
TL;DR
- Walks you through how to scrape product pages on Amazon using Python with
requests+BeautifulSoup(for title, images, price, rating, specs). - Shows how to mimic browser-like headers to bypass Amazon’s anti-bot mechanisms.
- Details how to extract high-resolution images via regex search for
hiResin the page’s <script> content. - Provides a full example script with rotating user-agents for basic scraping.
- Explains when you need to scale: using a proxy/API solution (specifically Scrapingdog’s Amazon Scraper API) to avoid IP blocks and handle high volume.
- Covers how to call that API (by ASIN, domain, postal-code-based locale) and other related endpoints (offers, autocomplete) for richer Amazon data.
The e-commerce industry has grown in recent years, transforming from a mere convenience to an essential facet of our daily lives.
As digital storefronts multiply and consumers increasingly turn to online shopping, there’s an increasing demand for data that can drive decision-making, competitive strategies, and customer engagement in the digital marketplace.
Additionally, scraped Amazon product data can significantly enhance customer service automation by providing customer service teams with real-time product information, pricing details, and availability status, enabling them to respond more efficiently to customer inquiries and resolve issues faster.
If you are into an e-commerce niche, scraping Amazon can give you a lot of data points to understand the market.
In this guide, we will use Python to scrape Amazon, do price scraping from this platform, and demonstrate how to extract crucial information to help you make well-informed decisions in your business.
Setting up the prerequisites for scraping amazon
I am assuming that you have already installed python 3.x on your machine. If not then you can download it from here. Apart from this, we will require two III-party libraries of Python.
- Requests– We will use this library to connect HTTP with the Amazon page. This library will help us to extract the raw HTML from the target page.
- BeautifulSoup– This is a powerful data parsing library. Using this we will extract necessary data out of the raw HTML we get using the requests library.
Before we install these libraries we will have to create a dedicated folder for our project.
mkdir amazonscraper
Now, we will have to install the above two libraries in this folder. Here is how you can do it.
pip install beautifulsoup4
pip install requests
amazon.pyDownloading raw data from amazon.com
requests library.
import requests
from bs4 import BeautifulSoup
target_url="https://www.amazon.com/dp/B0BSHF7WHW"
resp = requests.get(target_url)
print(resp.text)
Once you run this code, you might see this.

To bypass this on-site protection of Amazon we can send some headers like User-Agent. You can even check what headers are sent to amazon.com once you open the URL in your browser. You can check them from the network tab.
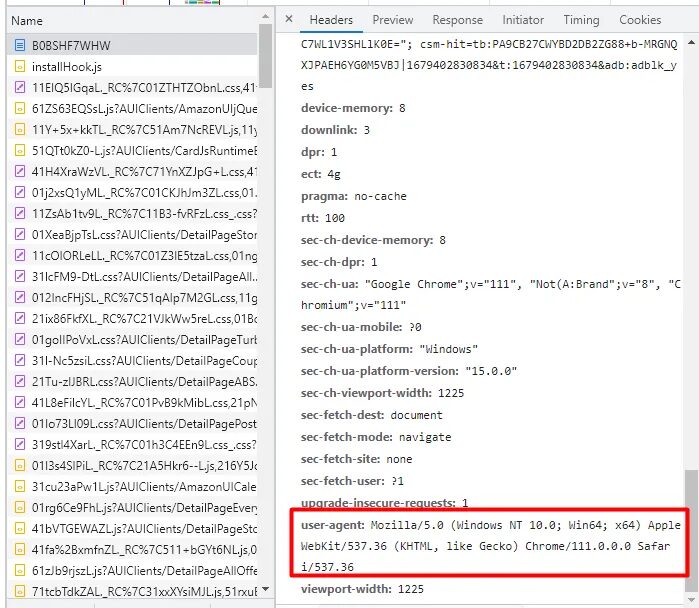
Once you pass this header to the request, your request will act like a request coming from a real browser. This can melt down the anti-bot wall of amazon.com. Let’s pass a few headers to our request.
import requests
from bs4 import BeautifulSoup
target_url="https://www.amazon.com/dp/B0BSHF7WHW"
headers={"accept-language": "en-US,en;q=0.9","accept-encoding": "gzip, deflate, br","User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36","accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7"}
resp = requests.get(target_url, headers=headers)
print(resp.text)
Once you run this code you might be able to bypass the anti-scraping protection wall of Amazon.
Now let’s decide what exact information we want to scrape from the page.
What are we going to scrape from Amazon?
It is always great to decide in advance what are you going to extract from the target page. This way we can analyze in advance which element is placed where inside the DOM.
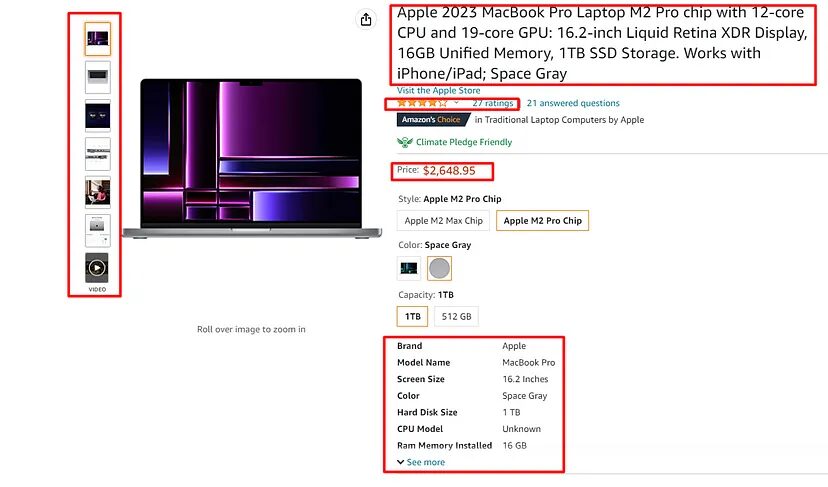
We are going to scrape five data elements from the page.
- Name of the product
- Images
- Price (Most important)
- Rating
- Specs
First, we are going to make the GET request to the target page using the requests library and then using BS4 we are going to parse out this data. Of course, there are multiple other libraries like lxml that can be used in place of BS4, but BS4 has the most powerful and easy-to-use API.
Before making the request we are going to analyze the page and find the location of each element inside the DOM. One should always do this exercise to identify the location of each element.
We are going to do this by simply using the developer tool. This can be accessed by right-clicking on the target element and then clicking on the inspect. This is the most common method, you might already know this.
Identifying the location of each element
Location of the title tag

Once you inspect the title you will find that the title text is located inside the h1 tag with the id title.
Coming back to our amazon.py file, we will write the code to extract this information from Amazon.
import requests
from bs4 import BeautifulSoup
l=[]
o={}
url="https://www.amazon.com/dp/B0BSHF7WHW"
headers={"accept-language": "en-US,en;q=0.9","accept-encoding": "gzip, deflate, br","User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36","accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7"}
resp = requests.get(url, headers=headers)
print(resp.status_code)
soup=BeautifulSoup(resp.text,'html.parser')
try:
o["title"]=soup.find('h1',{'id':'title'}).text.strip()
except:
o["title"]=None
print(o)
Here the line soup=BeautifulSoup(resp.text,’html.parser’) is using the BeautifulSoup library to create a BeautifulSoup object from an HTTP response text, with the specified HTML parser.
Then using soup.find() method will return the first occurrence of the tag h1 with id title. We are using .text method to get the text from that element. Then finally I used .strip() method to remove all the whitespaces from the text we receive.
Once you run this code you will get this.
[{'title': 'Apple 2023 MacBook Pro Laptop M2 Pro chip with 12‑core CPU and 19‑core GPU: 16.2-inch Liquid Retina XDR Display, 16GB Unified Memory, 1TB SSD Storage. Works with iPhone/iPad; Space Gray'}]
If you have not read the above section where we talked about downloading HTML data from the target page then you won’t be able to understand the above code. So, please read the above section before moving ahead.
Location of the image tag
This might be the most tricky part of this complete tutorial. Let’s inspect and find out why it is a little tricky.
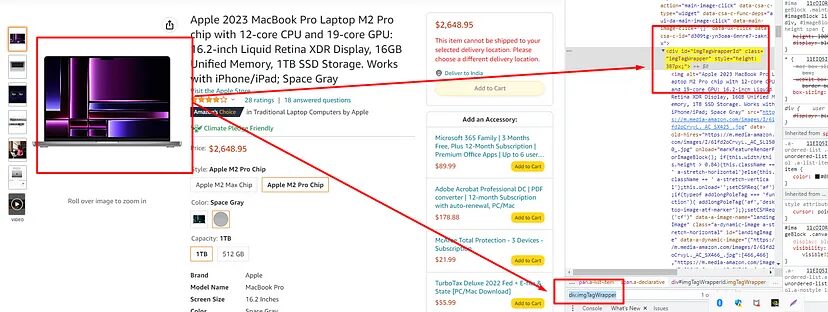
img tag in which the image is hidden is stored inside div tag with class imgTagWrapper.
allimages = soup.find_all("div",{"class":"imgTagWrapper"})
print(len(allimages))
Once you print this it will return 3. Now, there are 6 images and we are getting just 3. The reason behind this is JS rendering. Amazon loads its images through an AJAX request at the backend. That’s why we never receive these images when we make an HTTP connection to the page through requests library.
Finding high-resolution images is not as simple as finding the title tag. But I will explain to you step by step how you can find all the images of the product.
- Copy any product image URL from the page.
- Then click on the view page source to open the source page of the target webpage.
- Then search for this image.
You will find that all the images are stored as a value for hiRes key.
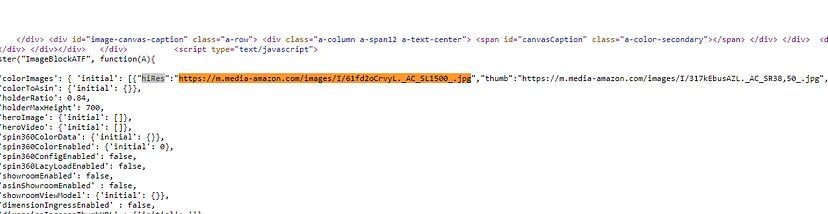
All this information is stored inside a script tag. Now, here we will use regular expressions to find this pattern of
We can still use BS4 but it will make the process a little lengthy and it might slow down our scraper. For now, we will use
- The
.matches any character except a newline - The
+matches one or more occurrences of the preceding character. - The
?makes the match non-greedy, meaning that it will match the minimum number of characters needed to satisfy the pattern.
The regular expression will return all the matched sequences of characters from the HTML string we are going to pass.
images = re.findall('"hiRes":"(.+?)"', resp.text)
o["images"]=images
This will return all the high-resolution images of the product in a list. In general, it is not advised to use regular expression in data parsing but it can do wonders sometimes.

Parsing the price tag
There are two price tags on the page, but we will only extract the one which is just below the rating.
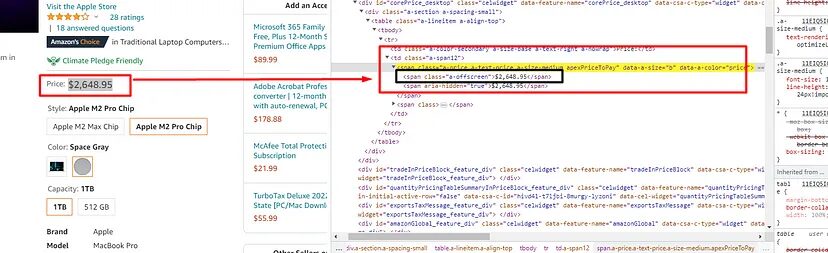
span tag with class a-price. Once you find this tag you can find the first child span tag to get the price. Here is how you can do it.
try:
o["price"]=soup.find("span",{"class":"a-price"}).find("span").text
except:
o["price"]=None
Once you print object o, you will get to see the price.
{'price': '$2,499.00'}
Extract rating
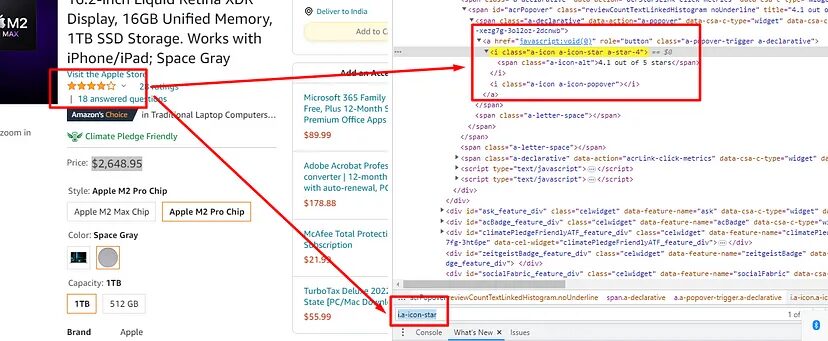
You can find the rating in the first i tag with class a-icon-star. Let’s see how to scrape this too.
try:
o["rating"]=soup.find("i",{"class":"a-icon-star"}).text
except:
o["rating"]=None
It will return this.
{'rating': '4.1 out of 5 stars'}
In the same manner, we can scrape the specs of the device.
Extract the specs of the device
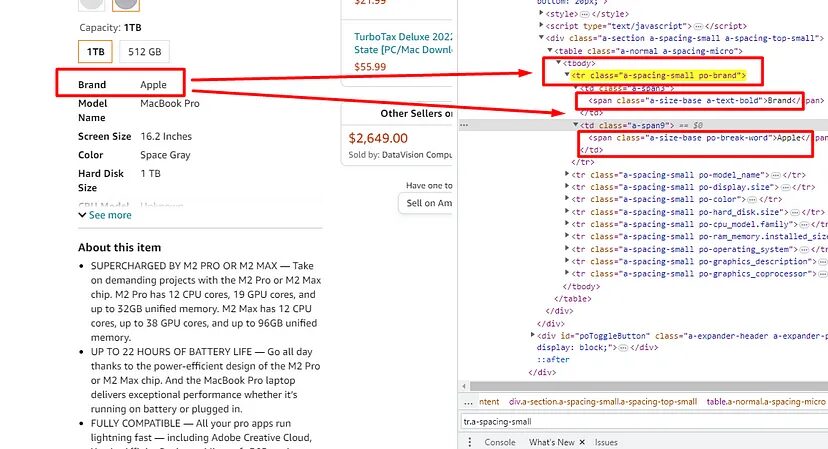
These specs are stored inside these tr tags with class a-spacing-small. Once you find these you have to find both the span under it to find the text. You can see this in the above image. Here is how it can be done.
specs_arr=[]
specs_obj={}
specs = soup.find_all("tr",{"class":"a-spacing-small"})
for u in range(0,len(specs)):
spanTags = specs[u].find_all("span")
specs_obj[spanTags[0].text]=spanTags[1].text
specs_arr.append(specs_obj)
o["specs"]=specs_arr
Using .find_all() we are finding all the tr tags with class a-spacing-small. Then we are running a for loop to iterate over all the tr tags. Then under for loop we find all the span tags. Then finally we are extracting the text from each span tag.
Once you print the object o it will look like this.
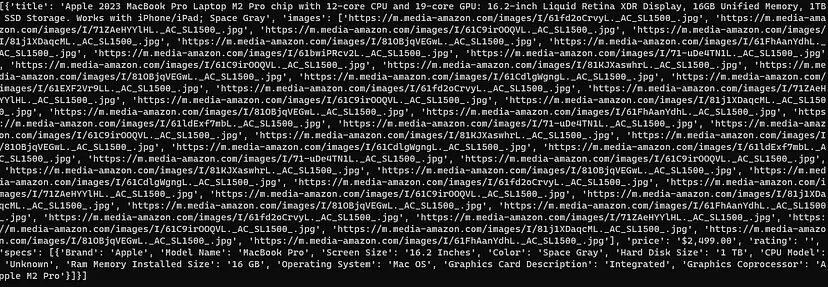
Throughout the tutorial, we have used try/except statements to avoid any run time error. We have not managed to scrape all the data we decided to scrape at the beginning of the tutorial.
Complete Code
You can of course make a few changes to the code to extract more data because the page is filled with large information. You can even use cron jobs to mail yourself an alert when the price drops. Or you can integrate this technique into your app, this feature can mail your users when the price of any item on Amazon drops.
But for now, the code will look like this.
import requests
from bs4 import BeautifulSoup
import re
l=[]
o={}
specs_arr=[]
specs_obj={}
target_url="https://www.amazon.com/dp/B0BSHF7WHW"
headers={"accept-language": "en-US,en;q=0.9","accept-encoding": "gzip, deflate, br","User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36","accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7"}
resp = requests.get(target_url, headers=headers)
print(resp.status_code)
if(resp.status_code != 200):
print(resp)
soup=BeautifulSoup(resp.text,'html.parser')
try:
o["title"]=soup.find('h1',{'id':'title'}).text.lstrip().rstrip()
except:
o["title"]=None
images = re.findall('"hiRes":"(.+?)"', resp.text)
o["images"]=images
try:
o["price"]=soup.find("span",{"class":"a-price"}).find("span").text
except:
o["price"]=None
try:
o["rating"]=soup.find("i",{"class":"a-icon-star"}).text
except:
o["rating"]=None
specs = soup.find_all("tr",{"class":"a-spacing-small"})
for u in range(0,len(specs)):
spanTags = specs[u].find_all("span")
specs_obj[spanTags[0].text]=spanTags[1].text
specs_arr.append(specs_obj)
o["specs"]=specs_arr
l.append(o)
print(l)
Changing Headers on every request
With the above code, your scraping journey will come to a halt, once Amazon recognizes a pattern in the request.
To avoid this you can keep changing your headers to keep the scraper running. You can rotate a bunch of headers to overcome this challenge. Here is how it can be done.
import requests
from bs4 import BeautifulSoup
import re
import random
l=[]
o={}
specs_arr=[]
specs_obj={}
useragents=['Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4894.117 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4855.118 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4892.86 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4854.191 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4859.153 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.79 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36/null',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36,gzip(gfe)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4895.86 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 12_3_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_13) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4860.89 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4885.173 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4864.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_12) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4877.207 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 12_2_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML%2C like Gecko) Chrome/100.0.4896.127 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.133 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4872.118 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 12_3_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_13) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4876.128 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML%2C like Gecko) Chrome/100.0.4896.127 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36']
target_url="https://www.amazon.com/dp/B0BSHF7WHW"
headers={"User-Agent":useragents[random.randint(0,31)],"accept-language": "en-US,en;q=0.9","accept-encoding": "gzip, deflate, br","accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7"}
resp = requests.get(target_url,headers=headers)
print(resp.status_code)
if(resp.status_code != 200):
print(resp)
soup=BeautifulSoup(resp.text,'html.parser')
try:
o["title"]=soup.find('h1',{'id':'title'}).text.lstrip().rstrip()
except:
o["title"]=None
images = re.findall('"hiRes":"(.+?)"', resp.text)
o["images"]=images
try:
o["price"]=soup.find("span",{"class":"a-price"}).find("span").text
except:
o["price"]=None
try:
o["rating"]=soup.find("i",{"class":"a-icon-star"}).text
except:
o["rating"]=None
specs = soup.find_all("tr",{"class":"a-spacing-small"})
for u in range(0,len(specs)):
spanTags = specs[u].find_all("span")
specs_obj[spanTags[0].text]=spanTags[1].text
specs_arr.append(specs_obj)
o["specs"]=specs_arr
l.append(o)
print(l)
We are using a random library here to generate random numbers between 0 and 31(31 is the length of the useragents list). These user agents are all latest so you can easily bypass the anti-scraping wall.
But again this technique is not enough to scrape Amazon at scale. What if you want to scrape millions of such pages? Then this technique is super inefficient because your IP will be blocked. So, for mass scraping one has to use a web scraping proxy API to avoid getting blocked while scraping.
Using Scrapingdog for scraping Amazon
The advantages of using Scrapingdog’s Amazon Scraper API are:
- You won’t have to manage headers anymore.
- Every request will go through a new IP. This keeps your IP anonymous.
- Our API will automatically retry on its own if the first hit fails.
- Scrapingdog will handle issues like changes in HTML tags. You won’t have to check every time for changes in tags. You can focus on data collection.
Let me show you how easy it is to scrape Amazon product pages using Scrapingdog with just an ASIN code. It would be great if you could read the documentation first before trying the API.
Before you try the API you have to signup for the free pack. The free pack comes with 1000 credits which is enough for testing Amazon scraper API.
import requests
url = "https://api.scrapingdog.com/amazon/product"
params = {
"api_key": "Your-API-Key",
"domain": "com",
"asin": "B0C22KCKVQ"
}
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
print(data)
else:
print(f"Request failed with status code {response.status_code}")
Once you run this code you will get this beautiful JSON response.
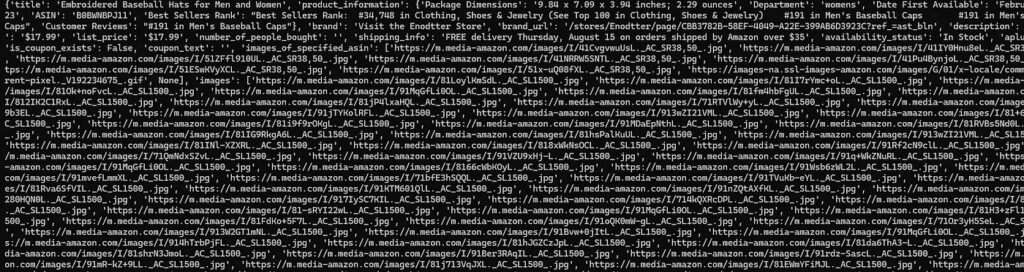
This JSON contains almost all the data you see on the Amazon product page.
Scraping Amazon data based on Postal Codes
Now, let’s scrape the data for a particular postal code. For this example, we are going to target New York. 10001 is the postal code of New York.
import requests
api_key = "Your-API-Key"
url = "https://api.scrapingdog.com/amazon/product"
params = {
"api_key": api_key,
"asin": "B0CTKXMQXK",
"domain": "com",
"postal_code": "10001",
"country": "us"
}
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
print(data)
else:
print(f"Request failed with status code: {response.status_code}")
Once you run this code you will get a beautiful JSON response based on the New York Location.
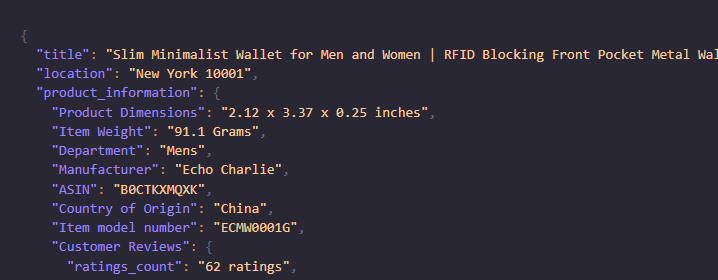
I have also created a video to guide you using Scrapingdog to scrape Amazon.
Scraping Amazon Offers Data Using Scrapingdog
This data will help you identify details about the seller, delivery options, pricing, etc, using Amazon Offers Scraper API.
import requests
url = "https://api.scrapingdog.com/amazon/offers"
params = {
"api_key": "your-api-key",
"asin": "B0BVJT3HVN",
"domain": "com",
"country": "us"
}
try:
response = requests.get(url, params=params)
response.raise_for_status() # Raise error for bad responses
data = response.json()
print("✅ API Response:")
print(data)
except requests.exceptions.RequestException as e:
print(f"❌ Request failed: {e}")
After running this code you will get this JSON response.
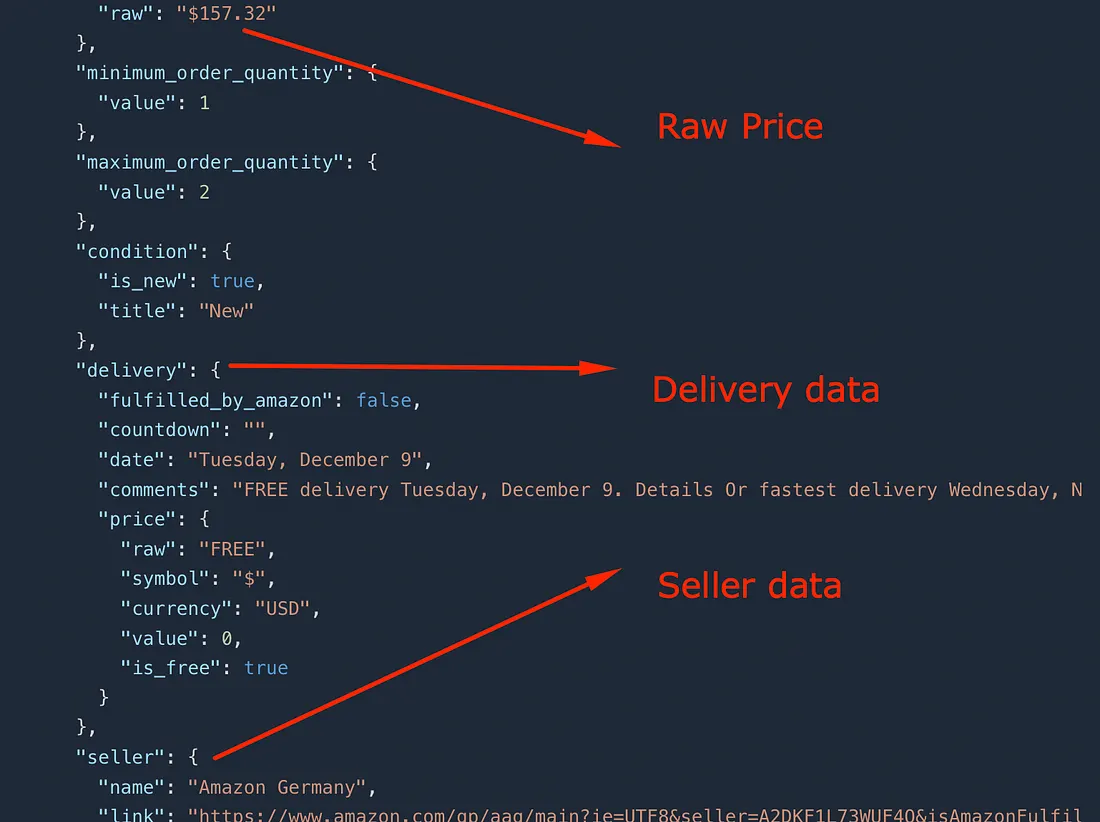
In addition to this, if you’re building a keyword research tool, validating product ideas, or running sentiment analysis, you can use Scrapingdog’s Amazon Autocomplete API for these use cases.
You just have to make a GET request to this endpoint https://api.scrapingdog.com/amazon/autocomplete and pass your target keyword. For example let’s say you are looking for a pen holder then you will pass a prefix by the name “pen holder”.
import requests
# API URL and key
api_url = "https://api.scrapingdog.com/amazon/autocomplete"
api_key = "your-api-key"
# Search parameters
domain = "com"
prefix = "pen holder"
# Create a dictionary with the query parameters
params = {
"api_key": api_key,
"prefix": prefix
}
# Send the GET request with the specified parameters
response = requests.get(api_url, params=params)
# Check if the request was successful (status code 200)
if response.status_code == 200:
data = response.json()
print(data)
else:
print(f"HTTP Request Error: {response.status_code}")
This will generate a list of keywords associated with the prefix.
Here are 5 Key Takeaways:
- Shows how to extract Amazon product data using Python and Scrapingdog’s Amazon Scraper API.
- You can retrieve structured product details like titles, prices, ratings, and availability.
- The API handles proxies and anti-bot measures, avoiding manual proxy management.
- It demonstrates a step-by-step Python implementation for ease of use.
- Scraping Amazon data programmatically enables price tracking, market research, and analytics.
Conclusion
Over 80% of the e-commerce businesses today rely on web scraping. If you’re not using it, you’re already falling behind.
There are many marketplaces that you can scrape & extract data from. Having a strategy to scrape e-commerce data for your product can take you far ahead of your competitors.
In this tutorial, we scraped various data elements from Amazon. First, we used the requests library to download the raw HTML, and then using BS4 we parsed the data we wanted. You can also use lxml in place of BS4 to extract data. Python and its libraries make scraping very simple for even a beginner. Once you scale, you can switch to web scraping APIs to scrape millions of such pages.
Combination of requests and Scrapingdog can help you scale your scraper. You will get more than a 99% success rate while scraping Amazon with Scrapingdog.
If you want to track the price of a product on Amazon, we have a comprehensive tutorial on tracking Amazon product prices using Python.
I hope you like this little tutorial. If you do, please don’t forget to share it with your friends and on your social media.
You can combine this data with business plan software to offer different solutions to your clients.
If you are a non-developer and wanted to scrape the data from Amazon, here is a good news for you.
We have recently launched a Google Sheet add-on Amazon Scraper.
Here is the video 🎥 tutorial for this action.
Frequently Asked Questions
Is scraping Amazon allowed?
Yes, scraping Amazon is allowed as long as you are scraping public information. Extracting private data can cause you problems and legal actions can be taken against it.
How does Amazon detect scrapers?
Amazon detects scraping by the anti-bot mechanism which can check your IP address and thus can block you if you continue to scrape it. However, using a proxy management system will help you to bypass this security measure.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:
- How to Scrape Amazon Review using Python
- How To Avoid IP Bans & CAPTCHA while Scraping Amazon
- Automate Amazon Price Tracking using Scrapingdog’s Amazon Scraper API & Make.com
- How to Scrape Walmart using Python
- How to Scrape Flipkart using Python
- Web Scraping Myntra using Python
- Web Scraping eBay using Python
- Web Scraping Google Shopping using Python


