
TL;DR
- Scrape public LinkedIn profiles in Python using
requests+ public-page cookies (legal), but it’s fragile. - Expect IP bans / cookie expiry leading to auth redirects.
- For scale, use Scrapingdog’s LinkedIn Profile Scraper: returns JSON for people / companies, includes 1,000 free credits; API key on dashboard + docs linked.
LinkedIn is a large network of professional people.
It connects around 900M people around the globe. This is a place where people post about their work experience, company culture, current market trends, etc.
It can also be used for generating leads for your business. You can find prospects who might be interested in your product.
Scraping LinkedIn profiles has multiple applications.
In this blog, we are going to learn how we can scrape LinkedIn profiles with Python.
Later I will explain how Scrapingdog’s LinkedIn Scraper API can help you scrape millions of profiles on daily basis.
Let’s get started!!
Setting up The Prerequisites for Scraping LinkedIn Profiles using Python
I hope you have already installed Python 3.x on your machine. If not then you can download it from here.
Then create a folder in which you will keep the Python script and inside this folder create a Python file.
mkdir linkedin
I am creating a Python file by the name scrapeprofile.py inside this folder.
Required Libraries
- Requests– Using this library we will make an HTTP connection with the Amazon page. This library will help us to extract the raw HTML from the target page.
You can install this library with this command.
pip install requests
Let’s Start Scraping LinkedIn Profile
Before we start writing the code, I would advise you to always focus on scraping public LinkedIn profiles rather than scraping the private ones.
If you want to learn more about legal issues involved while scraping LinkedIn then do read this article.
Let’s proceed with scraping LinkedIn. Let me first list down the number of methods we have through which we can scrape LinkedIn.
- Scraping LinkedIn profiles with the cookies of a registered user- This is an illegal process since you are using private cookies to get into their system.
- Scraping profiles with cookies of a public page- This is completely legal.
We are going to use the 2nd method. Of course, this method has its own limitation and I will later explain to you how you can bypass this limitation.
Let’s first collect cookies by opening a public profile. You can get cookies by opening the Chrome dev tools.
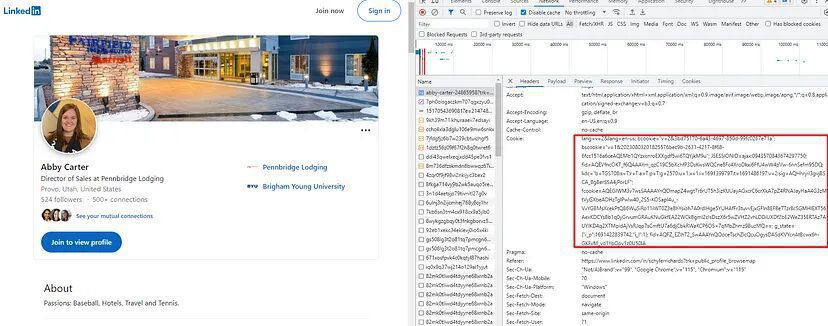
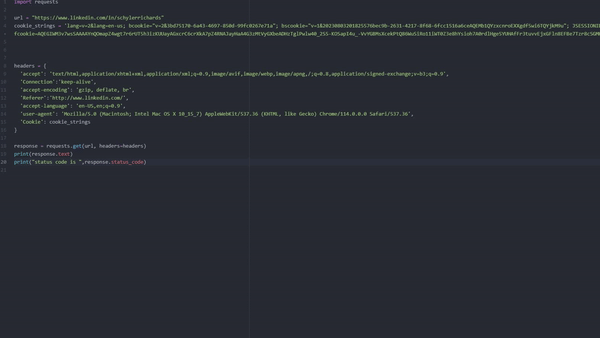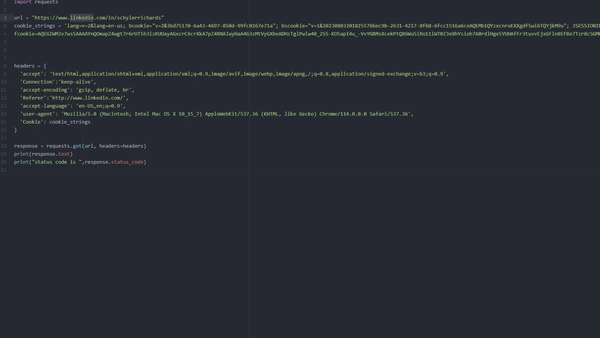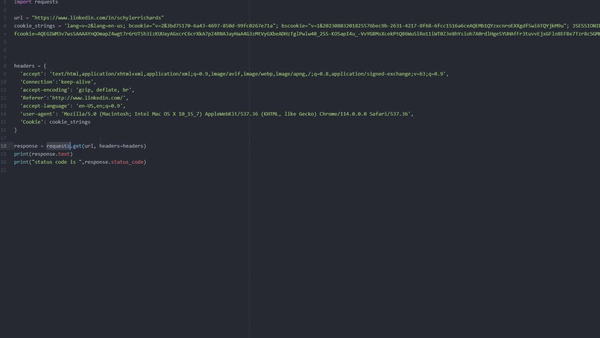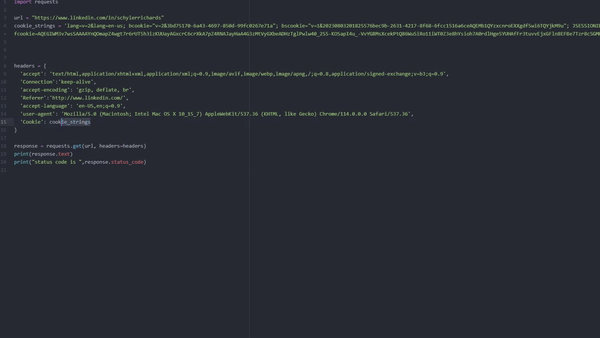
import requests
url = "https://www.linkedin.com/in/schylerrichards"
cookie_strings = 'lang=v=2&lang=en-us; bcookie="v=2&3bd75170–6a43–4697–850d-99fc0267e71a"; bscookie="v=1&20230803201825576bec9b-2631–4217–8f68–6fcc1516a6ceAQEMb1QYzxcnroEXXgdf5wi6TQYjkM9u"; JSESSIONID=ajax:0943570843674297750; fid=AQEVfncOKT_f6QAAAYm_qzC19C5bXchfP3DsKwsWQCne8Fc4XroDkxi6FfU4wW4pVw-6nnSefm95DQ; lidc="b=TGST08:s=T:r=T:a=T:p=T:g=2570:u=1:x=1:i=1691399797:t=1691486197:v=2:sig=AQHhryiI3gvjBSCA_BgBerSSA4jPorLF"; fcookie=AQEGIWM3v7wsSAAAAYnQOmapZ4wgt7r6rUT5h3izKUUayAGxcrC6crXkA7pZ4RNAJayHaA4G3zMtVyGXbeADHzTglPwlw40_2S5-KOSapI4u_-VvYGBMsXcekPtQ86WuSiRo11iWT0Z3e8hYsioh7A0rdlHge5YUHAfFr3tuvvEjxGFln8EFBe7Tzr8cSGMHlEXT56AexKDCYsBb1q0yGrvumGRAuKNuGkfEA22WCkBgml2cIsDszX6r5wZVHZ2vhLDDiUXDf2bE2WeZ35ERTAz7AUYIKD4q2XTMpidAjVsRJqp7sCmftU7a6djCbkRWaKCP6OS+7qMbZhmz9BuzMQ==; g_state={"i_p":1691422839742,"i_l":1}; fid=AQFZ_EZlhT2_SwAAAYnQOoceTschZlcQcuOgysDASdKVYcnAtBcwx6h-GKFvM_vd1YpOpv1z0U50lA'
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Connection':'keep-alive',
'accept-encoding': 'gzip, deflate, br',
'Referer':'http://www.linkedin.com/',
'accept-language': 'en-US,en;q=0.9',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
'Cookie': cookie_strings
}
response = requests.get(url, headers=headers)
print(response.status_code)
print(response.text)
This Python code performs a GET request to the URL “https://www.linkedin.com/in/schylerrichards“ with custom headers, including a specific set of cookies. The response status code is printed to the console.
Let’s break down the code step by step:
- Import the
requestslibrary: This code requires therequestslibrary to make HTTP requests. - Define the URL and Cookie String: The
urlvariable contains the URL of the page to be scraped. Thecookie_stringsvariable contains the cookie we copied earlier from a public LinkedIn profile. - Define the Headers: The
headersdictionary contains various request headers that are sent along with the GET request. These headers include'accept','Connection','accept-encoding','Referer','accept-language', and'user-agent'. Additionally, the'Cookie'header is set to thecookie_stringsvariable to include the specified cookies in the request. - Make the GET Request: The code uses
requests.get(url, headers=headers)to make the GET request to the given URL with the custom headers. - Print the Response Status Code: The status code of the response is printed to the console using
response.status_code. This status code indicates the success or failure of the GET request.
Once you run this code you will get a 200 status code.
Let’s try to scrape another profile. Once again if you run the code you will see a 200 status code.

At this stage, I bet your adrenaline is rushing and you are feeling like you have created the best LinkedIn scraper but hey this is just an illusion and this scraper is going to fall flat after just a few profiles have been scraped.
From here two things are might happen.
- Your IP will be banned.
- Your cookies will expire.
Once this happens, LinkedIn will redirect all of your requests to an authentication page.😔
LinkedIn is very protective of user privacy and due to this, your data pipeline will stop. But there is a solution through which you can scrape millions of LinkedIn profiles without getting blocked.
Scrapingdog’s LinkedIn Profile Scraper API For Blockage-Free Data Extraction
Scrapingdog offers a dedicated scraper for scraping LinkedIn profiles. This API provides free 1000 credits for you to test the service before you commit to the paid subscription.
After signing up, you will find an API key on the dashboard. You have to use that API key to access the API. You can read more about this API through documentation.
import requests
url = "https://api.scrapingdog.com/linkedin/"
params = {
"api_key": "Your-API-Key",
"type": "company",
"linkId": "amazon"
}
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
print(data)
else:
print(f"Request failed with status code: {response.status_code}")
Once you run this code you will get a JSON response.
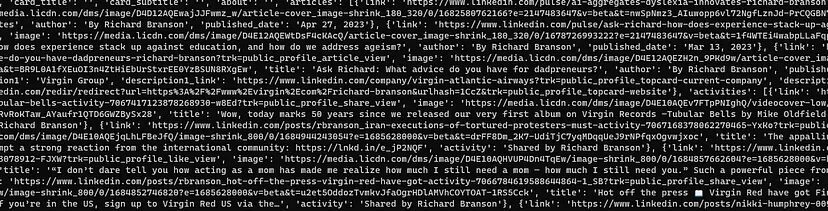
Right from the prospect’s name to his work experience, everything has been scraped and served to you in a JSON format.
Now you can use it anywhere you like. Watch the Video Below to understand how to use Scrapingdog’s LinkedIn Profile Scaper API⬇️
Similarly, you can scrape LinkedIn company profiles as well. Before proceeding I would recommend you to read the documentation.
import requests
url = "https://api.scrapingdog.com/linkedin/"
params = {
"api_key": "Your-API-Key",
"type": "company",
"linkId": "amazon"
}
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
print(data)
else:
print(f"Request failed with status code: {response.status_code}")
After running the code you will see this data.
Within this JSON you will get company details like:
- Company Size
- Company HQ
- Industry Type
- Description of the company
- Addresses of other offices
- Updates from the company
While developers often build scrapers for recruitment, lead gen, or market research, nonprofit organizations also find value in LinkedIn data, for example, when identifying potential supporters or collaborators through LinkedIn fundraising.
Key Takeaways:
The blog explains how to scrape LinkedIn profile data (name, headline, experience, location, etc.) using Python.
LinkedIn has strong anti-bot systems and login walls that make direct scraping difficult.
Public profile data can be accessed by carefully structuring requests and handling authentication barriers.
Python libraries are used to fetch and parse HTML or embedded data from profile pages.
For scalable and reliable scraping, using a dedicated LinkedIn scraper API is more practical than maintaining custom scraping logic.
Conclusion
In this article, I explained to you how you can scrape LinkedIn profiles using Python. I also showed you a way to bypass the LinkedIn auth wall (It is a paid method).
You can also check out my dedicated article on scraping LinkedIn jobs using Python. For the same, I have made a dedicated LinkedIn Job Scraper API, if you are looking to scrape LinkedIn jobs at scale, do check it out too!!
Also, recently we made an automation using make.com to scrape LinkedIn profiles using our LinkedIn Scraper API.
Scraping data from LinkedIn is not easy at all and I can say that this is the most challenging website when it comes to web scraping.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on your social media.


