
TL;DR
- No-code scraping in Google Sheets with
IMPORTXML/IMPORTHTML(IMPORTDATAnoted). IMPORTXML+ XPath: start with one item, then generalize the selector to pull all names / prices; fix quote errors.- Scale via a dynamic URL using a page-number cell for pagination.
IMPORTHTML: pull a full table (Wikipedia demo) into a new sheet.
Web scraping is collecting data from the Internet for price aggregation, market research, lead generation, etc. However, web scraping is mainly done by major programming languages like Python, Nodejs, or PHP, and because of this, many non-coders find it very difficult to collect data from the Internet. They have to hire a developer to complete even small data extraction tasks.
In this article, we will learn how we can scrape a website using Google Sheets without using a single line of code. Google Sheets provides built-in functions like IMPORTHTML, IMPORTXML, and IMPORTDATA that allows you to import data from external sources directly into your spreadsheet. It is a great tool for web scraping. Let’s first understand these built-in functions one by one.
Google Sheets Functions
It is better to discuss Google Sheets’ capabilities before scraping a live website. As explained above, it offers three functions. Let’s discuss those functions in a little detail.
IMPORTHTML– This function provides you with the capability to import a structured list or a table from a website directly into the sheet. Isn’t that great?
=IMPORTHTML("url", "query", index)
"url"is the URL of the webpage containing the table or list you want to import data from."query"specifies whether to import a table (“table”) or a list (“list”).indexthe index of the table or list on the webpage. For example, if there are multiple tables on the page, you can specify which one to import by providing its index (e.g., 1 for the first table).
IMPORTXML– This function can help you extract text/values or specific data elements from structured HTML or XML.
=IMPORTXML(url, xpath_query)
urlis the URL of the webpage or XML file containing the data you want to import.xpath_queryis the query used to specify the data element or value you want to extract from the XML or HTML source.
IMPORTDATA– This function can help you import data from any external CSV or a TSV file directly into your Google sheet. It will not be discussed in this article later because the application of this function in web scraping is too small.
=IMPORTDATA(url)
Scraping with Google Sheets
This section will be divided into two parts. In the first part, we will use IMPORTXML for scraping, and in the next section, we will use IMPORTHTML for the same.
Scraping with IMPORTXML
The first step would be to set up an empty or blank Google Sheet. You can do it by visiting https://sheets.google.com/.

You can click on Blank Spreadsheet to create a blank sheet. Once this is done we have to analyze the structure of the target website. For this tutorial, we are going to scrape this website https://scrapeme.live/shop/.
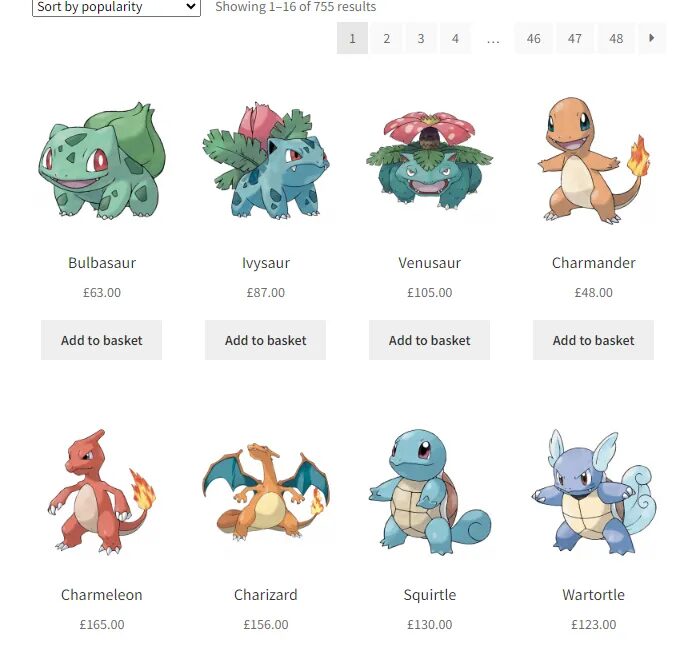
We are going to scrape the name of the Pokemon and its listed price. First, we will learn how we can scrape data for a single Pokemon and then later we will learn how it can be done for all the Pokemons on the page.
Scraping data for a single Pokemon
First, we will create three columns Name, Currency, and Price in our Google Sheet.
As you know IMPORTXML function takes two inputs as arguments.
- One is the target
URLand in our case the target URL is https://scrapeme.live/shop/ - Second is the
xpath_querywhich specifies the XPath expression used to extract specific data from the XML or HTML source.
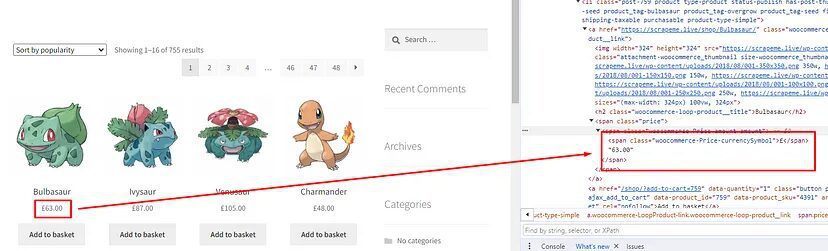
I know you must be wondering how you will get this xpath_query, well that is super simple. We will take advantage of Chrome developer tools in this case. Right-click on the name of the first Pokemon and then click on Inspect to open Chrome Dev Tools.
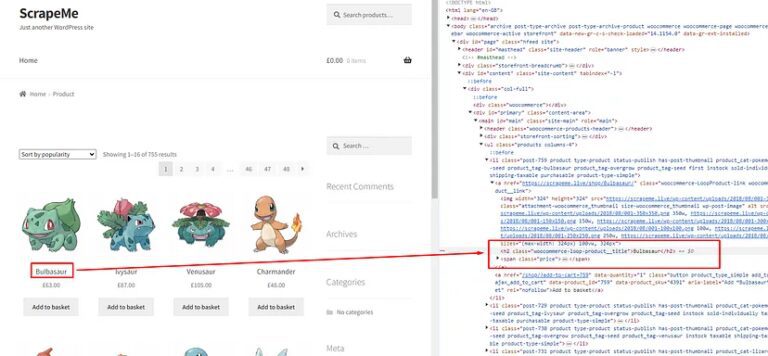
Now, we need an XPath query for this element. Well this can be done by a right click on that h2 tag and then click on the Copy button and finally click on the Copy XPath button. ⬇️
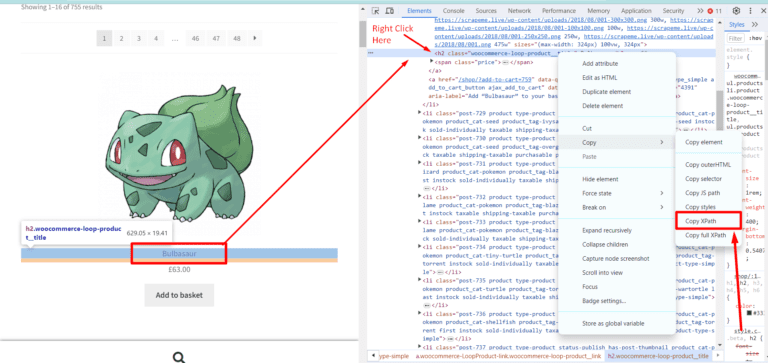
//*[@id="main"]/ul/li[1]/a[1]/h2
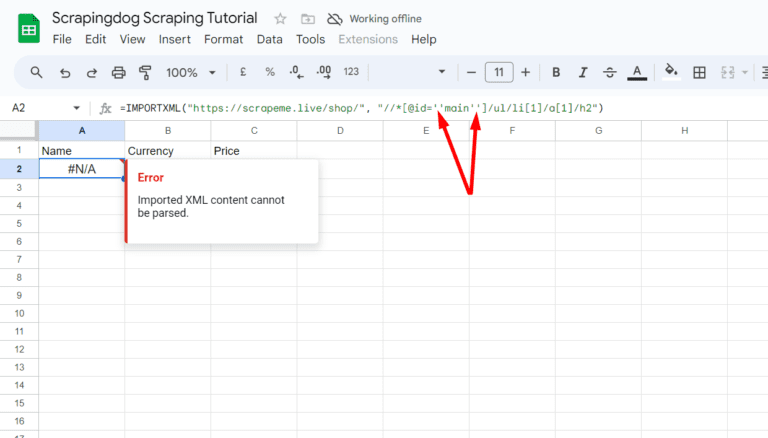
Formula parse error can be resolved by passing single quotes in xpath_query. So, once you type the right function, Google Sheets will pull the name of the first Pokemon.
=IMPORTXML("https://scrapeme.live/shop/", "//*[@id='main']/ul/li[1]/a[1]/h2")
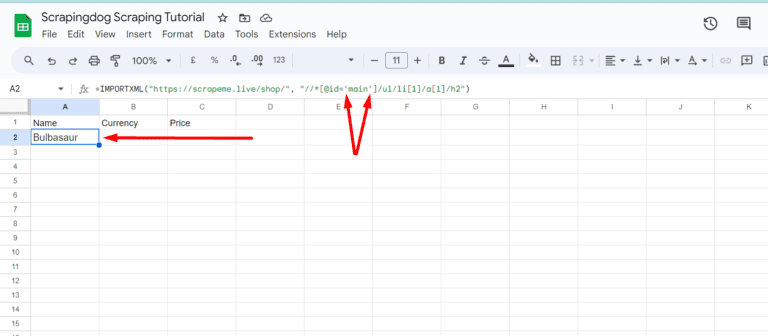
We can see Bulbasaur being pulled from the target web page in the A2 cell of the sheet. Well, this was fast and efficient too!
Now, the question is how to pull all the names. Do we have to apply a different xpath_query for each Pokemon present on the target page? Well, the answer is NO. We just have to figure out an XPath query that selects all the names of the Pokemon at once.
If you notice our current xpath_query you will notice that it is pulling data from the li element with an index 1. If you remove that index you will notice that it selects all the name tags.
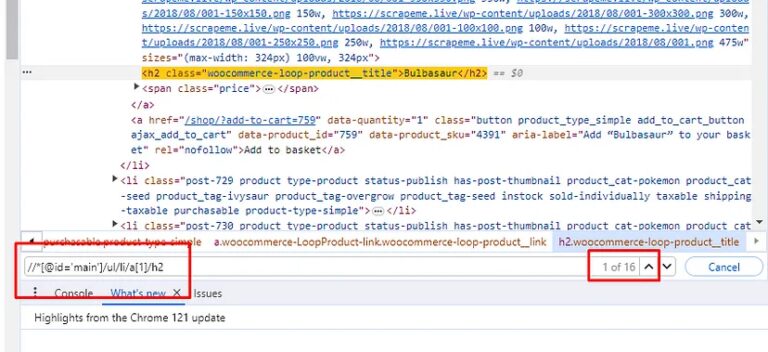
//*[@id='main']/ul/li/a[1]/h2
Let’s change our xpath_query in the IMPORTXML function.
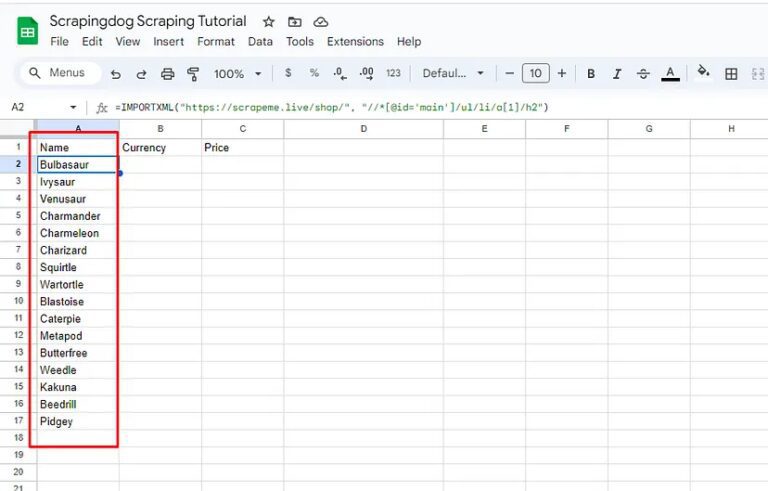
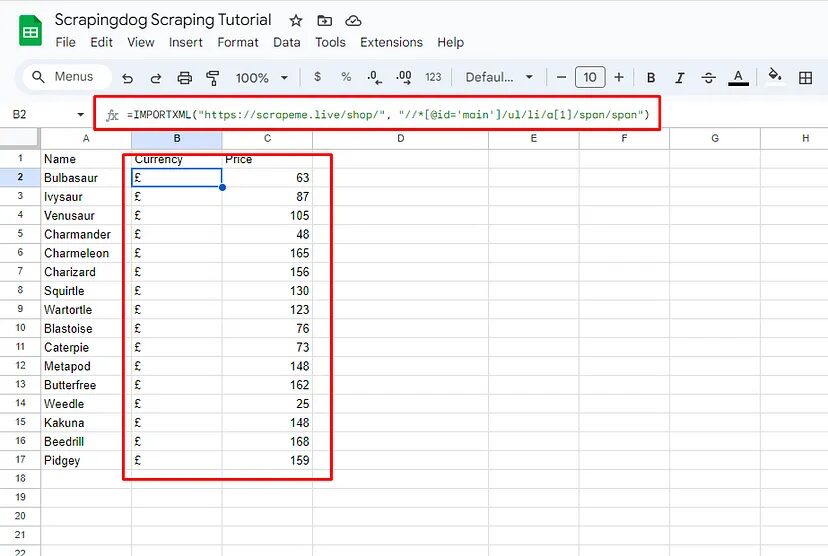
=IMPORTXML("https://scrapeme.live/shop/", "//*[@id='main']/ul/li/a[1]/h2")
xpath_query for all the price tags will be //*[@id=’main’]/ul/li/a[1]/span/span.
=IMPORTXML("https://scrapeme.live/shop/", "//*[@id='main']/ul/li/a[1]/span/span")
Let’s apply this to our currency column.
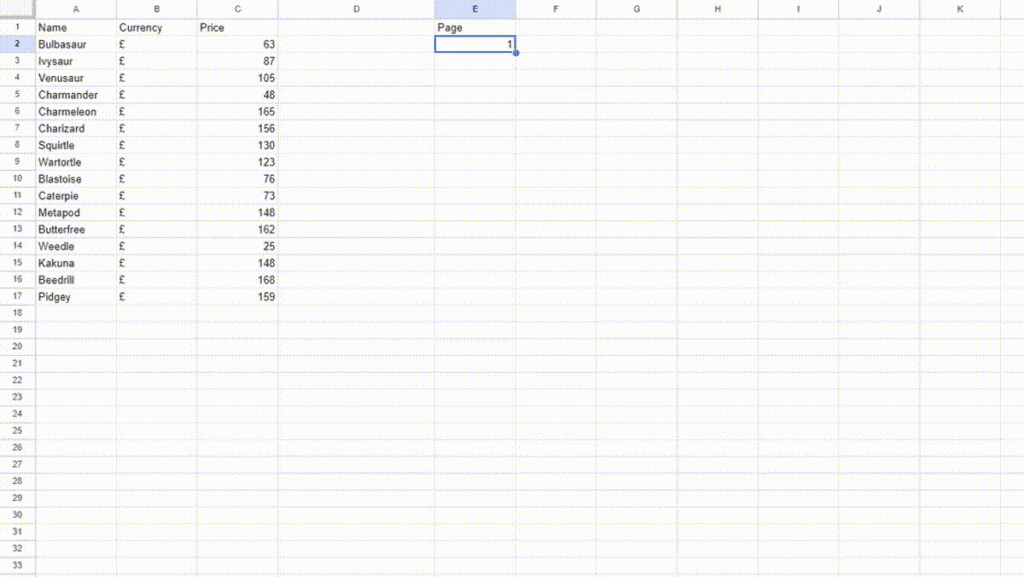
Let’s see whether we can scale this process by scraping more than one page. When you click on the II page by scrolling down you will notice that the website URL changes to https://scrapeme.live/shop/page/2/ and when you click on the III page the URL changes to https://scrapeme.live/shop/page/3/. We can see the pattern that the number after page/ increases by 1 on every click. This much information is enough for us to scale our current scraping process.
Create another column Page in your spreadsheet.
We have to make our target URL dynamic so that it can pick the page value from the E2 cell. This can be done by changing our target URL to this.
"https://scrapeme.live/shop/page/"&E2
Remember you have to change the target URL to the above URL for both the Name and Price columns. Now, the target URL changes based on the value you provide to the E2 cell.
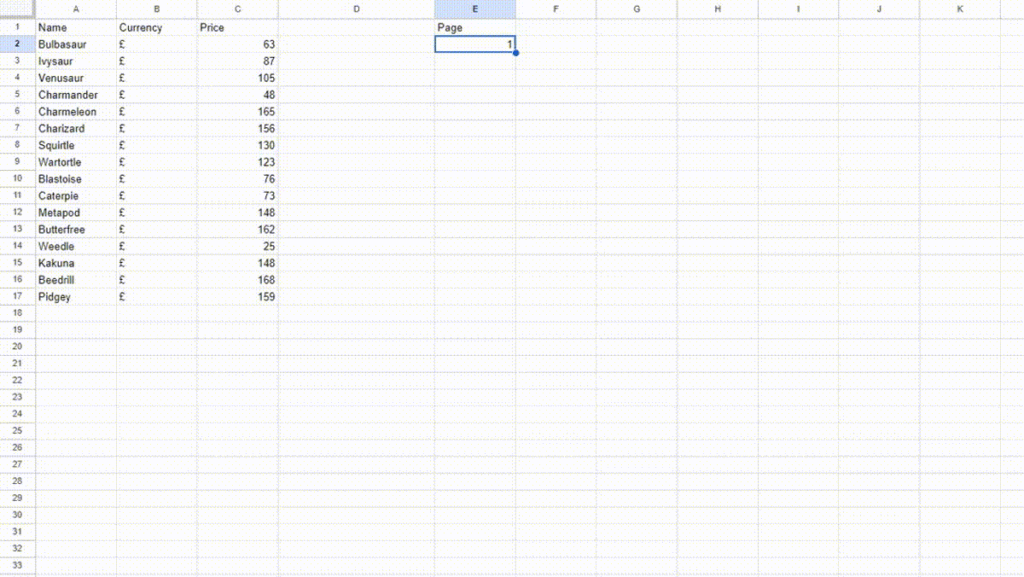
This is how you can scale the web scraping process by concatenating the static part of the URL with the cell reference containing the dynamic part.
Scraping with IMPORTHTML
Create another sheet within your current spreadsheet by clicking the plus button at the bottom.
For this section, we are going to use https://en.wikipedia.org/wiki/World_War_II_casualties as our target URL. We are going to pull country-wise data from this table.
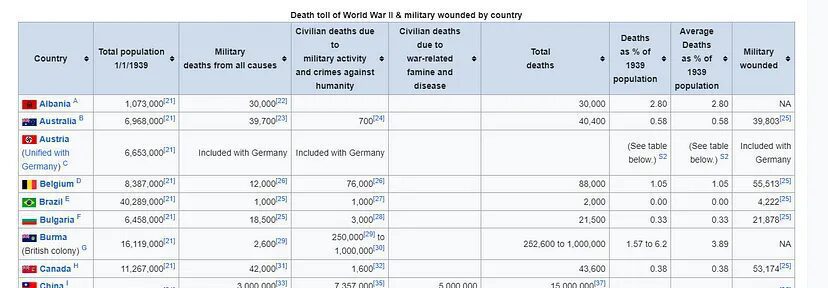
=IMPORTHTML("https://en.wikipedia.org/wiki/World_War_II_casualties", "table", 1)
The above function will pull this data.
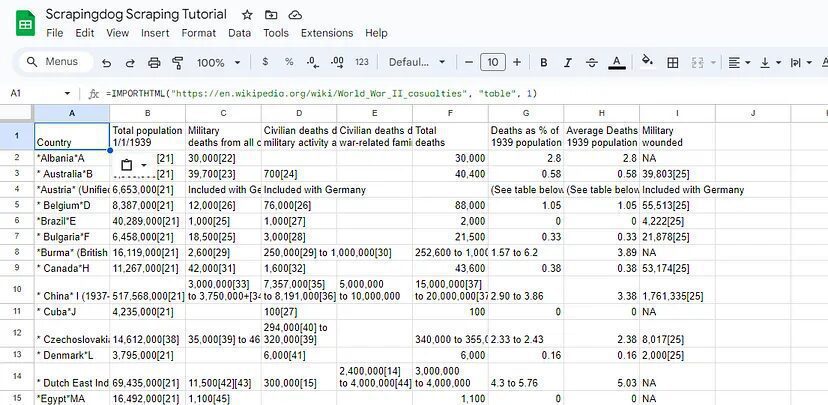
This function helps you quickly import the data from a table.
Overall, IMPORTHTML is a versatile function that can save you time and effort by automating the process of importing data from HTML tables or lists on web pages directly into your Google Sheets. It’s especially useful for tasks that involve data scraping, reporting, analysis, and monitoring of external data sources.
However, IMPORTHTML may not always format imported data as expected. This can result in inconsistent formatting or unexpected changes to the data once it’s imported into Google Sheets. Users may need to manually adjust formatting or use additional formulas to clean up the imported data.
Limitations of using IMPORTXML and IMPORTHTML
IMPORTXMLandIMPORTHTMLare designed for simple data extraction tasks and may not support advanced scraping requirements such as interacting with JavaScript-generated content, handling dynamic web pages, or navigating complex website structures.- Google Sheets imposes rate limits on the frequency and volume of requests made by
IMPORTXMLandIMPORTHTMLfunctions. Exceeding these limits can result in errors, delays, or temporary suspensions of the functions. This makes it challenging to scrape large volumes of data or scrape data from multiple websites rapidly. - Imported data may require additional formatting, cleaning, or transformation to make it usable for analysis or integration with other systems. This can introduce complexity and overhead, particularly when dealing with inconsistent data formats or messy HTML markup.
An alternative to scraping with Google Sheets – Scrapingdog
As discussed above, scraping with Google Sheets at scale has many limitations, and Scrapingdog can help you bypass all of those limitations.
Recently, we have introduced an add-on to Google Sheets that helps all non-coders to scrape data from different platforms.
Here is how you install this: go to extensions, search for Scrapingdog, and finally install the add-on.
Not A Developer? Scrapingdog Can Help You Extract Data in Your Desired Format
Contact us Today with Your Needs & Our Team Will Connect You Shortly!!

Once done, you can use different scrapers from Scrapingdog that are there. To know more about them you can refer to our blogs:
Conclusion
We’ve explored the capabilities of IMPORTXML and IMPORTHTML functions in Google Sheets for web scraping. They provide a convenient and accessible way to extract data from websites directly into your spreadsheets, eliminating the need for complex coding or specialized software.
However, it’s important to be mindful of the limitations of IMPORTXML and IMPORTHTML, such as rate limits, HTML structure dependencies, and data formatting challenges. And for those, you can always use Scrapingdog’s Web Scraping APIs to scale your data extraction.
If you need any help integrating our APIs in your workflow, we are ready available to help you out on chat.


