
TL;DR
- Two paths: Python +
BeautifulSoup, or Scrapingdog’s Google Jobs API for scale. - Python demo: set a
User-Agent, parse job cards, and extract title / company / location / source; full code shown. - API route: get an API key, query jobs, receive clean JSON; extra filters available in docs.
- Use cases: job boards, hiring-trend and skills analysis.
Google Jobs is a job aggregator that collects data from multiple job listing platforms. If you’re building a job board, scraping Google Jobs should be a priority.
Other use cases for scraping include market research, which can help track hiring trends, monitor demand for specific skills, and analyze job availability across industries.
In this tutorial, we’ll scrape Google Jobs using Python and explore techniques to avoid getting blocked when the platform detects scraping.
Let’s get started!
Methods For Scraping Google Jobs
We will cover two methods for scraping Google Jobs:
- Using Python and Beautiful Soup
- Using Scrapingdog’s Google Jobs API
Let’s start by creating our own basic scraper for Google Jobs using Python.
Scraping Google Jobs Using Python
In this section, we will create a simple Python script to scrape the first page of Google Jobs or retrieve a list of the first ten job postings, including the title, company, location, and other details.
Process
Suppose you’re a budding entrepreneur looking to understand the job market for data engineers. You want to gather insights about job availability, top employers, employer of record costs, and the skills in demand. While looking for options, you found a great option Google Jobs, which aggregates job postings from multiple sources and displays them in search results.
For example, searching for “Data Engineer Jobs in San Francisco” provides a wealth of information, including job titles, recruiters, qualifications, and locations — all in one place.
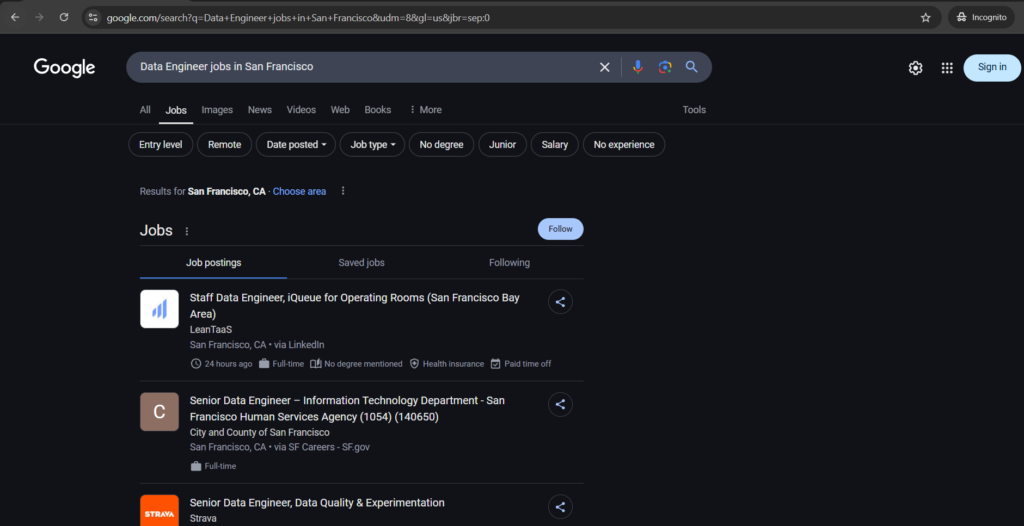
This is where Google Jobs becomes a valuable source of information. By extracting this data, we can create job boards, analyze job trends, and build a career insights portal for our audience.
Since this tutorial is in Python, I assume you have already set up Python on your desktop. Once you’re ready, import the following libraries into your project file.
import json
import requests
from bs4 import BeautifulSoup
JSON is a pre-built library. To install Requests and BeautifulSoup, run the following commands.
pip install requests
pip install beautifulsoup4
After that, we will establish a connection between the Google Jobs URL and the Requests library.
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36"
}
response = requests.get(
"https://www.google.com/search?q=jobs+in+san+francisco&udm=8&gl=us", headers=headers
)
soup = BeautifulSoup(response.content, "html.parser")
jobs_results = []
In the above code, we set up a custom HTTP header, User-Agent, to make the request appear as if it is coming from a real browser. Then, using the Requests library, we established an HTTP GET connection to the Google Jobs URL. Finally, we created a BeautifulSoup (BS4) object to parse the HTML and extract specific elements.
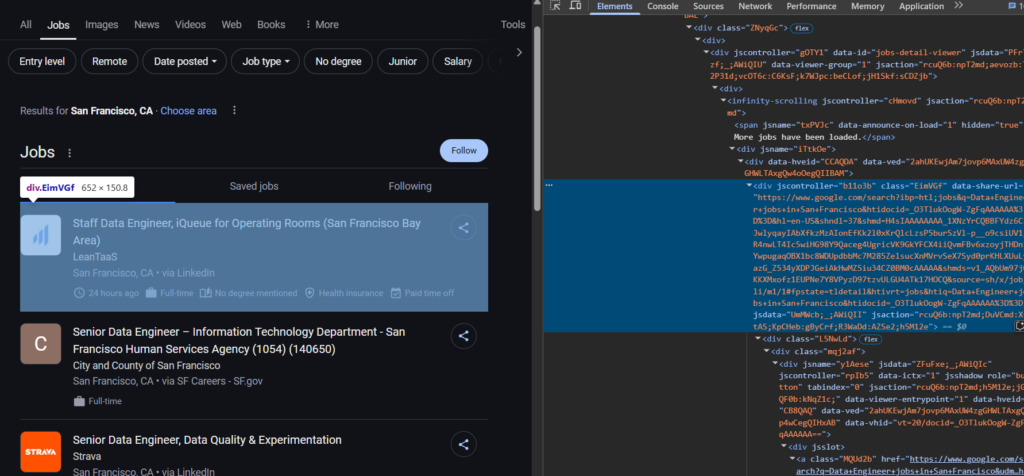
If you inspect the HTML, you will find that each job is inside a <div> tag with the class EimVGf. So, we need to loop through these <div> tags to extract the job details we are looking for.
for job_element in soup.select("div.EimVGf"):
job_data = {
}
jobs_results.append(job_data)
Scraping Jobs Title
Let’s take a look at how we can extract the title part.
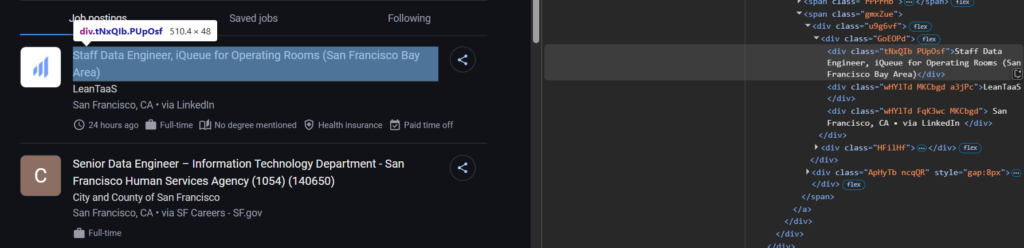
Looking inside the <div> with the class EimVGf, we found that the title is inside a <div> tag with the class tNxQIb PUpOsf.
Now, we will add this class inside our for-loop block to extract the title.
"title": job_element.select_one("div.tNxQIb.PUpOsf").text if job_element.select_one("div.tNxQIb.PUpOsf") else None,
Scraping Jobs Company
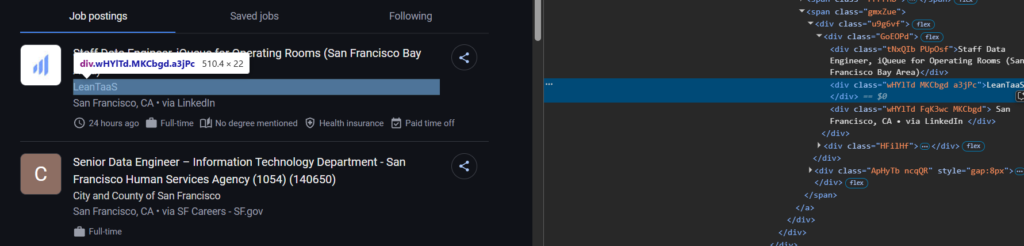
You can find the company name inside the <div> tag with the class wHYlTd MKCbgd.
Let’s add this as well.
"company": job_element.select_one("div.a3jPc").text if job_element.select_one("div.a3jPc") else None,
Scraping Job Location
Just beneath the company name, you’ll find the company location. Add the code below to retrieve the location.
"location": job_element.select_one(".FqK3wc").text.split("•")[0] if job_element.select_one(".FqK3wc") else None,
Scraping Job Source
Getting the job source is easy. You can find it right next to the job location.
"source": job_element.select_one(".FqK3wc").text.split("•")[1] if job_element.select_one(".FqK3wc") and "•" in job_element.select_one(".FqK3wc").text else None
In the last part, we will scrape the extensions.
Scraping Job Extensions

The job extensions can be found inside the div tag with the class K3eUK. Add this to the loop as well.
extensions = [ext.text for ext in job_element.select(".K3eUK")] if job_element.select(".K3eUK") else []
if extensions:
job_data["extensions"] = extensions
jobs_results.append(job_data)
Complete Code
So, this is how job data can be extracted. If you want to customize the code to retrieve more data, feel free to do so. For this tutorial, the code will look like this:
import requests
from bs4 import BeautifulSoup
# Define the target URL
url = "https://www.google.com/search?q=jobs+in+san+francisco&udm=8&gl=us"
# Set the headers to mimic a real browser
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}
# Send an HTTP GET request
response = requests.get(url, headers=headers)
# Parse the HTML response
soup = BeautifulSoup(response.text, "html.parser")
# Initialize an empty list for job results
jobs_results = []
# Find all job listing elements
for job_element in soup.select("div.EimVGf"):
job_data = {
"title": job_element.select_one("div.tNxQIb.PUpOsf").text if job_element.select_one("div.tNxQIb.PUpOsf") else None,
"company": job_element.select_one("div.a3jPc").text if job_element.select_one("div.a3jPc") else None,
"location": job_element.select_one(".FqK3wc").text.split("•")[0] if job_element.select_one(".FqK3wc") else None,
"source": job_element.select_one(".FqK3wc").text.split("•")[1] if job_element.select_one(".FqK3wc") and "•" in job_element.select_one(".FqK3wc").text else None
}
# Check for job extensions (additional info)
extensions = [ext.text for ext in job_element.select(".K3eUK")] if job_element.select(".K3eUK") else []
if extensions:
job_data["extensions"] = extensions
jobs_results.append(job_data)
# Print the scraped job results
print(jobs_results)
Run this code in the terminal and check the results.

Scraping Google Jobs With Scrapingdog
Whether you are creating a job board, automating recruitment, or analyzing new trends in the job market, you need to collect data on a large scale. Additionally, converting raw data into a structured format can be challenging. To scrape data consistently, the scraper must be maintained regularly; otherwise, there is a high chance your data pipeline may break over time.
This is why a scalable web scraping API is required to deal with any kind of blockage in the data pipeline. In this section, we will use Scrapingdog’s Google Jobs API with Python to extract job details.
Setting up a Scrapingdog Account
To use the Scrapingdog API, you need an API Key, which grants access to the API. Visit the Scrapingdog website and click on the “Get Free Trial” button to obtain your API credentials.
After activating your account, you will be redirected to the dashboard, where you can find your API KEY.
Let's start scraping!!
Now that we have set up the account, we can begin the scraping process. Using Scrapingdog’s Google Jobs API, we will target “Data Engineer Jobs in San Francisco” and extract details about the listed jobs.
payload = {'api_key': 'APIKEY', 'query':'Data+Engineer+jobs+in+San+Francisco'}
resp = requests.get('https://api.scrapingdog.com/google_jobs', params=payload)
data = resp.json()
print(data["jobs_results"])
If you wish to add more filters and parameters to the API request, you can refer to this documentation to get started.
Run this code in your project terminal and you will get all the details about data engineer jobs in San Francisco.
[
{
"title": "Principal Data Engineer",
"company_name": "Atlassian",
"location": "San Francisco, CA",
"via": "LinkedIn",
"share_link": "https://www.google.com/search?ibp=htl;jobs&q=Data+Engineer+jobs+in+San+Francisco&htidocid=9Xb3S06YXXeR9RIgAAAAAA%3D%3D&hl=en-US&shndl=37&shmd=H4sIAAAAAAAA_xXNPQoCMRBAYWz3CBYytWgigo1Wi39gJXiAZRKGbCTOhMwUewnv7Nq8r3zdd9G5Z8scc8UCFzSEK6fMRA228JAAStjiCMJwF0mFlqfRrOrRe9Xikhpaji7KxwtTkMm_Jeg_g47YqBY0GvaH3eQqp_Wqt4KqGRkyw2vm1nC-a5QNnPsfdyoACZAAAAA&shmds=v1_AUFQtON8pYGasi24HNXVKAtRiJFovn9liHF3Q7Q7Xz6oN4_MmA&shem=jblt,jbolt&source=sh/x/job/uv/m5/1#fpstate=tldetail&htivrt=jobs&htidocid=9Xb3S06YXXeR9RIgAAAAAA%3D%3D&htiq=Data+Engineer+jobs+in+San+Francisco",
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTTIj7S_FsdbFgxCTkMsNTS6PS4BiU-piJi34mp&s=0",
"detected_extensions": {
"health_insurance": true
},
"description": "Overview\n\nWorking at Atlassian\n\nAtlassians can choose where they work – whether in an office, from home, or a combination of the two. That way, Atlassians have more control over supporting their family, personal goals, and other priorities. We can hire people in any country where we have a legal entity. Interviews and onboarding are conducted virtually, a part of being a distributed-first company.\n\nAtlassian is looking for a Principal Data Engineer to join our Data Engineering Team and play a tech lead & architect role to build world-class data solutions and applications that power crucial business decisions throughout the organization. We are looking for an open-minded, structured thinker who is passionate about building systems at scale. You will enable a world-class engineering practice, drive the approach with which we use data, develop backend systems and data models to serve the needs of insights and play an active role in building Atlassian's data-driven culture.\n\nResponsibilities\n• Own the technical evolution of the data engineering capabilities and be responsible for ensuring solutions are being delivered incrementally, meeting outcomes, and promptly escalating risks and issues\n• Establish a deep understanding of how things work in data engineering, use this to direct and coordinate the technical aspects of work across data engineering, and systematically improve productivity across the teams.\n• Maintain a high bar for operational data quality and proactively address performance, scale, complexity and security considerations.\n• Drive complex decisions that can impact the work in data engineering. Set the technical direction and balance customer and business needs with long-term maintainability & scale.\n• Understand and define the problem space, and architect solutions. Coordinate a team of engineers towards implementing them, unblocking them along the way if necessary.\n• Lead a team of data engineers through mentoring and coaching, work closely with the engineering manager, and provide consistent feedback to help them manage and grow the team\n• Work with close counterparts in other departments as part of a multi-functional team, and build this culture in your team.\n\nQualifications\n\nOn your first day, we'll expect you to have:\n• You have 12+ years of experience in a Data Engineer role as an individual contributor.\n• You have at least 2 years of experience as a tech lead for a Data Engineering team.\n• You are an engineer with a track record of driving and delivering large (multi-person or multi-team) and complex efforts.\n• You are a great communicator and maintain many of the essential cross-team and cross-functional relationships necessary for the team's success.\n• Experience with building streaming pipelines with a micro-services architecture for low-latency analytics.\n• Experience working with varied forms of data infrastructure, including relational databases (e.g. SQL), Spark, and column stores (e.g. Redshift)\n• Experience building scalable data pipelines using Spark using Airflow scheduler/executor framework or similar scheduling tools.\n• Experience working in a technical environment with the latest technologies like AWS data services (Redshift, Athena, EMR) or similar Apache projects (Spark, Flink, Hive, or Kafka).\n• Understanding of Data Engineering tools/frameworks and standards to improve the productivity and quality of output for Data Engineers across the team.\n• Industry experience working with large-scale, high-performance data processing systems (batch and streaming) with a \"Streaming First\" mindset to drive Atlassian's business growth and improve the product experience.\n\nWe'd Be Super Excited If You Have\n• Built and designed Kappa or Lambda architecture data platforms and services.\n• Experience implementing Master Data Management (MDM) solutions.\n• Built pipelines using Databricks and is well-versed with their APIs.\n\nCompensation\n\nAt Atlassian, we strive to design equitable, explainable, and competitive compensation programs. To support this goal, the baseline of our range is higher than that of the typical market range, but in turn we expect to hire most candidates near this baseline. Base pay within the range is ultimately determined by a candidate's skills, expertise, or experience. In the United States, we have three geographic pay zones. For this role, our current base pay ranges for new hires in each zone are:\n\nZone A: $203,300 - $271,100\n\nZone B: $183,000 - $244,000\n\nZone C: $168,700 - $225,000\n\nThis role may also be eligible for benefits, bonuses, commissions, and equity.\n\nPlease visit go.atlassian.com/payzones for more information on which locations are included in each of our geographic pay zones. However, please confirm the zone for your specific location with your recruiter.\n\nOur Perks & Benefits\n\nAtlassian offers a variety of perks and benefits to support you, your family and to help you engage with your local community. Our offerings include health coverage, paid volunteer days, wellness resources, and so much more. Visit go.atlassian.com/perksandbenefits to learn more.\n\nAbout Atlassian\n\nAt Atlassian, we're motivated by a common goal: to unleash the potential of every team. Our software products help teams all over the planet and our solutions are designed for all types of work. Team collaboration through our tools makes what may be impossible alone, possible together.\n\nWe believe that the unique contributions of all Atlassians create our success. To ensure that our products and culture continue to incorporate everyone's perspectives and experience, we never discriminate based on race, religion, national origin, gender identity or expression, sexual orientation, age, or marital, veteran, or disability status. All your information will be kept confidential according to EEO guidelines.\n\nTo provide you the best experience, we can support with accommodations or adjustments at any stage of the recruitment process. Simply inform our Recruitment team during your conversation with them.\n\nTo learn more about our culture and hiring process, visit go.atlassian.com/crh .",
"job_highlights": [
{
"title":"Qualifications",
"items": [
"We are looking for an open-minded, structured thinker who is passionate about building systems at scale",
...... and so on
That’s how you can easily scrape Google Jobs using Scrapingdog’s API without extra effort, wasted time, or additional resources.
Key Takeaways:
The guide explains how to programmatically scrape Google Jobs listings using Python.
It shows how to send requests to Google Jobs search endpoints and retrieve structured job data.
You learn how to parse key fields such as job title, company, location, posting date, and job description.
The tutorial outlines organizing and storing the extracted job data for analysis or reporting.
Automating Google Jobs scraping helps with job market research, competitor hiring insights, and job trend tracking.
Conclusion
In a nutshell, Google Jobs is a vast repository of job postings from various trusted sources, helping users identify industry trends and stay informed about the latest market demands worldwide.
In this tutorial, we learned how to scrape Google Jobs results using Python.
I hope you enjoyed this article! If you did, please share it on social media.
Thanks for reading! 👋


