TL;DR
- Step-by-step Python scrape of Zillow using
requests+BeautifulSoup. - Extracts price, size, and address from listing cards.
- Fine for small runs; expect IP blocks at scale.
- For production, use Scrapingdog’s Web Scraping API (proxies, headless, retries); includes 1,000 free credits to test.
Scraping Zillow is one of the easiest ways to analyze the market of properties in your desired area. According to similarweb Zillow has an estimated user visits of 348.4 Million per month.
Over time this number will increase and more and more people will be registering their properties over it. Hence, scraping Zillow can get you some valuable insights.
Well, then how to scrape Zillow? There are various other methods you can use for Zillow scraping. However, for the sake of this blog, we will be using Python.
Let’s Get Started!!
Why Scrape Zillow Data using Python?
Python has many libraries for web scraping that are easy to use and well-documented. That doesn’t mean that other programming languages have bad documentation or anything else, but Python gives you more flexibility.
You can do countless things with Python, from scraping Google search results to price scraping.
With all this, you get great community support and many forums to solve any issue you might face in your Python journey.
When you are extracting data from the web then starting with Python will help you collect data in no time and it will also boost your confidence especially if you are a beginner.
Some of the best Python forums that I suggest are:
Prerequisites
zillow. Now, inside this folder create a python file zillow.py and install two libraries requests and BeautifulSoup.
mkdir scraper
pip install requests
pip install beautifulsoup4
Let’s Scrape Zillow Data using Python!
- The first step would be to download the raw HTML from the target page using the requests library.
- The second step will be to parse the data using the BeautifulSoup library.
Downloading raw HTML
Our target page will be this and from this page, we are going to extract the price, size, and address of each property. Before coding let’s find the DOM location of each element.
All of these properties are part of a list that has a class name ListItem-c11n-8–109–3__sc-13rwu5a-0. You can find that by inspecting the element.
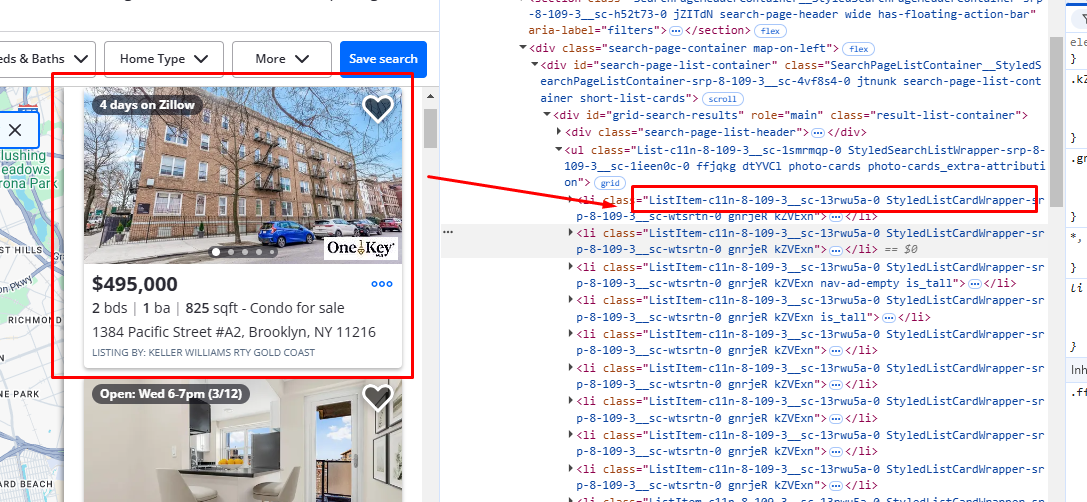
There are almost 42 properties listed on this page. Let’s check where our target data elements are stored.
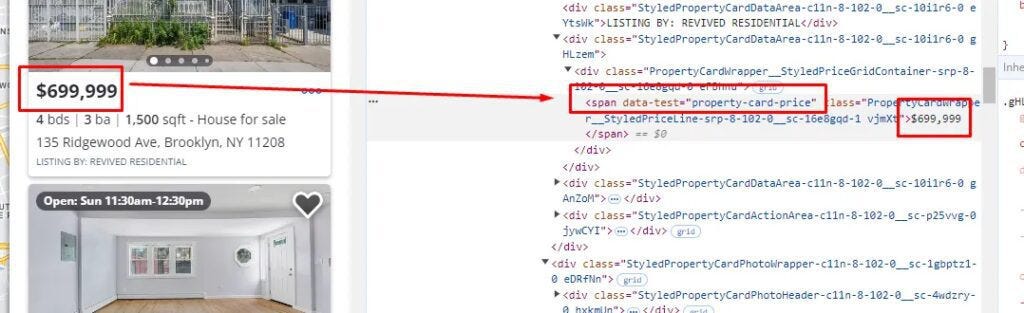
As you can see the price tag is stored in the class span tag with attribute data-test and value property-card-price.
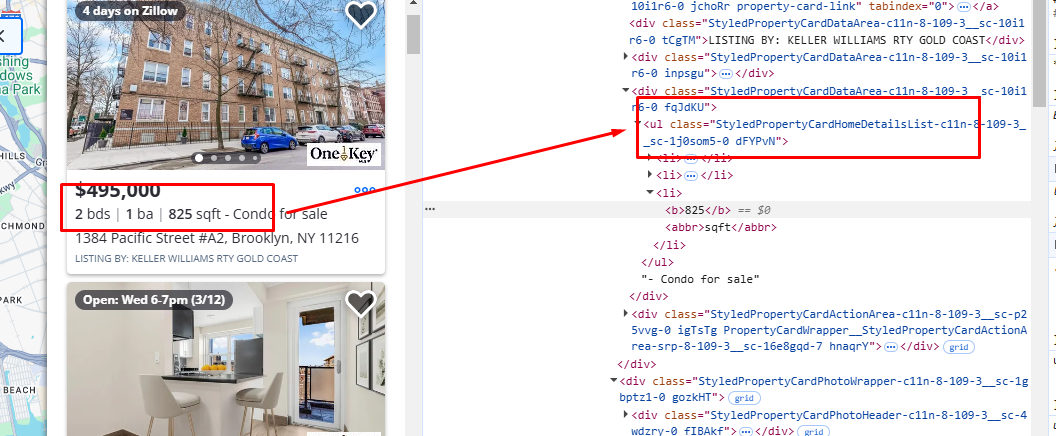
Similarly, you can see that the property size is located inside a ul tag with the class StyledPropertyCardHomeDetailsList-c11n-8–109–3__sc-1j0som5–0.
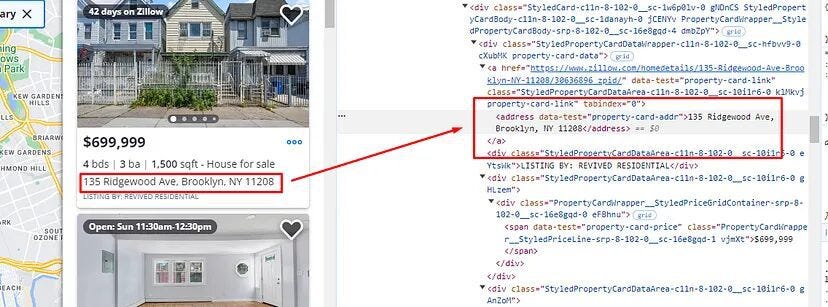
The address is located inside the address tag.
We have all the ingredients to make a great Zillow scraper. Let’s code!
import requests
from bs4 import BeautifulSoup
l=list()
obj={}
target_url = "https://www.zillow.com/homes/for_sale/Brooklyn,-New-York,-NY_rb/"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36","Accept-Language":"en-US,en;q=0.9","Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9","Accept-Encoding":"gzip, deflate, br","upgrade-insecure-requests":"1"}
resp = requests.get(target_url, headers=headers)
print(resp.status_code)
The above code is pretty simple but let me explain it to you step by step.
- First, we have imported the required libraries i.e. requests and BS4.
- Then empty list l and an object obj are declared.
target_urlis declared which holds our target Zillow web page.headersis declared which will be passed to the requests library. This will help us make our request look more authentic.- Finally, we are checking whether the status code is
200or not with aprintstatement. If it is200then we can proceed ahead with our second and final step of parsing.
After running the code I got 200.

Parsing with BS4
resp=resp.text
soup = BeautifulSoup(resp,'html.parser')
properties = soup.find_all("li",{"class":"ListItem-c11n-8-102-0__sc-13rwu5a-0"})
Here I have created a BeautifulSoup object. Then we will find all the property boxes using the find_all() method.
for x in range(0,len(properties)):
try:
obj["pricing"]=properties[x].find("span",{'data-test':'property-card-price'}).text
except:
obj["pricing"]=None
try:
obj["size"]=properties[x].find("ul",{"class":"StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0"}).find_all('li')[-1].text
except:
obj["size"]=None
try:
obj["address"]=properties[x].find("address").text
except:
obj["address"]=None
l.append(obj)
obj={}
print(l)
After finding all the properties we will run a for loop through which we are going to extract information like price, size, and address.
