TL;DR
- Google News data (title, source, date, snippet, link) can be scraped from the Google News search tab or
news.google.com. - A basic scraper can be built in Python using requests and BeautifulSoup to extract news details.
- The collected data can be stored and exported to
CSVusing pandas. - DIY scraping works for small projects but often gets blocked by Google due to CAPTCHAs, IP blocks, and changing HTML classes.
- For large-scale scraping, APIs like Scrapingdog Google News API return structured JSON and handle proxies and CAPTCHAs automatically.
When people talk about scraping Google News, they’re usually referring to one of two things: the news tab in regular Google Search (google.com/search?tbm=nws) or the dedicated news aggregator at news.google.com. These are two completely different pages with different structures, different data, and different scraping challenges and most tutorials only cover one of them.
In this guide, we’ll show you how to scrape both using Python and Scrapingdog’s Google News API, so you get structured data like headlines, sources, publication times, and article links, regardless of which source you need.
What are Google News results?
Google News results are news articles that Google surfaces from multiple publishers across the web based on a user’s query, interests, and freshness of content. Unlike regular Google Search results, which mix blogs, product pages, and websites, Google News focuses specifically on journalistic and news-style content.
When you search a keyword in Google News, you typically see:
- Headlines from multiple publishers covering the same story
- Source names (BBC, Reuters, niche blogs, local media, etc.)
- Publication time (minutes ago, hours ago, days ago)
- Article snippets summarizing the story
- Images or thumbnails tied to the article
- Topic clusters, where related coverage is grouped together
Why Scrape Google News Results?
Media Monitoring — Track brand or competitor mentions across thousands of news sources in real time.
Sentiment Analysis — Feed headlines into NLP models to measure how media coverage shifts over time.
Competitive Intelligence — See which stories about your competitors are gaining traction in the press.
Market Research — Correlate breaking news with stock movements, industry trends, or consumer behavior.
AI Training Data — Google News surfaces authoritative, publisher-verified content ideal for LLM training datasets.
Academic Research — Analyze how stories evolve across outlets, detect misinformation, or study media bias at scale.
Methods For Scraping Google News
We will be discussing two ways of extracting news from Google:
- Using Python and BeautifulSoup
- Using Scrapingdog’s Google News API
Let’s start by creating a basic scraper using Python and BS4.
Method 1: Scrape Google News with Python
In this section, we’ll build a Python script that extracts up to 10 Google News results, including the title, snippet, link, source, and publication date, and finally saves them to a CSV file.
Prerequisites
Make sure you have Python 3.7+ installed along with the following libraries:
pip install requests beautifulsoup4 pandas
Once installed, create a new Python file and import them at the top:
import requests
from bs4 import BeautifulSoup
import pandas
Next, define the core scraping function. This function sends a request to Google News with a spoofed User-Agent header to avoid being immediately blocked, then parses the returned HTML with BeautifulSoup.
def getNewsData(query="amazon", country="us"):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36"
}
url = f"https://www.google.com/search?q={query}&gl={country}&tbm=nws&num=10"
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
news_results = []
⚠️ A static User-Agent works for testing, but Google will block repeated requests at scale. For production use, rotate User-Agents or route requests through a proxy.
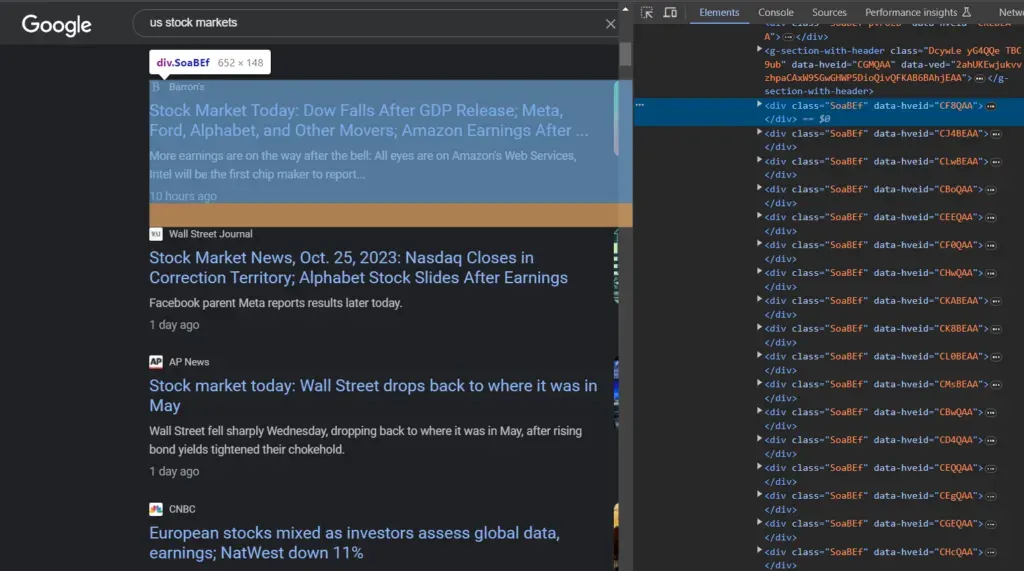
Now we need to identify the right HTML elements to target. If you open Chrome DevTools (right-click → Inspect) on a Google News results page, you’ll find that each individual news card is wrapped in a div with the class SoaBEf. We loop over all of them to extract data from each result:
for el in soup.select("div.SoaBEf"):
news_results.append(
{
}
)
print(json.dumps(news_results, indent=2))
getNewsData()
This loop iterates over every news card on the page and appends an empty dictionary for each one. We’ll fill in the actual fields title, source, link, snippet, and date in the next steps.
Scraping News Title
Let’s find the headline of the news article by inspecting it.

As you can see in the above image, the title is under the div container with the class MBeuO.
Add the following code in the append block to get the news title.
"title": el.select_one("div.MBeuO").get_text(),
Scraping News Source and Link
Similarly, we can extract the News source and link from the HTML.
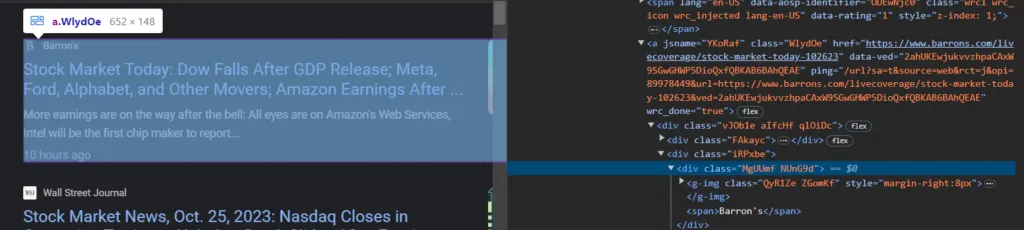
Each news card contains an anchor tag whose href attribute holds the article URL, and the publisher name sits inside a span within .NUnG9d:
"source": el.select_one(".NUnG9d span").get_text(),
"link": el.find("a")["href"],
Scraping News Description and Date
The article snippet is inside .GI74Re and the publication date is inside .LfVVr:

"snippet": el.select_one(".GI74Re").get_text(),
"date": el.select_one(".LfVVr").get_text(),
Complete Code
Here’s the complete scraper putting it all together:
import json
import requests
from bs4 import BeautifulSoup
def getNewsData(query="us+stock+markets", country="us"):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36"
}
url = f"https://www.google.com/search?q={query}&gl={country}&tbm=nws&num=100"
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
news_results = []
for el in soup.select("div.SoaBEf"):
news_results.append({
"link": el.find("a")["href"],
"title": el.select_one("div.MBeuO").get_text(),
"snippet": el.select_one(".GI74Re").get_text(),
"date": el.select_one(".LfVVr").get_text(),
"source": el.select_one(".NUnG9d span").get_text()
})
print(json.dumps(news_results, indent=2))
getNewsData()
Run this in your terminal and you should see a JSON array of news results. Here’s what the output looks like:
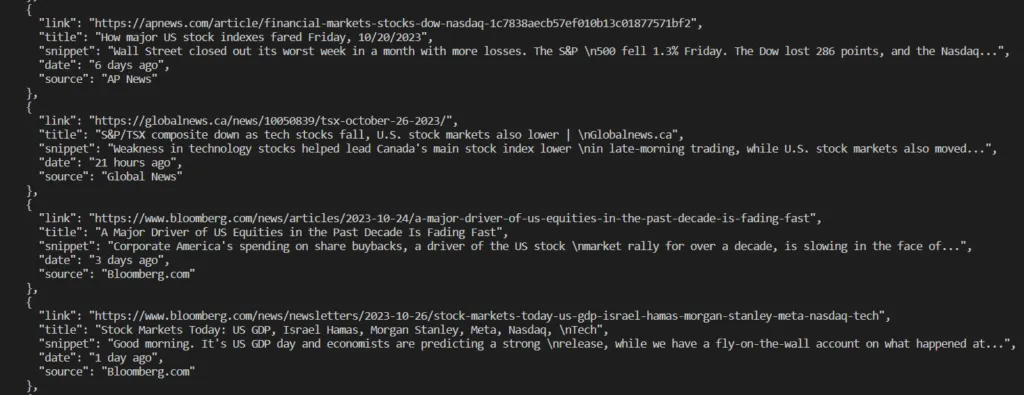
Saving Data to CSV
Instead of printing to the terminal, let’s save the results directly to a CSV file. Add pandas to your imports at the top:
import pandas
Then, you can replace the print line with the following code.
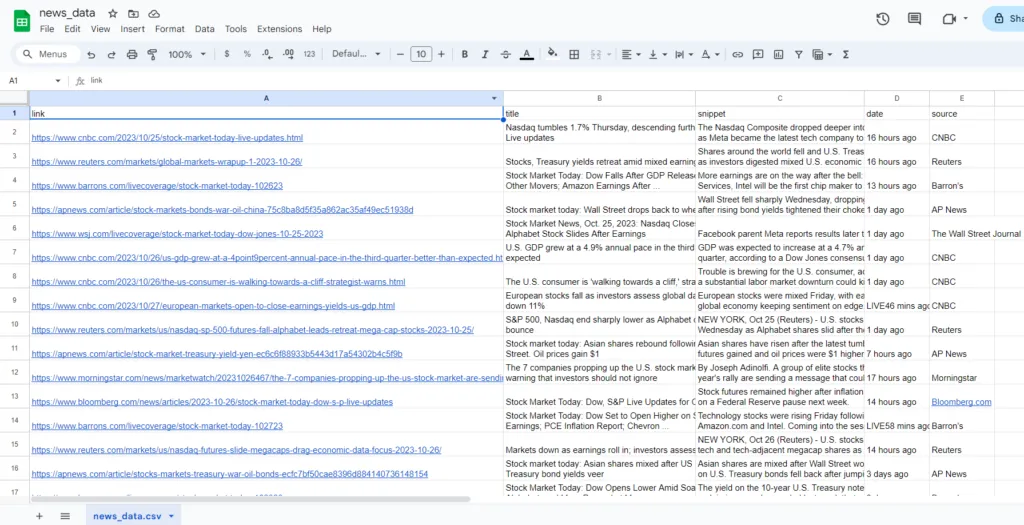
df = pd.DataFrame(news_results)
df.to_csv("news_data.csv", index=False)
print("Data saved to news_data.csv")
Running the script now will create a news_data.csv file in your project directory with one row per news result.
Hurray!!!
Method 2: Scraping Google News Using Scrapingdog’s Google News API
The bare requests + beautifulSoup approach works well for testing and small runs, but it has a hard ceiling; Google will block repeated requests, class names change without warning, and maintaining the scraper becomes a job in itself.
Scrapingdog’s Google News API handles all of that behind the scenes: proxy rotation, CAPTCHA bypassing, and header management are taken care of automatically. Instead of raw HTML, you get back clean, structured JSON that’s ready to use without any parsing.
This approach makes sense when you need:
- More than a few hundred requests per day
- Reliable, uninterrupted data collection
- Consistent JSON output without worrying about Google’s layout changes
To get started, you’ll need a Scrapingdog API key.
Getting API Credentials From Scrapingdog’s Google News API
Head to Scrapingdog’s registration page and create a free account. You’ll get 1,000 credits to test with, no credit card required.
Once registered, your API key will be waiting on the dashboard. Copy it somewhere handy as you’ll need it in the next step.
Making Your First API Request
Since the API returns structured JSON, you only need the requests library , no BeautifulSoup required:
import requests
payload = {
'api_key': 'YOUR_API_KEY',
'query': 'stock market',
'country': 'us'
}
resp = requests.get('https://api.scrapingdog.com/google_news', params=payload)
data = resp.json()
print(data["news_results"])
Here’s what a single result looks like:
{
"title": "Dow tumbles 300 points as Fed decision looms",
"snippet": "Sticky inflation data and poor earnings sent stock prices lower.",
"source": "CNBC",
"lastUpdated": "8 minutes ago",
"url": "https://www.cnbc.com/2024/04/29/stock-market-today-live-updates.html"
}
Each result contains five fields — title, snippet, source, lastUpdated, and urlwhich map directly to what you see on the Google News page. The full list of supported parameters (language, country, date range, topic filtering) is covered in the API documentation.
Scraping Multiple Pages
By default the API returns 10 results per request. To collect more, use the page parameter to paginate through results:
import requests
api_key = "your-api-key"
url = "https://api.scrapingdog.com/google_news"
all_results = []
for page in range(0, 20):
params = {
"api_key": api_key,
"query": "elon musk",
"country": "us",
"page": page
}
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
all_results.extend(data.get("news_results", []))
else:
print(f"Request failed on page {page} with status: {response.status_code}")
break
print(f"Total results fetched: {len(all_results)}")
This loops through 20 pages for the query “Elon Musk”, appending each page’s results to all_results. Adjust range(0, 20) to control how many pages you collect.
How to scrape the dedicated Google news portal
If you want to scrape data from news.google.com using Scrapingdog, then you have to use Google news Scraper API.
import requests
api_key = "your-api-key"
url = "https://api.scrapingdog.com/google_news/v2"
params = {
"api_key": api_key,
"query": "elon musk",
"country": "us"
}
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
print(data)
else:
print(f"Request failed with status code: {response.status_code}")
Once you run this code, you will get this data:
{
"menu_links": [
{
"title": "U.S.",
"topic_token": "CAAqIggKIhxDQkFTRHdvSkwyMHZNRGxqTjNjd0VnSmxiaWdBUAE",
"scrapingdog_link": "https://api.scrapingdog.com/google_news/v2?api_key=670d12181fecbac22c66d410&topic_token=CAAqIggKIhxDQkFTRHdvSkwyMHZNRGxqTjNjd0VnSmxiaWdBUAE"
},
{
"title": "World",
"topic_token": "CAAqJggKIiBDQkFTRWdvSUwyMHZNRGx1YlY4U0FtVnVHZ0pWVXlnQVAB",
"scrapingdog_link": "https://api.scrapingdog.com/google_news/v2?api_key=670d12181fecbac22c66d410&topic_token=CAAqJggKIiBDQkFTRWdvSUwyMHZNRGx1YlY4U0FtVnVHZ0pWVXlnQVAB"
},
{
"title": "Local",
"topic_token": "CAAqHAgKIhZDQklTQ2pvSWJHOWpZV3hmZGpJb0FBUAE",
"scrapingdog_link": "https://api.scrapingdog.com/google_news/v2?api_key=670d12181fecbac22c66d410&topic_token=CAAqHAgKIhZDQklTQ2pvSWJHOWpZV3hmZGpJb0FBUAE"
}
],
"news_results": [
{
"title": "Elon Musk's xAI wins permit to build power plant in Mississippi despite pollution concerns",
"link": "https://www.cnbc.com/2026/03/10/elon-musk-xai-permit-for-mississippi-plant-despite-pollution-concerns.html",
"thumbnail": "https://image.cnbcfm.com/api/v1/image/108170649-1752223567421-gettyimages-2199701064-HL_VFEURAY_2670140.jpeg?v=1773166328&w=1600&h=900",
"source": "CNBC",
"icon": "https://encrypted-tbn0.gstatic.com/faviconV2?url=https://www.cnbc.com&client=NEWS_360&size=96&type=FAVICON&fallback_opts=TYPE,SIZE,URL",
"authors": [],
"date": "2026-03-10T19:04:46.000Z",
"rank": 1
},
{
"title": "Forbes 40th Annual World’s Billionaires List: Elon Musk Is World’s Richest Person Ever Recorded",
"link": "https://www.forbes.com/sites/pr/2026/03/10/forbes-40th-annual-worlds-billionaires-list-elon-musk-is-worlds-richest-person-ever-recorded/",
"thumbnail": "https://imageio.forbes.com/specials-images/imageserve/69af8af502d5a48e99a841a0/social-pr-16x9-billionaires-2026-illustration-by-neil-jamieson-for-forbes/0x0.jpg?format=jpg&width=480",
"source": "Forbes",
"icon": "https://encrypted-tbn2.gstatic.com/faviconV2?url=https://www.forbes.com&client=NEWS_360&size=96&type=FAVICON&fallback_opts=TYPE,SIZE,URL",
"authors": [],
"date": "2026-03-10T13:00:00.000Z",
"rank": 2
}
],
"related_topics": [
{
"title": "Elon Musk",
"topic_token": "CAAqIggKIhxDQkFTRHdvSkwyMHZNRE51ZW1ZeEVnSmxiaWdBUAE",
"scrapingdog_link": "https://api.scrapingdog.com/google_news/v2?api_key=670d12181fecbac22c66d410&topic_token=CAAqIggKIhxDQkFTRHdvSkwyMHZNRE51ZW1ZeEVnSmxiaWdBUAE"
},
{
"title": "Spend Elon Musk' Money",
"topic_token": "CAAqKAgKIiJDQkFTRXdvTkwyY3ZNVEZ0WW10dE4ySXplaElDWlc0b0FBUAE",
"scrapingdog_link": "https://api.scrapingdog.com/google_news/v2?api_key=670d12181fecbac22c66d410&topic_token=CAAqKAgKIiJDQkFTRXdvTkwyY3ZNVEZ0WW10dE4ySXplaElDWlc0b0FBUAE"
}
]
}
Key Takeaways:
- Google News exposes headlines, snippets, sources, publication dates, and URLs. All is scrapable for brand monitoring, market research, and competitive analysis.
- A
requests+BeautifulSoupsetup is sufficient for learning and small-scale runs. - DIY scrapers are fragile; Google’s class names change, CAPTCHAs trigger quickly, and IP blocks follow at scale.
- Scaling the DIY approach means managing proxies, header rotation, retries, and pagination yourself, which adds significant engineering overhead.
- Scrapingdog’s Google News API handles all of that automatically, returning clean JSON with no HTML parsing required.
Conclusion
This article discussed two ways of scraping news from Google using Python. Data collectors looking to have an independent scraper and want to maintain a certain amount of flexibility while scraping data can use Python as an alternative to interacting with the web page.
Otherwise, Google News API is a simple solution that can quickly extract and clean the raw data obtained from the web page and present it in structured JSON format.
We also learned how this extracted data can be used for various purposes, including brand monitoring and competitor analysis.
If you like this article please do share it on your social media accounts. If you have any questions, please contact me at [email protected].
Additional Resources
- Scrape Bing Search Results using Python (A Detailed Tutorial)
- Scrape Google Short Videos using Python
- 10 Best Google Search Scraper APIs
- Web Scraping Google Maps using Python
- Web Scraping Google Search Results using Python
- Web Scraping Google Images using Python
- Scrape Google Finance using Python
- Web Scraping Google Scholar using Python
- How To Scrape Google Shopping using Python
- How To Scrape Google Patents
- Web Scraping Google Jobs using Nodejs
- Building A Stock Automation To Predict The Daily Stock Analysis Using News API
- How to scrape Google AI Overviews using Python
- How to Scrape Google AI Mode Using Python


