TL;DR
- Python how-to:
requests+BeautifulSoupto scrape Google Patents search results. - Extract title, patent link, metadata, dates, snippet; return a JSON list.
- Good for building patent datasets for research / market analysis.
- Wrap-up suggests Scrapingdog’s Google Patents API for ready JSON.
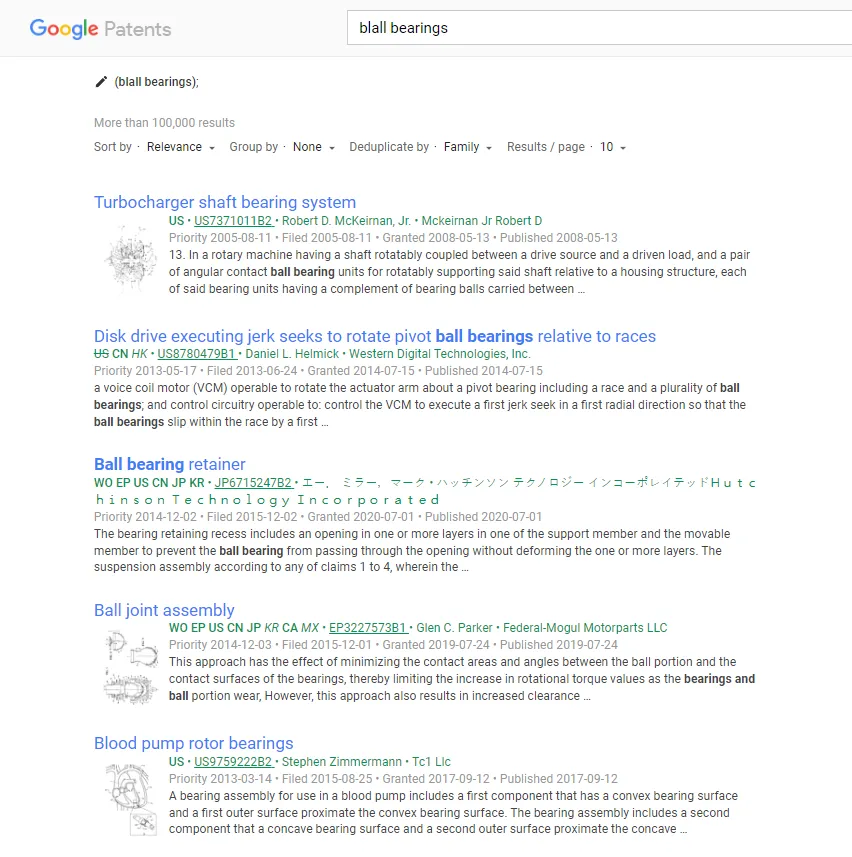
Google Patents contains a vast database of patents granted worldwide and is used to explore them for a particular query. It has a vast collection of documents and consists of patents issued by the United States Patent and Trademark Office, the European Patent Office (EPO), and many other patent offices globally.
In this article, we will try to access and scrape Google Patents, a valuable resource for accessing patent information from the internet.
Let’s Start Scraping Google Patents Using Python
We’ll mainly focus on scraping organic results from Google Patents.
Let’s get started by installing the required libraries which we will use further in this tutorial.
pip install requests
pip install beautifulsoup4
- Requests — This allows you to send HTTP requests very easily.
- Beautiful Soup — For parsing the HTML data.
Next, we will import these libraries into our program file.
import json
import requests
from bs4 import BeautifulSoup
Then, we will define our target URL to make a get request with the driver and wait for two seconds till the page completely loads.
url = "https://patents.google.com/?q=(ball+bearings)&oq=ball+bearings"
response = requests.get(url)
If the response status is 200, we will create a Beautiful Soup instance to parse the extracted HTML data.
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
Then, we will inspect the target web page to find the respective tags of the required data points.
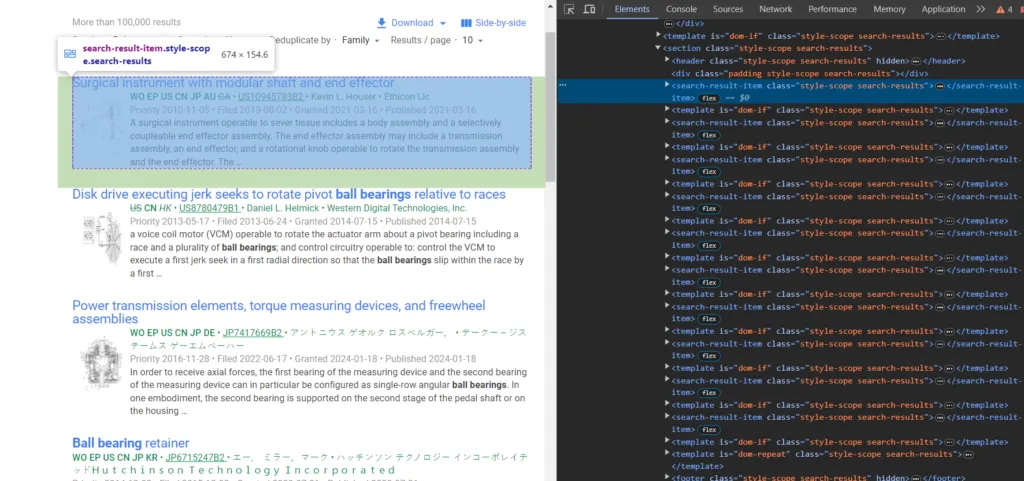
As you can see, every patent result is under the tag search-result-item. We will use this tag as a reference to find other elements.
patent_results = []
for el in soup.select('search-result-item'):
Scraping Patent Title

So, the title is present under the h3 tag. Add this title inside the for loop block.
title = el.select_one('h3').get_text().strip()
Scraping Patent Link
In the above image, we can see that the anchor link is under the tag a with the class state-modifier.
Let us study this link before adding it to our code.
https://patents.google.com/patent/US10945783B2/en?q=(ball+bearings)&oq=ball+bearings&peid=61296253f5d80%3Af%3A51b23c37
Remove the noisy part, you will get this as the link.
https://patents.google.com/patent/US10945783B2/
The unique entity in this URL is the patent ID which is US10945783B2. So, we need a patent ID to create a link.
If you inspect the title again, you will find that the h3 header is inside the tag state-modifier which consists of an attribute data-result that has the patent ID.

We will add this to our code to create a link.
link = "https://patents.google.com/" + el.select_one("state-modifier")['data-result']
Scraping Metadata and Dates
Metadata is additional information on the Google Patents page for categorization, indexing, and search purposes. You can notice it below the title of the organic patent result.
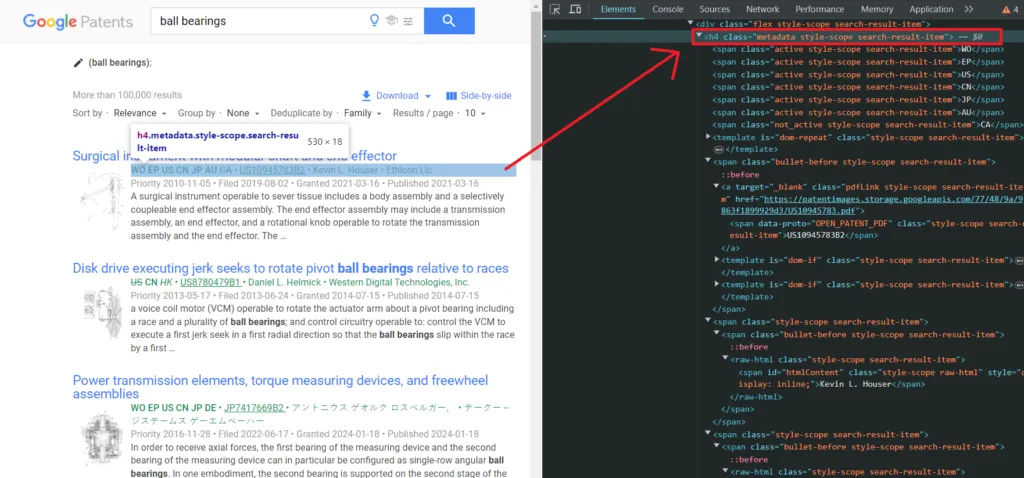
Let us add this in our code also.
metadata = ' '.join(el.select_one('h4.metadata').get_text().split())
Similarly, we will select the dates that are present with the same tag h4 but with a different class name dates.
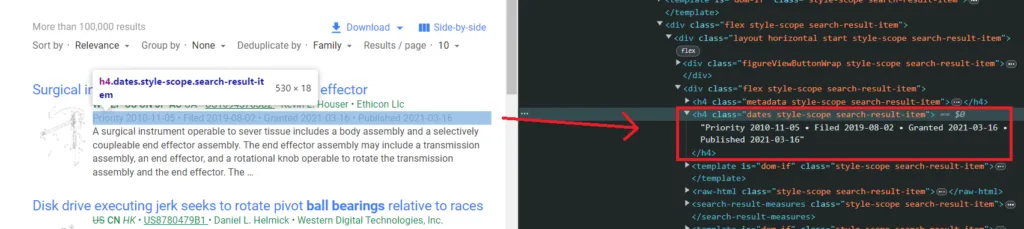
date = el.select_one('h4.dates').get_text().strip()
Finally, we will extract the snippet part of the patent.
Scraping Snippet
The snippet is contained inside the span tag with the id htmlContent.

At last, we will add this to our code.
snippet = el.select_one('span#htmlContent').get_text()
We have parsed every data point we need from the web page.
At the end, we will append these data points to our patent_results array.
for el in soup.select('search-result-item'):
title = el.select_one('h3').get_text().strip()
link = "https://patents.google.com/" + el.select_one("state-modifier")['data-result']
metadata = ' '.join(el.select_one('h4.metadata').get_text().split())
date = el.select_one('h4.dates').get_text().strip()
snippet = el.select_one('span#htmlContent').get_text()
patent_results.append({
'title': title,
'link': link,
'metadata': metadata,
'date': date,
'snippet': snippet
})
Complete Code
You can modify the below code as per your requirements. But for this tutorial, we will go with this one:
import json
import requests
from bs4 import BeautifulSoup
url = "https://patents.google.com/?q=(ball+bearings)&oq=ball+bearings"
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
patent_results = []
for el in soup.select('search-result-item'):
title = el.select_one('h3').get_text().strip()
link = "https://patents.google.com/" + el.select_one("state-modifier")['data-result']
metadata = ' '.join(el.select_one('h4.metadata').get_text().split())
date = el.select_one('h4.dates').get_text().strip()
snippet = el.select_one('span#htmlContent').get_text()
patent_results.append({
'title': title,
'link': link,
'metadata': metadata,
'date': date,
'snippet': snippet
})
print(json.dumps(patent_results, indent=2))
else:
print(f"Failed to retrieve the page. Status code: {response.status_code}")
Run this program in your terminal and you will get the below desired results.
[
{
title: 'Surgical instrument with modular shaft and end effector',
link: 'https://patent.google.com/patent/US10945783B2/en',
metadata: 'WO EP US CN JP AU CA US10945783B2 Kevin L. Houser Ethicon Llc',
date: 'Priority 2010-11-05 • Filed 2019-08-02 • Granted 2021-03-16 • Published 2021-03-16',
snippet: ' Surgical instrument with modular shaft and end effectorKevin L. HouserEthicon Llc A surgical instrument operable to sever tissue includes a body assembly and a selectively coupleable end effector assembly. The end effector assembly may include a transmission assembly, an end effector, and a rotational knob operable to rotate the transmission assembly and the end effector. The …'
},
{
title: 'Disk drive executing jerk seeks to rotate pivot ball bearings relative to races',
link: 'https://patent.google.com/patent/US8780479B1/en',
metadata: 'US CN HK US8780479B1 Daniel L. Helmick Western Digital Technologies, Inc.',
date: 'Priority 2013-05-17 • Filed 2013-06-24 • Granted 2014-07-15 • Published 2014-07-15',
snippet: ' Disk drive executing jerk seeks to rotate pivot ball bearings relative to racesDaniel L. HelmickWestern Digital Technologies, Inc. a voice coil motor (VCM) operable to rotate the actuator arm about a pivot bearing including a race and a plurality of ball bearings; and control circuitry operable to: control the VCM to execute a first jerk seek in a first radial direction so that the ball bearings slip within the race by a first …'
},
.....
Key Takeaways:
Google Patents contains structured data like patent titles, inventors, assignees, filing dates, citations, and legal status.
Manual extraction is inefficient due to pagination, dynamic loading, and anti-bot protections.
Scraping Google Patents requires handling JavaScript rendering and request throttling.
Patent data is valuable for competitive research, innovation tracking, and IP analysis.
Using a scraping API simplifies large-scale patent data extraction without managing proxies or bypass systems.
Conclusion
In a nutshell, scraping Google Patents can be a powerful tool for researchers who seek to create a patent database for market research, data analysis, academic projects, and much more.
In this article, we learned to scrape Google Patent results using Python. For those looking to further refine their scraping skills, consider the option to hire a Python developer. We will continue to update this article with more insights into scraping Google patent data more efficiently.
You can use Scrapingdog’s Google Patents API to get the JSON data.
Feel free to contact us for anything you need clarification on. Follow us on Twitter. Thanks for reading!


