TL;DR
- Python how-to: scrape a ZoomInfo company page with
requests+BeautifulSoup. - Pull company name, industry, employees, HQ, website, social links (code provided).
- Notes rapid IP bans; recommends switching fetch to Scrapingdog for reliability (1k free credits, >99% success).
- Core parsing unchanged—only the fetch layer swaps for scale.
Scraping ZoomInfo can provide you with market intelligence solutions and a comprehensive company and contact information database. It offers various services and tools that help businesses with sales and marketing efforts, lead generation, account targeting, and customer relationship management (CRM).
In this blog, we are going to learn how we can enrich our CRM panel by scraping Zoominfo. We will use Python for this task.
Setting up the Prerequisites for Scraping ZoomInfo
You will need Python 3.x for this tutorial. I hope you have already installed this on your machine, if not then you can download it from here. We will also need two external libraries of Python.
- Requests– Using this library we will make an HTTP connection with the Zoominfo page. This library will help us to extract/download the raw HTML from the target page.
- BeautifulSoup– This is a powerful data parsing library. Using this we will extract necessary data out of the raw HTML we get using the
requestslibrary.
We will have to create a dedicated folder for this project.
mkdir zoominfo
Now, let’s install the above two libraries.
pip install beautifulsoup4
pip install requests
Inside this folder create a python file where we will write our python script. I am naming the file as zoom.py.
Downloading raw data from zoominfo.com
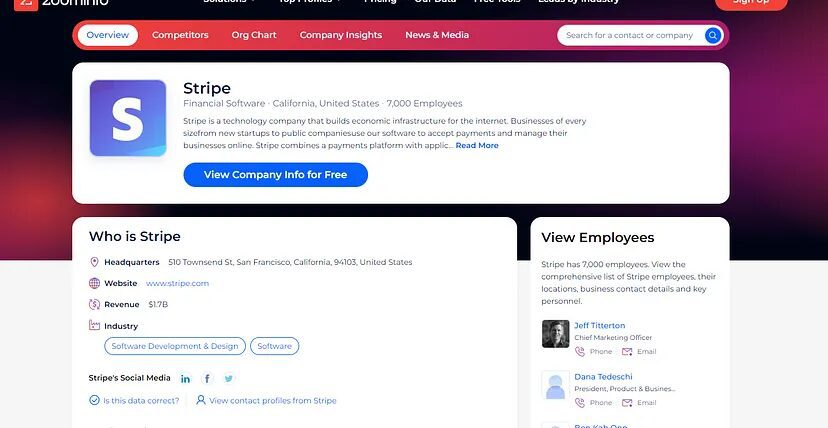
The first step of every scraping task is downloading the raw HTML code from the target page. We are going to scrape the Stripe company page.
import requests
from bs4 import BeautifulSoup
target_url="https://www.zoominfo.com/c/stripe/352810353"
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}
resp = requests.get(target_url,headers=headers,verify=False)
print(resp.content)
1. The required libraries are imported:
requestsis a popular library for making HTTP requests and handling responses.BeautifulSoupis a library for parsing HTML and XML documents, making it easier to extract data from web pages.
2. The target URL is specified:
- The
target_urlvariable holds the URL of the web page to be scraped. In this case, it is set to “https://www.zoominfo.com/c/stripe/352810353“.
3. The user agent header is defined:
- The
headersdictionary is created, and the “User-Agent” header is set to mimic a common web browser. This can help in bypassing certain restrictions or anti-bot measures on websites.
4. The web page is requested:
- The
requests.get()function is used to send an HTTP GET request to thetarget_url. - The
headersparameter is passed to include the user agent header in the request. - The
verify=Falseparameter is used to disable SSL certificate verification. This is sometimes necessary when working with self-signed or invalid certificates, but it is generally recommended to use valid certificates for security purposes.
5. The response content is printed:
- The
resp.contentproperty returns the raw HTML content of the response. - This content is printed to the console using
print().
Once you run this code you should get this output with a status code
What are we going to scrape from Zoominfo?
Scraping zoominfo provides a lot of data for any company and it is always great to decode what exact information we need from the target page.
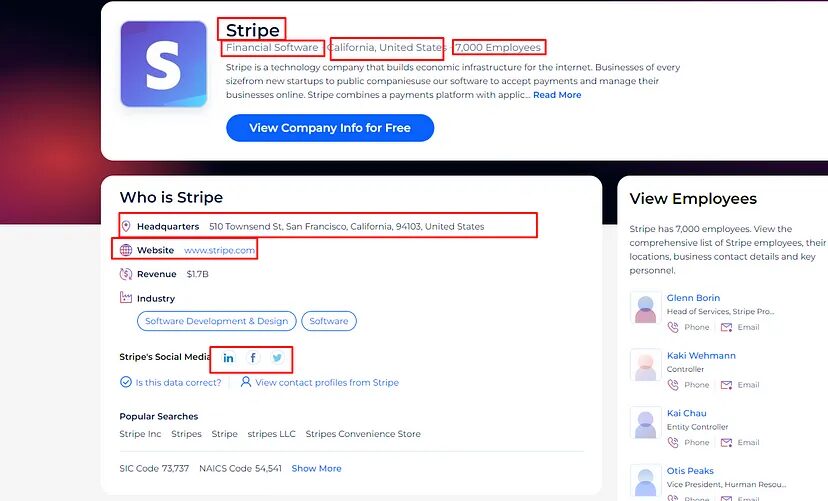
For this tutorial, we will scrape zoominfo for this information.
- Company Name
- Industry
- Number of Employees
- Headquarters Address
- Website
- Social media Links
Since we have already downloaded the raw HTML from the page the only thing left is to extract the above information using BS4.
First, we will analyze the location of each data inside the DOM and then we can take the help of BS4 to parse them out.
Identifying the location of each element
Scraping the Company Name

The company name is stored inside the h1 tag. This can be scraped very easily.
soup=BeautifulSoup(resp.text,'html.parser')
try:
o["company_name"]=soup.find('h1').text
except:
o["company_name"]=None
1. Parsing the HTML content:
- The
BeautifulSoupfunction is called withresp.textas the first argument, which represents the HTML content of the web page obtained in the previous code snippet usingresp.content. - The second argument
'html.parser'specifies the parser to be used byBeautifulSoupfor parsing the HTML content. In this case, the built-in HTML parser is used.
2. Extracting the company name:
- The code then tries to find the company name within the parsed HTML using
soup.find('h1'). - The
soup.find()function searches for the first occurrence of the specified HTML tag, in this case, ‘h1’ (which typically represents the main heading on a webpage). - If a matching ‘h1’ tag is found,
.textis called on it to extract the textual content within the tag, which is assumed to be the company name. - The company name is then assigned to the
o["company_name"]dictionary key.
3. Handling exceptions:
- The code is wrapped in a
try-exceptblock to handle any exceptions that may occur during the extraction of the company name. - If an exception occurs (for example, if there is no ‘h1’ tag present in the HTML content), the
exceptblock is executed. - In the
exceptblock,o["company_name"]is assigned the valueNone, indicating that the company name could not be extracted or was not found.
Scraping the industry and the number of employees

The industry name and the number of employees both are stored inside a p tag with class company-header-subtitle.
try:
o['industry']=soup.find('p',{"class":"company-header-subtitle"}).text.split(".")[0]
except:
o['industry']=None
try:
o['employees']=soup.find('p',{"class":"company-header-subtitle"}).text.split(".")[1].split(".")[1]
except:
o['employees']=None
split() function will help us split the text and separate it from “.”.
Scraping the Address
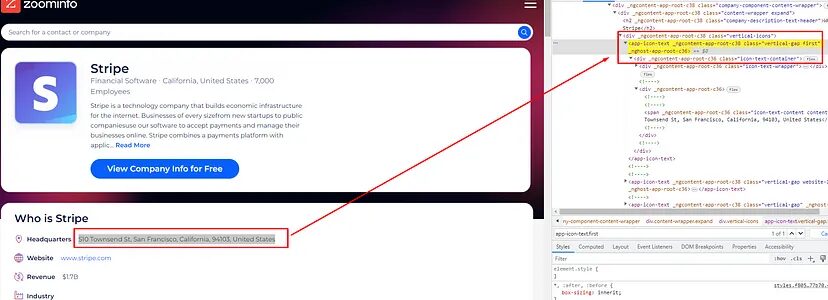
The address is stored inside the span tag and that tag can be found inside the tag app-icon-text with class first.
try:
o['address']=soup.find('app-icon-text',{"class":"first"}).find('span').text
except:
o['address']=None
Scraping the website link

The website link can be found inside the a tag and the a tag is inside app-icon-text tag with the class website-link.
try:
o['website']=soup.find('app-icon-text',{"class":"website-link"}).find('a').text
except:
o['website']=None
Finally, we have managed to extract all the data we decided to earlier in this post.
Complete Code
Of course, you can scrape many more data from Zoominfo. You can even collect email formats from this page to predict the email formats for any company.
import requests
from bs4 import BeautifulSoup
l=[]
o={}
s=[]
target_url="https://www.zoominfo.com/c/stripe/352810353"
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}
resp = requests.get(target_url,headers=headers,verify=False)
print(resp.status_code)
soup=BeautifulSoup(resp.text,'html.parser')
try:
o["company_name"]=soup.find('h1').text
except:
o["company_name"]=None
try:
o['industry']=soup.find('p',{"class":"company-header-subtitle"}).text.split("·")[0]
except:
o['industry']=None
try:
o['employees']=soup.find('p',{"class":"company-header-subtitle"}).text.split("·")[1].split("·")[1]
except:
o['employees']=None
try:
o['address']=soup.find('app-icon-text',{"class":"first"}).find('span').text
except:
o['address']=None
try:
o['website']=soup.find('app-icon-text',{"class":"website-link"}).find('a').text
except:
o['website']=None
try:
mediaLinks = soup.find('div',{'id':'social-media-icons-wrapper'}).find_all('a')
except:
mediaLinks = None
for i in range(0,len(mediaLinks)):
s.append(mediaLinks[i].get('href'))
l.append(o)
l.append(s)
print(l)
Once you run this code you should see this response.

Zoominfo is a well-protected website and your scraper won’t last long as your IP will get banned. IP banning will result in the blocking of your data pipeline. But there is a solution to that too.
Scraping Zoominfo without getting Blocked using Scrapingdog
You can use Scrapingdog’s scraper API to scrape Zoominfo without any restrictions. You can start using it with just a simple sign-up. It offers you a generous 1000 free credits for you to test the service.
Once you sign up you will get your personal API key. You can place that API key in the below code.
import requests
from bs4 import BeautifulSoup
import re
l=[]
o={}
s=[]
target_url="https://api.scrapingdog.com/scrape?api_key=Your-API-Key&url=https://www.zoominfo.com/c/stripe/352810353&dynamic=false"
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}
pattern = r'\b\d+\b'
resp = requests.get(target_url,headers=headers,verify=False)
print(resp.status_code)
soup=BeautifulSoup(resp.text,'html.parser')
try:
o["company_name"]=soup.find('h1').text
except:
o["company_name"]=None
try:
o['industry']=soup.find('p',{"class":"company-header-subtitle"}).text.split("·")[0]
except:
o['industry']=None
try:
o['employees']=soup.find('p',{"class":"company-header-subtitle"}).text.split("·")[1].split("·")[1]
except:
o['employees']=None
try:
o['address']=soup.find('app-icon-text',{"class":"first"}).find('span').text
except:
o['address']=None
try:
o['website']=soup.find('app-icon-text',{"class":"website-link"}).find('a').text
except:
o['website']=None
try:
mediaLinks = soup.find('div',{'id':'social-media-icons-wrapper'}).find_all('a')
except:
mediaLinks = None
for i in range(0,len(mediaLinks)):
s.append(mediaLinks[i].get('href'))
l.append(o)
l.append(s)
print(l)
One thing you might have noticed is the code did not change a bit except the target_url. With this Python code, you will be able to scrape Zoominfo at scale.
Key Takeaways:
The guide explains how to scrape publicly available ZoomInfo data using Python.
It walks through sending HTTP requests to ZoomInfo pages and retrieving the HTML content.
You learn how to parse and extract structured details such as company names and business information.
The tutorial outlines the full scraping workflow, from setup to data extraction.
The scraped data can be used for lead generation, market research, and CRM enrichment.
Conclusion
In this tutorial, we successfully scraped crucial data from Zoominfo. Now, in place of BS4, you can also use lxml but BS4 is more flexible comparatively.
You can create an email-finding tool with the data you get from Zoominfo pages. I have a separate guide on scraping email addresses from any website, you can refer to that too.
You can also analyze the market valuation of any product. There are many applications for this kind of data.
Combination of requests and Scrapingdog can help you scale your scraper. You will get more than a 99% success rate while scraping Zoominfo with Scrapingdog.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on your social media.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:


