart/moviemeter/');
const html = await page.content();
const $ = cheerio.load(html);
$('li.ipc-metadata-list-summary-item').each((i, el) => {
obj['Title'] = $(el).find('h3.ipc-title__text').text().trim();
obj['Rating'] = $(el).find('span.ipc-rating-star--rating').text().trim();
arr.push(obj);
obj = {};
});
console.log(arr);
await browser.close();
}
playwrightTest();
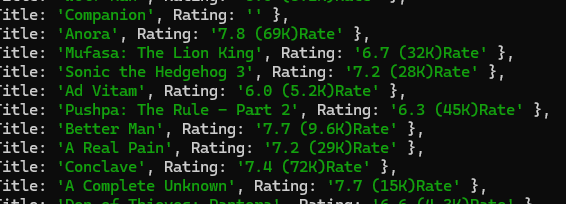
We use Cheerio’s each() to iterate over every li tag, extract the title and rating, push them into an array, and log the final result. You should see a clean array of movie objects printed to your console.
Before closing the browser, we are going to print the output.
How to wait for an element in Playwright
When scraping dynamic websites, content often loads asynchronously after the initial page load. If you try to extract data before the target element appears in the DOM, your scraper will either return empty results or throw an error. This is where page.waitForSelector() comes in.
const { chromium } = require('playwright');
const cheerio = require('cheerio')
async function playwrightTest() {
const browser = await chromium.launch({
headless: false
});
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://www.imdb.com/chart/moviemeter/');
await page.waitForSelector('h1.ipc-title__text')
await browser.close();
}
playwrightTest()
Here we are waiting for the title to appear before we close the browser.
How to do Infinite Scrolling with Playwright
Many e-commerce websites have infinite scrolling and you might have to scroll down in order to scroll the whole page.
const { chromium } = require('playwright');
const cheerio = require('cheerio')
async function playwrightTest() {
const browser = await chromium.launch({
headless: false
});
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://www.imdb.com/chart/moviemeter/');
let previousHeight;
while (true) {
previousHeight = await page.evaluate('document.body.scrollHeight');
await page.evaluate('window.scrollTo(0, document.body.scrollHeight)');
await page.waitForTimeout(2000); // Wait for new content to load
const newHeight = await page.evaluate('document.body.scrollHeight');
if (newHeight === previousHeight) break;
}
await browser.close();
}
playwrightTest()
We are using while(true) to keep scrolling until we no longer have any new content loading. await page.evaluate(‘window.scrollTo(0, document.body.scrollHeight)’) Scrolls the page to the bottom by setting the vertical scroll position (window.scrollTo) to the maximum scrollable height. Once newHeight and previousHeight becomes equal we are breaking out of the loop.
Let’s see this in action.

How to type and click
In this example, we are going to simply visit www.google.com, enter a query, and click on the enter button. After that, we are going to scrape the results using page.content() method.
const { chromium } = require('playwright');
const cheerio = require('cheerio')
async function playwrightTest() {
const browser = await chromium.launch({
headless: false
});
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://www.google.com');
await page.fill('textarea[name="q"]', 'Scrapingdog');
await page.press('textarea[name="q"]', 'Enter');
await page.waitForTimeout(3000);
console.log(await page.content())
await browser.close();
}
playwrightTest()
We are simply visiting google.com then we are typing ‘Scrapingdog’ in the search query using fill() method and then using the press() method we pressed the Enter button.

How to Use Proxies with Playwright
If you want to scrape a few hundred pages then old traditional methods are fine but if you want to scrape millions of pages then you have to use proxies in order to bypass IP banning.
const browser = await chromium.launch({
headless: false,
proxy: {
server: 'http://IP:PORT',
username: 'PASSWORD',
password: 'USERNAME'
}
});
server specifies the proxy server’s address in the format: protocol://IP:PORT. username and password are the credentials for accessing that private IP. If it is public, you might not need a username and password.
How to take a screenshot
Playwright has a built-in screenshot() method that lets you capture the current state of any page. This is particularly useful for debugging — if your scraper is returning unexpected results, a screenshot tells you exactly what the browser was seeing at that moment.
const { chromium } = require('playwright');
async function playwrightTest() {
const browser = await chromium.launch({ headless: false });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://www.imdb.com/chart/moviemeter/');
await page.waitForSelector('h1.ipc-title__text');
await page.screenshot({ path: 'imdb.png' });
console.log('Screenshot saved!');
await browser.close();
}
playwrightTest();
This saves a screenshot of the visible viewport as imdb.png in your project folder. If you want to capture the entire page including content below the fold, add fullPage: true:
await page.screenshot({ path: 'imdb-full.png', fullPage: true });
You can also capture a specific element rather than the entire page:
const element = await page.$('h3.ipc-title__text');
await element.screenshot({ path: 'title.png' });
This is handy when you only need to visually inspect a particular part of the page rather than the whole thing.
How to handle pagination
Most websites split their data across multiple pages. Instead of manually visiting each page, you can automate pagination by detecting and clicking the “Next” button repeatedly until it no longer exists.
Let’s use GitHub’s topic page as an example:
const { chromium } = require('playwright');
const cheerio = require('cheerio');
async function playwrightTest() {
const browser = await chromium.launch({ headless: false });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://github.com/topics/nodejs');
let results = [];
let hasNextPage = true;
while (hasNextPage) {
await page.waitForSelector('article.border');
const html = await page.content();
const $ = cheerio.load(html);
$('article.border').each((i, el) => {
results.push({
name: $(el).find('h3 a').last().text().trim(),
description: $(el).find('div.px-3 p').text().trim(),
stars: $(el).find('a[href*="stargazers"]').text().trim()
});
});
const nextButton = await page.$('a[rel="next"]');
if (nextButton) {
await nextButton.click();
await page.waitForTimeout(2000);
} else {
hasNextPage = false;
}
}
console.log(results);
await browser.close();
}
playwrightTest();
Here’s how the pagination logic works. On each iteration, we wait for the content to load, extract the data using Cheerio, then check if a “Next” button exists using page.$(). If it does, we click it and wait for the next page to load. If it doesn’t, we set hasNextPage to false and break out of the loop.
This pattern works on the vast majority of paginated websites. Just swap out the “Next” button selector to match your target site.
Scaling with Scrapingdog
Playwright is an excellent tool for scraping dynamic websites, but it comes with some real limitations once you try to scale:
- Resource heavy — Running a full browser instance consumes significant RAM and CPU. Spinning up dozens of concurrent Playwright instances will quickly overwhelm even a powerful server.
- Easy to detect — Despite its stealth capabilities, headless browsers leave fingerprints that sophisticated anti-bot systems like Cloudflare, Akamai, and DataDome can detect. You’ll start seeing CAPTCHAs and IP bans as soon as you scale up.
- Proxy management — You need to source, rotate, and manage proxies yourself. A single IP will get banned fast on most popular websites.
- Maintenance overhead — Websites change their DOM structure regularly. Every change can break your scraper and requires manual fixes.
- Slow — Browser-based scraping is inherently slower than API-based approaches, making large-scale data collection time-consuming and expensive.
This is where Scrapingdog’s JavaScript Rendering API comes in. Instead of managing browsers, proxies, and anti-bot bypasses yourself, Scrapingdog handles all of it behind a single API call. It renders JavaScript just like Playwright does, but at scale with automatic proxy rotation, CAPTCHA solving, and bot detection bypass built in.
Here’s the same IMDb scrape done with Scrapingdog instead:
const cheerio = require('cheerio');
async function scrapeWithScrapingdog() {
const response = await axios.get('https://api.scrapingdog.com/scrape', {
params: {
api_key: 'YOUR_API_KEY',
url: 'https://www.imdb.com/chart/moviemeter/',
dynamic: true // enables JS rendering
}
});
const $ = cheerio.load(response.data);
const results = [];
$('li.ipc-metadata-list-summary-item').each((i, el) => {
results.push({
title: $(el).find('h1.ipc-title__text').text().trim(),
rating: $(el).find('span.ipc-rating-star--rating').text().trim()
});
});
console.log(results);
}
scrapeWithScrapingdog();
No browser setup, no proxy rotation, no bot detection headaches — just clean data with a simple GET request. You can scrape any JavaScript-rendered page at any scale without worrying about infrastructure.
Try Scrapingdog free with 1,000 credits — no credit card required.
Playwright vs Puppeteer vs Selenium
Choosing the right browser automation tool depends on your specific use case. Here’s how the three compare:
Browser Support
- Playwright — Chromium, Firefox, and WebKit (Safari) out of the box
- Puppeteer — Chromium and Firefox only
- Selenium — All major browsers including Chrome, Firefox, Safari, and Edge
Language Support
- Playwright — Node.js, Python, Java, and .NET
- Puppeteer — JavaScript and TypeScript only
- Selenium — JavaScript, Python, Java, Ruby, C#, and more
Auto-Waiting
- Playwright — Built-in auto-waiting for elements before every action
- Puppeteer — Manual waits required in most cases
- Selenium — Manual waits required, prone to timing errors
Speed
- Playwright — Fast, supports parallel execution across multiple browser contexts
- Puppeteer — Fast, but limited to single browser contexts per instance
- Selenium — Slowest of the three due to WebDriver protocol overhead
Anti-Bot Detection
- Playwright — Harder to detect than Selenium, stealth plugins available
- Puppeteer — Moderate detection risk, stealth plugins available
- Selenium — Easiest to detect, frequently blocked by anti-bot systems
Ease of Use
- Playwright — Modern API, excellent documentation, easy setup
- Puppeteer — Simple API, large community, well documented
- Selenium — Steeper learning curve, more boilerplate code required
Best For
- Playwright — Web scraping, end-to-end testing, dynamic content extraction
- Puppeteer — Quick scraping tasks, Chrome-specific automation
- Selenium — Cross-browser testing, legacy projects, enterprise environments
Overall, Playwright is the best choice for web scraping in 2026. It combines the speed of Puppeteer with broader browser support, better reliability through auto-waiting, and stronger anti-detection capabilities, all in a modern, well-maintained package.
Here are Some Key Takeaways:
- Playwright is a browser automation framework for Node.js that allows you to control real browsers for scraping and testing.
- It can handle dynamic, JavaScript-heavy websites that traditional HTTP requests cannot properly scrape.
- The guide walks through setting up Playwright in a Node.js environment and launching a browser instance.
- You can automate user-like actions such as clicking buttons, filling forms, waiting for elements, and extracting rendered content.
- Playwright is useful for web scraping, end-to-end testing, and automating complex browser workflows.
Conclusion
Playwright, with its robust and versatile API, is a powerful tool for automating browser interactions and web scraping in Node.js. Whether you’re scraping data, waiting for elements, scrolling, or interacting with complex web elements like buttons and input fields, Playwright simplifies these tasks with its intuitive methods. Moreover, its support for proxies and built-in features like screenshot capturing and multi-browser support make it a reliable choice for developers.
I understand that these tasks can be time-consuming, and sometimes, it’s better to focus solely on data collection while leaving the heavy lifting to web scraping APIs like Scrapingdog. With Scrapingdog, you don’t have to worry about managing proxies, browsers, or retries — it takes care of everything for you. With just a simple GET request, you can scrape any page effortlessly using this API.
If you found this article helpful, please consider sharing it with your friends and followers on social media!