TL;DR
- Build a Python 3 scraper for Indeed NY “Python” jobs using
requests+BeautifulSoup. - Extract job title, company, location, and details by looping job cards; full code included.
- Fine for demos / small runs; at scale you’ll hit blocks.
- For scale, the post recommends Scrapingdog’s Indeed Scraper (JSON) with 1,000 free credits.
Indeed is one of the biggest job listing platforms available in the market. According to SemRush, they have monthly visitors ~ 542.52 Millions.
As a data engineer, you want to identify which job is in great demand. Well, then you have to scrape data from websites like Indeed to identify and make a conclusion.
In this article, we are going to web scrape Indeed & create a Scraper using Python 3.x. We are going to scrape Python jobs from Indeed in New York.
At the end of this tutorial, we will have all the jobs that need Python as a skill in New York.
Why Scrape Indeed Jobs?
Scraping Indeed Jobs can help you in multiple ways. Some of the use cases for extracting data from it are: –
- With this much data, you can train an AI model to predict salaries in the future for any given skill.
- Companies can use this data to analyze what salaries their rival companies are offering for a particular skill set. This will help them improve their recruitment strategy.
- You can also analyze what jobs are in high demand and what kind of skill set one needs to qualify for jobs in the future.
Setting up the prerequisites
We would need Python 3.x for this project and our target page will be this one from Indeed.
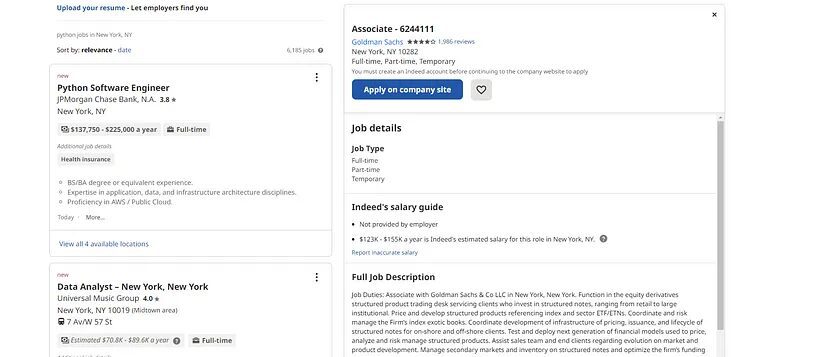
I am assuming that you have already installed Python on your machine. So, let’s move forward with the rest of the installation.
We would need two libraries that will help us extract data. We will install them with the help of pip.
Requests— Using this library we are going to make a GET request to the target URL.BeautifulSoup— Using this library we are going to parse HTML and extract all the crucial data that we need from the page. It is also known as BS4.
Installation
pip install requests
pip install beautifulsoup4
You can create a dedicated folder for Indeed on your machine and then create a Python file where we will write the code.
Let’s decide what we are going to scrape from Indeed.com
Whenever you start a scraping project, it is always better to decide in advance what exactly we need to extract from the target page.
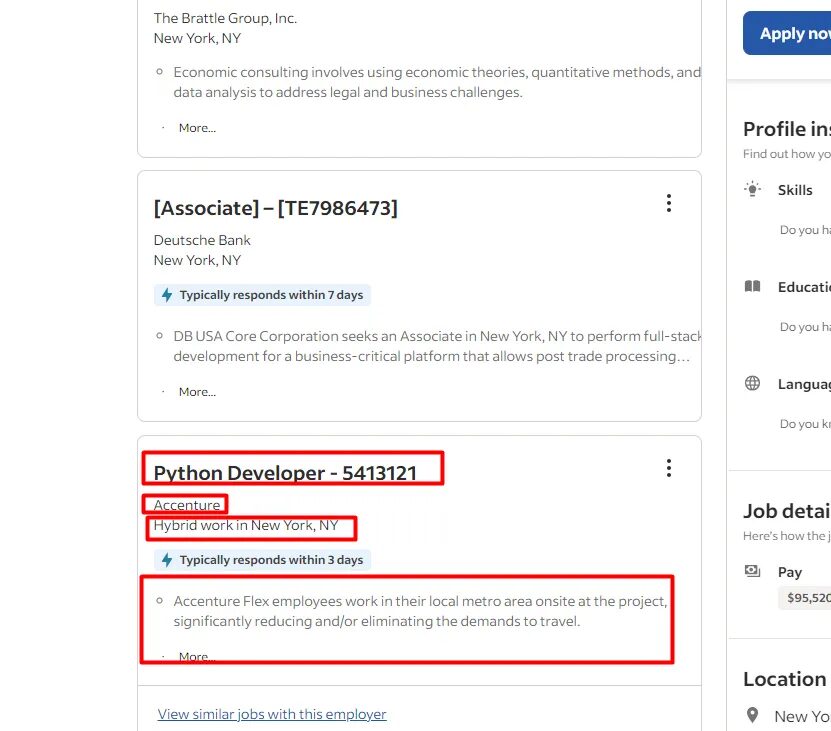
We are going to scrape all the highlighted parts in the above image.
- Name of the job
- Name of the company
- Location
- Job details
Let’s Start Indeed Job Scraping
Before even writing the first line of code, let’s find the exact element location in the DOM.
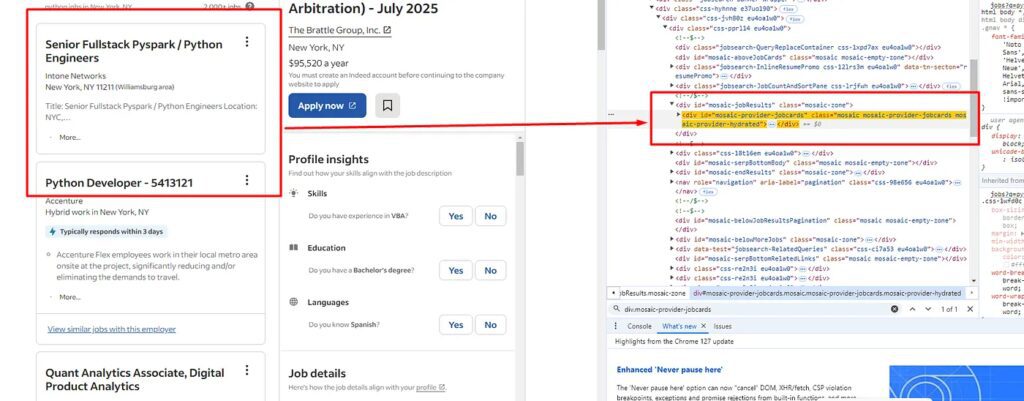
list tag. You can see this in the above image. There are 18 of them on each page, all under the div tag with class jobsearch-ResultsList. So, our first job would be to find this div tag.Let’s first import all the libraries in the file.
import requests
from bs4 import BeautifulSoup
Now, let’s declare the target URL and make an HTTP connection to that website.
l=[]
o={}
target_url = "https://www.indeed.com/jobs?q=python&l=New+York%2C+NY&vjk=8bf2e735050604df"
head= {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36",
"Accept-Encoding": "gzip, deflate, br",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Connection": "keep-alive",
"Accept-Language": "en-US,en;q=0.9,lt;q=0.8,et;q=0.7,de;q=0.6",
}
resp = requests.get(target_url, headers=head)
soup = BeautifulSoup(resp.text, 'html.parser')
allData = soup.find("div",{"class":"mosaic-provider-jobcards"})
Now, we have to iterate over each of these li tags and extract all the data one by one using a for loop.
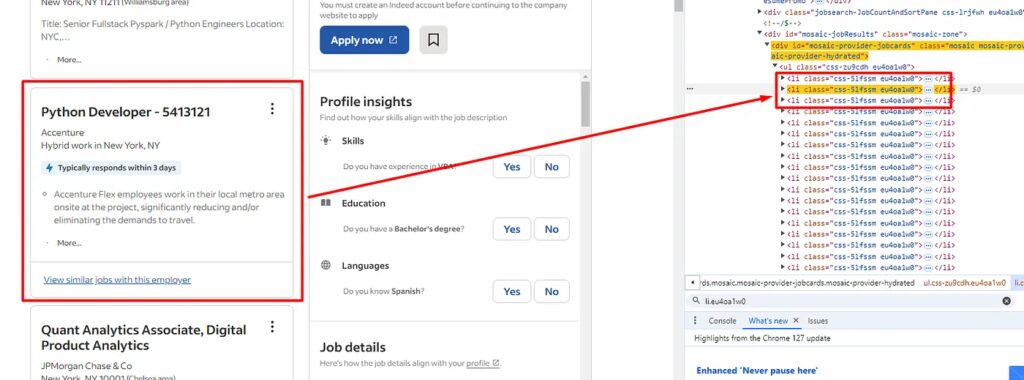
alllitags = allData.find_all("li",{"class":"eu4oa1w0"})
for loop on this list alllitags.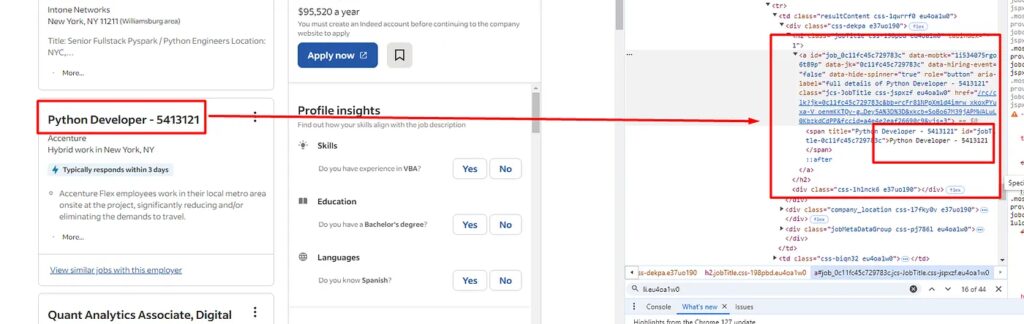
a tag. So, we will find this a tag and then extract the text out of it using .text() method of BS4.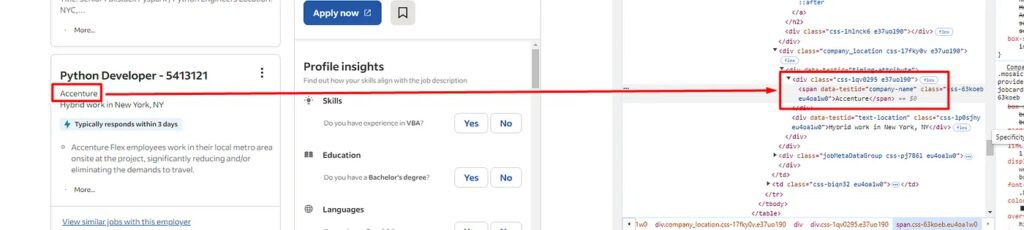
The name of the company can be found under the span tag with attribute data-testid and value company-name. Let’s extract this too.
for i in range(0,len(alllitags)):
try:
o["name-of-the-job"]=alllitags[i].find("a").find("span").text
except:
o["name-of-the-job"]=None
try:
o["name-of-the-company"]=alllitags[i].find("span",{"data-testid":"company-name"}).text
except:
o["name-of-the-company"]=None
Here we have first found the a tag and then we have used the .find() method to find the span tag inside it. You can check the image above for more clarity.

div tag with attribute data-testid and value text-location.
try:
o["job-location"]=alllitags[i].find("div",{"data-testid":"text-location"}).text
except:
o["job-location"]=None
The last thing we have to extract is the job details.

div tag with the class jobMetaDataGroup.
try:
o["job-details"]=alllitags[i].find("div",{"class":"jobMetaDataGroup"}).text
except:
o["job-details"]=None
l.append(o)
o={}
In the end, we have pushed the object o inside the list l and made the object o empty so that when the for loop runs again it will be able to store data of the new job.
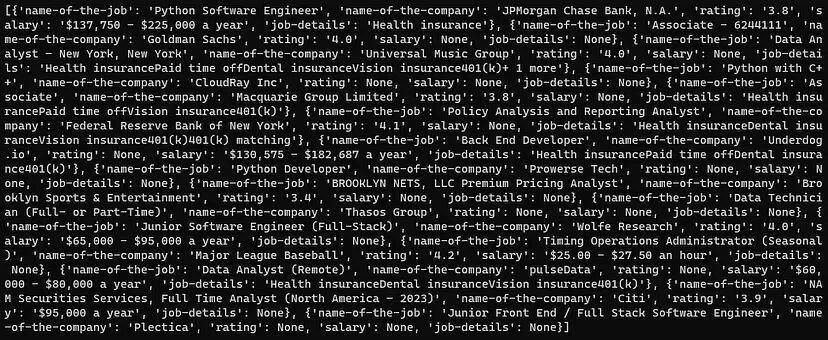
Let’s print it and see what are the results.
print(l)
Complete Code
You can make further changes to extract other details as well. You can even change the URL of the page to scrape jobs from the next pages.
But for now, the complete code will look like this.
import requests
from bs4 import BeautifulSoup
l=[]
o={}
target_url = "https://www.indeed.com/jobs?q=python&l=New+York%2C+NY&vjk=8bf2e735050604df"
head= {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36",
"Accept-Encoding": "gzip, deflate, br",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Connection": "keep-alive",
"Accept-Language": "en-US,en;q=0.9,lt;q=0.8,et;q=0.7,de;q=0.6",
}
resp = requests.get(target_url, headers=head)
print(resp.status_code)
soup = BeautifulSoup(resp.text, 'html.parser')
allData = soup.find("div",{"class":"mosaic-provider-jobcards"})
alllitags = allData.find_all("li",{"class":"eu4oa1w0"})
print(len(alllitags))
for i in range(0,len(alllitags)):
try:
o["name-of-the-job"]=alllitags[i].find("a").find("span").text
except:
o["name-of-the-job"]=None
try:
o["name-of-the-company"]=alllitags[i].find("span",{"data-testid":"company-name"}).text
except:
o["name-of-the-company"]=None
try:
o["job-location"]=alllitags[i].find("div",{"data-testid":"text-location"}).text
except:
o["job-location"]=None
try:
o["job-details"]=alllitags[i].find("div",{"class":"jobMetaDataGroup"}).text
except:
o["job-details"]=None
l.append(o)
o={}
print(l)
The approach we have used until now is fine, but it will not help you scrape millions of pages from Indeed. In such cases, it is advised to use web scraping APIs like Scrapingdog.
Scrapingdog will handle all the hassle, from rotating proxies to handling headless browsers. It will provide you with a seamless data pipeline without getting blocked.
Using Scrapingdog for scraping Indeed
Scrapingdog provides a dedicated Indeed Scraping API with which you can scrape Indeed at scale. You won’t even have to parse the data because you will already get data in JSON form.
Web Scraping APIs like Scrapingdog are crucial if you are trying to scrape Indeed at scale. The above approach is great but it will be blocked in no time when your IP will be blocked. Scrapingdog will use its own pool of more than 15 million proxies to scrape Indeed. This eliminates the possibility of the scraper getting blocked.
Scrapingdog provides a generous free pack with 1000 credits. You just have to sign up for that.
You can watch this quick video tutorial, wherein I have scrape Indeed using Scrapingdog’s API. ⬇️
Once you sign up, you will find an API key on your dashboard. You have to paste that API key in the provided code below.
import requests
import json
url = "https://api.scrapingdog.com/indeed"
api_key = "5eaa61a6e562fc52fe763tr516e4653"
job_search_url = "https://www.indeed.com/jobs?q=python%26l=New+York%2C+NY%26vjk=8bf2e735050604df"
# Set up the parameters
params = {"api_key": api_key, "url": job_search_url}
# Make the HTTP GET request
response = requests.get(url, params=params)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse the JSON content
json_response = response.json()
print(json_response)
else:
print(f"Error: {response.status_code}")
print(response.text)
You have to send a GET request to https://api.scrapingdog.com/indeed with your API key and the target Indeed URL.
With this script, you will be able to scrape Indeed with a lightning-fast speed that too without getting blocked.
Key Takeaways:
Indeed job listings can be scraped using Python libraries like
requestsandBeautifulSoup.Important fields include job title, company name, location, salary, and job summary.
Pagination handling is required to collect multiple pages of job results.
Indeed uses anti-bot measures, so scraping at scale may require proxies and proper headers.
Structured output (JSON/CSV) makes scraped job data ready for job boards or analytics use cases.
Conclusion
In this tutorial, we were able to scrape Indeed job postings with Requests and BS4. Of course, you can modify the code a little to extract other details as well.
I have scraped Glassdoor job listings using Python, LinkedIn Jobs & Google Jobs using python, do check them out as well! Recently, I also made a tutorial on building a job board from web scraping, this blog gives a step-by-step approach to how you can create your job board with actionable insights.
You can change the page URL to scrape jobs from the next page. You have to find the change that happens to the URL once you change the page by clicking the number from the bottom of the page. For scraping millions of such postings you can always use Scrapingdog.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on your social media.


