
TL;DR
- Scrape Expedia in Python: render pages with
Selenium; add real headers so prices load. - Parse with
BeautifulSoupto grab hotel name, room type, and prices (before / after tax); full code included. - For scale, switch to Scrapingdog’s Web Scraping API — handles headers, rotating IPs, retries, residential proxies; quick dashboard setup with a free account.
Web scraping has become essential in today’s data-driven world, enabling individuals and businesses to gather crucial information and insights from various websites.
In the case of Expedia, a leading online travel agency (OTA) and metasearch engine, web scraping allows you to collect valuable data on hotels, flights, rental cars, cruises, and vacation packages. This data allows you to analyze price trends, track deals, and discounts, monitor customer reviews, and even create travel apps or websites.
In this blog post, we will discuss essential web scraping concepts. To ensure you’re equipped with the necessary skills to scrape Expedia’s website, we’ll also share practical examples and step-by-step tutorials on how to effectively navigate through the intricacies of the platform.
Setting up the prerequisites for scraping Expedia
In this tutorial, we are going to use Python 3.x.
I hope you have already installed Python on your machine. If not then you can download it from here.
Then create a folder in which you will keep the Python script. Then create a Python file where you will write the code.
mkdir Expedia
Then inside this folder create a Python file that will be used to write Python code for scraping Expedia.
Installation
For scraping Expedia we will take the support of some III party libraries.
Selenium– Selenium is a popular web scraping tool for automating web browsers. It is often used to interact with dynamic websites, where the content of the website changes based on user interactions or other events. You can install it like this.
pip install selenium
2. BeautifulSoup– It will be used for parsing raw HTML. You can install it like this.
pip install beautifulsoup4
3. We also need a Chromium web driver to render Expedia. Remember to keep the version of the Chromium web driver and your Chrome browser the same otherwise, it will keep generating an error.
You can download it from here.
Setup and Testing
Let’s first create a small setup and render the website. This is just to make sure everything works fine for us later. The target URL for this tutorial will be a hotel page from Expedia.
from bs4 import BeautifulSoup
from selenium import webdriver
import time
PATH = 'C:\Program Files (x86)\chromedriver.exe'
l=list()
o={}
target_url = "https://www.expedia.com/Cansaulim-Hotels-Heritage-Village-Resort-Spa-Goa.h2185154.Hotel-Information?=one-key-onboarding-dialog&chkin=2023-05-13&chkout=2023-05-14&destType=MARKET&destination=Goa%2C%20India%20%28GOI-Dabolim%29&latLong=15.383019%2C73.838253®ionId=6028089&rm1=a2"
driver=webdriver.Chrome(PATH)
driver.get(target_url)
time.sleep(5)
resp = driver.page_source
driver.close()
print(resp)
The code is pretty straightforward but let me break it down for you.
- The first three lines import the required modules, including BeautifulSoup for parsing HTML documents, Selenium WebDriver for automating web browsers, and time for pausing the program execution for a specified amount of time.
- The next line sets the path for the Chrome WebDriver executable file. The WebDriver is needed to launch the Chrome browser for web scraping.
- The next two lines define an empty
list land an emptydictionary othat will be used later in the program to store the scraped data. - The
target_urlvariable contains the URL of the target Expedia page that we want to scrape. It includes the check-in and check-out dates, the destination, and other parameters needed to perform a hotel search. - The
webdriver.Chrome(PATH)line launches the Chrome browser using the Chrome WebDriver executable file. ThePATHvariable specifies the location of the Chrome WebDriver executable file. - The
driver.get(target_url)line loads the target URL in the Chrome browser. - The
time.sleep(5)line pauses the program execution for 5 seconds to give the web page time to load and render. - The
driver.page_sourceline retrieves the HTML source code of the loaded web page. - The
driver.close()line closes the Chrome browser. - Finally, the
print(resp)line prints the retrieved HTML source code to the console output.
I hope you have got an idea now. Before we run this code let’s see what the page actually looks like in our browser.
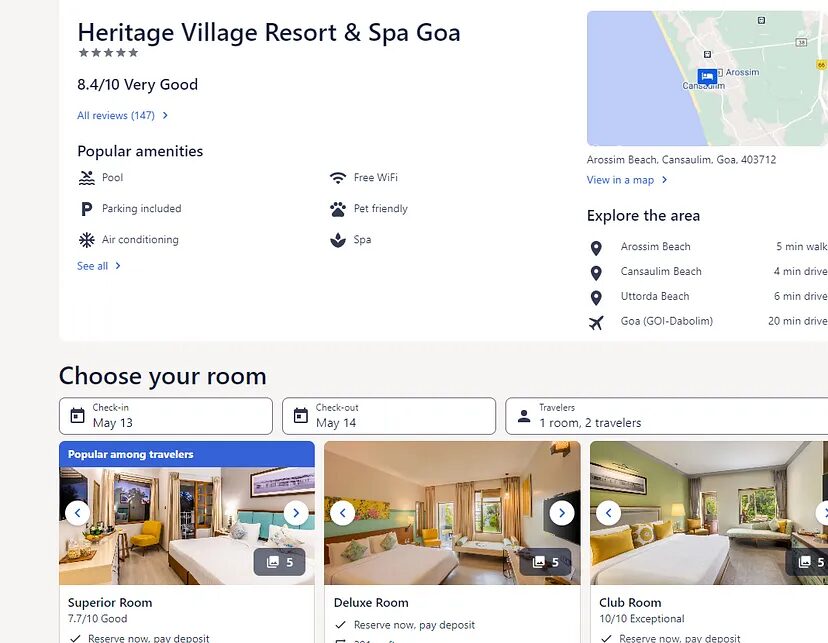
As you can see at the top there is the name of the hotel and at the bottom, you can find multiple room types and their pricing. Now, let’s run our code and see what appears on our screen.
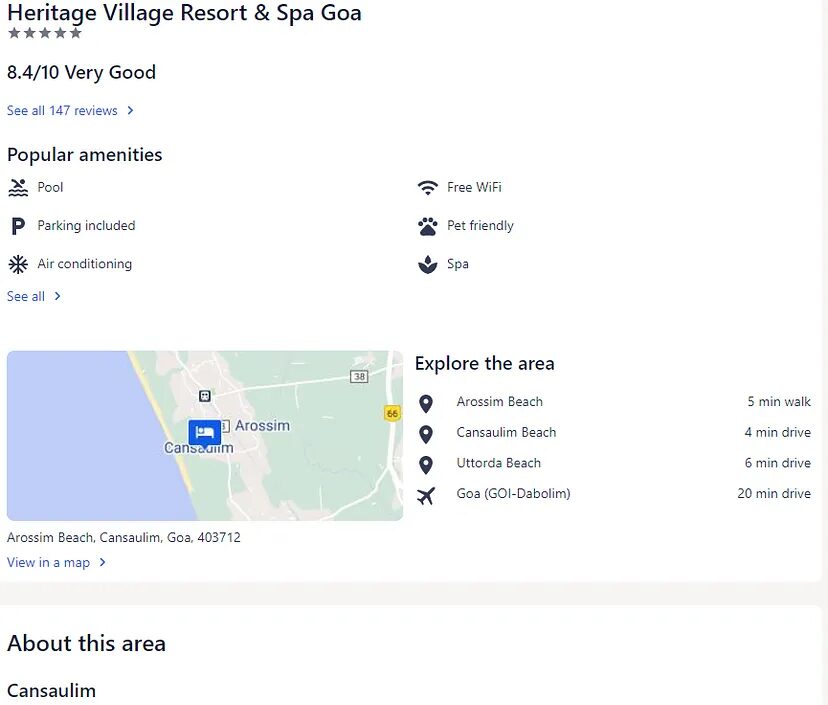
This will appear on your Chrome Webdriver screen once you run your code. Did you notice the difference?
Well, the prices are not visible when we run the code. Why is that?
The reason behind this is HTTP headers. While scraping Expedia we have to pass multiple headers like User-Agent, Accept, Accept-Encoding, Referer, etc.
Bypassing all these headers in web scraping requests, we can make the request appear more like a legitimate user request, thereby reducing the chances of being detected and blocked by the website.
So, let’s make the changes to the code and then run it.
from bs4 import BeautifulSoup
from selenium import webdriver
import time
PATH = 'C:\Program Files (x86)\chromedriver.exe'
options = webdriver.ChromeOptions()
options.add_argument('user-agent=Mozilla/5.0 (Linux; Android 11; SM-G991B) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Mobile Safari/537.36')
options.add_argument('accept-encoding=gzip, deflate, br')
options.add_argument('accept=text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7')
options.add_argument('referer=https://www.expedia.com/')
options.add_argument('upgrade-insecure-requests=1')
l=list()
o={}
target_url = "https://www.expedia.com/Cansaulim-Hotels-Heritage-Village-Resort-Spa-Goa.h2185154.Hotel-Information?=one-key-onboarding-dialog&chkin=2023-05-13&chkout=2023-05-14&destType=MARKET&destination=Goa%2C%20India%20%28GOI-Dabolim%29&latLong=15.383019%2C73.838253®ionId=6028089"
driver=webdriver.Chrome(PATH,options=options)
driver.get(target_url)
# driver.maximize_window()
time.sleep(5)
resp = driver.page_source
driver.close()
print(resp)
We have created a new instance webdriver.ChromeOptions() which is a class that allows you to configure options for the Chrome browser. Then we added five headers using add_argument() method. add_argument() helps us to add command-line arguments to the options.
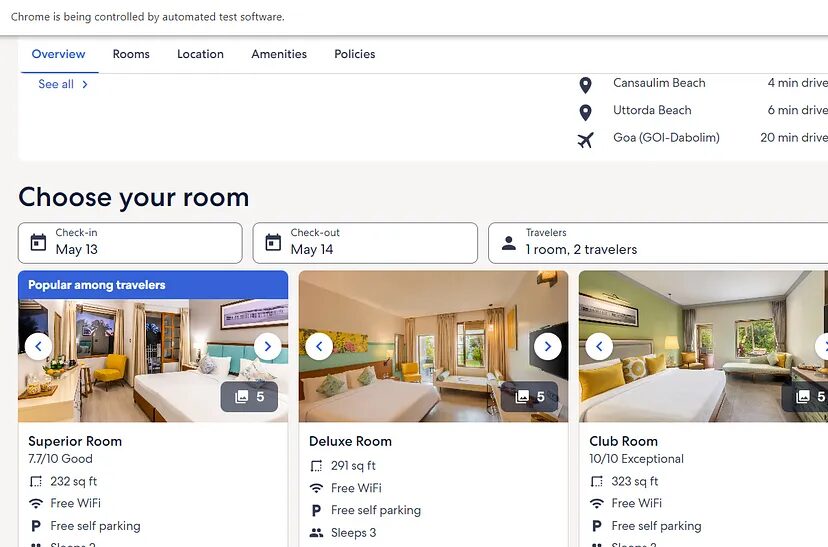
As you can see we have managed to render the complete page of Expedia by adding custom headers. Now, let’s decide what exactly we want to scrape.
What are we going to scrape from Expedia?
It is always better to decide in advance what data you want to parse from the raw data.
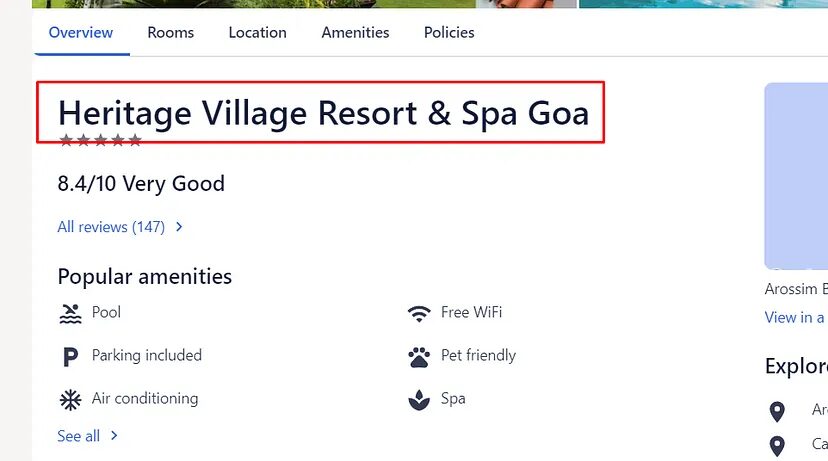
For this tutorial, we are going to scrape:
- Name of the hotel
- Room Type
- Price Before Tax
- Price After Tax
Let’s start scraping Expedia!!
Before we scrape any text we have to identify their position inside the DOM. Continuing with the above code, we will first find the locations of each element and then extract them with the help of BS4. We will use .find() and .find_all() methods provided by the BS4. If you want to learn more about BS4 then you should refer BeautifulSoup Tutorial.
Let’s start with the name first.
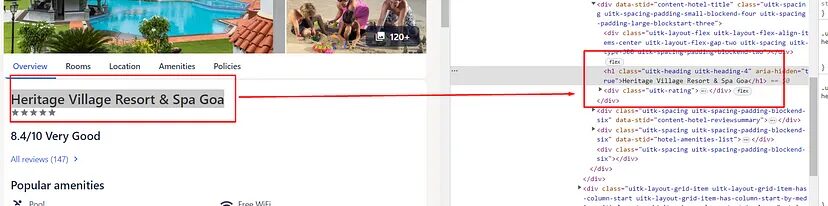
So, the name is stored inside the h1 tag. Scraping this would be super easy.
soup=BeautifulSoup(resp,'html.parser')
try:
o["hotel"]=soup.find("h1").text
except:
o["hotel"]=None
- Here we created a BeautifulSoup object. The resulting
soupthe object is an instance of theBeautifulSoupclass, which provides a number of methods for searching and manipulating the parsed HTML document. - Then using
.find()method of BS4 we are extracting the text.
Now let’s scrape the room-type data. But before that let us examine where are these room blocks are located.
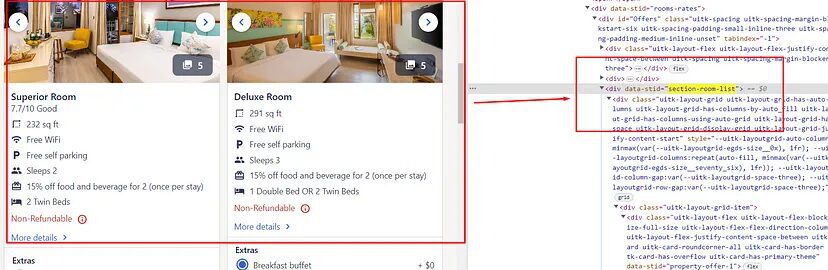
As you can see this complete section of rooms is located inside div tag with attribute data-stid whose value is section-room-list.
allOffers = soup.find("div",{"data-stid":"section-room-list"})
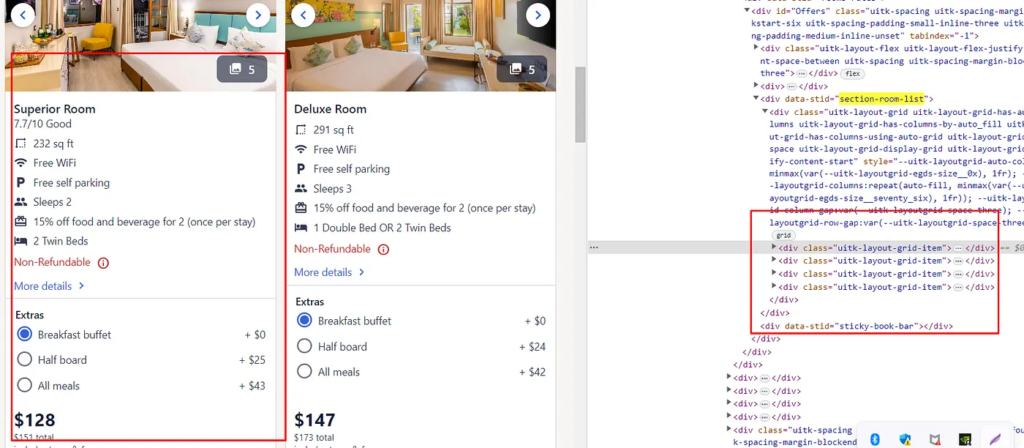
Inside this, you will notice that all these individual rooms details are stored inside div tag with class uitk-layout-grid-item.
Offers = allOffers.find_all("div",{"class":"uitk-layout-grid-item"})
Now, it will be much easier to scrape room-type text.
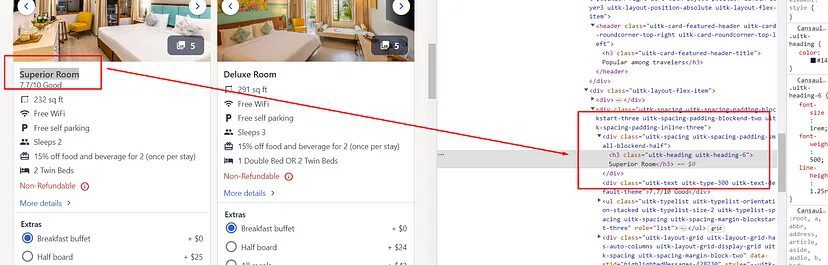
You will notice that each room-type text is stored inside div tag with class uitk-spacing-padding-small-blockend-half and this element is inside div tag with class uitk-spacing-padding-blockstart-three.
Since there are multiple rooms then we have to run a for loop in order to access all the room details. All we have to do is run a for loop which will iterate over Offers list.
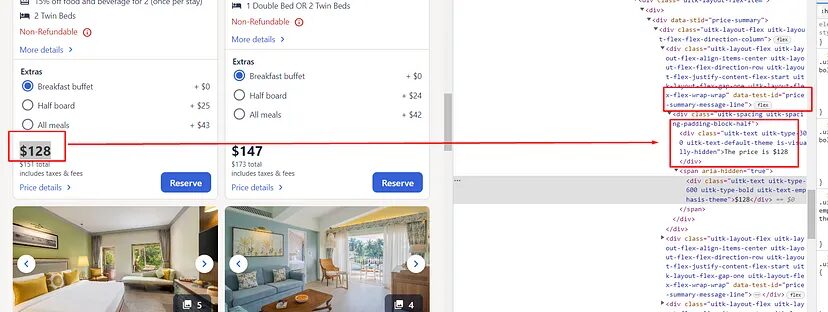
Now, both the pricing are stored inside div tag with an attribute data-test-id whose value is price-summary-message-line. We just have to find all such elements inside each room block. For that I will use find_all() method inside the loop.
price_arr=Offer.find_all("div",{"data-test-id":"price-summary-message-line"})
try:
o["price_before_tax"]=price_arr[0].find("span").text
except:
o["price_before_tax"]=None
try:
o["price_after_tax"]=price_arr[1].text.replace(" total","")
except:
o["price_after_tax"]=None
l.append(o)
o={}
Finally, we have managed to scrape all the data points from Expedia.
Complete Code
Now, of course, you can scrape many more things like ratings, reviews, amenities, etc. But for now, the code will look like this.
from bs4 import BeautifulSoup
from selenium import webdriver
import time
PATH = 'C:\Program Files (x86)\chromedriver.exe'
options = webdriver.ChromeOptions()
options.add_argument('user-agent=Mozilla/5.0 (Linux; Android 11; SM-G991B) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Mobile Safari/537.36')
options.add_argument('accept-encoding=gzip, deflate, br')
options.add_argument('accept=text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7')
options.add_argument('referer=https://www.expedia.com/')
options.add_argument('upgrade-insecure-requests=1')
l=list()
o={}
target_url = "https://www.expedia.com/Cansaulim-Hotels-Heritage-Village-Resort-Spa-Goa.h2185154.Hotel-Information?=one-key-onboarding-dialog&chkin=2023-05-13&chkout=2023-05-14&destType=MARKET&destination=Goa%2C%20India%20%28GOI-Dabolim%29&latLong=15.383019%2C73.838253®ionId=6028089"
driver=webdriver.Chrome(PATH,options=options)
driver.get(target_url)
# driver.maximize_window()
time.sleep(5)
resp = driver.page_source
driver.close()
soup=BeautifulSoup(resp,'html.parser')
allOffers = soup.find("div",{"data-stid":"section-room-list"})
Offers = allOffers.find_all("div",{"class":"uitk-layout-grid-item"})
try:
o["hotel"]=soup.find("h1").text
except:
o["hotel"]=None
l.append(o)
o={}
for Offer in Offers:
price_arr=Offer.find_all("div",{"data-test-id":"price-summary-message-line"})
try:
o["room-type"]=Offer.find("div",{"class":"uitk-spacing-padding-blockstart-three"}).find("div",{"class":"uitk-spacing-padding-small-blockend-half"}).text
except:
o["room-type"]=None
try:
o["price_before_tax"]=price_arr[0].find("span").text
except:
o["price_before_tax"]=None
try:
o["price_after_tax"]=price_arr[1].text.replace(" total","")
except:
o["price_after_tax"]=None
l.append(o)
o={}
print(l)
Once you run this code you will get this on your console.

Using Scrapingdog To Scale up Data Extraction from Expedia
The advantages of using Scrapingdog Web Scraping API are:
- You won’t have to manage headers anymore.
- Every request will go through a new IP. This keeps your IP anonymous.
- Our API will automatically retry on its own if the first hit fails.
- Scrapingdog uses residential proxies to scrape Expedia. This increases the success rate of scraping Expedia or any other such website.
You have to sign up for the free account to start using it. It will take just 10 seconds to get you started with Scrapingdog.
Once you sign up, you will be redirected to your dashboard. The dashboard will look somewhat like this.
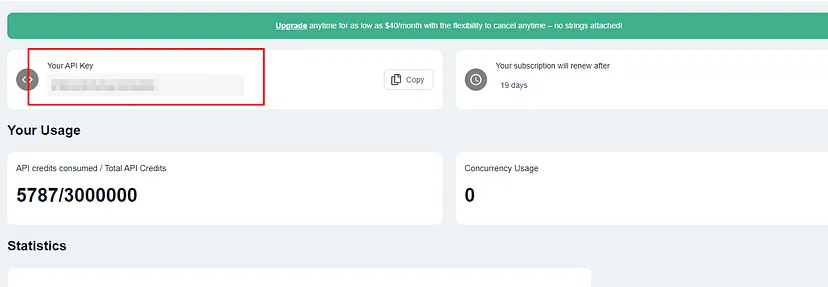
You have to use your API key.
Now, you can paste your Expedia page link to the left and then select JS Rendering as Yes. After this click on Copy Code from the right. Now use this API in your script to scrape Expedia.
from bs4 import BeautifulSoup
import requests
l=list()
o={}
resp=requests.get('https://api.scrapingdog.com/scrape?api_key=xxxxxxxxxxxxxxxxxxxxxxxxxx&url=https://www.expedia.com/Cansaulim-Hotels-Heritage-Village-Resort-Spa-Goa.h2185154.Hotel-Information?=one-key-onboarding-dialog&chkin=2023-05-13&chkout=2023-05-14&destType=MARKET&destination=Goa%2C%20India%20%28GOI-Dabolim%29&latLong=15.383019%2C73.838253®ionId=6028089')
soup=BeautifulSoup(resp.text,'html.parser')
allOffers = soup.find("div",{"data-stid":"section-room-list"})
Offers = allOffers.find_all("div",{"class":"uitk-layout-grid-item"})
try:
o["hotel"]=soup.find("h1").text
except:
o["hotel"]=None
l.append(o)
o={}
for Offer in Offers:
price_arr=Offer.find_all("div",{"data-test-id":"price-summary-message-line"})
try:
o["room-type"]=Offer.find("div",{"class":"uitk-spacing-padding-blockstart-three"}).find("div",{"class":"uitk-spacing-padding-small-blockend-half"}).text
except:
o["room-type"]=None
try:
o["price_before_tax"]=price_arr[0].find("span").text
except:
o["price_before_tax"]=None
try:
o["price_after_tax"]=price_arr[1].text.replace(" total","")
except:
o["price_after_tax"]=None
l.append(o)
o={}
print(l)
With Scrapingdog you won’t have to worry about any Chrome drivers. It will be handled automatically for you. You just have to make a normal GET request to the API.
With Scrapingdog’s API for web scraping, you will be able to scrape Expedia with a lightning-fast speed that too without getting blocked.
Key Takeaways:
Expedia listings include hotel names, prices, ratings, reviews, amenities, and availability details.
The website relies heavily on dynamic content, requiring proper handling of JavaScript-rendered pages.
Pagination and date-based search parameters must be managed to extract complete results.
Anti-bot systems require proxy rotation and request optimization for large-scale scraping.
Extracted travel data can be used for price comparison, market research, and travel analytics tools.
Conclusion
In this tutorial, we saw how headers play a crucial role while scraping websites like Expedia itself. Using Python and Selenium we were able to download full HTML code and then using BS4 we were able to parse the data.
You can use Makcorps Hotel API to get hotel prices of more than 200 OTAs (including Expedia).
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on your social media.
The best way to scrape Expedia is by using web scraping API. Scrapingdog can help you extract data at a very economical cost. Check out our pricing plan here.
When the website structure changes, we make sure that we incorporate can scrape booking.com. We have a dedicated tutorial made on that, you can check that out here. that structure change in the backend of our API for hassle-free data extraction.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:


