TL;DR
- Python guide: use
Seleniumto render the Nasdaq page, then parse withBeautifulSoup. - Extract key fields for TSLA: name, ask price, P/E, dividend, and 1-year target.
- Full walkthrough + complete script included for quick reuse.
- Bonus: add a simple email alert when price crosses your target.
Nasdaq is a marketplace for buying and selling stocks. It was the first online stock exchange platform around the globe.
But why stock market data scraping is important? Well, it lets you do: –
- Sentiment analysis using blogs, news, social media status, etc.
- Stock market price prediction
- Financial analysis of any company with a single click. Obviously, you have to pass that scraped data through a Machine Learning model.
Why use Python to Scrape Nasdaq?
Python is a flexible programming language & is used extensively for web scraping. With many Python libraries for web scraping, this language is fast and reliable & has a strong community so that you can ask questions from this community whenever you get stuck.
In this blog post, we are going to scrape Tesla’s share information from Nasdaq.
Later in this blog, we will also create an alert email through which you will be notified once the stock hits the target price.
Read More: A Guide on Web Scraping using Python from Scratch!!
Let’s Start Scraping Stock Data from Nasdaq!
I am assuming you have already installed Python on your machine. Then we will create a folder and install all the required libraries in it.
>> mkdir nasdaq
>> pip install selenium
>> pip install beautifulsoup4
We have installed Selenium and BeautifulSoup. Selenium is a browser automating tool, it will be used to load NASDAQ target URL in a real Chrome browser. BeautifulSoup aka BS4 will be used for clean data extraction from raw HTML returned by selenium.
We could have used the requests library also but since NASDAQ loads everything using javascript then making a normal HTTP GET request would have been useless. If you want to learn more about the difference between how websites load data using Javascript and AJAX requests then you can read this requests for complete information on this topic.
Our target URL will be this and we will extract the following data points from the page.
- Name of the stock
- Current Ask Price
- P/E Ratio
- Dividend Rate
- 1-year target
For the purpose of this blog and tutorial on scraping Nasdaq, we will be extracting these data points only!
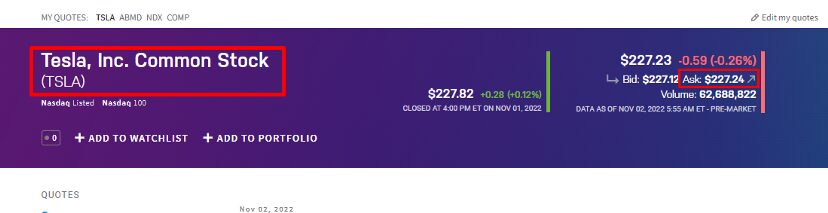
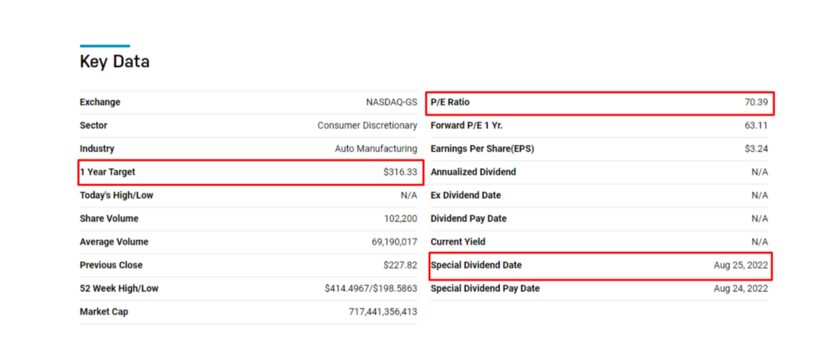
Create a Python file by the name you like and import all the libraries.
from bs4 import BeautifulSoup
from selenium import webdriver
import time
Let us first track the HTML location of each of these elements by inspecting them.

span tag with the class name symbol-page-header__name.
span tag with a class name as summary-data__table-body.

Both P/E ratio and Dividend date are part of the second tbody element of the table element.

1-year target is part of the first tbody element of the table element.
Finally, we have the exact locations of each of these elements. Let’s extract them all step-by-step.
from selenium.webdriver.common.keys import Keys
PATH = 'C:\Program Files (x86)\chromedriver.exe'
l=list()
obj={}
target_url = "https://www.nasdaq.com/market-activity/stocks/tsla"
driver=webdriver.Chrome(PATH)
driver.get(target_url)
html = driver.find_element_by_tag_name('html')
html.send_keys(Keys.END)
time.sleep(2)
resp = driver.page_source
driver.close()
.close() function.
soup=BeautifulSoup(resp,'html.parser')
try:
obj["name"]=soup.find("span",{"class":"symbol-page-header__name"}).text
except:
obj["name"]=None
try:
obj["askPrice"]=soup.find("span",{"class":"symbol-page-header__pricing-ask"}).text
except:
obj["askPrice"]=None
tables = soup.find("table",{"class":"summary-data__table"}).find_all("tbody",{"class":"summary-data__table-body"})
print(tables)
table1 = tables[0]
table2=tables[1]
try:
obj["P/E Ratio"]=table2.find_all("tr",{"class":"summary-data__row"})[0].find("td",{"class":"summary-data__cell"}).text
except:
obj["P/E Ratio"]=None
try:
obj["1-year budget"]=table1.find_all("tr",{"class":"summary-data__row"})[3].find("td",{"class":"summary-data__cell"}).text
except:
obj["1-year budget"]=None
try:
obj["Dividend"]=table2.find_all("tr",{"class":"summary-data__row"})[7].find("td",{"class":"summary-data__cell"}).text
except:
obj["Dividend"]=None
l.append(obj)
obj={}
print(l)
Then after closing the browser, we created an HTML tree using BS4. From that tree, we are going to extract our data of interest using .find() function. We are going to use the exact same HTML location that we found out about above.
The table part might be a little confusing for you. Let me explain it.
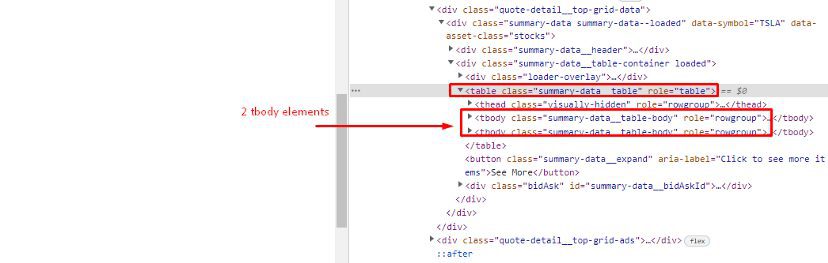
First, we find the table element using .find(), and then we have .find_all() to find both of these tbody elements. The first tbody element consists of a 1-year target value and the other one consist of both dividend date and P/E ratio. I hope your confusion is clear now.
Once you run this code you get all the data we were looking for in an array.
Complete Code
from bs4 import BeautifulSoup
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
PATH = 'C:\Program Files (x86)\chromedriver.exe'
l=list()
obj={}
target_url = "https://www.nasdaq.com/market-activity/stocks/tsla"
driver=webdriver.Chrome(PATH)
driver.get(target_url)
html = driver.find_element_by_tag_name('html')
html.send_keys(Keys.END)
time.sleep(2)
resp = driver.page_source
driver.close()
soup=BeautifulSoup(resp,'html.parser')
try:
obj["name"]=soup.find("span",{"class":"symbol-page-header__name"}).text
except:
obj["name"]=None
try:
obj["askPrice"]=soup.find("span",{"class":"symbol-page-header__pricing-ask"}).text
except:
obj["askPrice"]=None
tables = soup.find("table",{"class":"summary-data__table"}).find_all("tbody",{"class":"summary-data__table-body"})
print(tables)
table1 = tables[0]
table2=tables[1]
try:
obj["P/E Ratio"]=table2.find_all("tr",{"class":"summary-data__row"})[0].find("td",{"class":"summary-data__cell"}).text
except:
obj["P/E Ratio"]=None
try:
obj["1-year budget"]=table1.find_all("tr",{"class":"summary-data__row"})[3].find("td",{"class":"summary-data__cell"}).text
except:
obj["1-year budget"]=None
try:
obj["Dividend"]=table2.find_all("tr",{"class":"summary-data__row"})[7].find("td",{"class":"summary-data__cell"}).text
except:
obj["Dividend"]=None
l.append(obj)
obj={}
print(l)
Target Stock Price Alert via Email
What if you want to get an email alert once your target stock stocks hit a certain price? Well for that web scraping can be very helpful. Selling/buying a stock at the right time without raising your anxiety levels can be done easily with web scraping.
We will use the schedule library of Python that will help you to run the code at any given interval of time. Let’s split this section into two parts. In the first section, we will run the crawler every 15 minutes, and in the second section, we will mail ourselves once the price hits the target spot.
Part I — Running Crawler every 24 hours
We will run our main function every 15 minutes just to keep a regular check on the stock price.
from bs4 import BeautifulSoup
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
PATH = 'C:\Program Files (x86)\chromedriver.exe'
l=list()
obj={}
target_url = "https://www.nasdaq.com/market-activity/stocks/tsla"
driver=webdriver.Chrome(PATH)
driver.get(target_url)
html = driver.find_element_by_tag_name('html')
html.send_keys(Keys.END)
time.sleep(2)
resp = driver.page_source
driver.close()
soup=BeautifulSoup(resp,'html.parser')
try:
obj["name"]=soup.find("span",{"class":"symbol-page-header__name"}).text
except:
obj["name"]=None
try:
obj["askPrice"]=soup.find("span",{"class":"symbol-page-header__pricing-ask"}).text
except:
obj["askPrice"]=None
tables = soup.find("table",{"class":"summary-data__table"}).find_all("tbody",{"class":"summary-data__table-body"})
print(tables)
table1 = tables[0]
table2=tables[1]
try:
obj["P/E Ratio"]=table2.find_all("tr",{"class":"summary-data__row"})[0].find("td",{"class":"summary-data__cell"}).text
except:
obj["P/E Ratio"]=None
try:
obj["1-year budget"]=table1.find_all("tr",{"class":"summary-data__row"})[3].find("td",{"class":"summary-data__cell"}).text
except:
obj["1-year budget"]=None
try:
obj["Dividend"]=table2.find_all("tr",{"class":"summary-data__row"})[7].find("td",{"class":"summary-data__cell"}).text
except:
obj["Dividend"]=None
l.append(obj)
obj={}
print(l)
Here inside our main function, we have used the schedule library for running the tracker function every 15 minutes. Now, let’s send an email to ourselves for a price alert.
Part II — Mail
You will only send an email when your target price is hit otherwise you will not send any emails. So, we have to create an if/else condition where we will mention that if the price is our target price then send an email otherwise skip it.
Let us first set this if/else condition and then we will create our mail function. I am assuming our target price is 278 and the stock is in a bull mode which means the stock is currently rising. So, once it hits the 278 price we will receive an email for selling it.
from bs4 import BeautifulSoup
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
import schedule
PATH = 'C:\Program Files (x86)\chromedriver.exe'
l=list()
obj={}
target_url = "https://www.nasdaq.com/market-activity/stocks/tsla"
def tracker():
driver=webdriver.Chrome(PATH)
driver.get(target_url)
html = driver.find_element_by_tag_name('html')
html.send_keys(Keys.END)
time.sleep(2)
resp = driver.page_source
driver.close()
soup=BeautifulSoup(resp,'html.parser')
try:
obj["name"]=soup.find("span",{"class":"symbol-page-header__name"}).text
except:
obj["name"]=None
try:
obj["askPrice"]=soup.find("span",{"class":"symbol-page-header__pricing-ask"}).text
except:
obj["askPrice"]=None
tables = soup.find("table",{"class":"summary-data__table"}).find_all("tbody",{"class":"summary-data__table-body"})
print(tables)
table1 = tables[0]
table2=tables[1]
try:
obj["P/E Ratio"]=table2.find_all("tr",{"class":"summary-data__row"})[0].find("td",{"class":"summary-data__cell"}).text
except:
obj["P/E Ratio"]=None
try:
obj["1-year budget"]=table1.find_all("tr",{"class":"summary-data__row"})[3].find("td",{"class":"summary-data__cell"}).text
except:
obj["1-year budget"]=None
try:
obj["Dividend"]=table2.find_all("tr",{"class":"summary-data__row"})[7].find("td",{"class":"summary-data__cell"}).text
except:
obj["Dividend"]=None
if(obj["askPrice"] >= 278):
mail()
l.append(obj)
obj={}
print(l)
if __name__ == "__main__":
schedule.every().minute.at(":15").do(tracker)
while True:
schedule.run_pending()
As you can see I am comparing the current price with the target price if it is greater than or equal to 278 we are going to sell it otherwise the code will keep running every 15 minutes. Now, let’s define our mail function.
from bs4 import BeautifulSoup
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
import schedule
import smtplib
PATH = 'C:\Program Files (x86)\chromedriver.exe'
l=list()
obj={}
target_url = "https://www.nasdaq.com/market-activity/stocks/tsla"
def mail():
Msg = "Stock has hit your target price, it's time to earn some cash."
server = smtplib.SMTP('smtp.gmail.com', 587)
server.ehlo()
server.starttls()
server.login("from@gmail.com", "xxxx")
SUBJECT = "Stock Price Alert"
message = 'From: from@gmail.com \nSubject: {}\n\n{}'.format(SUBJECT, Msg)
server.sendmail("from@gmail.com", 'send_to@gmail.com', message)
def tracker():
driver=webdriver.Chrome(PATH)
driver.get(target_url)
html = driver.find_element_by_tag_name('html')
html.send_keys(Keys.END)
time.sleep(2)
resp = driver.page_source
driver.close()
soup=BeautifulSoup(resp,'html.parser')
try:
obj["name"]=soup.find("span",{"class":"symbol-page-header__name"}).text
except:
obj["name"]=None
try:
obj["askPrice"]=soup.find("span",{"class":"symbol-page-header__pricing-ask"}).text
except:
obj["askPrice"]=None
tables = soup.find("table",{"class":"summary-data__table"}).find_all("tbody",{"class":"summary-data__table-body"})
print(tables)
table1 = tables[0]
table2=tables[1]
try:
obj["P/E Ratio"]=table2.find_all("tr",{"class":"summary-data__row"})[0].find("td",{"class":"summary-data__cell"}).text
except:
obj["P/E Ratio"]=None
try:
obj["1-year budget"]=table1.find_all("tr",{"class":"summary-data__row"})[3].find("td",{"class":"summary-data__cell"}).text
except:
obj["1-year budget"]=None
try:
obj["Dividend"]=table2.find_all("tr",{"class":"summary-data__row"})[7].find("td",{"class":"summary-data__cell"}).text
except:
obj["Dividend"]=None
if(obj["askPrice"] == 278):
mail()
l.append(obj)
obj={}
print(l)
if __name__ == "__main__":
schedule.every().minute.at(":15").do(tracker)
while True:
schedule.run_pending()
In our mail function, we have used smtplib to send an email through Gmail id. You can set your own subject and message.
So, this was our alert mechanism which can be used on any website for price alerts. You can even use it for tracking Google keywords by scraping Google.
How to Web Scrape Nasdaq using Scrapingdog
Nasdaq is a very popular data-rich stock exchange website and many people crawl it on a regular basis. As we have discussed above Nasdaq cannot be scraped with normal HTTP GET requests, so we need headless Chrome support for scraping it and if you want to do it scale then it takes a lot of resources. Let’s see how Scrapingdog can help scrape this website.
Scrapingdog is a data scraping API that can help you create a seamless data pipeline in no time. You can start by signing up and making a test call directly from your dashboard.
Let’s go step by step to understand how you can use Scrapingdog to scrape Nasdaq without spending on some resource-hungry architecture. Oh! I almost forgot to tell you that for new users first 1000 calls are absolutely free.
First, you have to sign up!
Complete Code
Here we can take advantage of the requests library.
from bs4 import BeautifulSoup
import schedule
import smtplib
import requests
PATH = 'C:\Program Files (x86)\chromedriver.exe'
l=list()
obj={}
target_url = "https://api.scrapingdog.com/scrape?api_key=YOUR-API-KEY&url=https://www.nasdaq.com/market-activity/stocks/tsla"
def mail():
attackMsg = "Stock has hit your target price, it's time to earn some cash."
server = smtplib.SMTP('smtp.gmail.com', 587)
server.ehlo()
server.starttls()
server.login("from@gmail.com", "xxxx")
SUBJECT = "Stock Price Alert"
message = 'From: from@gmail.com \nSubject: {}\n\n{}'.format(SUBJECT, attackMsg)
server.sendmail("from@gmail.com", 'send_to@gmail.com', message)
def tracker():
resp = requests.get(target_url).text
soup=BeautifulSoup(resp,'html.parser')
try:
obj["name"]=soup.find("span",{"class":"symbol-page-header__name"}).text
except:
obj["name"]=None
try:
obj["askPrice"]=soup.find("span",{"class":"symbol-page-header__pricing-ask"}).text
except:
obj["askPrice"]=None
tables = soup.find("table",{"class":"summary-data__table"}).find_all("tbody",{"class":"summary-data__table-body"})
print(tables)
table1 = tables[0]
table2=tables[1]
try:
obj["P/E Ratio"]=table2.find_all("tr",{"class":"summary-data__row"})[0].find("td",{"class":"summary-data__cell"}).text
except:
obj["P/E Ratio"]=None
try:
obj["1-year budget"]=table1.find_all("tr",{"class":"summary-data__row"})[3].find("td",{"class":"summary-data__cell"}).text
except:
obj["1-year budget"]=None
try:
obj["Dividend"]=table2.find_all("tr",{"class":"summary-data__row"})[7].find("td",{"class":"summary-data__cell"}).text
except:
obj["Dividend"]=None
if(obj["askPrice"] == 278):
mail()
l.append(obj)
obj={}
print(l)
if __name__ == "__main__":
schedule.every().minute.at(":15").do(tracker)
while True:
schedule.run_pending()
You have to place your own API key in the target_url variable. Everything remains the same except we have removed the selenium driver and we are now making a normal GET request to the Scrapingdog API.
This helps you to save expenses of resources and avoid getting blocked while scraping at scale.
Forget about getting blocked while scraping the Web
Try out Scrapingdog Web Scraping API & Scrape Nasdaq at Scale without Getting Blocked
Key Takeaways:
Scraping data from Nasdaq requires handling JavaScript-rendered pages, which makes simple request-based scraping unreliable.
Using Selenium with BeautifulSoup allows you to extract dynamic stock metrics like price, P/E ratio, dividend rate, and 1-year target estimates.
Automated scripts can monitor stock prices and trigger alerts, enabling real-time financial tracking.
Running browser-based scrapers at scale is resource-intensive and harder to maintain long term.
Using a scraping API simplifies the process by handling JavaScript rendering, proxies, and infrastructure management for you.
Conclusion
We can create a price-tracking alert system for any website for example flight prices from websites like Expedia, product pricing from Amazon, etc. Python can help you create these crawlers with very little effort. But obviously, there is some limitation when you scrape these websites without Web Scraping API.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on social media.
Frequently Asked Questions
Try Scrapingdog for free today!! The first 1000 GET requests are free and get reset every month. Lite Plan is $30 and offers 200000 requests.
No, It never gets blocked. Scrapingdog’s Web Scraping API is made to surpass any blockage so that you can scrape Nasdaq without any blockage. Check out our Pricing Plans here!!


