
TL;DR
- Python tutorial to scrape an eBay product with
requests+BeautifulSoup. - Extracts title, rating, price, list price / discount, shipping, and image URLs; full code included.
- Fine for demos; at scale eBay blocks , use Scrapingdog to fetch reliably; 1,000 free credits; >99% success.
- Useful for price tracking and market analysis.
eBay scraper can collect a large amount of data about sellers, their offer price, their ratings, etc. This data can help you analyze the dynamic market or if you are a seller itself on eBay then you can monitor your own competitor by scraping prices. Over time once you have a large data set you can identify trends in product popularity, seller behavior, and buyer preferences, which can help you stay ahead of the curve in your industry.
In this article, we are going to extract product information from eBay by creating our own eBay scraper. Through this, we will learn how we can create a seamless data pipeline from eBay by extracting crucial information for target products.
Setting up the prerequisites for eBay scraping
I hope you have already installed Python 3.x on your machine. If not then you can download it from here. Apart from this, we will require two III-party libraries of Python.
- Requests– Using this library we will make an HTTP connection with the Amazon page. This library will help us to extract the raw HTML from the target page.
- BeautifulSoup– This is a powerful data parsing library. Using this we will extract necessary data out of the raw HTML we get using the requests library.
Before we install these libraries we will have to create a dedicated folder for our project.
mkdir ebayscraper
Now, we will have to install the above two libraries in this folder. Here is how you can do it.
pip install beautifulsoup4
pip install requests
Now, you can create a Python file by any name you wish. This will be the main file where we will keep our code. I am naming it ebay.py.
Downloading raw data from ebay.com
Before we dive in let’s test type a small Python script to proof test it. This is just to determine that our code will be able to scrape eBay without getting blocked.
Our target page is this. It is a wristwatch.
import requests
from bs4 import BeautifulSoup
target_url="https://www.ebay.com/itm/182905307044"
resp = requests.get(target_url)
print(resp.status_code)
Well, the code is very clear and concise. But let me explain to you line by line.
- The
requestslibrary is imported in the first line. - The
BeautifulSoupclass from thebs4(Beautiful Soup) library is also imported. - The
target_urlvariable is assigned the value of the desired URL to scrape, in this case, “https://www.ebay.com/itm/182905307044“. You can replace this URL with the desired target URL. - The
requests.get()function is used to send an HTTP GET request to thetarget_url. The response from the server is stored in therespvariable. - The
resp.status_codeis printed, which will display the HTTP status code returned by the server in response to the GET request.
By executing this code, you will be able to retrieve the HTTP status code of the response received from the target URL. The status code can provide information about the success or failure of the request, such as 200 for a successful request or 404 for a page not found error.
Once you run this code you should see 200 on the console.
So, our setup script successfully scraped eBay and downloaded the HTML we wanted. Now, let’s decide what exact information we want to extract from the page.
What are we going to scrape from eBay?
Deciding this in advance helps us identify the location of all the data elements inside the DOM at once.
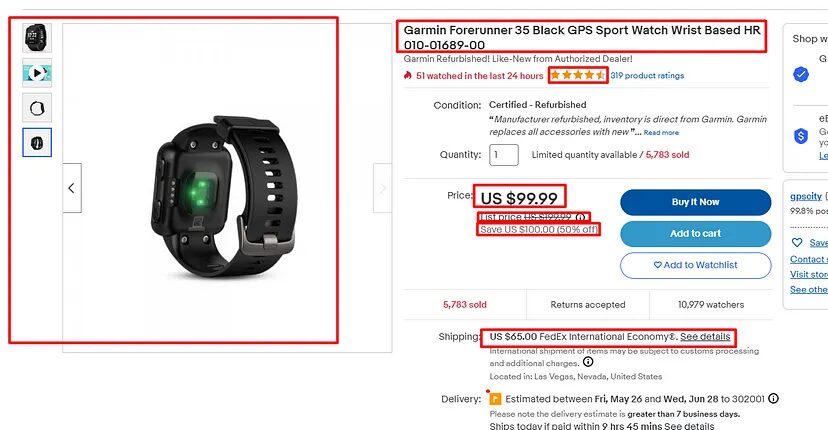
We are going to scrape seven data elements from the page.
- Images of the product
- Title of the product
- Rating
- Price
- Listed Price
- Discount/Savings
- Shipping charges
To start, we will use the requests library to send a GET request to the target page. After that, we will utilize the BeautifulSoup library to extract the desired data from the response. While there are alternative libraries like lxml available for parsing, BeautifulSoup stands out with its robust and user-friendly API.
Prior to sending the request, we will analyze the page and determine the position of each element within the Document Object Model (DOM). It is advisable to perform this exercise in order to accurately locate each element on the page.
We will accomplish this by utilizing the developer tool. To access it, simply right-click on the desired element and select “Inspect”. This is a commonly used method, and you may already be familiar with it.
Identifying the location of each element
Scraping Title of the product
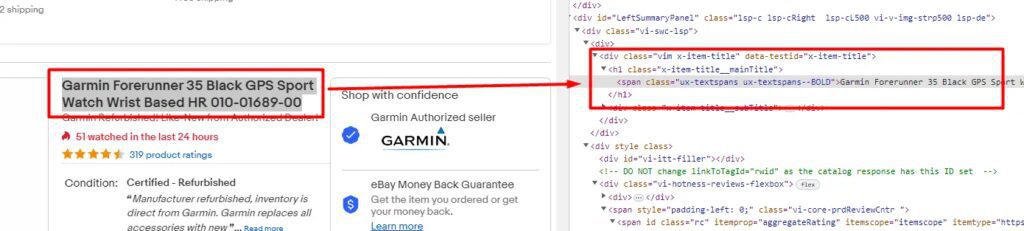
As you can see the title of the product is stored inside the h1 tag with class x-item-title__mainTitle. So, scraping this would be super simple.
l=[]
o={}
image_list=[]
soup=BeautifulSoup(resp.text,'html.parser')
o["title"]=soup.find("h1",{"class":"x-item-title__mainTitle"}).text
First, we have declared some empty lists and an object to store all the scraped data.
The fourth line creates a BeautifulSoup object named soup by parsing the HTML content of the resp response object. The HTML parser used is specified as 'html.parser'.
The last line finds an h1 element with a class attribute of "x-item-title__mainTitle" within the parsed HTML content. It then accesses the text attribute to retrieve the text content of the h1 element. Finally, it assigns this text to the o dictionary with the key "title".
To fully grasp the meaning of the code snippet provided above, it is essential to have prior knowledge of the preceding section where we discussed the process of retrieving HTML data from the target page. Therefore, I strongly recommend reviewing the earlier section before proceeding further with the coding.
Scraping Rating of the product
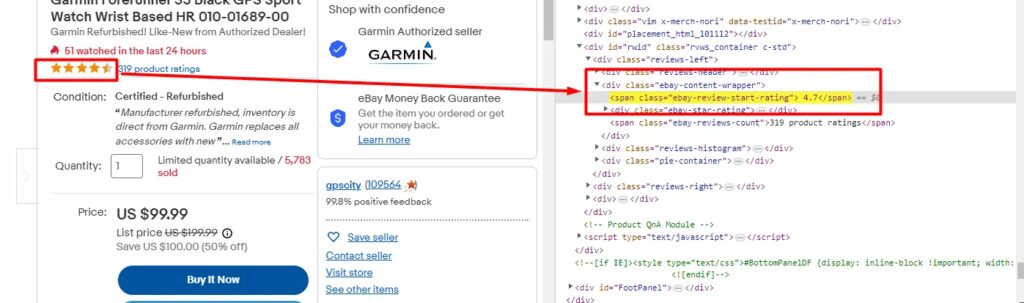
As you can see in the above image, the rating is hidden inside the span tag with class ebay-review-start-rating. Scraping rating is super simple. Here is how you can do it.
o["rating"]=soup.find("span",{"class":"ebay-review-start-rating"}).text.strip()
The strip() method is then applied to remove any leading or trailing whitespace characters from the extracted text.
Scraping the Actual Price
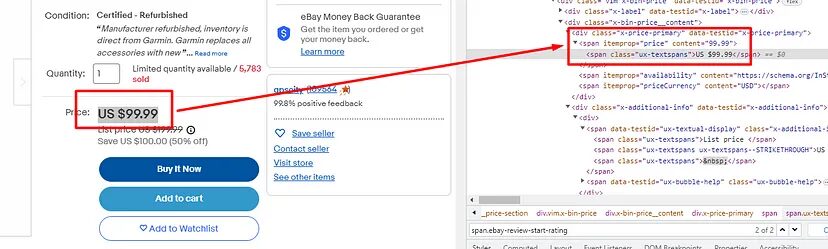
The price is hidden inside span tag with attribute itemprop and value as price.
Scraping the list price and the discount
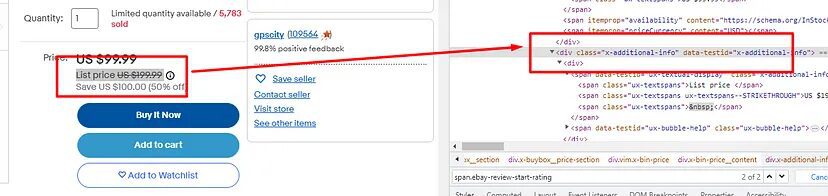
When you inspect you will notice that both the listing price and the discount are listed inside the div tag with class x-additional-info. So, let’s first find this class using the .find() method of BS4.
box=soup.find("div",{"class":"x-additional-info"})
Now, let’s find where the price and discount are stored.
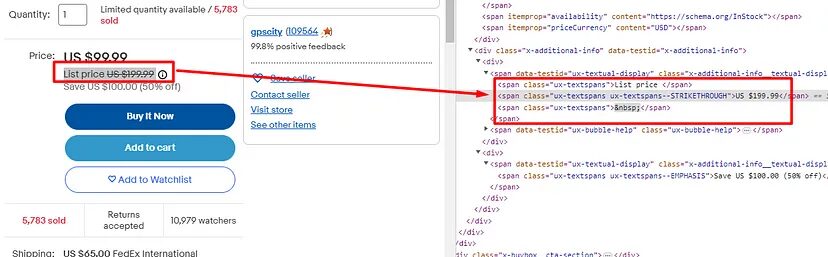
So, the listed price is stored inside span tag with class ux-textspans — STRIKETHROUGH.
o["list_price"]=box.find("span",{"class":"ux-textspans--STRIKETHROUGH"}).text
Similarly, the discount is stored inside a span tag with class ux-textspans — EMPHASIS.
o["discount"]=box.find("span",{"class":"ux-textspans--EMPHASIS"}).text
Scraping the Shipping Charges
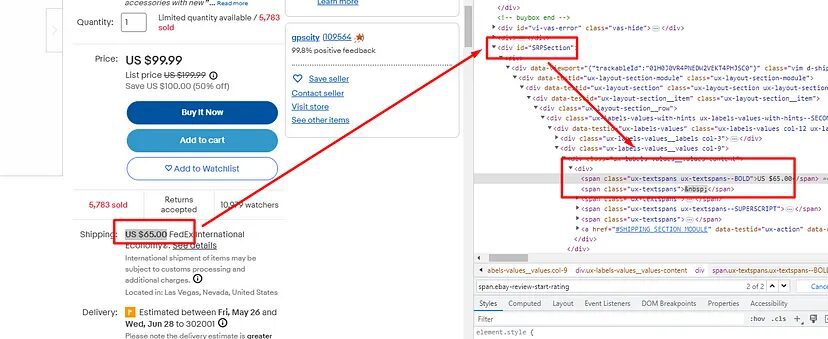
Shipping charges are stored inside the span tag with class ux-textspans — BOLD and this span tag is inside the div tag with id SRPSection.
o["shipping_price"]=soup.find("div",{"id":"SRPSection"}).find("span",{"class":"ux-textspans--BOLD"}).text
Scraping the product Images
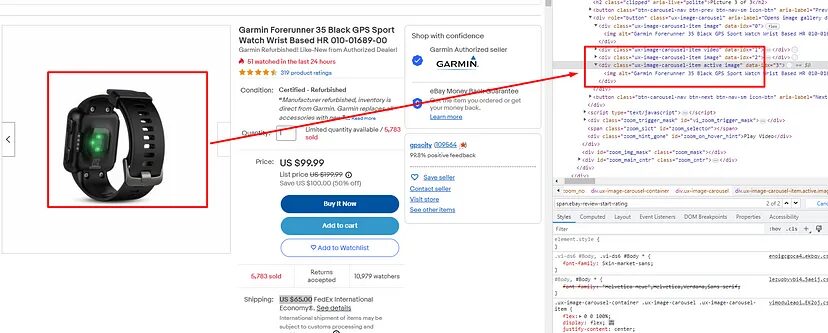
All the product images are stored inside the div tag with the class ux-image-carousel-item. Inside each of these div tags, there is an img tag where the URL of the image is stored.
So, let’s first crawl all of these div tags and then with the help of for loop we will extract values of the src attributes of the img tag.
images=soup.find_all("div",{"class":"ux-image-carousel-item"})
Here we are looking for <div> elements with the class attribute “ux-image-carousel-item”. The find_all() method returns a list of all matching elements found in the HTML document. The extracted elements are assigned to the images variable.
Now we will use for loop to iterate over all the div tags and extract the image URL.
for image in images:
image_url=image.find("img").get('data-src')
image_list.append(image_url)
l.append(o)
l.append(image_list)
print(l)
All the images are inside the src attribute. But once you scrape the page it will appear as data-src instead of simply src. That’s why we have used data-src above.
With this, we have scraped all the data we decided on earlier. You can also use try/except statement to avoid any kind of error.
Complete Code
On our target page, there is a tremendous amount of data that can be used for data analysis. You can of course make changes to the code and extract more data points from the page.
You can even use a cron job to run a crawler at a particular time and once the product is available at your target price it will send you an email.
But for now, the code will look like this.
import requests
from bs4 import BeautifulSoup
l=[]
o={}
image_list=[]
target_url="https://www.ebay.com/itm/182905307044"
resp = requests.get(target_url)
soup=BeautifulSoup(resp.text,'html.parser')
o["title"]=soup.find("h1",{"class":"x-item-title__mainTitle"}).text
o["rating"]=soup.find("span",{"class":"ebay-review-start-rating"}).text.strip()
o["actual_price"]=soup.find("span",{"itemprop":"price"}).text
box=soup.find("div",{"class":"x-additional-info"})
images=soup.find_all("div",{"class":"ux-image-carousel-item"})
for image in images:
image_url=image.find("img").get('data-src')
image_list.append(image_url)
o["list_price"]=box.find("span",{"class":"ux-textspans--STRIKETHROUGH"}).text
o["discount"]=box.find("span",{"class":"ux-textspans--EMPHASIS"}).text
o["shipping_price"]=soup.find("div",{"id":"SRPSection"}).find("span",{"class":"ux-textspans--BOLD"}).text
l.append(o)
l.append(image_list)
print(l)
Once you run this code it will return this.

Using Scrapingdog for eBay scraping
The technique we have used will not be enough for crawling eBay at scale. Because eBay detects that the traffic is coming from a bot/script it will block our IP and your data pipeline will stop pulling data from the website.
Here you can use Web Scraping APIs like Scrapingdog which can help you pull millions of pages from eBay without getting blocked. Scrapingdog uses new IP on every request which makes scraping completely anonymous.
You can start with 1000 free credits that you get once you sign up.
Once you sign up, you will be redirected to your dashboard. The dashboard will look somewhat like this.
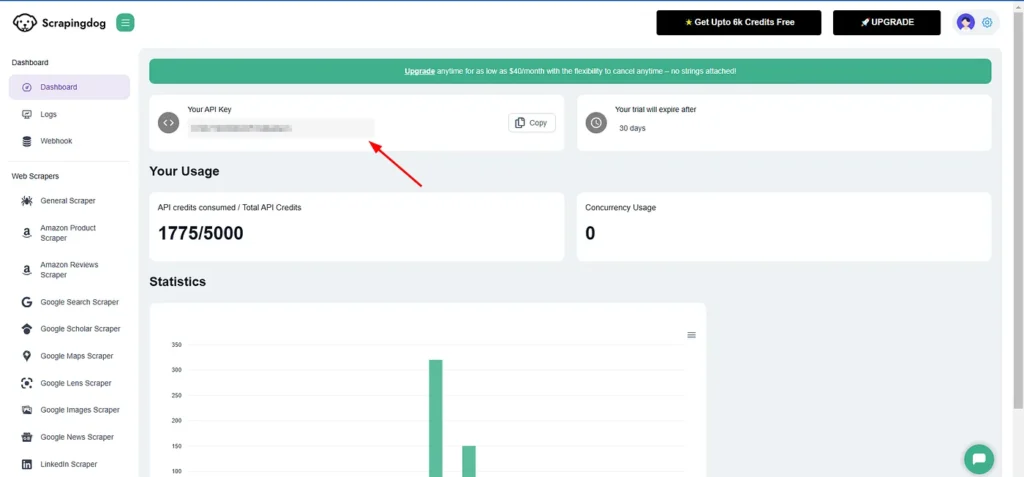
You have to use your API key.
Now, you can paste your target indeed target page link to the left and then select JS Rendering as No. After this click on Copy Code from the right. Now use this API in your script to scrape eBay.
import requests
from bs4 import BeautifulSoup
l=[]
o={}
image_list=[]
target_url="https://api.scrapingdog.com/scrape?api_key=xxxxxxxxxxxxxx&url=https://www.ebay.com/itm/182905307044&dynamic=false"
resp = requests.get(target_url)
soup=BeautifulSoup(resp.text,'html.parser')
o["title"]=soup.find("h1",{"class":"x-item-title__mainTitle"}).text
o["rating"]=soup.find("span",{"class":"ebay-review-start-rating"}).text.strip()
o["actual_price"]=soup.find("span",{"itemprop":"price"}).text
box=soup.find("div",{"class":"x-additional-info"})
images=soup.find_all("div",{"class":"ux-image-carousel-item"})
for image in images:
image_url=image.find("img").get('data-src')
image_list.append(image_url)
o["list_price"]=box.find("span",{"class":"ux-textspans--STRIKETHROUGH"}).text
o["discount"]=box.find("span",{"class":"ux-textspans--EMPHASIS"}).text
o["shipping_price"]=soup.find("div",{"id":"SRPSection"}).find("span",{"class":"ux-textspans--BOLD"}).text
l.append(o)
l.append(image_list)
print(l)
You will notice the code will remain somewhat the same as above. We just have to change one thing and that is our target URL.
You don’t have to bother about retrying on a failed request or even passing any header. All of this will be handled by Scrapingdog itself.
So, give Scrapingdog’s Scraping API a try. You can sign up from here (NO CREDIT CARD REQUIRED)
Key Takeaways:
eBay listings contain structured data such as product title, price, seller details, ratings, and shipping information.
Scraping requires handling pagination to collect multiple product results across pages.
eBay uses anti-bot protections, making headers, delays, and proxy rotation important.
Extracted data can support price monitoring, competitor analysis, and product research.
Structured output formats like JSON or CSV make eBay data easy to analyze and integrate into tools.
Conclusion
In this tutorial, we scraped various data elements from eBay. First, we used the requests library to download the raw HTML, and then using BS4 we parsed the data we wanted. Finding the locations of each element was super simple in this tutorial. I must say scraping eBay is way easier than Amazon price scraping or scraping Walmart for a beginner. I do have a recent guide on scraping Amazon reviews using Python, do check it out too!
Combination of requests and Scrapingdog can help you scale your eBay scraping. You will get more than a 99% success rate while scraping eBay with Scrapingdog.
I hope you like this little tutorial in which we learned how to build an eBay scraper. And if you liked it then please do not forget to share it with your friends and on your social media.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:


