Once you run this code you will get this on your console.
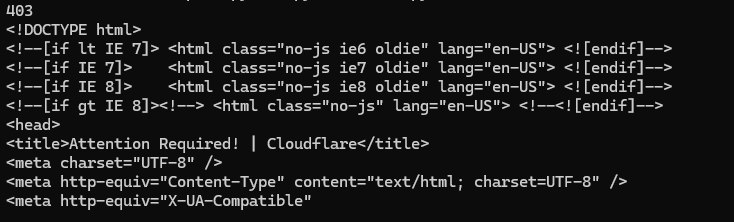
The request was blocked by Cloudflare, resulting in a 403 error code. Cloudflare redirected us to its verification page. This error is quite common when you are scraping websites.
Cloudflare thought that the incoming request was bot-like and ultimately blocked it. To bypass this verification page and scrape the target page we have to make the request look more humanized. This is where cloudscraper can help us.
Now, let’s see how we can bypass this blockage through Cloudscrper.
We have created a cloudscraper instance.
interpreter="nodejs"uses Node.js for executing JavaScript challenges.delay=10adds a 10-second delay between requests. This helps avoid detection.- Then to make the request look more authentic we are adding browser emulation. This will mimic a real browser. In our
cloudscrapercode, we are emulating a mobile Chrome browser on iOS.
Then finally we are making the GET request. Let’s run the code and see what happens.

We got 200 status code. That means cloudscraper was able to scrape our target webpage.
We will parse the title of the restaurant, the phone number, and the status of the restaurant.
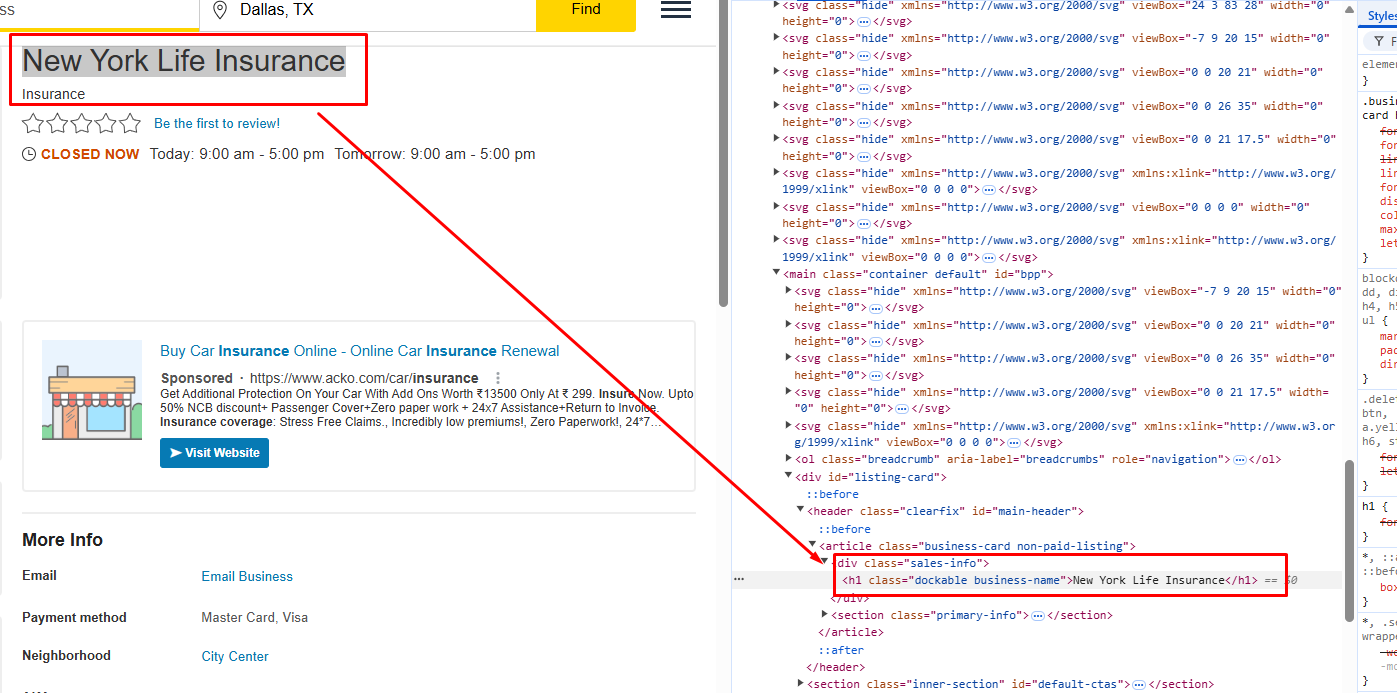
The title is located inside the h1 tag with the class business-name.

The status is located inside the div tag with class status-text.

The phone number is located inside the a tag with class phone.
Let’s run the code.

We were able to scrape and parse the data with the help of cloudscraper and BS4.
There is a small issue with this approach. This approach will not work if you want to scrape thousands of pages from websites protected by Cloudflare. We have to tweak the way we are making the GET request. Oneway is through passing custom headers.
So far, we’ve focused on what CloudScraper can do, but now let’s shift our attention to its limitations.
- Cloudflare keeps updating its security measures which makes scraping very difficult.
- Cloudscraper is designed specifically for bypassing Cloudflare but does not work on other bot protection systems, such as Akamai, PerimeterX, and Datadome.
- Cloudscraper bypasses JavaScript challenges, but when Cloudflare triggers reCAPTCHA or hCaptcha, it fails.
Let’s understand this with an example. Let’s scrape this page from indeed.com using cloudscraper. When you visit this page normally on your browser you will see this on your screen.
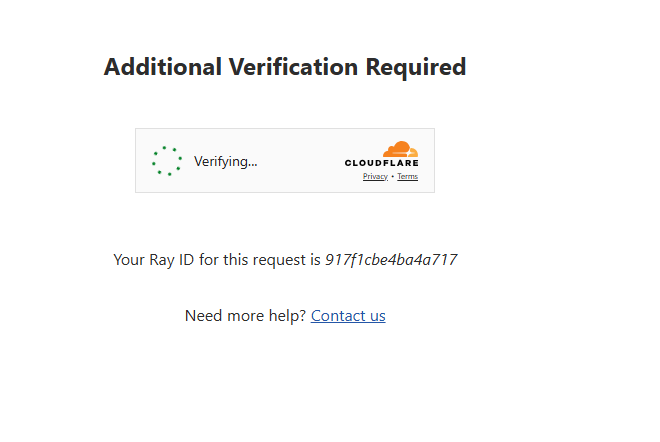
After waiting for a few seconds it will redirect us to the target page because it knows that the request came from a legit browser.
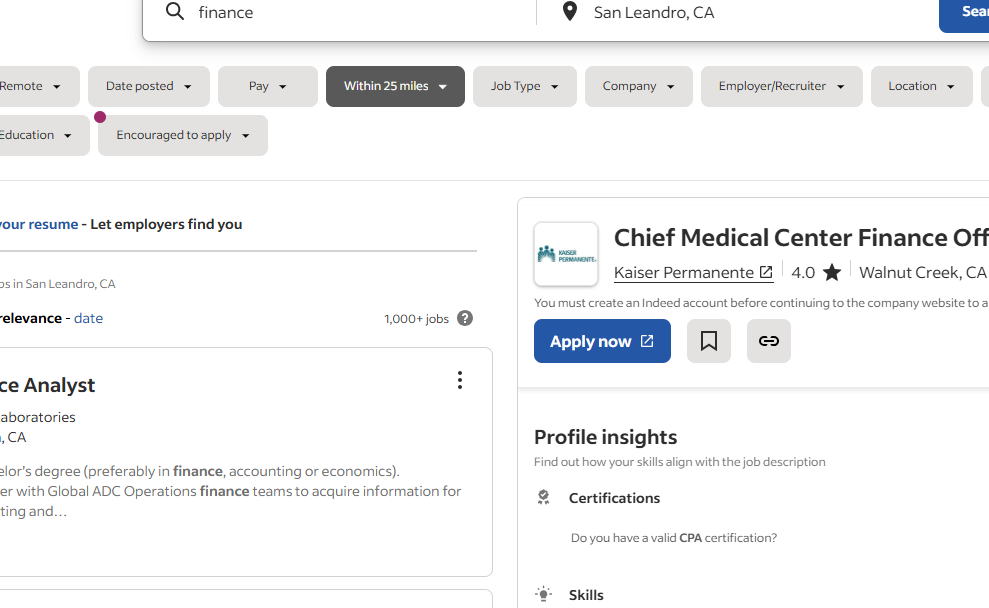
Now, let’s see whether cloudscraper can do the same thing or not.

Every request will give 403 error because the new updated version of Cloudflare won’t let cloudscraper bypass it.
If you want to scrape millions of pages from such websites then Scrapingdog can help you with it. It is a web scraping API that handles headers, proxies, retries, and of course Captchas for you.
To start with you just need to sign up for the trial pack. Once you are on the dashboard you can just paste your target URL and copy the code from the right-hand side.

Remember to use your own Scrapingdog API key before running the code.
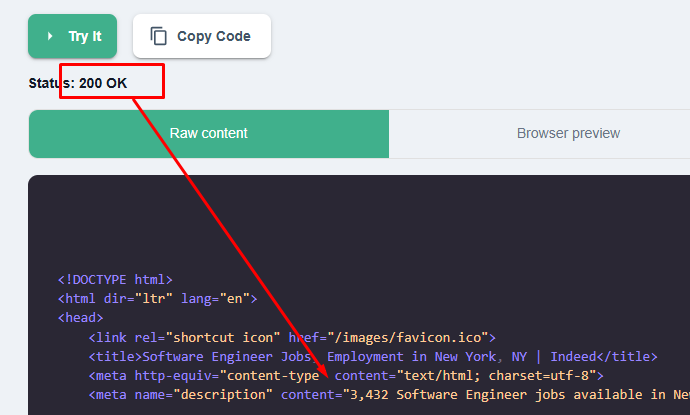
Once you run this code in your working environment you will see that Scrapingdog has bypassed Cloudflare’s security wall and extracted the results. We got the raw HTML and now using any parsing library you can extract valuable details from it.


