TL;DR
- Python guide to scrape Idealista with
requests+BeautifulSoup. - Parses listing cards to get title, price, area, description, and property link.
- Full code and sample output; adds realistic headers to reduce blocks.
- For scale, recommends a scraping API (Scrapingdog) to handle proxies / headers / browsers / retries.
Scraping Idealista can give you massive datasets that you need to drive business growth. Real Estate has become a crucial sector for any country around the globe and every decision is backed by some solid data analysis.
Now if we are talking about data, how should we collect so much data faster? Well, here web scraping can help you collect data.
In this tutorial, we are going to scrape the biggest real estate portal in Portugal Idealista. We are going to use Python for this tutorial & will create our own Idealista scraper.
Collecting all the Ingredients for Scraping
I am assuming that you have already installed Python on your machine. I will be using Python 3.x. With that being installed we will require two more libraries for data extraction.
- Requests — This will be used to make the GET request and download the raw HTML from our target web page.
- BeautifulSoup — It will be used to parse the data.
First, we need to create the folder where we will keep our script.
mkdir coding
Inside this folder, you can create a file by any name you like. I am going to use idealista.py in this case. Finally, we are going to install the libraries mentioned above using pip.
pip install requests
pip install beautifulsoup4
This web scraping task is mainly divided into two parts, one is to download the raw HTML from the target web page using requests and the other part is to parse the data using BS4.
What are we going to scrape?
For this tutorial, we are going to scrape this page from Idealista and from the same page, we are going to extract these data points:
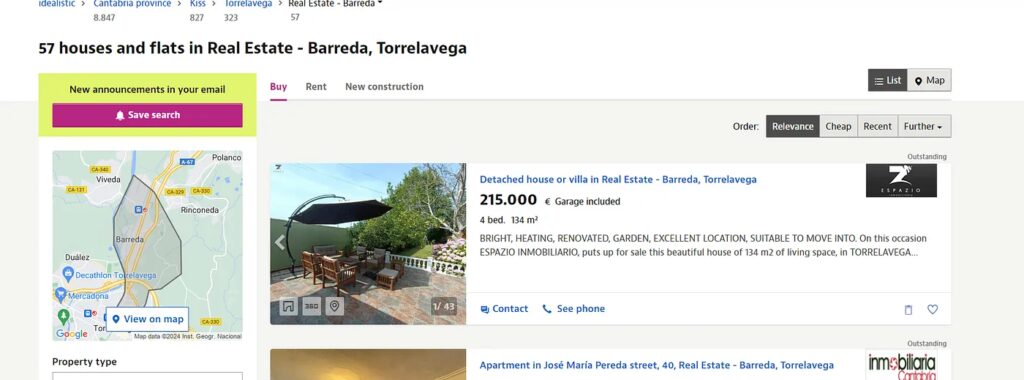
I have decided to scrape the following data points:
- Title of the property
- Price of the property
- Property Description
- Dedicated web link of the property.
requests and then parse the data using BS4.Downloading the raw HTML
Using requests we will make a simple GET request to download the raw HTML.
import requests
from bs4 import BeautifulSoup
l=list()
o={}
target_url = "https://www.idealista.com/venta-viviendas/torrelavega/inmobiliaria-barreda/"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36","Accept-Language":"en-US,en;q=0.9","Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9","Accept-Encoding":"gzip, deflate, br","upgrade-insecure-requests":"1"}
resp = requests.get(target_url, headers=headers)
print(resp.status_code)
I first imported all the required libraries and then declared an empty list l and an object o.
Then I declared the target URL and headers. We are passing headers to the request because idealista.com loves throwing captchas. This will help us make this request look more authentic.
Finally, we are making a GET request using requests.
After running the code if you get a 200 status code then we can proceed with the parsing process. Let’s run the code and check the status.

I know most of you will not get a 200 , which is fine. I will share a solution at the end of this article that will help you scrape Idealista at scale without getting blocked.
Parsing using BeautifulSoup
Before we write a single line of code for parsing the data we have to identify the location of each data element inside the HTML DOM.
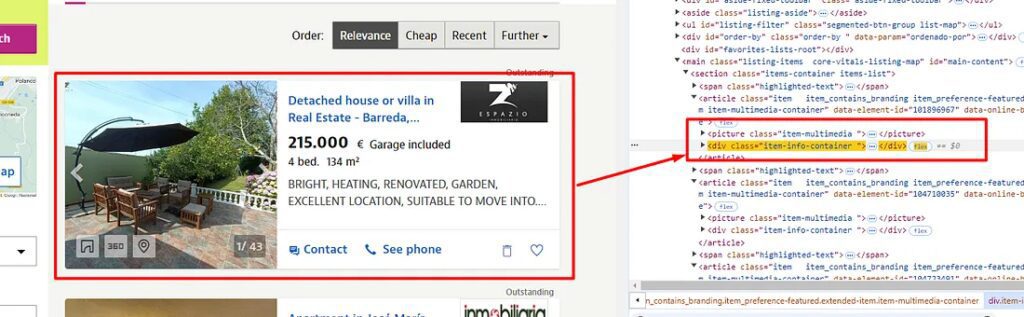
Identifying the location of each element
Each property listing is located inside the div tag with the class item-info-container.
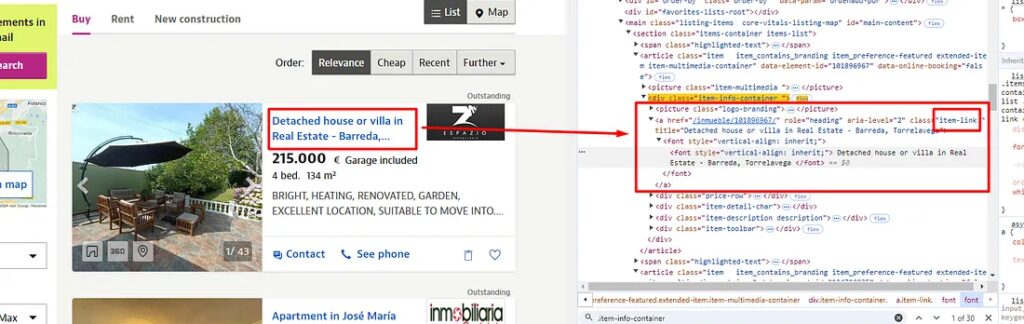
Identifying where the title tag is stored
The property title is stored inside a tag with a class item-link.
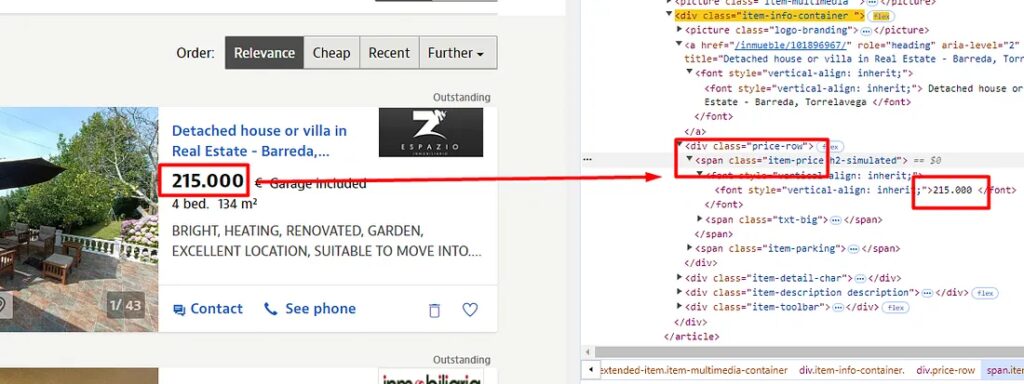
Identifying where the property price is stored
The property price is stored inside the span tag with the class item-price.
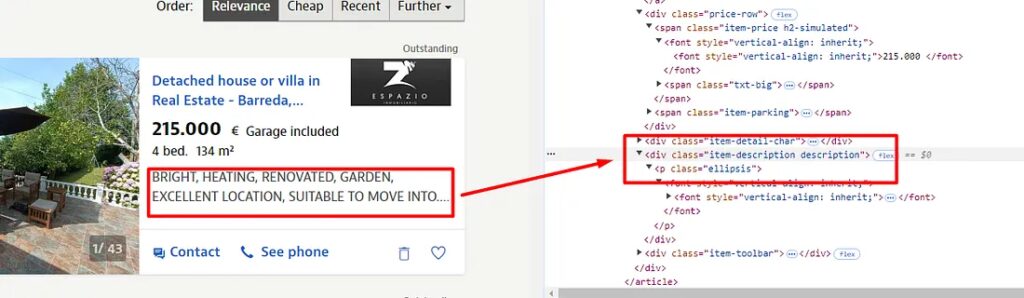
Identifying where the property description is in HTML
The property description is stored inside the div tag with the class item-description.
Property link is stored inside a tag with class item-link.
We are now completely ready to parse this data.
soup = BeautifulSoup(resp.text, 'html.parser')
allProperties = soup.find_all("div",{"class":"item-info-container"})
for i in range(0,len(allProperties)):
o["title"]=allProperties[i].find("a",{"class":"item-link"}).text.strip("\n")
o["price"]=allProperties[i].find("span",{"class":"item-price"}).text.strip("\n")
o["area-size"]=allProperties[i].find("div",{"class":"item-detail-char"}).text.strip("\n")
o["description"]=allProperties[i].find("div",{"class":"item-description"}).text.strip("\n")
o["property-link"]="https://www.idealista.com"+allProperties[i].find("a",{"class":"item-link"}).get('href')
l.append(o)
o={}
print(l)
Using find_all() method of BeautifulSoup we have created a list allProperties of all the listed properties.
Then using a for loop we reach each element inside the allProperties list. Using find() method we are finding property data and storing it inside the object o and finally pushing the data to a list l.
Once we run the code we get this.

We were able to scrape and extract the data from Idealista.
Complete Code
You can make a few more changes to extract a little more information like the number of properties, map, etc. But the current code will look like this.
import requests
from bs4 import BeautifulSoup
l=list()
o={}
target_url = "https://www.idealista.com/venta-viviendas/torrelavega/inmobiliaria-barreda/"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36","Accept-Language":"en-US,en;q=0.9","Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9","Accept-Encoding":"gzip, deflate, br","upgrade-insecure-requests":"1"}
resp = requests.get(target_url, headers=headers)
print(resp.status_code)
soup = BeautifulSoup(resp.text, 'html.parser')
allProperties = soup.find_all("div",{"class":"item-info-container"})
for i in range(0,len(allProperties)):
o["title"]=allProperties[i].find("a",{"class":"item-link"}).text.strip("\n")
o["price"]=allProperties[i].find("span",{"class":"item-price"}).text.strip("\n")
o["area-size"]=allProperties[i].find("div",{"class":"item-detail-char"}).text.strip("\n")
o["description"]=allProperties[i].find("div",{"class":"item-description"}).text.strip("\n")
o["property-link"]="https://www.idealista.com"+allProperties[i].find("a",{"class":"item-link"}).get('href')
l.append(o)
o={}
print(l)
Limitations of this approach
Using Scrapingdog for scraping Idealista
So, we have seen how you can scrape Idealista using Python. But to be very honest, idealista.com is a well-protected site and you cannot extract data at scale using only Python. In fact, after 10 or 20 odd requests Idealista will detect scraping and ultimately will block your scrapers.
After that, you will continuously get 403 errors on every web request you make. Here Scrapingdog’s web scraping API can help you scrape Idealista very efficiently with its large pool of proxies to overcome any challenges such as IP blocking.
Scrapingdog provides free 1000 API calls for all new users and in that pack, you can use all the premium features. First, you need to sign up to get your private API key.
You can find your API key at the top of the dashboard. You just have to make a few changes to the above code and Scrapingdog will be able to handle the rest of the things. You don’t need Selenium or any other web driver to scrape it. You just have to use the requests library to make a GET request to the Scrapingdog API.
import requests
from bs4 import BeautifulSoup
l=list()
o={}
target_url = "https://www.idealista.com/venta-viviendas/torrelavega/inmobiliaria-barreda/"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36","Accept-Language":"en-US,en;q=0.9","Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9","Accept-Encoding":"gzip, deflate, br","upgrade-insecure-requests":"1"}
resp = requests.get("https://api.scrapingdog.com/scrape?api_key=Your-API-Key&url={}&dynamic=false".format(target_url))
print(resp.status_code)
soup = BeautifulSoup(resp.text, 'html.parser')
allProperties = soup.find_all("div",{"class":"item-info-container"})
for i in range(0,len(allProperties)):
o["title"]=allProperties[i].find("a",{"class":"item-link"}).text.strip("\n")
o["price"]=allProperties[i].find("span",{"class":"item-price"}).text.strip("\n")
o["area-size"]=allProperties[i].find("div",{"class":"item-detail-char"}).text.strip("\n")
o["description"]=allProperties[i].find("div",{"class":"item-description"}).text.strip("\n")
o["property-link"]="https://www.idealista.com"+allProperties[i].find("a",{"class":"item-link"}).get('href')
l.append(o)
o={}
print(l)
As you can see the code is very similar to our earlier approach. Integrating Scrapingdog with your existing solution is very easy plus it fires up your data collection cylinders🔥.
Conclusion
In this blog, we understood how you can use Python to scraper Idealista, which is data rich real-estate website that needs no introduction. Further, we saw how Idealista can block your scrapers and to overcome you can use Scrapingdog’s web scraping API.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on social media.
Additional Resources
Here are a few additional resources you may find resourceful. We have scraped other real estate websites that are below: –