Once the parsing is over we push all the results to a list l. When you run the code you will get these results:
[
{
'pricing': '$599,900',
'size': '8 bds4 ba3,198 sqft',
'address': '119 Rockaway Parkway, Brownsville, NY 11212'
},
{
'pricing': '$550,000',
'size': '4 bds2 ba1,835 sqft',
'address': '1046 E 102nd Street, Canarsie, NY 11236'
}
...
Finally, we were able to scrape Zillow and parse important results from it. However, this approach has a limitation. This approach will not work if you want to scrape millions of pages from Zillow. Zillow will ban your IP and all of your requests will be blocked. Resulting in the blockage of your data pipeline.
To avoid this situation you should use Web Scraping API like Scrapingdog. Scrapingdog will handle all the proxies, headless browsers, and all the retries so that you can focus on data collection.
Once you sign up for Scrapingdog’s free pack, you will receive 1000 free credits, which you can use to test the service easily.
Scraping Zillow with Scrapingdog
Once you sign up you will be redirected to your dashboard where you can find your API Key at the top. API key helps to identify the user. You need this while making the GET request to Scrapingdog.
The code will remain the same as used in the earlier section. Just the target URL will change as it will be replaced with Scrapingdog’s API.
import requests
from bs4 import BeautifulSoup
l=list()
obj={}
target_url = "https://www.zillow.com/homes/for_sale/Brooklyn,-New-York,-NY_rb/"
resp = requests.get("https://api.scrapingdog.com/scrape", params={
'api_key': 'your-api-key',
'url': target_url,
'dynamic': 'false',
})
print(resp.status_code)
soup = BeautifulSoup(resp.text,'html.parser')
properties = soup.find_all("li",{"class":"ListItem-c11n-8-102-0__sc-13rwu5a-0"})
for x in range(0,len(properties)):
try:
obj["pricing"]=properties[x].find("span",{'data-test':'property-card-price'}).text
except:
obj["pricing"]=None
try:
obj["size"]=properties[x].find("ul",{"class":"StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0"}).find_all('li')[-1].text
except:
obj["size"]=None
try:
obj["address"]=properties[x].find("address").text
except:
obj["address"]=None
l.append(obj)
obj={}
print(l)
Once you run the code you will get this result.

Scraping Zillow without Creating Parsing Logic using Scrapingdog's AI Query Parameter
Once you extact the data from Zillow, you would need to also create parser for it. And the logic would totally depend upon the Zillow tags.
But think of it, if Zillow changes its tags overnight?
Your data pipeline will break, of course!
Using the AI query parameter (documentation) in our Data extraction API, you can just prompt the data points you need to get in lets’s suppose JSON format & the rest will be done by our API.
Watch how it can be used in this video walkthrough ⬇️
Here are 5 Quick Key Takeaways:
The guide teaches how to scrape Zillow property data like prices, sizes, and addresses using code (e.g., Python or a scraping API).
It explains how to handle Zillow’s anti-scraping protections (like CAPTCHAs and blocks) by using a robust scraping API so you can extract data at scale.
The blog includes example code snippets and setup steps to connect to Zillow pages and parse the HTML for structured property fields.
Using a scraper API (like Scrapingdog’s dedicated Zillow endpoint) lets you bypass common blocking and get clean responses without frequent failures.
The article emphasizes that Zillow is a data-rich site valuable for market research and analysis, but scraping must be done responsibly.
Conclusion
In this post, we built a Zillow scraper using Python & learned how to extract real estate data. Also, we saw how Scrapingdog can help scale this process.
We learned the main difference between normal HTTP requests and JS rendering while web scraping Zillow with Python.
I have also created a list below of famous real-estate websites to help you identify which website needs JS rendering and which does not.

Frequently Asked Questions
What’s the best & economical tool to scrape zillow?
Scrapingdog has a dedicated Zillow Scraper API for extracting data from Zillow at scale and has a faster response rate compared to other APIs available. Check it out & give it a spin to see if it meets your business needs.
Is scraping data from Zillow is Legal?
Yes, it is legal. As long as you are using this data for ethical purposes, you don’t violate any legal policy.


