TL;DR
- Python guide to scrape Yahoo Finance.
- Using
requests+BeautifulSoupto fetch data via Scrapingdog to avoid blocks (1,000 free credits). - Extracting key stats like price, ranges, volume, market cap, PE, EPS from the quote page.
- Finally building a simple JSON of the fields for downstream analysis.
Web scraping financial data is done widely around the globe today. With Python being a versatile language, it can be used for a wide variety of tasks.
In this blog post, we’ll scrape Yahoo Finance from the web using the Python programming language.
We’ll go over some of the basics of web scraping, and then we’ll get into how to scrape financial data specifically. We’ll also talk about some of the challenges in it, and how to overcome them.
We will code a scraper for extracting data from Yahoo Finance. As you know, I like to make things pretty simple; for that, I will also be using a web scraper, which will increase your scraping efficiency.
Why use a web scraper? This tool will help us to scrape dynamic websites using millions of rotating proxies so that we don’t get blocked. It also provides a captcha-clearing facility. It uses headerless Chrome to scrape dynamic websites.
Know More: Why Price Scraping is Done!!
Why Scrape Stock data from Yahoo Finance?
There are a number of reasons why you might want to scrape financial data from Yahoo Finance. Perhaps you’re trying to track the performance of a publicly traded company, or you’re looking to invest.
I have also scraped Nasdaq & scraped Google Finance in my other blogs, do check it out too if you are looking to extract data from it. In any case, gathering this data can be a tedious and time-consuming process.
That’s where web scraping comes in. By writing a simple Python script, you can automate the task of extracting data. Not only will this save you time, but it will also allow you to gather data more frequently, giving you a more up-to-date picture of a company’s financial health.
Requirements for Scraping Yahoo Finance
Generally, web scraping is divided into two parts:
- Fetching data by making an HTTP request
- Extracting important data by parsing the HTML DOM
Libraries & Tools
- Beautiful Soup is a Python library for pulling data out of HTML and XML files. BeautifulSoup is a library for parsing HTML and XML documents. It provides a number of methods for accessing and manipulating the data in the document. We’ll be using the BeautifulSoup library to parse the HTML document that we get back from the website.
- Requests allow you to send HTTP requests very easily. Requests is a library that allows you to send HTTP requests. We’ll be using the requests library to make a GET request to the website that we want to scrape.
- Web scraping tools like Scrapingdog that extract the HTML code of the target URL.
Putting it all together
Now that we’ve seen how to use the BeautifulSoup and requests libraries, let’s see how to put it all together to scrape Yahoo Finance.
We’ll start by making a GET request to the website that we want to scrape. We’ll then use the BeautifulSoup library to parse the HTML document that we get back. Finally, we’ll extract the data that we want from the parsed document.
Setup
Our setup is pretty simple. Just create a folder and install Beautiful Soup & requests. For creating a folder and installing libraries type below given commands. I am assuming that you have already installed Python 3.x.
mkdir scraper
pip install beautifulsoup4
pip install requests
Now, create a file inside that folder by any name you like. I am using scraping.py. Firstly, you have to sign up for the scrapingdog API. It will provide you with 1000 FREE credits. Then just import Beautiful Soup & requests in your file. like this.
What we are going to scrape from Yahoo Finance
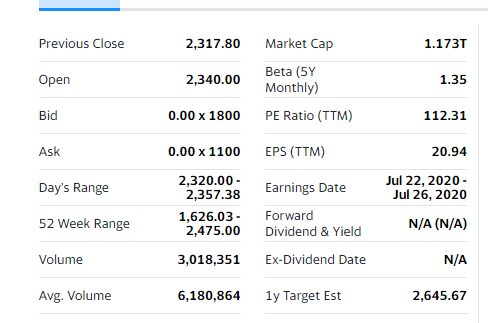
Here is the list of fields we will be extracting:
- Previous Close
- Open
- Bid
- Ask
- Day’s Range
- 52 Week Range
- Volume
- Avg. Volume
- Market Cap
- Beta
- PE Ratio
- EPS
- Earnings Rate
- Forward Dividend & Yield
- Ex-Dividend & Date
- 1y target EST
Preparing the Food
Now, since we have all the ingredients to prepare the scraper, we should make a GET request to the target URL to get the raw HTML data. If you are not familiar with the scraping tool, I would urge you to go through its documentation. Now we will scrape Yahoo Finance for financial data using the requests library as shown below.
r = requests.get("https://api.scrapingdog.com/scrape?api_key=5ea541dcacf6581b0b4b4042&url=https://finance.yahoo.com/quote/AMZN?p=AMZN").text
This will provide you with an HTML code of that target URL. Now, you have to use BeautifulSoup to parse HTML.
soup = BeautifulSoup(r,’html.parser’)
Now, on the entire page, we have four “tbody” tags. We are interested in the first two because we currently don’t need the data available inside the third & fourth “tbody” tags.
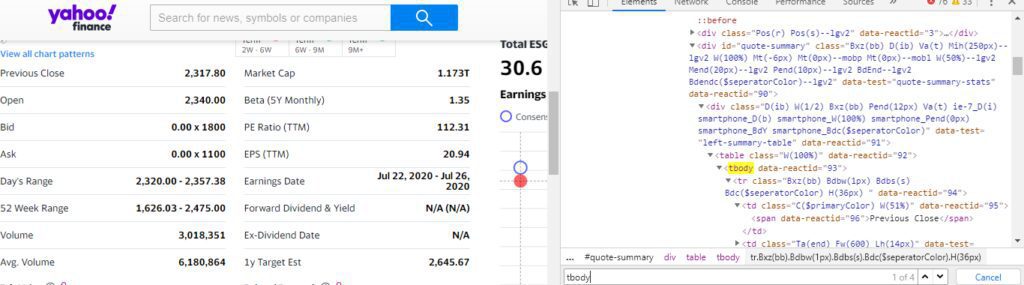
First, we will find out all those “tbody” tags using variable “soup”.
alldata = soup.find_all(“tbody”)

As you can notice that the first two “tbody” has 8 “tr” tags and every “tr” tag has two “td” tags.
try:
table1 = alldata[0].find_all(“tr”)
except:
table1=None
try:
table2 = alldata[1].find_all(“tr”)
except:
table2 = None
Now, each “tr” tag has two “td” tags. The first td tag consists of the name of the property and the other one has the value of that property. It’s something like a key-value pair.

At this point, we are going to declare a list and a dictionary before starting a for loop.
l={}
u=list()
For making the code simple I will be running two different “for” loops for each table. First for “table1”
for i in range(0,len(table1)):
try:
table1_td = table1[i].find_all(“td”)
except:
table1_td = None
l[table1_td[0].text] = table1_td[1].text
u.append(l)
l={}
Now, what we have done is we are storing all the td tags in a variable “table1_td”. And then we are storing the value of the first & second td tag in a “dictionary”. Then we are pushing the dictionary into a list. Since we don’t want to store duplicate data we are going to make the dictionary empty at the end. Similar steps will be followed for “table2”.
for i in range(0,len(table2)):
try:
table2_td = table2[i].find_all(“td”)
except:
table2_td = None
l[table2_td[0].text] = table2_td[1].text
u.append(l)
l={}
Then at the end when you print the list “u” you get a JSON response.
{
“Yahoo finance”: [
{
“Previous Close”: “2,317.80”
},
{
“Open”: “2,340.00”
},
{
“Bid”: “0.00 x 1800”
},
{
“Ask”: “2,369.96 x 1100”
},
{
“Day’s Range”: “2,320.00–2,357.38”
},
{
“52 Week Range”: “1,626.03–2,475.00”
},
{
“Volume”: “3,018,351”
},
{
“Avg. Volume”: “6,180,864”
},
{
“Market Cap”: “1.173T”
},
{
“Beta (5Y Monthly)”: “1.35”
},
{
“PE Ratio (TTM)”: “112.31”
},
{
“EPS (TTM)”: “20.94”
},
{
“Earnings Date”: “Jul 23, 2020 — Jul 27, 2020”
},
{
“Forward Dividend & Yield”: “N/A (N/A)”
},
{
“Ex-Dividend Date”: “N/A”
},
{
“1y Target Est”: “2,645.67”
}
]
}
Isn’t that amazing?
We managed to scrape Yahoo Finance in just 5 minutes of setup. We have an array of Python objects containing the financial data of the company Amazon. In this way, we can scrape the data from any website.
The Benefits of Scraping Yahoo Finance with Python
- Python is a versatile scripting language that is widely used in many different programming contexts.
- Python’s “requests” and “BeautifulSoup” libraries make it easy to download and process web pages for data scraping purposes.
- Python can be used to scrap financial statements from websites quickly and efficiently.
- The data from financial statements can be used for various financial analyses and research purposes.
- Python’s “pandas” library provides excellent tools for data analysis and manipulation, making it ideal for use with financial data.
Thus, Python is an excellent tool for scraping financial statements from websites. It is quick, efficient, and versatile, making it a great choice for those looking to gather data for financial analysis and research.
Key Takeaways
The blog explains how Yahoo Finance data such as stock prices, charts, and company financials can be extracted programmatically.
It highlights why manual data collection from Yahoo Finance does not scale and often leads to incomplete or outdated datasets.
The article shows how using a scraping API helps handle dynamic content, request limits, and blocking issues on Yahoo Finance.
It demonstrates how structured financial data can be collected in a clean format for analysis, tracking, or automation.
The post emphasizes use cases like building financial dashboards, monitoring stock performance, and conducting market research.
Conclusion
Forget about getting blocked while scraping the Web
Try out Scrapingdog Web Scraping API & Scrape Yahoo Finance at Scale without Getting Blocked
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey: