TL;DR
- Python guide to scrape Booking.com hotel data (name, address, rating, room type, price, facilities) using
requests+BeautifulSoup. - Process: GET with headers → build soup → iterate table rows via
data-block-id→ persist room name → extract prices; full code included. - Fine for small runs; expect IP blocks at scale.
- For scale, switch to Scrapingdog—same parsing, reliable fetching, plus 1,000 free credits to start.
Booking.com hosts over 28 million listings across hotels, apartments, and vacation rentals, making it one of the richest sources of travel pricing data on the internet. Whether you’re building a price monitoring tool, training an ML model on hospitality data, or tracking competitor rates across cities, scraping Booking.com is the fastest way to get that data at scale.
The problem? Booking.com is one of the harder sites to scrape reliably. It uses Cloudflare protection, dynamic JavaScript rendering, and aggressive IP-based rate limiting. A basic requests call will work for a few pages but the moment you try to scale, you’ll hit blocks.
In this guide, you’ll learn how to scrape Booking.com using Python step by step. In this guide we will create a hotel page scraper to extract name, address, rating, room type, price, and facilities. Before reading this article if you want to learn scraping then do read web scraping with python.
Let’s get started.
Why Scrape Booking.com?
Booking.com is one of the largest travel platforms in the world, with millions of hotel listings across virtually every country. That makes it a valuable data source for a wide range of use cases.
Price Monitoring — Hotel prices shift multiple times a day based on demand and seasonality. Travel agencies and revenue managers scrape Booking.com to track these changes in real time and adjust their own pricing accordingly.
Building Comparison Tools — By scraping listings and prices across multiple platforms, you can build travel aggregators that show users the best available deal without them having to check each site manually.
Market Research — Analysts use Booking.com data to study pricing trends, occupancy patterns, and emerging destinations, faster and cheaper than any third-party industry report.
ML and Data Science — Booking.com’s structured property pages make it a clean training data source for dynamic pricing models, demand forecasting, and recommendation engines.
Setting Up Your Python Environment
We need Python 3.x for this tutorial and I am assuming that you have already installed it on your computer, if not then you can download it from here. Along with that, you need to install two more libraries which will be used further in this tutorial for web scraping.
Requests will help us to make an HTTP connection with Booking.com.BeautifulSoup will help us to create an HTML tree for smooth data extraction.
Now first create a folder and then install the libraries mentioned above.
mkdir booking
pip install requests
pip install beautifulsoup4
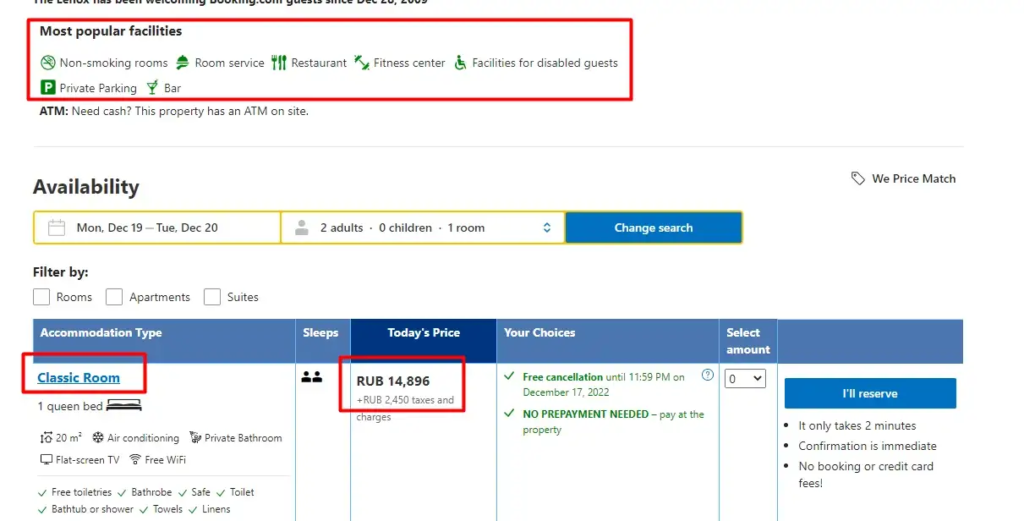
Inside this folder, create a Python file with any name you prefer. In this tutorial, we will scrape the following data points from the target website.
- Address
- Name
- Pricing
- Rating
- Room Type
- Facilities

How to Scrape Booking.com Search Results with Python
Since everything is set let’s make a GET request to the target website and see if it works.
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
}
target_url = (
"https://www.booking.com/hotel/us/the-lenox.html"
"?checkin=2026-04-15"
"&checkout=2026-04-16"
"&group_adults=2"
"&group_children=0"
"&no_rooms=1"
"&selected_currency=USD"
)
resp = requests.get(target_url, headers=headers)
print(resp.status_code) # 200 means success
The code is pretty straightforward and needs no explanation but let me explain you a little. First, we imported two libraries that we downloaded earlier in this tutorial then we declared headers and target URL.
After sending a GET request to the target URL, a 200 status code confirms success. Any other status code means the request did not go through as expected.
Now that we know what data we’re after, the next step is finding where each field lives in Booking.com’s HTML. Right-click on any element in Chrome and hit Inspect to open DevTools, this is how we’ll identify the exact tags and class names to target with BeautifulSoup.
We’ll use two BeautifulSoup methods throughout this tutorial:
find()— when there’s only one instance of an element on the page, like the hotel name or addressfind_all()— when we need to grab multiple elements at once, like room types or facilities listed in a table
The right method to use depends entirely on how Booking.com structures that particular piece of data in the DOM.
Extracting hotel name and address
Let’s inspect Chrome and find the DOM location of the name as well as the address.

As you can see the hotel name can be found under the h2 tag with class pp-header__title. For the sake of simplicity let’s first create a soup variable with the BeautifulSoup constructor and from that, we will extract all the data points.
soup = BeautifulSoup(resp.text, 'html.parser')
Here BS4 will use an HTML Parser to convert a complex HTML document into a complex tree of Python objects. Now, let’s use the soup variable to extract the name and address.
o["name"]=soup.find("h2",{"class":"pp-header__title"}).text
In a similar manner, we will extract the address.

The address of the property is stored under the div tag with the class name f17adf7576
o["address"]=soup.find_all("div",{"class":"f17adf7576"})[0].text.strip("\n")
Extracting rating and facilities
Once again we will inspect and find the DOM location of the rating and facilities element.
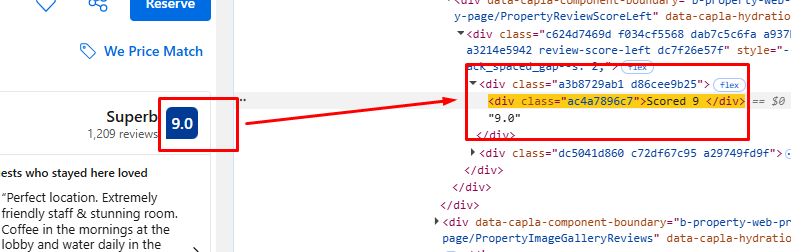
o["rating"]=soup.find_all("div",{"class":"ac4a7896c7"})[0].text
Extracting facilities is a bit tricky. We will create a list in which we will store all the facilities HTML elements. After that, we will run a for loop to iterate over all the elements and store individual text in the main array.

Let’s see how it can be done in two simple steps.
fac=soup.find_all("div",{"class":"important_facility"})
fac variable will hold all the facilities elements. Now, let’s extract them one by one.
for i in range(0,len(fac)):
fac_arr.append(fac[i].text.strip("\n"))
Extract Price and Room Types
This is the trickiest part of the entire tutorial. Booking.com’s DOM structure is quite intricate and requires careful inspection before you can reliably extract price and room type details.
The <tbody> tag contains all the relevant data. Inside it, each <tr> tag represents a row and holds all the information for a single listing or item, typically starting from the first column.

Next, as you dive deeper into the DOM, you’ll encounter multiple <td> tags within each <tr>. These <td> tags contain essential details like room type, pricing, taxes, and other booking information.
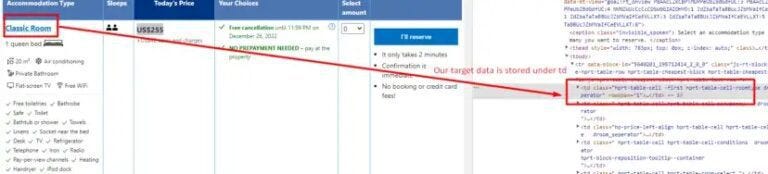
First, let’s find all the tr tags.
ids= list()
targetId=list()
try:
tr = soup.find_all("tr")
except:
tr = None
You’ll notice that each <tr> tag comes with a data-block-id attribute. The next step is to extract all these IDs and store them in a list for further processing.
for y in range(0,len(tr)):
try:
id = tr[y].get('data-block-id')
except:
id = None
if( id is not None):
ids.append(id)
Once you’ve gathered all the data-block-id values, the process becomes more manageable. We can loop through each data-block-id and directly access their corresponding <tr> blocks to extract key details such as room types and pricing information.
for i in range(0,len(ids)):
try:
allData = soup.find("tr",{"data-block-id":ids[i]})
except:
k["room"]=None
k["price"]=None
allData variable will store all the HTML data for a particular data-block-id.
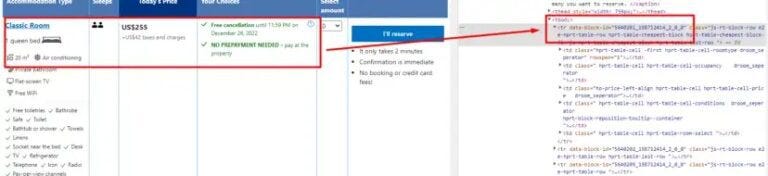
Next, let’s navigate to the <td> elements located inside each <tr> block. Our initial focus will be on extracting the room type information, which is usually nested within a specific <td> cell inside each row.
try:
rooms = allData.find("span",{"class":"hprt-roomtype-icon-link"})
except:
rooms=None
Here comes the tricky part: when a room type has multiple pricing options (e.g., refundable, non-refundable, breakfast included, etc.), you’ll notice that the room type is often mentioned once, but the subsequent price rows are linked to that same room type. So, while looping through each pricing option, we must ensure that the original room type is reused until a new room type is encountered. Let me illustrate this more clearly with the help of an image.
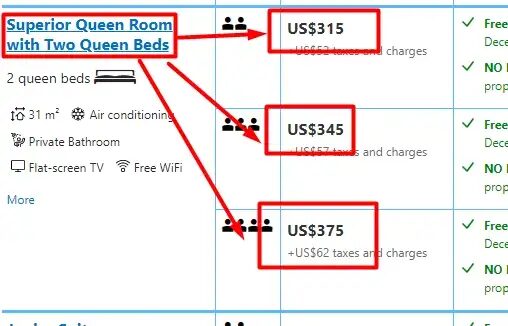
In this scenario, you’ll often encounter multiple pricing options listed under a single room type. When iterating through the rows, you’ll notice that the room type might only appear once, while the subsequent pricing rows leave the room name empty (or return None). To handle this, we simply retain the last non-empty room type value and reuse it for the following pricing options until a new room type is encountered. This ensures the pricing data stays correctly linked to its room type.
if(rooms is not None):
last_room = rooms.text.replace("\n","")
try:
k["room"]=rooms.text.replace("\n","")
except:
k["room"]=last_room
Here last_room will store the last value of rooms until we receive a new value.
Let’s extract the price now.
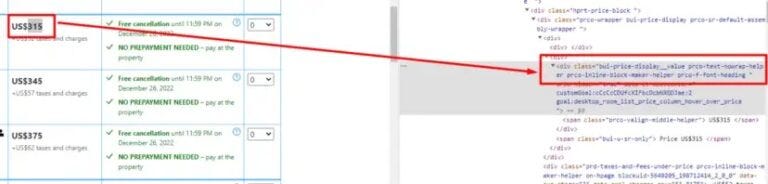
Price is stored under the div tag with the class “bui-price-display__value prco-text-nowrap-helper prco-inline-block-maker-helper prco-f-font-heading”. Let’s use allData variable to find it and extract the text.
price = allData.find("div",{"class":"bui-price-display__value prco-text-nowrap-helper prco-inline-block-maker-helper prco-f-font-heading"})
k["price"]=price.text.replace("\n","")
We have finally managed to scrape all the data elements that we were interested in.
Complete Code
You can extract other pieces of information like amenities, reviews, etc. You just have to make a few more changes and you will be able to extract them too. Along with this, you can extract other hotel details by just changing the unique name of the hotel in the URL.
The code will look like this.
import requests
from bs4 import BeautifulSoup
l = list()
g = list()
o = {}
k = {}
fac = []
fac_arr = []
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
}
target_url = (
"https://www.booking.com/hotel/us/the-lenox.html"
"?checkin=2026-04-15"
"&checkout=2026-04-16"
"&group_adults=2"
"&group_children=0"
"&no_rooms=1"
"&selected_currency=USD"
)
resp = requests.get(target_url, headers=headers)
soup = BeautifulSoup(resp.text, "html.parser")
# --- Hotel metadata ---
o["name"] = soup.find("h2", {"class": "pp-header__title"}).text.strip()
o["address"] = soup.find("div", {"class": "f17adf7576"}).text.strip()
o["rating"] = soup.find("div", {"class": "ac4a7896c7"}).text.strip()
# --- Facilities ---
fac = soup.find_all("div", {"class": "important_facility"})
fac_arr = [f.text.strip() for f in fac]
# --- Room types and prices ---
last_room = None
for row in soup.find_all("tr"):
block_id = row.get("data-block-id")
if block_id is None:
continue
# Persist room name across merged rows
room_tag = row.find("span", {"class": "hprt-roomtype-icon-link"})
if room_tag:
last_room = room_tag.text.strip()
# Extract price
price = row.find("div", {"class": "bui-price-display__value prco-text-nowrap-helper prco-inline-block-maker-helper prco-f-font-heading"})
if price is None:
continue
k["room"] = last_room
k["price"] = price.text.strip()
g.append(k)
k = {}
# --- Final output ---
l.append(g)
l.append(o)
l.append(fac_arr)
print(l)The output of this script should look like this.
Keep in mind, that this technique is good for small-scale scraping — perhaps a few hundred requests. However, once you cross that threshold, Booking.com will likely detect the pattern and block further requests due to IP bans.
To avoid this situation, you are advised to use a web scraping API like Scrapingdog.
Scraping Booking.com at Scale with Scrapingdog
The Python scraper we built above works well for small runs and a handful of hotel pages, occasional price checks. But once you start scraping hundreds of pages, Booking.com will start throwing CAPTCHAs and blocking your IP. At that point, maintaining your own proxy rotation and browser fingerprinting setup becomes a project in itself.
That’s where Scrapingdog comes in. Instead of sending requests directly to Booking.com, you route them through Scrapingdog’s API, it handles IP rotation, CAPTCHA solving, JS rendering and header randomization automatically on the backend. Your parsing code stays exactly the same, you just swap out the request.
The first step would be to sign up for the free pack. The free pack will provide you with 1000 API credits.

Click on General Scraper and enter your target booking.com link. This step will create a ready Python snippet on the right.
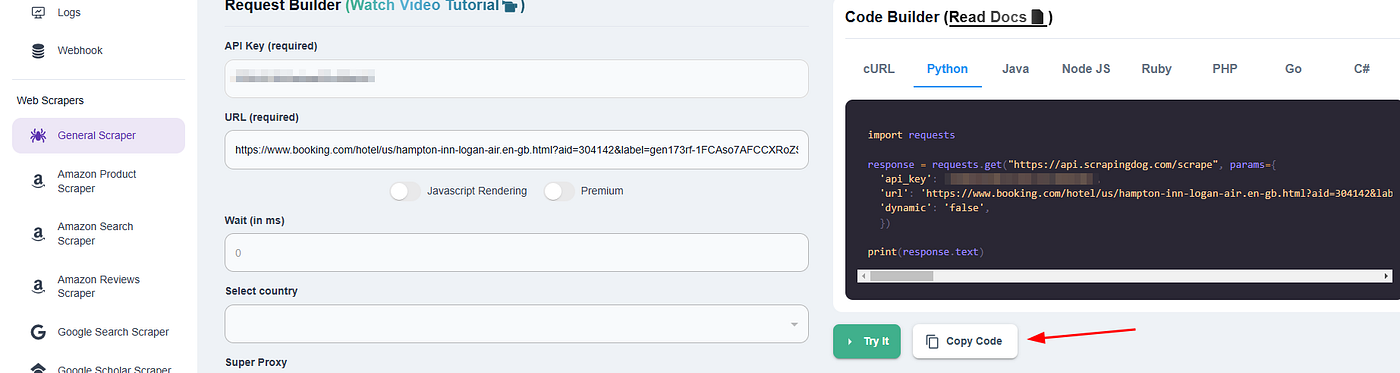
Now just copy this Python code and paste it into your working environment. Of course, your parsing code will remain the same as earlier.
import requests
from bs4 import BeautifulSoup
l = list()
g = list()
o = {}
k = {}
fac = []
fac_arr = []
target_url = (
"https://www.booking.com/hotel/us/the-lenox.html"
"?checkin=2026-04-15"
"&checkout=2026-04-16"
"&group_adults=2"
"&group_children=0"
"&no_rooms=1"
"&selected_currency=USD"
)
resp = requests.get("https://api.scrapingdog.com/scrape", params={
"api_key": "YOUR_API_KEY",
"url": target_url,
"dynamic": "true",
})
print(resp.status_code)
soup = BeautifulSoup(resp.text, "html.parser")
# --- Hotel metadata ---
o["name"] = soup.find("h2", {"class": "pp-header__title"}).text.strip()
o["address"] = soup.find("div", {"class": "f17adf7576"}).text.strip()
o["rating"] = soup.find("div", {"class": "ac4a7896c7"}).text.strip()
# --- Facilities ---
fac = soup.find_all("div", {"class": "important_facility"})
fac_arr = [f.text.strip() for f in fac]
# --- Room types and prices ---
last_room = None
for row in soup.find_all("tr"):
block_id = row.get("data-block-id")
if block_id is None:
continue
# Persist room name across merged rows
room_tag = row.find("span", {"class": "hprt-roomtype-icon-link"})
if room_tag:
last_room = room_tag.text.strip()
# Extract price
price = row.find("div", {"class": "bui-price-display__value prco-text-nowrap-helper prco-inline-block-maker-helper prco-f-font-heading"})
if price is None:
continue
k["room"] = last_room
k["price"] = price.text.strip()
g.append(k)
k = {}
# --- Final output ---
l.append(g)
l.append(o)
l.append(fac_arr)
print(l)
With Scrapingdog you will be able to scrape millions of pages from booking.com without getting blocked.
Here are 5 Quick key takeaways 👇
- Booking.com data can be scraped by first collecting hotel listing URLs from search results.
- Individual hotel pages contain structured data like price, location, amenities, and ratings.
- Reviews and guest feedback can be extracted using review endpoints and pagination.
- Booking.com has anti-bot protections, so scraping at scale requires proper tools or APIs.
- The data is useful for price monitoring, market research, and travel analysis.
Conclusion
Scraping booking.com using Python is a powerful way to collect hotel data like room types and pricing. However, scraping at scale often results in IP blocks and anti-bot challenges from booking.com. While this tutorial showed you how to get started with BeautifulSoup, handling large-scale scraping manually is a hassle.
This is where Scrapingdog comes in. It helps bypass restrictions and scrape millions of booking.com pages reliably, saving you time and infrastructure costs. So, when your Python scraper hits a wall, Scrapingdog keeps the data flowing smoothly.
I have scraped Expedia using Python here, Do check it out too!!
But scraping at scale would not be possible with this process. After some time booking.com will block your IP and your data pipeline will be blocked permanently. Ultimately, you will need to track and monitor prices for hotels when you will be scraping the hotel data.
Frequently Asked Questions (FAQs)
1. How can I scrape Booking.com hotel prices with Python?
You can scrape Booking.com hotel prices with Python, Requests, and BeautifulSoup. Fetch the hotel page, parse the HTML, and extract details like price, room type, hotel name, and rating.
2. What data can a Booking.com scraper collect?
A Booking.com scraper can collect hotel name, address, rating, room type, room price, and facilities. With extra parsing, it can also collect reviews and amenities.
3. Why does Booking.com block Python scrapers?
Booking.com blocks scrapers to prevent bot traffic and repeated automated requests. If you scrape too many pages from one IP, your script can hit rate limits or IP bans.
4. Is it legal to scrape Booking.com hotel prices?
Scraping publicly available hotel data is usually possible, but you should still check Booking.com’s terms and scrape responsibly. Avoid heavy request volumes or anything that could disrupt the platform.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey: