TL;DR
- Step-by-step Python scrape of Yelp business details (name, address, rating, phone).
- Uses
requests+BeautifulSoup: fetch HTML → parse → output JSON; full script included. - Works for small runs; for scale / anti-bot reliability, switch the fetch to Scrapingdog’s Web Scraping API and keep the same parsing.
Yelp is a platform that gathers customer opinions about businesses. It started in 2004 and helps people see what real customers think about local businesses. It ranks as the 44th most visited website & has over 184 million reviews. (source)
As of now, there are more than 5 million businesses listed on Yelp, making it a valuable resource for finding information about these businesses. To extract details from any listing from Yelp there are different ways.
For the sake of this tutorial, we’ll use Python to extract business listing details from Yelp.
Requirements For Scraping Yelp Data
Generally, web scraping is divided into two parts:
- Fetching data by making an HTTP request
- Extracting important data by parsing the HTML DOM
Libraries & Tools
- Beautiful Soup is a Python library for pulling data out of HTML and XML files.
- Requests allow you to send HTTP requests very easily.
- Web scraping API extracts the HTML code of the target URL.
Know more: Learn Web Scraping 101 with Python!!
Setup
Our setup is pretty simple. Just create a folder and install BeautifulSoup & requests. For creating a folder and installing libraries, type the below-given commands. I assume that you have already installed Python 3. x (The latest version is 3.9 as of April 2022).
mkdir scraper
pip install beautifulsoup4
pip install requests
Now, create a file inside that folder by any name you like. I am using scraping.py.
from bs4 import BeautifulSoup
import requests
Data Points We Are Going To Scrape From Yelp
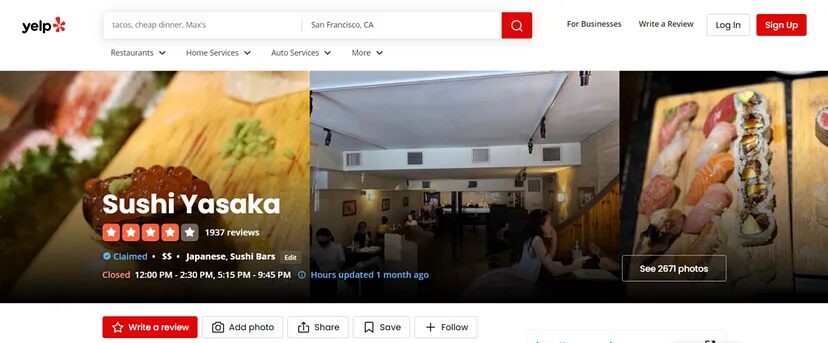
We are going to scrape data from this restaurant.
We will extract the following information from our target page.
- Name of the Restaurant
- Address of the Restaurant
- Rating
- Phone number
Let’s Start Scraping
Now, since we have all the ingredients to prepare the scraper, we should make a GET request to the target URL to get the raw HTML data.
We will scrape Yelp data using the requests library below.
from bs4 import BeautifulSoup
import requests
l={}
u=[]
r = requests.get('https://www.yelp.com/biz/sushi-yasaka-new-york').text
This will provide you with an HTML code of that target URL. If the status code of this request is 200 then we are going to parse the data out of it.
Parsing the raw HTML
Now we will use BS4 to extract the information we need. But before this, we have to find the DOM location of each data element. We will take advantage of Chrome developer tools to find the location.
Let’s start with the name first.

So, the name is located inside the h1 tag with the class y-css-olzveb.
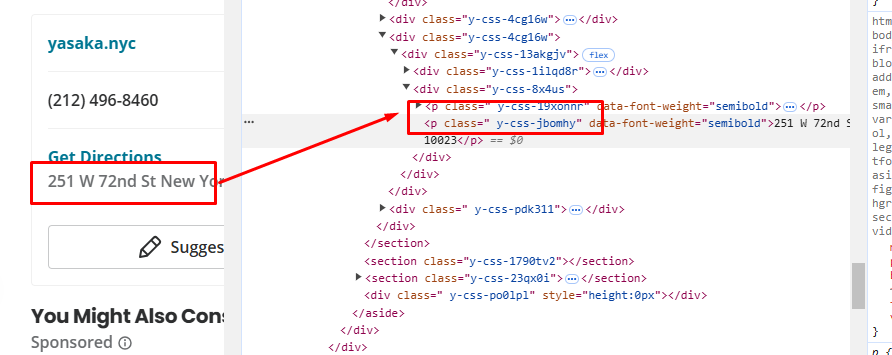
Similarly, the address can be found inside the p tag with the class y-css-jbomhy from the image above.

The star rating can be found in the div tag with the class y-css-f0t6x4. Inside this class, there is an attribute aria-label inside which this star rating is hidden.
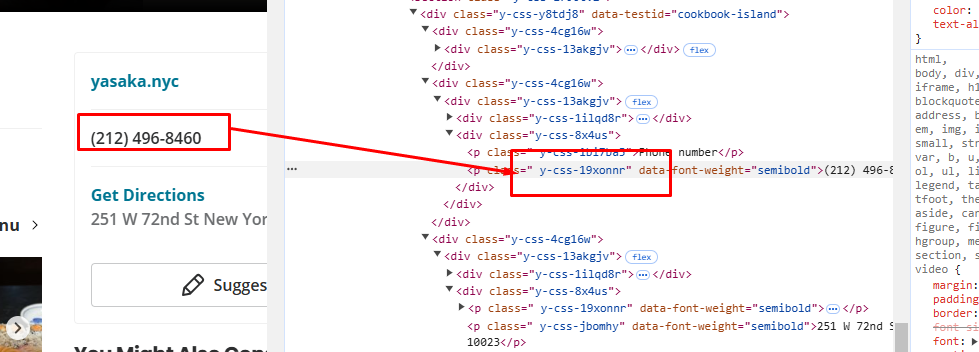
The phone number is located inside the second div tag with the class y-css-4cg16w.
Now, we have the location of each data point we want to extract from the target page. Let’s now use BS4 to parse this information.
soup = BeautifulSoup(r,'html.parser')
Here we have created a beautifulSoup object.
try:
l["name"]=soup.find("h1",{"class":"y-css-olzveb"}).text
except:
l["name"]=None
try:
l["address"]=soup.find("p",{"class":"y-css-jbomhy"}).text
except:
l["address"]=None
try:
l["stars"]=soup.find("div",{"class":"y-css-f0t6x4"}).get('aria-label').replace(" star rating","")
except:
l["stars"]=None
try:
l["phone"]=soup.find("section",{"class":"y-css-1790tv2"}).find_all("div",{"class":"y-css-4cg16w"})[1].text.replace("Phone number","")
except:
l["phone"]=None
u.append(l)
l={}
print({"data":u})
Once you run the above code you will get this output on your console.
{'data': [{'name': 'Sushi Yasaka', 'address': '251 W 72nd St New York, NY 10023', 'stars': '4.2', 'phone': '(212) 496-8460'}]}
There you go!
We have the Yelp data ready to manipulate and maybe store somewhere like in MongoDB. But that is out of the scope of this tutorial.
Complete Code
You can scrape other information like reviews, website addresses, etc from the raw HTML we downloaded in the first step. But for now, the code will look like this.
from bs4 import BeautifulSoup
import requests
l={}
u=[]
r = requests.get('https://www.yelp.com/biz/sushi-yasaka-new-york').text
soup = BeautifulSoup(r,'html.parser')
try:
l["name"]=soup.find("h1",{"class":"y-css-olzveb"}).text
except:
l["name"]=None
try:
l["address"]=soup.find("p",{"class":"y-css-jbomhy"}).text
except:
l["address"]=None
try:
l["stars"]=soup.find("div",{"class":"y-css-f0t6x4"}).get('aria-label').replace(" star rating","")
except:
l["stars"]=None
try:
l["phone"]=soup.find("section",{"class":"y-css-1790tv2"}).find_all("div",{"class":"y-css-4cg16w"})[1].text.replace("Phone number","")
except:
l["phone"]=None
u.append(l)
l={}
print({"data":u})
How to scrape Yelp without getting blocked?
Scrapingdog’s API for web scraping can help you extract data from Yelp at scale without getting blocked. You just have to pass the target url and Scrapingdog will create an unbroken data pipeline for you, that too without any blockage.
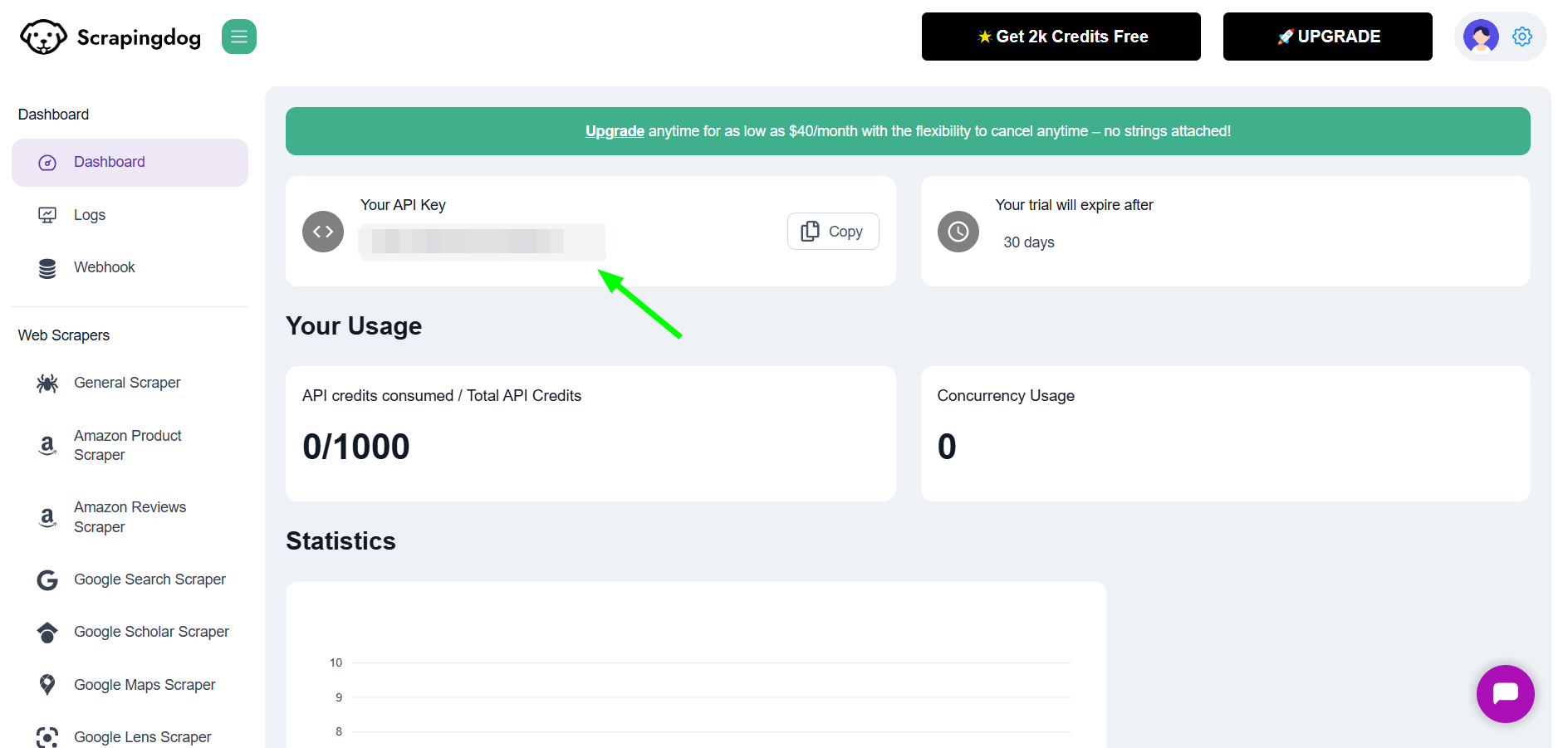
You have to use this API key in the below provided code.
from bs4 import BeautifulSoup
import requests
l={}
u=[]
key='your-api-key'
r = requests.get(f"https://api.scrapingdog.com/scrape?dynamic=false&api_key={key}&url=https://www.yelp.com/biz/sushi-yasaka-new-york")
soup = BeautifulSoup(r.text,'html.parser')
print(r.status_code)
try:
l["name"]=soup.find("h1",{"class":"y-css-olzveb"}).text
except:
l["name"]=None
try:
l["address"]=soup.find("p",{"class":"y-css-jbomhy"}).text
except:
l["address"]=None
try:
l["stars"]=soup.find("div",{"class":"y-css-f0t6x4"}).get('aria-label').replace(" star rating","")
except:
l["stars"]=None
try:
l["phone"]=soup.find("section",{"class":"y-css-1790tv2"}).find_all("div",{"class":"y-css-4cg16w"})[1].text.replace("Phone number","")
except:
l["phone"]=None
u.append(l)
l={}
print({"data":u})
As you can see the code is the same except the target url. With the help of Scrapingdog, you can scrape endless data from Yelp.
Key Takeaways:
Yelp contains valuable business and review data useful for analytics, lead generation, and sentiment analysis.
Basic Python scraping (requests + HTML parsing) can extract data but often gets blocked.
Common data points include business name, address, rating, reviews, and contact details.
Yelp uses anti-bot protections, making large-scale scraping challenging.
Using a scraper API simplifies proxy rotation, CAPTCHA handling, and scalable data extraction.
Conclusion
In this step-by-step guide, you’ve gained a comprehensive understanding of how to create a Python scraper capable of retrieving Yelp data efficiently. As demonstrated throughout this tutorial, the process is surprisingly straightforward.
Additionally, you’ve explored an alternative approach using the Web Scraping API, which can help bypass anti-bot protection mechanisms and extract Yelp data with ease. The techniques outlined in this article not only apply to Yelp but can also be employed to scrape data from similarly complex websites without the risk of being blocked.
Happy Scraping!!


