TL;DR
- Python guide: render Glassdoor with
Selenium, parse withBeautifulSoup; extract company, title, location, salary; save toCSV. - Pagination: scroll and click Next with
Selenium(URLs aren’t stable). - For scale: swap fetch layer to Scrapingdog’s API to avoid blocks; includes 1,000 free credits.
Web Scraping Glassdoor can provide you with some insights like what salary should one expect when applying for a job.
Employers can do Glassdoor scraping to improve their hiring strategy by comparing data with their competition. Or can use this data if building a job board.
The use cases for web scraping Glassdoor are endless and here in this article, we will extract data from jobs.
In this article, we are going to use Python & design a Glassdoor scraper. At the end of this tutorial, you will be able to save this data in a CSV file too.
What You Need To Scrape Glassdoor
For this article, we will need python 3.x, and I am assuming that you have already installed it on your machine. Along with this, we have to download third-party libraries like BeautifulSoup, Selenium, and a chromium driver.
pip install selenium
pip install beautifulsoup4
glassdoor.py
mkdir glass
What Job Details Will We Scrape from Glassdoor?
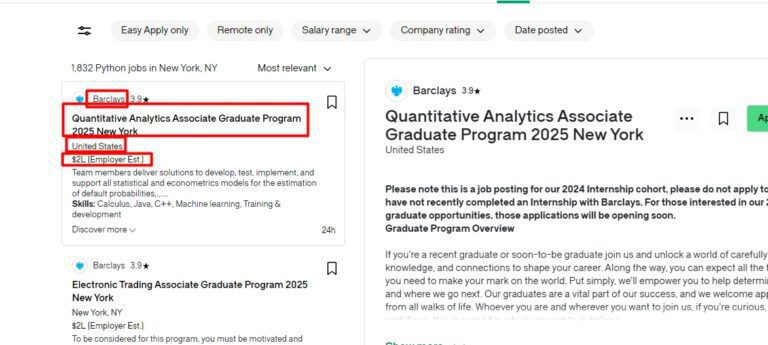
- Name of the Company
- Job Title
- Location
- Salary
First, we are going to extract the raw HTML using Selenium from the website and then we are going to use .find() and .find_all() methods of BS4 to parse this data out of the raw HTML.
Chromium will be used in coordination with Selenium to load the website. You can download Chromium from here.
Let’s Start Scraping Glassdoor Job Data
from bs4 import BeautifulSoup
from selenium import webdriver
import time
PATH = 'C:\Program Files (x86)\chromedriver.exe'
l=list()
o={}
target_url = "https://www.glassdoor.com/Job/new-york-python-jobs-SRCH_IL.0,8_IC1132348_KO9,15.htm?clickSource=searchBox"
driver=webdriver.Chrome(PATH)
driver.get(target_url)
driver.maximize_window()
time.sleep(2)
resp = driver.page_source
driver.close()
Now, let me explain to you what we have done here step by step.
- We have imported the libraries that were installed earlier in this article.
- Then we have declared
PATHwhere our chromium driver is installed. - An empty list and an empty object to store job data are also declared.
target_urlholds the target page URL of glassdoor.- Then we created an instance using
.Chromemethod. - Using
.get()method we are trying to connect with the target webpage. Chromium will load this page. - Using
.maximize_window()we are increasing the size of the chrome window to its maximum size. - Then we are using
.sleep()method to wait before we close down the chrome instance. This will help us to load the website completely. - Then using
.page_sourcewe are collecting all the raw HTML of the page. - Then finally we are closing down the chromium instance using the
.close()method provided by the Selenium API.
Once you run this code, it should open a chrome instance, load the page and then close the browser. If this too happens with your script then we can move ahead. Our main setup is ready.
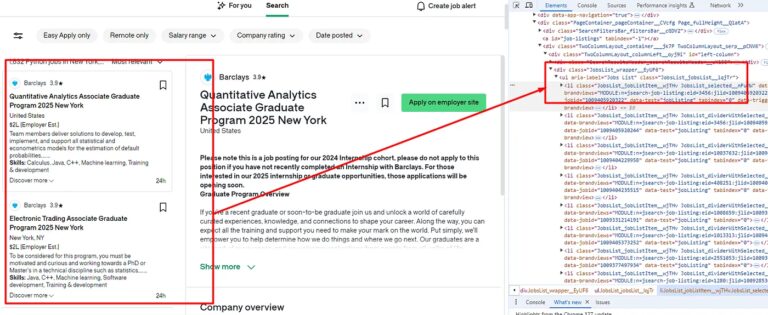
You will notice that all these jobs are under ul tag with class JobsList_jobsList__lqjTr. So, we have to find this class first. We will use .find() method of BS4 to find this tag inside our DOM.
allJobsContainer = soup.find("ul",{"class":"JobsList_jobsList__lqjTr"})
allJobs = allJobsContainer.find_all("li")
Using .find() method we are searching for the ul tag and then using .find_all() method we are searching for all the li tags inside the ul tag.
Now, we can use a for loop to access data of all the 30 jobs available on the page.
Sometimes Glassdoor will show you a page with no jobs. All you have to do is clear the cookies and try again.
Now, let’s find the location of each target element, one by one.

As you can see the name of the company can be found under the div tag with the class EmployerProfile_profileContainer__VjVBX. Let’s parse it out from the raw HTML using BS4.
for job in allJobs:
try:
o["name-of-company"]=job.find("div",{"class":"EmployerProfile_profileContainer__VjVBX"}).text
except:
o["name-of-company"]=None
Now let’s find the job name.

You can find the name of the job in a tag with the class JobCard_jobTitle___7I6y.
try:
o["name-of-job"]=job.find("a",{"class":"JobCard_jobTitle___7I6y"}).text
except:
o["name-of-job"]=None

In the above image, you can see the location is stored under the div tag with the class JobCard_location__rCz3x.
try:
o["location"]=job.find("div",{"class":"JobCard_location__rCz3x"}).text
except:
o["location"]=None
The last thing left is the salary and this is the most important part for obvious reasons.

You can see in the above image that the salary information can be found under the div tag with the class css-3g3psg pr-xxsm.
try:
o["salary"]=job.find("div",{"class":"JobCard_salaryEstimate__arV5J"}).text
except:
o["salary"]=None
l.append(o)
o={}
In the end, we have pushed the object o inside the list l. Then we declared the object o empty.
Once you run and print the list l, you will get these results.
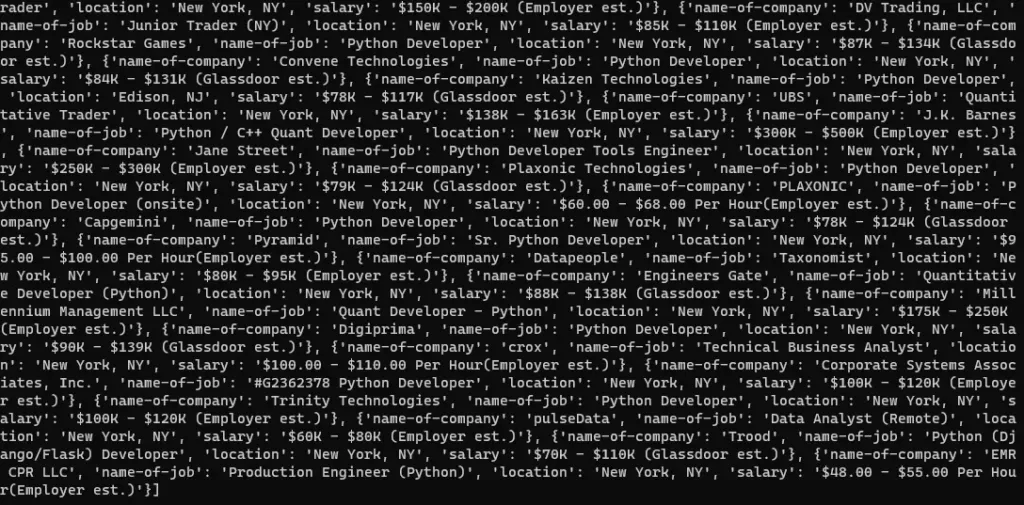
You will get the name of the company, the name of the job, the location, and the salary in a list.
Let’s save this data to a CSV file
For saving this data to a CSV file all we have to do is install pandas. This is just a two-line code and we will be able to create a CSV file and store this data in that file.
First, let’s install pandas.
pip install pandas
Then import this into our main script glassdoor.py file.
import pandas as pd
Now using DataFrame method we are going to convert our list l into a row and column format. Then using .to_csv() method we are going to convert a DataFrame to a CSV file.
df = pd.DataFrame(l)
df.to_csv('jobs.csv', index=False, encoding='utf-8')
You can add these two lines once your list l is ready with all the data. Once the program is executed you will get a CSV file by the name jobs.csv in your root folder.
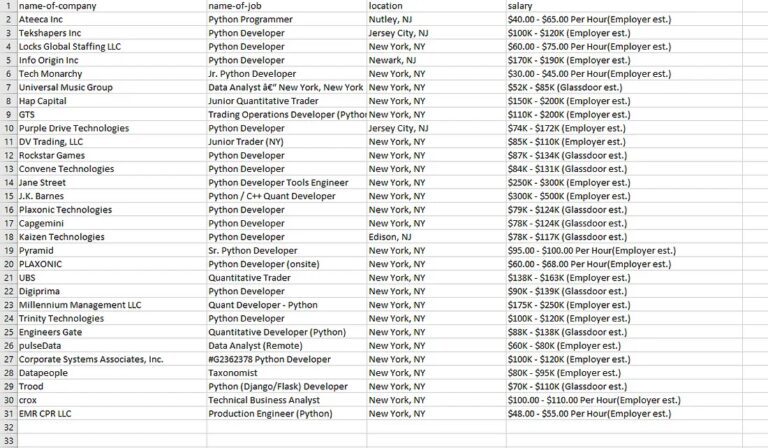
Complete Code
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import pandas as pd
PATH = 'C:\Program Files (x86)\chromedriver.exe'
l=list()
o={}
target_url = "https://www.glassdoor.com/Job/new-york-python-jobs-SRCH_IL.0,8_IC1132348_KO9,15.htm?clickSource=searchBox"
driver=webdriver.Chrome(PATH)
driver.get(target_url)
driver.maximize_window()
time.sleep(2)
resp = driver.page_source
driver.close()
soup=BeautifulSoup(resp,'html.parser')
allJobsContainer = soup.find("ul",{"class":"JobsList_jobsList__lqjTr"})
allJobs = allJobsContainer.find_all("li")
for job in allJobs:
try:
o["name-of-company"]=job.find("div",{"class":"EmployerProfile_profileContainer__VjVBX"}).text
except:
o["name-of-company"]=None
try:
o["name-of-job"]=job.find("a",{"class":"JobCard_jobTitle___7I6y"}).text
except:
o["name-of-job"]=None
try:
o["location"]=job.find("div",{"class":"JobCard_location__rCz3x"}).text
except:
o["location"]=None
try:
o["salary"]=job.find("div",{"class":"JobCard_salaryEstimate__arV5J"}).text
except:
o["salary"]=None
l.append(o)
o={}
print(l)
df = pd.DataFrame(l)
df.to_csv('jobs.csv', index=False, encoding='utf-8')
What if you want to scrape all the pages from Glassdoor?
If you want to scrape all the jobs from all the pages from Glassdoor then you will first notice URL patterns.
First-page https://www.glassdoor.com/Job/new-york-python-jobs-SRCH_IL.0,8_IC1132348_KO9,15.htm?includeNoSalaryJobs=true
Second Page — Second Page — https://www.glassdoor.com/Job/new-york-python-jobs-SRCH_IL.0,8_IC1132348_KO9,15_IP2.htm?includeNoSalaryJobs=true&pgc=AB4AAYEAHgAAAAAAAAAAAAAAAfkQ90AAUgEBAQgW%2Fr3vuIzCm5wwBSiI3WKjWOqbueSQvnI%2BGizAAsjV8NiAL80nAjkvw3vucgztbs4IIrkoqerQ462C14jLJVNRIV0ihlakU7p20hMXIG4AAA%3D%3D
Third Page-Third page-— https://www.glassdoor.com/Job/new-york-python-jobs-SRCH_IL.0,8_IC1132348_KO9,15_IP3.htm?includeNoSalaryJobs=true&pgc=AB4AAoEAPAAAAAAAAAAAAAAAAfkQ90AAdwEBAQtEzo8VunEQLF8uBoWr%2BRnCsnMFj0JNOLbRUXIkLkFAzjjZlKDW1axVwiTVV%2BbXo8%2BX471WNF8IEWPMdAwCPhbzQe1T1HHMEVPYFwQLM8h1NnGMDPcEwo7tpQ7XL65R7DMDR26n0NhBU7lFGCODAwxNTsJRAAA%3D
First, scroll and then click.
So, this is how you are going to scroll down the page of any Glassdoor page.
scrolling_element= driver.find_element_by_xpath("//*[@id='MainCol']")
driver.execute_script('arguments[0].scrollTop = arguments[0].scrollHeight', scrolling_element)
With .find_element_by_xpath() we are finding the column where all the jobs are stored. Once you scroll down this element you have to find the button and click it.
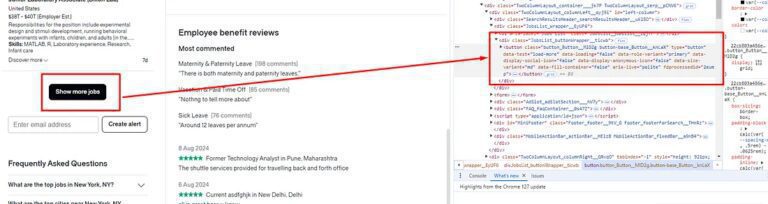
You have to find it using the same method of selenium .find_element_by_xpath(). And finally, you have to use .click() method to click it. This will take you to the next page.
time.sleep(3)
driver.find_element_by_xpath('//*[@id="left-column"]/div[2]/div/button').click()
time.sleep(3)
Now, you have to use it in a loop to extract all the jobs from the particular location. I know it is a bit lengthy process, but unfortunately, this is the only way to scrape Glassdoor.
But while scraping Glassdoor might limit your search and restrict your IP. In this case, you have to use a Web Scraping API. Let’s see how you can avoid getting blocked with a Web Scraper API like Scrapingdog.
Avoid Getting Blocked While Scraping Glassdoor at Scale with Scrapingdog
You can use Scrapingdog’s web scraping API to avoid getting blocked while scraping Glassdoor at scale.
You have to sign up from here for the free account to start using it. It will take just 10 seconds to get you started with Scrapingdog. In a free account, Scrapingdog offers 1000 free API calls.
Once you sign up, you will be redirected to your dashboard. The dashboard will look somewhat like this.
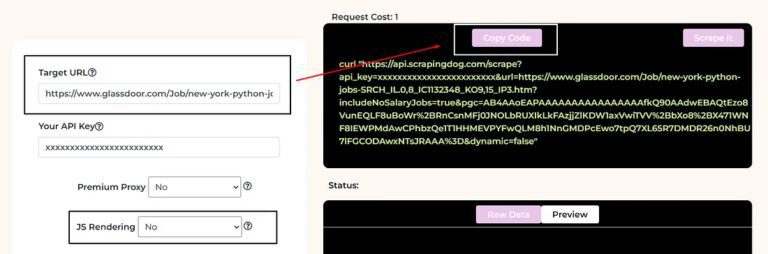
You have to use your own API key.
Now, you can paste your target Glassdoor target page link to the left and then select JS Rendering as No. After this click on Copy Code from the right. Now use this API in your Python script to scrape Glassdoor.
You will notice the code will remain somewhat the same as above. We just have to change one thing and that is our target URL.
from bs4 import BeautifulSoup
import pandas as pd
import requests
l=list()
o={}
target_url = "http://api.scrapingdog.com/scrape?dynamic=false&api_key=Your-API-Key&url=https://www.glassdoor.co.in/Job/new-york-python-jobs-SRCH_IL.0,8_IC1132348_KO9,15.htm?clickSource=searchBox"
resp=requests.get(target_url)
soup=BeautifulSoup(resp.text,'html.parser')
allJobsContainer = soup.find("ul",{"class":"JobsList_jobsList__lqjTr"})
allJobs = allJobsContainer.find_all("li")
for job in allJobs:
try:
o["name-of-company"]=job.find("div",{"class":"EmployerProfile_profileContainer__VjVBX"}).text
except:
o["name-of-company"]=None
try:
o["name-of-job"]=job.find("a",{"class":"JobCard_jobTitle___7I6y"}).text
except:
o["name-of-job"]=None
try:
o["location"]=job.find("div",{"class":"JobCard_location__rCz3x"}).text
except:
o["location"]=None
try:
o["salary"]=job.find("div",{"class":"JobCard_salaryEstimate__arV5J"}).text
except:
o["salary"]=None
l.append(o)
o={}
print(l)
df = pd.DataFrame(l)
df.to_csv('jobs.csv', index=False, encoding='utf-8')
As you can see we have replaced the target URL of Glassdoor with the API URL of Scrapingdog and we no longer require Selenium to scrape Glassdoor. You have to use your own API Key in order to successfully run this script.
With this script, you will be able to scrape Glassdoor with a lightning-fast speed that too without getting blocked.
Conclusion
In this post, we learned to scrape Glassdoor and store the data in a CSV file. Such data can also help companies refine their hiring strategy and make better talent decisions. We later discovered a way to scrape all the pages for any given location. Now, you can create your logic and scrape Glassdoor but this was a pretty straightforward way to scrape it.
I have more tutorials on Scraping Indeed Job Portal with Python, Scraping LinkedIn Jobs using Python & Scraping Google Jobs using Nodejs. You can check them out too!!
Of course, I would recommend a Web Scraping API if you are planning to scrape it at scale. With a normal script without proxy rotation, you will be blocked in no time and your data pipeline will be stuck. For scraping millions of such postings you can always use Scrapingdog.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on your social media.