
TL;DR
- Scrape dynamic, JS-heavy pages in Python by fetching rendered HTML with Scrapingdog and parsing it with
BeautifulSoup. - Quick setup: install
requests+bs4; sign up, 1,000 free credits. - Demo converts an Amazon results page into a clean
JSONlist of book titles. - Takeaway: skip local headless stacks; this API +
BS4pattern is fast and reliable for dynamic sites.
One of the challenges of data scraping is dealing with dynamic web pages. In this post, we’ll show you how to scrape dynamic web pages with Python.
We’ll also provide some tips on avoiding common scraping pitfalls.
In the previous post, we learned how to scrape static websites using Python selenium. Well, honestly that was the easiest part of scraping.
Now, if you want to scrape dynamic websites that use JavaScript libraries like React.js, Vue.js, Angular.js, etc. you have to put in the extra effort.
It is an easy but lengthy process if you are going to install all the libraries like Selenium, Puppeteer, and headerless browsers like Phantom.js.
Why scrape dynamic web page content?
As the name suggests, dynamic web pages are those that change in response to user interaction. This makes them difficult to scrape, since the data you want to extract may not be present in the initial page load.
However, there are still many cases where scraping dynamic web pages can be useful. For example, if you want to get the latest prices from an online store, or extract data from a website that doesn’t have an API.
There are many reasons why you might want to scrape dynamic web pages. Some common use cases include:
- Extracting data that isn’t available through an API
- Getting the latest data from a website (e.g. extracting prices from an online store)
- Monitoring changes to a website
What will we need for scraping dynamic web pages content?
Web scraping is divided into two simple parts —
- Fetching data by making an HTTP request
- Extracting important data by parsing the HTML DOM
We will be using Python and Scrapingdog API :
- Beautiful Soup is a Python library for pulling data out of HTML and XML files.
- Requests allow you to send HTTP requests very easily.
Setup
Our setup is pretty simple. Just create a folder and install Beautiful Soup & requests. To create a folder and install libraries type the below-given commands. I am assuming that you have already installed Python 3.x.
mkdir scraper
pip install beautifulsoup4
pip install requests
Now, create a file inside that folder by any name you like. I am using scraping.py.Firstly, you have to sign up for the scrapingdog API. It will provide you with 1000 FREE credits. Then just import Beautiful Soup & requests in your file. like this.
from bs4 import BeautifulSoup
import requests
Let’s scrape the dynamic content
Now, we are familiar with Scrapingdog and how it works. But for reference, you should read the documentation of this API. This will give you a clear idea of how this API works. Now, we will scrape Amazon for Python books’ titles.
Also, I have a dedicated article on scraping Amazon Product details using Python. You can check that out too!! (But, after this blog)
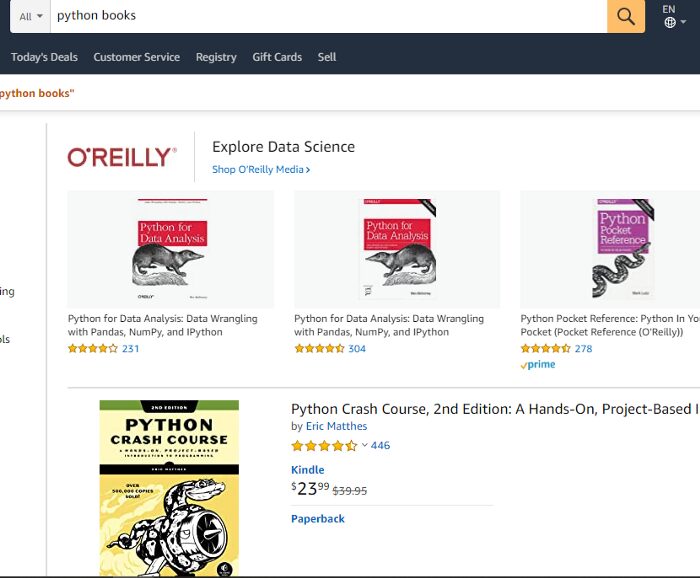
Now we have 16 books on this page. We will extract HTML from Scrapingdog API and then we will use Beautifulsoup to generate a JSON response. Now in a single line, we will be able to scrape Amazon. For requesting an API I will use requests.
r = requests.get(‘https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://www.amazon.com/s?k=python+books&ref=nb_sb_noss_2&dynamic=true').text
This will provide you with an HTML code of that target URL. Now, you have to use BeautifulSoup to parse HTML.
soup = BeautifulSoup(r,’html.parser’)
Every title has an attribute of “class” with the name “a-size-mini a-spacing-none a-color-base s-line-clamp-2” and tag “h2”. You can look at that in the below image.
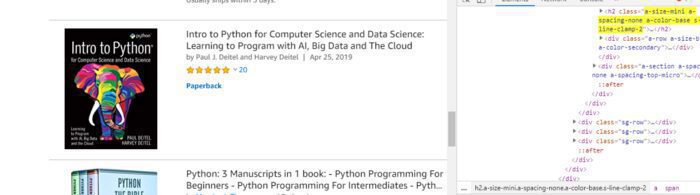
First, we will find out all those tags using variable soup.
allbooks = soup.find_all(“h2”,{“class”:”a-size-mini a-spacing-none a-color-base s-line-clamp-2"})
Then we will start a loop to reach all the titles of each book on that page using the length of the variable “allbooks”.
l={}
u=list()
for i in range(0,len(allbooks)):
l[“title”]=allbooks[i].text.replace(“\n”,””)
u.append(l)
l={}
print({"Titles":u})
The list “u” has all the titles and we just need to print it. Now, after printing the list “u” out of the for loop we get a JSON response. It looks like…
{
“Titles”: [
{
“title”: “Python for Beginners: 2 Books in 1: Python Programming for Beginners, Python Workbook”
},
{
“title”: “Python Tricks: A Buffet of Awesome Python Features”
},
{
“title”: “Python Crash Course, 2nd Edition: A Hands-On, Project-Based Introduction to Programming”
},
{
“title”: “Learning Python: Powerful Object-Oriented Programming”
},
{
“title”: “Python: 4 Books in 1: Ultimate Beginner’s Guide, 7 Days Crash Course, Advanced Guide, and Data Science, Learn Computer Programming and Machine Learning with Step-by-Step Exercises”
},
{
“title”: “Intro to Python for Computer Science and Data Science: Learning to Program with AI, Big Data and The Cloud”
},
{
“title”: “Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython”
},
{
“title”: “Automate the Boring Stuff with Python: Practical Programming for Total Beginners”
},
{
“title”: “Python: 2 Books in 1: The Crash Course for Beginners to Learn Python Programming, Data Science and Machine Learning + Practical Exercises Included. (Artifical Intelligence, Numpy, Pandas)”
},
{
“title”: “Python for Beginners: 2 Books in 1: The Perfect Beginner’s Guide to Learning How to Program with Python with a Crash Course + Workbook”
},
{
“title”: “Python: 2 Books in 1: The Crash Course for Beginners to Learn Python Programming, Data Science and Machine Learning + Practical Exercises Included. (Artifical Intelligence, Numpy, Pandas)”
},
{
“title”: “The Warrior-Poet’s Guide to Python and Blender 2.80”
},
{
“title”: “Python: 3 Manuscripts in 1 book: — Python Programming For Beginners — Python Programming For Intermediates — Python Programming for Advanced”
},
{
“title”: “Python: 2 Books in 1: Basic Programming & Machine Learning — The Comprehensive Guide to Learn and Apply Python Programming Language Using Best Practices and Advanced Features.”
},
{
“title”: “Learn Python 3 the Hard Way: A Very Simple Introduction to the Terrifyingly Beautiful World of Computers and Code (Zed Shaw’s Hard Way Series)”
},
{
“title”: “Python Tricks: A Buffet of Awesome Python Features”
},
{
“title”: “Python Pocket Reference: Python In Your Pocket (Pocket Reference (O’Reilly))”
},
{
“title”: “Python Cookbook: Recipes for Mastering Python 3”
},
{
“title”: “Python (2nd Edition): Learn Python in One Day and Learn It Well. Python for Beginners with Hands-on Project. (Learn Coding Fast with Hands-On Project Book 1)”
},
{
“title”: “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems”
},
{
“title”: “Hands-On Deep Learning Architectures with Python: Create deep neural networks to solve computational problems using TensorFlow and Keras”
},
{
“title”: “Machine Learning: 4 Books in 1: Basic Concepts + Artificial Intelligence + Python Programming + Python Machine Learning. A Comprehensive Guide to Build Intelligent Systems Using Python Libraries”
}
]
}
Isn’t that amazing? We managed to scrape Amazon in just 5 minutes of setup. We have an array of python Objects containing the title of the Python books from the Amazon website. In this way, we can scrape the data from any dynamic website.
Key Takeaways:
Dynamic websites load content using JavaScript, which cannot be scraped with simple HTTP requests alone.
Tools like Selenium, Puppeteer, or headless browsers are required to render JavaScript content.
Waiting for elements to load is crucial to avoid incomplete data extraction.
Handling scrolling, clicks, and AJAX requests is often necessary for full content retrieval.
Scalable scraping of dynamic sites requires proxy management and anti-bot handling.
Conclusion
In this article, we first understood what are dynamic websites and how we can scrape data using Scrapingdog & BeautifulSoup regardless of the type of website. Feel free to comment and ask me anything. You can follow me on Twitter and Medium. Thanks for reading and please hit the like button!
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:


