
TL;DR
- Python tutorial: render Airbnb search with
Selenium, parse withBeautifulSoup. - Extract property title, rating, price, and price with tax; export to
CSV. - DIY is fine for small runs; expect blocks at scale.
- For scale, switch to Scrapingdog (handles JS & rotating IPs); 1,000 free credits to test.
Airbnb is one of the major websites that travelers go to. Scraping Airbnb data with Python can give you a lot of insights into how the travel market is working currently. Further, trends can be analyzed in how the pricing deviates over the period.
Alrighty, now before diving into the main context of this blog, If you are new to web scraping, I would recommend you to go through the basics of web scraping with Python.
Let’s get started!!
Setting up the prerequisites for scraping Airbnb
For this tutorial, you will need Python 3.x on your machine. If it is not installed then you can download it from here. We will start by creating a folder where we will keep our Python script.
mkdir airbnb
Inside this folder, we will install two libraries that will be used in the course of this tutorial.
- Selenium– It is used to automate web browser interaction from Python.
- Beautiful Soup is a Python library for parsing data from the raw HTML downloaded using Selenium.
- Chromium– It is a web browser that will be controlled through selenium. You can download it from here.
pip install bs4 pip install selenium

Once all the libraries are installed we can now create a Python file where we will write the code for the scraper. I am naming this file as scraper.py.
What are we going to scrape?
For this tutorial, we are going to scrape this page.
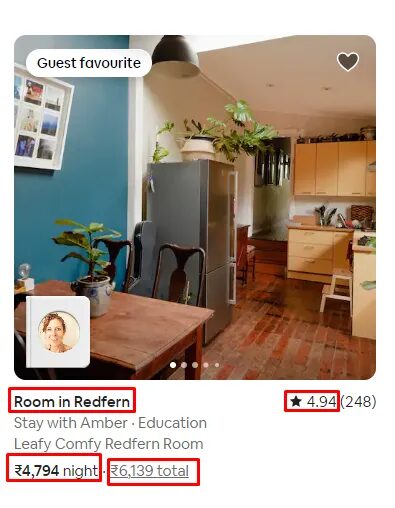
We are going to scrape mainly four data points from this page.
- Name of the property
- Rating
- Price per night
- Price per night with tax
The procedure to execute this task is very simple.
- First, we are going to download the raw HTML using Selenium.
- Then using BS4 we are going to parse the required data.
Downloading the raw data using Selenium
Before writing the script let’s import all the libraries that will be used in this tutorial.
from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.chrome.service import Service import time
from bs4 import BeautifulSoupImports theBeautifulSoupclass from
thebs4module. BeautifulSoup is a popular Python library for parsing HTML and XML documents.from selenium import webdriverImports thewebdrivermodule from
theseleniumpackage. Selenium is a web automation tool that allows you to control web browsers
programmatically.from selenium.webdriver.chrome.service import ServiceImports theServiceclass
from theselenium.webdriver.chrome.servicemodule. This is used to configure the ChromeDriver
service.import timeImports thetimemodule, which provides various time-related
functions. We will use it for the timeout.
PATH = 'C:\Program Files (x86)\chromedriver.exe'
Then we have declared a PATH variable that shows the location of the chrome driver. In your case, the location string can be different.
service = Service(executable_path=PATH) options = webdriver.ChromeOptions() driver = webdriver.Chrome(service=service, options=options)
The executable_path parameter specifies the path to the chromedriver executable file. This is necessary for Selenium to know where to find the chromedriver executable.
The second line creates a new instance of ChromeOptions, which allows you to configure various options for the Chrome browser.
The third line creates a new instance of the Chrome WebDriver. It takes two parameters: service, which specifies the ChromeDriver service that was set up earlier, and options , which specifies the Chrome Options object that was created. This line effectively initializes the WebDriver with the specified service
and options.
# Navigate to the target page
driver.get("https://www.airbnb.co.in/s/Sydney--Australia/homes?adults=1&checkin=2024-05-17&checkout=2024-05-18")
time.sleep(5)
html_content = driver.page_source
print(html_content)
driver.quit()
The first line tells the WebDriver to navigate to the specified URL, which is an Airbnb search page for homes in Sydney, Australia. It includes query parameters for the number of adults and the check-in and check-out dates.
This second line pauses the execution of the script for 5 seconds, allowing time for the webpage to load completely. This is a simple way to wait for dynamic content to be rendered on the page.
The third line retrieves the HTML content of the target webpage using the page_source attribute of the WebDriver.
The last line closes the browser and terminates the WebDriver session. This line is necessary because it can save your memory too while doing mass scraping.
Once you run this code you will see this on your console.
We have successfully managed to download the raw HTML from our target page. Now, we can proceed with the next step of parsing.
Parsing the data with BS4
Before we write the code for parsing, let’s find out the DOM location of each target data point.
Finding the Property Title
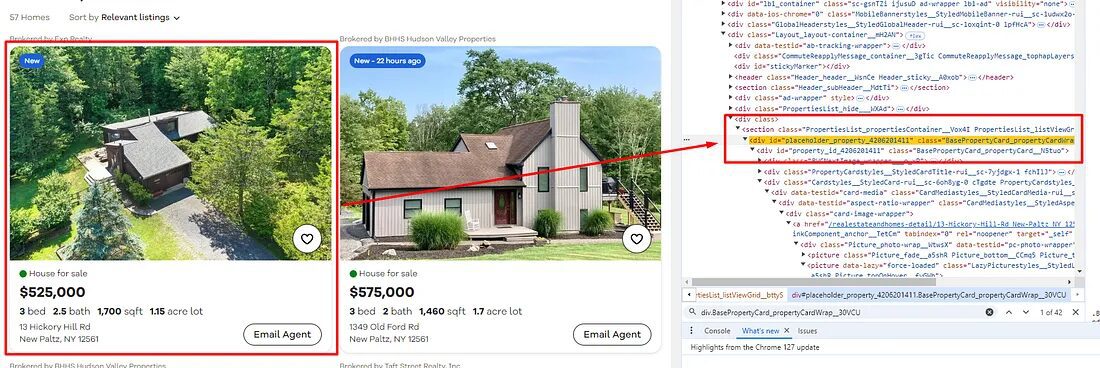
As you can see in the above image, the title of each property is located inside the div tag with attribute data-testid and value listing-card-title.
Finding the Rating
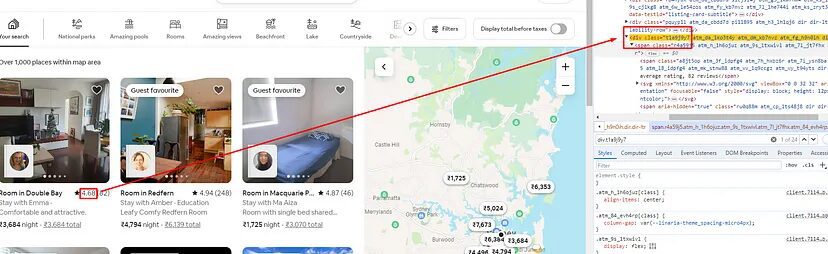
The rating can be found inside a div tag with class t1a9j9y7.
Finding the Price Without Tax
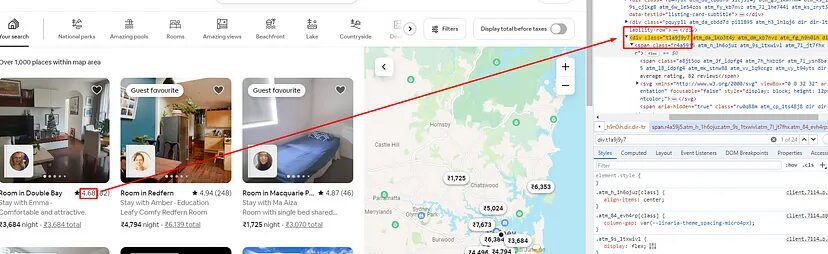
Price without tax can be found inside a span tag with class _14y1gc.
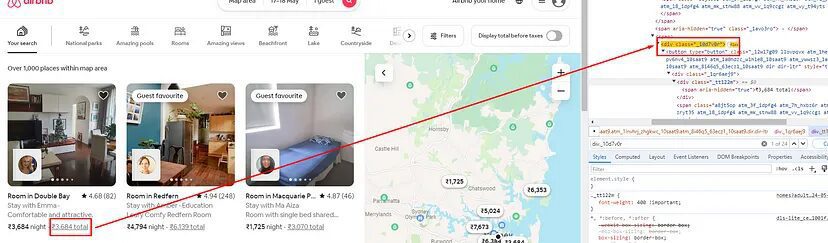
Finding the Price with Tax
Price with tax can be found inside a div tag with class _10d7v0r.
Finding all the property Boxes
Now on every page, there are a total of 24 properties and to get data from each of these properties we have to run a for loop. But before that, we have to find the location where all these property boxes are located.
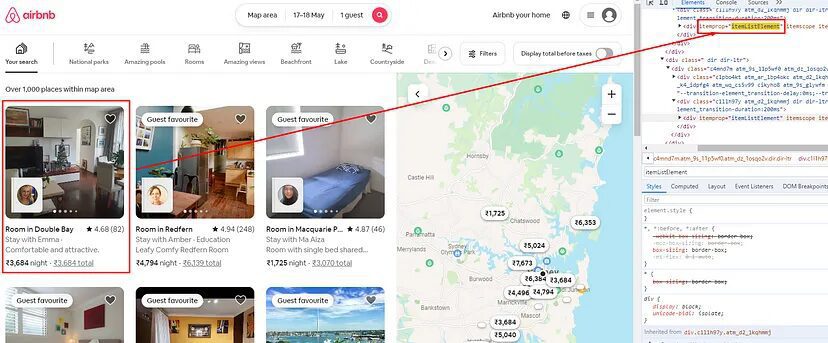
All these properties are located inside a div tag with an attribute itemprop and value itemListElement.
soup=BeautifulSoup(html_content,'html.parser')
Here we have created an instance of BS4 to parse the data from the raw HTML.
allData = soup.find_all("div",{"itemprop" : "itemListElement"})
Then we search for all the properties present on that particular target page.
for i in range(0,len(allData)):
try:
o["property-title"]=allData[i].find('div',{'data-testid':'listing-card-title'}).text.lstrip().rstrip()
except:
o["property-title"]=None
try:
o["rating"]=allData[i].find('div',{'class':'t1a9j9y7'}).text.split()[0]
except:
o["rating"]=None
try:
o["price"]=allData[i].find('span',{"class":"_14y1gc"}).text.lstrip().rstrip().split()[0]
except:
o["price"]=None
try:
o["price_with_tax"]=allData[i].find('div',{'class':'_i5duul'}).find('div',{"class":"_10d7v0r"}).text.lstrip().rstrip().split(" total")[0]
except:
o["price_with_tax"]=None
l.append(o)
o={}
print(l)
Then we are running a for loop to extract the data from their respective locations. Finally, we store all the data inside a list l.
Once you run this code you will see an array with all the data on your console.
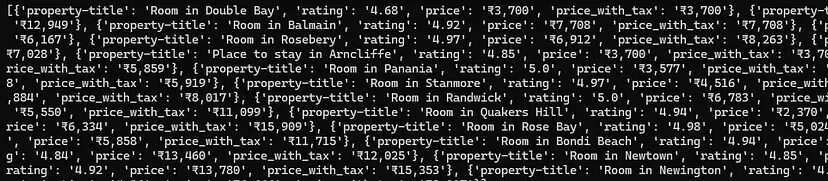
Saving the data to a CSV file
We can save this data to a CSV file by using the pandas library. You can install this library like this.
Now, import this library at the top of your script.
import pandas as pd
First, we have to create a Pandas DataFrame named df from the list l. Each element of the list l becomes a row in the DataFrame, and the DataFrame’s columns are inferred from the data in the list.
df = pd.DataFrame(l)
df.to_csv('airbnb.csv', index=False, encoding='utf-8')
The second line exports the DataFrame df to a CSV file named “airbnb.csv”. The to_csv() method is used to save the DataFrame to a CSV file.
Again once you run the code you will find a CSV file inside your working directory.
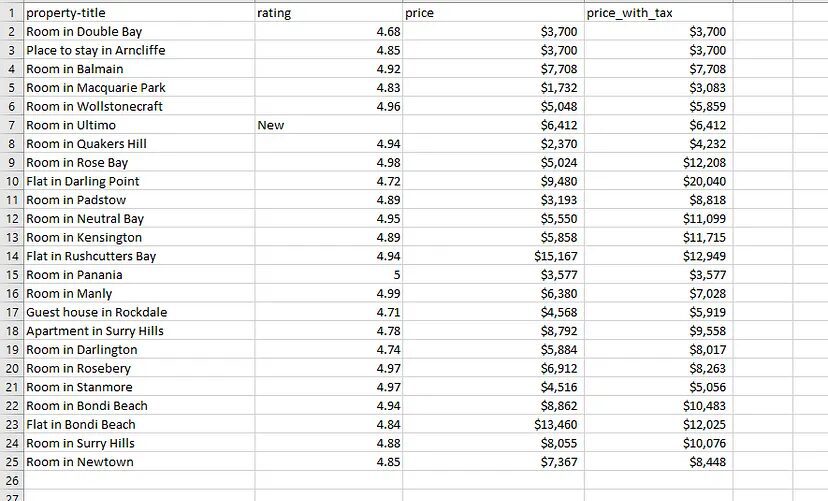
Complete Code
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
import pandas as pd
l=[]
o={}
PATH = 'C:\Program Files (x86)\chromedriver.exe'
service = Service(executable_path=PATH)
options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=service, options=options)
driver.get("https://www.airbnb.co.in/s/Sydney--Australia/homes?adults=1&checkin=2024-05-17&checkout=2024-05-18")
time.sleep(2)
html_content = driver.page_source
driver.quit()
soup=BeautifulSoup(html_content,'html.parser')
allData = soup.find_all("div",{"itemprop":"itemListElement"})
for i in range(0,len(allData)):
try:
o["property-title"]=allData[i].find('div',{'data-testid':'listing-card-title'}).text.lstrip().rstrip()
except:
o["property-title"]=None
try:
o["rating"]=allData[i].find('div',{'class':'t1a9j9y7'}).text.split()[0]
except:
o["rating"]=None
try:
o["price"]=allData[i].find('span',{"class":"_14y1gc"}).text.lstrip().rstrip().split()[0]
except:
o["price"]=None
try:
o["price_with_tax"]=allData[i].find('div',{'class':'_i5duul'}).find('div',{"class":"_10d7v0r"}).text.lstrip().rstrip().split(" total")[0]
except:
o["price_with_tax"]=None
l.append(o)
o={}
df = pd.DataFrame(l)
df.to_csv('airbnb.csv', index=False, encoding='utf-8')
print(l)
Limitations
The above approach for scraping Airbnb is fine but this approach will not work if you want to scrape millions of pages. Airbnb will either block your IP or your resources will not be enough for you to get the data at high speed.
To overcome this problem you can use web scraping APIs like Scrapingdog. Scrapingdog will handle all the hassle of JS rendering with headless chrome and rotation of IPs. Let’s see how you can use Scrapingdog to scrape Airbnb at scale.
Scraping Airbnb with Scrapingdog
Using Scrapingdog is super simple. To get started with Scrapingdog you have to sign up for an account. Once you sign up you will get free 1000 API credits which is enough for initial testing.
On successful account creation, you will be redirected to your dashboard where you will find your API key.
Using this API key you can easily integrate Scrapingdog within your coding environment. For now, we will scrape Airbnb using Scrapingdog in our Python environment. You can even refer to this Web Scraping API Docs before proceeding with the coding.
import requests
from bs4 import BeautifulSoup
import pandas as pd
l=[]
o={}
target_url="https://api.scrapingdog.com/scrape?api_key=YOUR-API-KEY&url=https://www.airbnb.co.in/s/Sydney--Australia/homes?adults=1&checkin=2024-05-17&checkout=2024-05-18&wait=3000"
resp = requests.get(target_url)
soup=BeautifulSoup(resp.text,'html.parser')
allData = soup.find_all("div",{"itemprop":"itemListElement"})
for i in range(0,len(allData)):
try:
o["property-title"]=allData[i].find('div',{'data-testid':'listing-card-title'}).text.lstrip().rstrip()
except:
o["property-title"]=None
try:
o["rating"]=allData[i].find('div',{'class':'t1a9j9y7'}).text.split()[0]
except:
o["rating"]=None
try:
o["price"]=allData[i].find('span',{"class":"_14y1gc"}).text.lstrip().rstrip().split()[0]
except:
o["price"]=None
try:
o["price_with_tax"]=allData[i].find('div',{'class':'_i5duul'}).find('div',{"class":"_10d7v0r"}).text.lstrip().rstrip().split(" total")[0]
except:
o["price_with_tax"]=None
l.append(o)
o={}
df = pd.DataFrame(l)
df.to_csv('airbnb.csv', index=False, encoding='utf-8')
print(l)
As you can see we have removed Selenium and in place of that we have imported requests library that will be used for requesting the Scrapingdog Scraping API. Scrapingdog will now handle all the JS rendering and IP rotation.
Key Takeaways:
Airbnb listings contain data such as property name, price per night, ratings, reviews, location, and amenities.
The platform uses dynamic content loading, requiring proper handling of JavaScript-rendered pages.
Search parameters like dates, guests, and filters must be managed to extract accurate results.
Anti-bot protections make proxy rotation and request control necessary for large-scale scraping.
Extracted Airbnb data can support price monitoring, rental market analysis, and competitive research.
Conclusion
In this tutorial, we learned how we can create a scraper for Airbnb using Selenium and BS4. We also covered how using Scrapingdog, we can bypass the limitations of a Python Scraper.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on social media.
Frequently Asked Questions
Can Airbnb block you while scraping it with Python?
Yes, Airbnb may detect the scraping when you do this process on a large scale. With a Web Scraping API, you can extract bulk data without getting blocked.
What if the Airbnb changes its website structure?
When the website structure changes, we make sure that we incorporate that structure change in the backend of our API for hassle-free data extraction.
Can you test Scrapingdog to scrape Airbnb before committing to a paid plan?
Of course, we offer 1000 free API credits to spin our API. This way you can check the accuracy and response and buy a paid plan if you are satisfied with it. You can sign up for free from here.


