
TL;DR
- Beginner guide: scrape JS-heavy pages with Python using Selenium + BeautifulSoup.
- Setup Chrome / Driver, install
selenium&bs4; run headless; wait for content to load. - Demo: open a Walmart search, read
page_source, parse titles / prices, build a JSON list. - Takeaway: render with Selenium, parse with Soup—simple pattern for dynamic sites.
In this post, we will learn how to do Selenium web scraping with Python. Selenium is an open-source automated testing framework used to validate web applications across different browsers and platforms. It was created by Jason Huggins in 2004, a Software Engineer at ThoughtWorks.
He created it when he had to test a web application multiple times, manually leading to higher inefficiency and effort. The Selenium API has the advantage of controlling Firefox and Chrome through an external adaptor. It has a much larger community than Puppeteer. It is an executable module that runs a script on a browser instance & hence is also called Python headless browser scraping.
Why you should use Selenium?
Today selenium is mainly used for web scraping and automation purposes.
- clicking on buttons
- filling forms
- scrolling
- taking a screenshot
Requirements for Web Scraping With Selenium & Python
Generally, web scraping is divided into two parts:
- Fetching data by making an HTTP request
- Extracting important data by parsing the HTML DOM
Libraries & Tools
- Beautiful Soup is a Python library for pulling data out of HTML and XML files.
- Selenium is used to automate web browser interaction from Python.
- Chrome download page
- Chrome driver binary
Setup
- Beautiful Soup is a Python library for pulling data out of HTML and XML files.
- Selenium is used to automate web browser interaction from Python.
- Chrome download page
- Chrome driver binary
mkdir scraper
pip install beautifulsoup4
pip install selenium
Quickstart
Once you have installed all the libraries, create a Python file inside the folder. I am using scraping.py and then importing all the libraries as shown below. Also, import time in order to let the page load completely.
from selenium import webdriver
from bs4 import BeautifulSoup
import time
What We Are Going to Scrape Using Selenium
We are going to extract the Python Book price and title from Walmart via selenium.
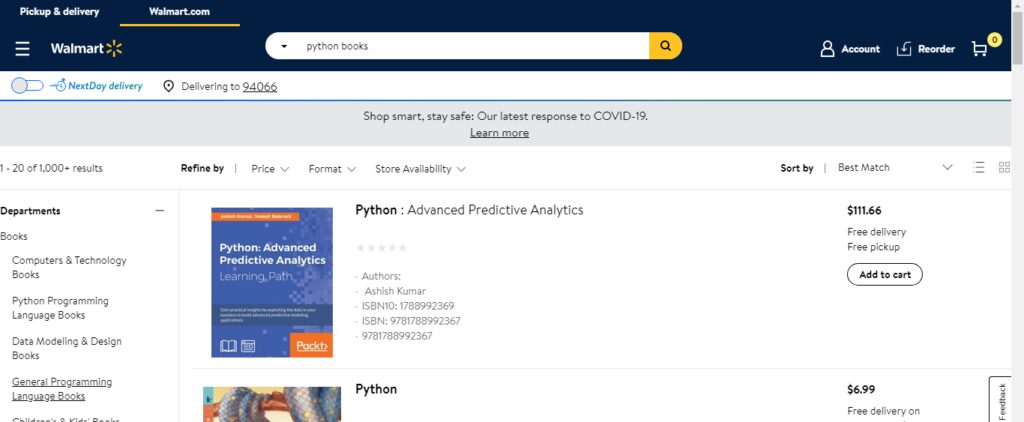
Preparing the Food
Now, since we have all the ingredients to prepare the scraper, we should make a GET request to the target URL to get the raw HTML data.
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome('F:/chromed/chromedriver')
url="https://www.walmart.com/search/?query=python%20books"
A headless chrome will be launched which will be controlled by some external adaptor. Here are two interesting webdriver properties:
driver.stop_clientCalled after executing a quit command.driver.nameReturns the name of the underlying browser for this instance.
Now, to get raw HTML from the website, we have to use BeautifulSoup.
time.sleep(4)
soup=BeautifulSoup(driver.page_source,’html.parser’)
driver.close()
books=list()
k={}
Now, I am letting it sleep for four seconds. The reason behind this is to let the page load completely. Then we will use BeautifulSoup to parse HTML. driver.page_source will return raw HTML from the website.
I have also declared an empty list and dictionary to create a JSON object of the data we are going to scrape.
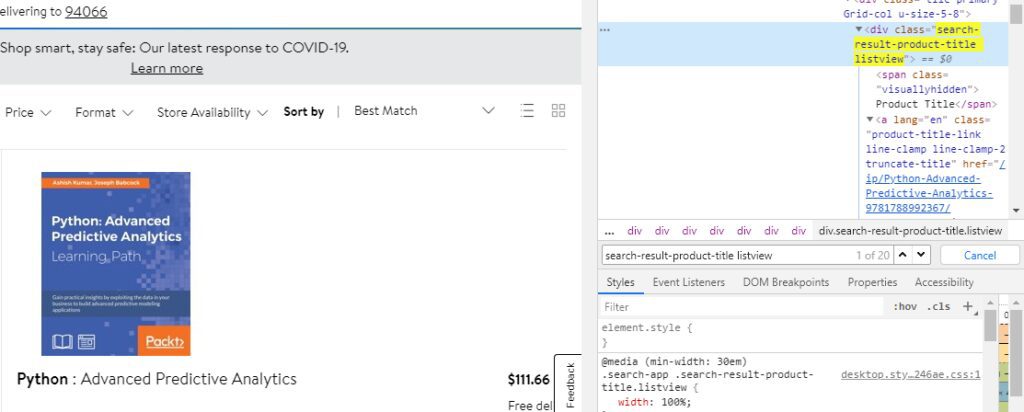
After inspecting the title in chrome developer tools, we can see that the title is stored in a “div” tag with class “search-result-product-title listview”.
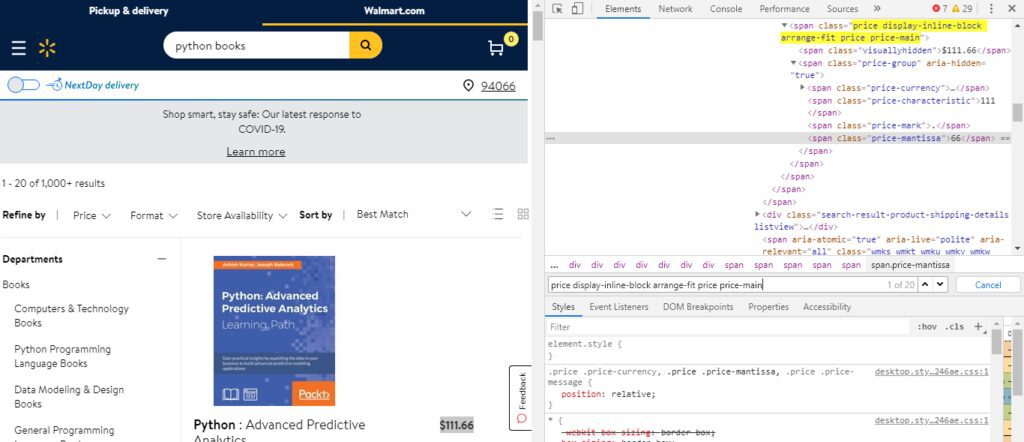
Similarly, the price is stored in “span” tag with class “price display-inline-block arrange-fit price price-main.” Also, we have to dive deep inside this tag to find “visuallyhidden” to find the price in text format.
try:
Title=soup.find_all(“div”,{“class”:”search-result-product-title listview”})
except:
Title=None
try:
Price = soup.find_all(“span”,{“class”:”price display-inline-block arrange-fit price price-main”})
except:
Price=None
We have all the titles and prices stored in a list format in variable Title and Price, respectively. We are going to start a for loop so that we can reach each and every book.
for i in range(0,len(Title)):
try:
k[“Title{}”.format(i+1)]=Title[i].text.replace(“\n”,””)
except:
k[“Title{}”.format(i+1)]=None
try:
k[“Price{}”.format(i+1)]=Price[i].find(“span”,{“class”:”visuallyhidden”}).text.replace(“\n”,””)
except:
k[“Price{}”.format(i+1)]=None
books.append(k)
k={}
So, finally, we have all the prices and titles stored inside the list books. After printing it we got.
{
“PythonBooks”: [
{
“Title1”: “Product TitlePython : Advanced Predictive Analytics”,
“Price1”: “$111.66”
},
{
“Title2”: “Product TitlePython”,
“Price2”: “$6.99”
},
{
“Title3”: “Product TitlePython : Learn How to Write Codes-Your Perfect Step-By-Step Guide”,
“Price3”: “$16.05”
},
{
“Title4”: “Product TitlePython: The Complete Beginner’s Guide”,
“Price4”: “$14.99”
},
{
“Price5”: “$48.19”,
“Title5”: “Product TitlePython : The Complete Reference”
},
{
“Title6”: “Product TitleThe Greedy Python : Book & CD”,
“Price6”: “$10.55”
},
{
“Price7”: “$24.99”,
“Title7”: “Product TitlePython: 2 Manuscripts in 1 Book: -Python for Beginners -Python 3 Guide (Paperback)”
},
{
“Title8”: “Product TitleBooks for Professionals by Professionals: Beginning Python Visualization: Crafting Visual Transformation Scripts (Paperback)”,
“Price8”: “$67.24”
},
{
“Title9”: “Product TitlePython for Kids: A Playful Introduction to Programming (Paperback)”,
“Price9”: “$23.97”
},
{
“Price10”: “$17.99”,
“Title10”: “Product TitlePython All-In-One for Dummies (Paperback)”
},
{
“Title11”: “Product TitlePython Tutorial: Release 3.6.4 (Paperback)”,
“Price11”: “$14.53”
},
{
“Price12”: “$13.58”,
“Title12”: “Product TitleCoding for Kids: Python: Learn to Code with 50 Awesome Games and Activities (Paperback)”
},
{
“Price13”: “$56.10”,
“Title13”: “Product TitlePython 3 Object Oriented Programming (Paperback)”
},
{
“Title14”: “Product TitleHead First Python: A Brain-Friendly Guide (Paperback)”,
“Price14”: “$35.40”
},
{
“Title15”: “Product TitleMastering Object-Oriented Python — Second Edition (Paperback)”,
“Price15”: “$44.99”
},
{
“Title16”: “Product TitlePocket Reference (O’Reilly): Python Pocket Reference: Python in Your Pocket (Paperback)”,
“Price16”: “$13.44”
},
{
“Title17”: “Product TitleData Science with Python (Paperback)”,
“Price17”: “$39.43”
},
{
“Title18”: “Product TitleHands-On Deep Learning Architectures with Python (Paperback)”,
“Price18”: “$29.99”
},
{
“Price19”: “$37.73”,
“Title19”: “Product TitleDjango for Beginners: Build websites with Python and Django (Paperback)”
},
{
“Title20”: “Product TitleProgramming Python: Powerful Object-Oriented Programming (Paperback)”,
“Price20”: “$44.21”
}
]
}
Similarly, you can scrape any JavaScript-enabled website using Selenium and Python. If you don’t want to run these scrapers on your server, try Scrapingdog, a Web Scraping API.
Key Takeaways:
Selenium automates a real browser, making it suitable for scraping JavaScript-heavy websites.
It allows interaction with page elements like clicks, scrolls, form submissions, and dynamic content loading.
WebDriver setup (e.g., ChromeDriver) is required to control the browser instance.
Explicit and implicit waits help manage dynamic elements and avoid timing issues.
Selenium is powerful but slower than lightweight scraping methods, making it better suited for complex sites rather than simple static pages.
Conclusion
In this article, we understood how we could scrape data using Selenium & BeautifulSoup regardless of the type of website. I hope now you feel more comfortable scraping web pages.
If you are new to Python you can read this comprehensive guide on web scraping with Python.
Feel free to comment and ask me anything. You can follow me on Twitter and Medium. Thanks for reading, and please hit the like button!
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:


