
Search engines are the pulse of the internet, they reveal what people are searching for, which brands dominate visibility, and how information trends evolve. Scraping them gives you direct access to this live search intelligence, which can be applied across multiple use cases.
Here’s why businesses and developers scrape search engines:
- Keyword Research & SEO Tracking- Collect SERP data to analyze keyword trends, monitor rankings, and track competitors’ visibility.
- Market & Competitor Insights- Understand how rivals position themselves across search platforms and identify emerging topics or products.

- Content and News Monitoring- Extract real-time updates from search results to feed dashboards or alert systems.
- Data-Driven Applications- Power custom tools like price trackers, sentiment analysis systems, and AI models with fresh, search-based data.
- Automation- Instead of manually checking results, APIs automate the process — saving hours of repetitive work.
In short, scraping search engines lets you turn public search results into actionable data, enabling smarter decisions across SEO, marketing, and analytics.
We’ll test dedicated APIs for scraping Google, Bing, DuckDuckGo, and Baidu, one by one using Python(Before we begin testing the the APIs I hope you have Python 3.x installed on your machine). And just when you think you’ve seen it all, I’ll introduce an API that can pull results from all these search engines in a single call. Sounds interesting? Let’s dive in.
Scraping Google search results with Scrapingdog
Once you sign up and access the dashboard, you’ll find the Google SERP Scraping API displayed right there on the dashboard.
To scrape Google search results you can pass any randome query. For this tutorial, I’ll be using the query “search engine scraping”.
With the Google scraper you will get this complete data in JSON format.
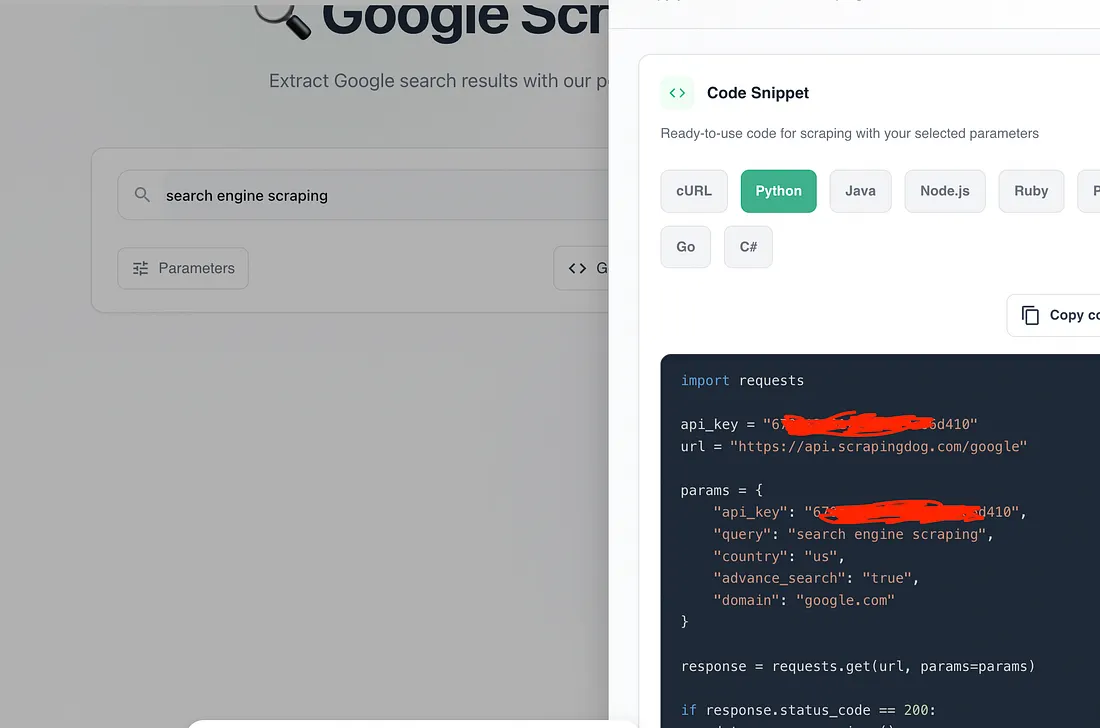
Once I pass this query in the scraper I will get a python code which I can just copy and paste it in my python environment to scrape Google.
Once you run this code you will get this beautiful JSON response.
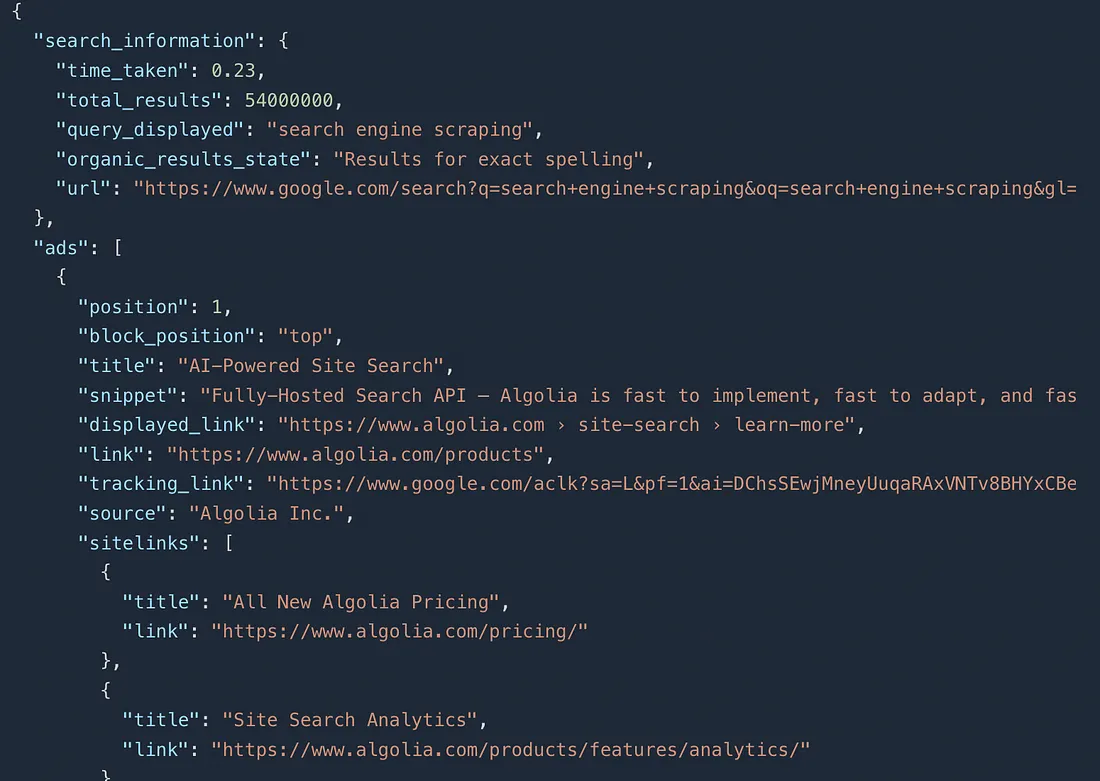
You will get everything right from Ads, AI overview to organic search results within this JSON response.
If you don’t need such a detailed response and are only interested in organic search data, you can use the Google Light Search API instead.
You will get this JSON response with the above code.
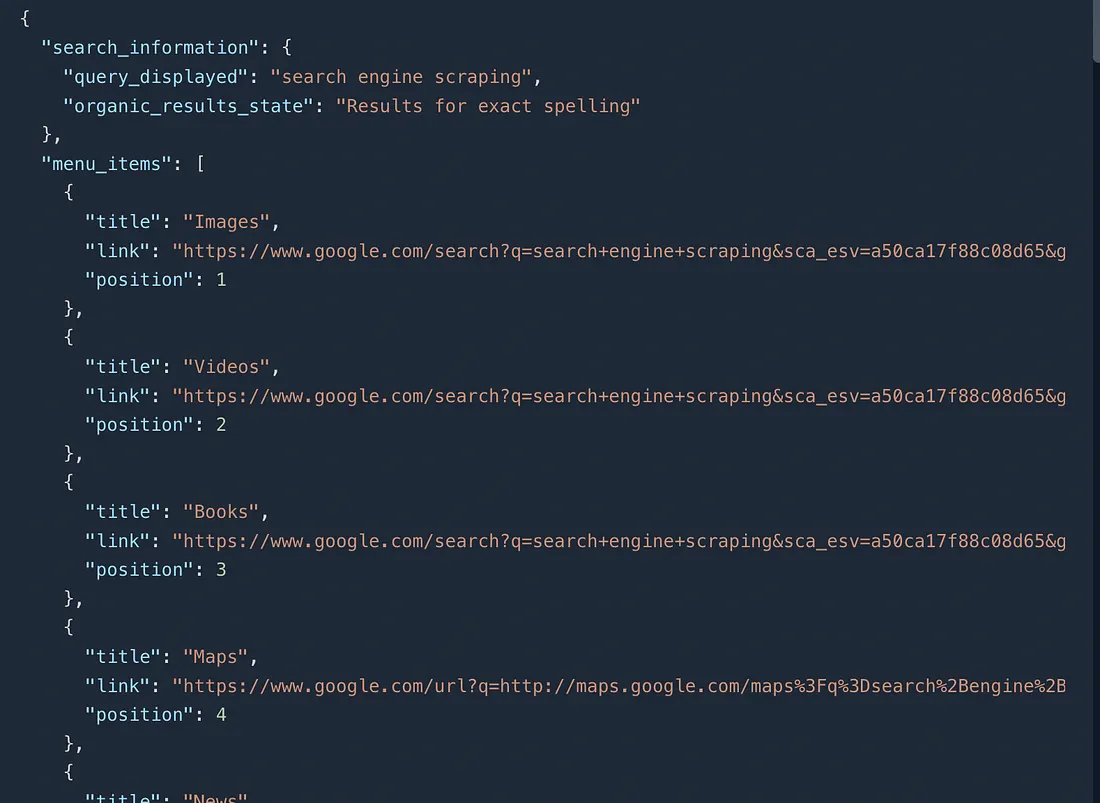
This API is economical and its latency is also very low compared to the advance search API.
Scrapingdog also provides a dedicated endpoint for scraping Bing at scale. To test this API just pass search engine scraping to the Bing scraper
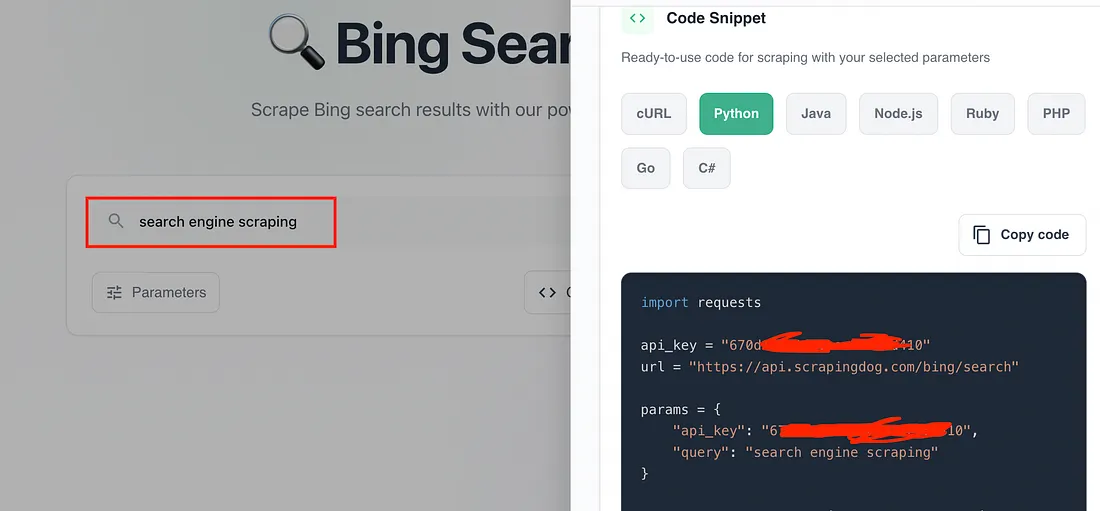
.
Copy the python code from the dashboard and paste it in your Python file.
Once you run this code you will get this JSON response.
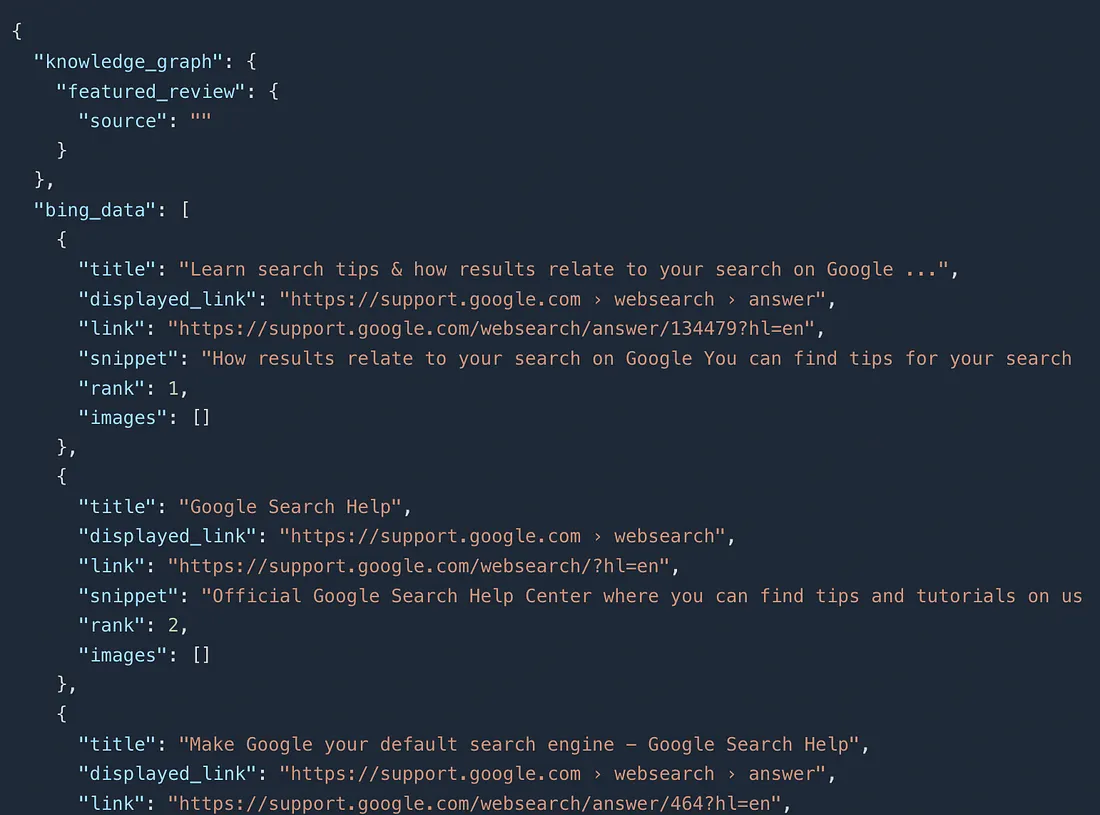
DuckduckGo is another search engine which is widely used in many countries. You can scrape this search engine to create your own seo tool. Let’s see how this can be scraped with the help of Scrapingdog’s scraping APIs.
We will use DuckduckGo scraper API to scrape search results in JSON format. Again we will use the same query search engine scraping. If you search this query on DuckDuckGo, it will render this.
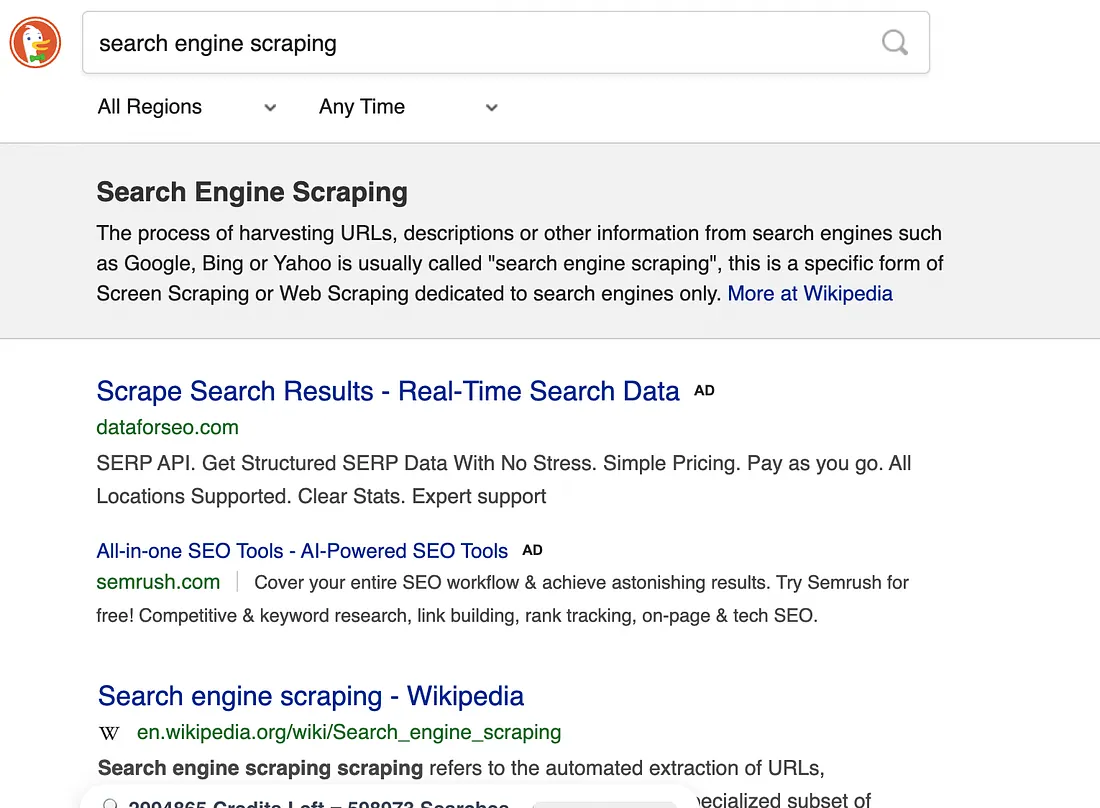
Now, to scrape this you have to pass the query to the scraper and copy the python code from the dashboard.
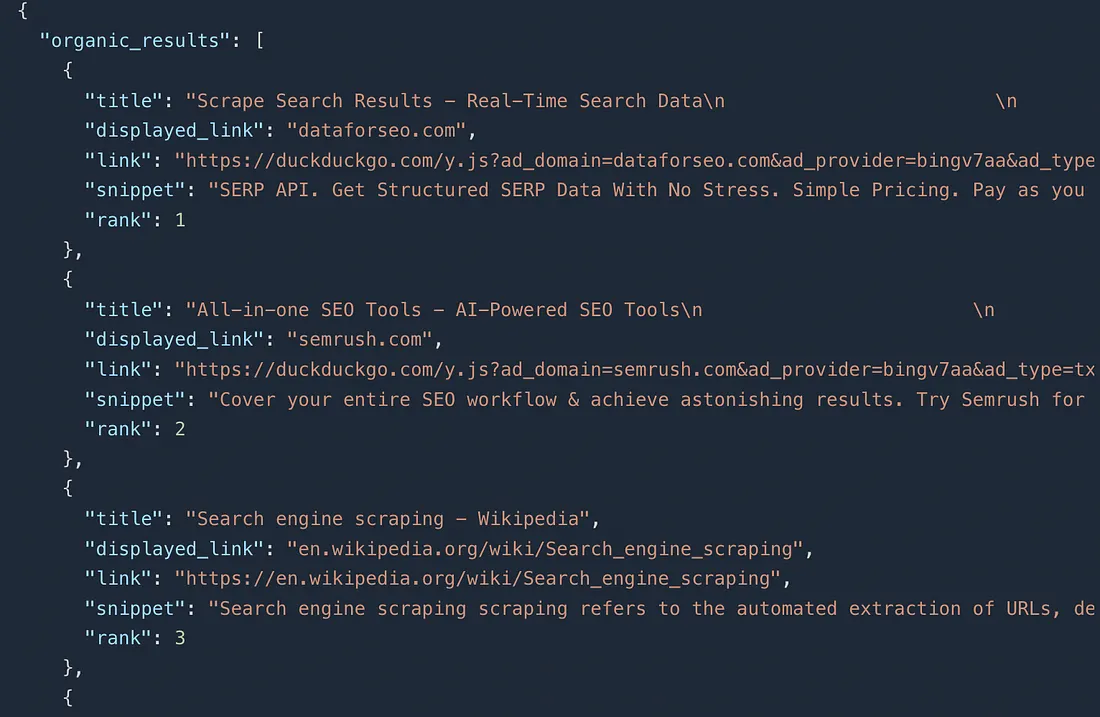
Here we are making a GET request to https://api.scrapingdog.com/duckduckgo/search along with the basic query parameters. Once you run this code you will get this JSON response.
Baidu is a dominant search engine in China and scraping this search engine can provide you with valuable insight about Chinese market.
In this section we will learn to scrape Baidu with the help of Baidu Scraping API. You will find the scraper over here. We will use the same technique used before with other search engines.
We will make a GET request to https://api.scrapingdog.com/baidu/search to extract the search result data in JSON format.
Once you run this code you will get this JSON data.
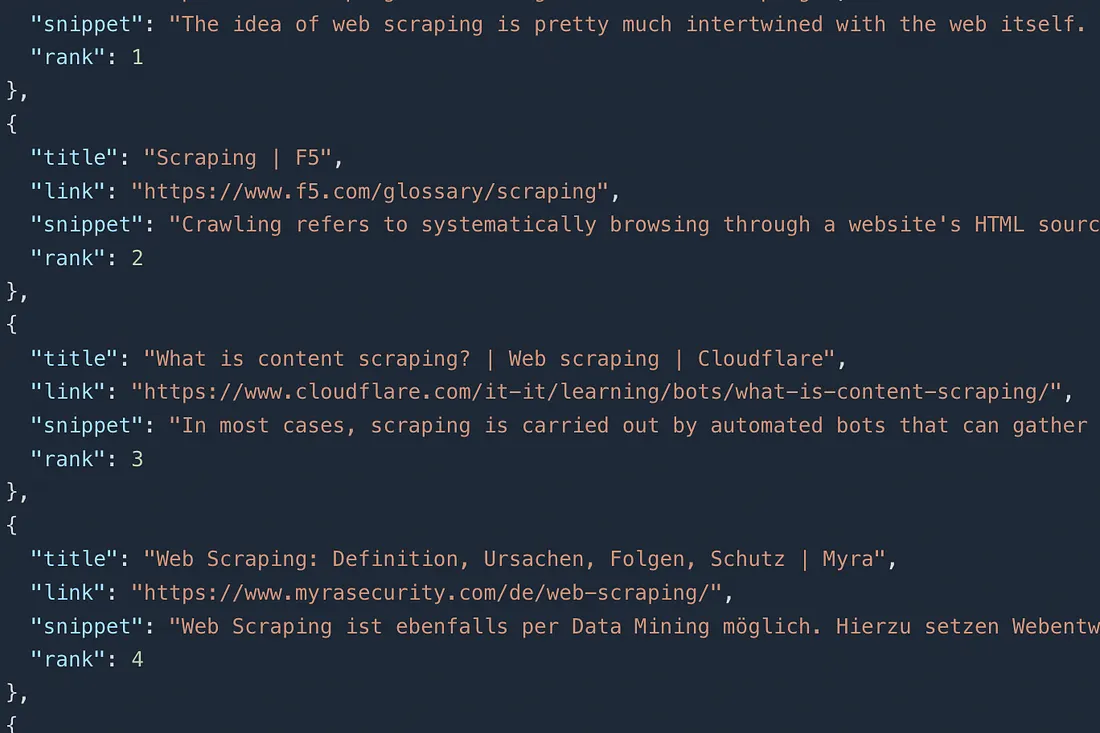
This data will have everything from links to title. Of course, you can pass more query parameter to the API according to your requirements.
Earlier in this article, I mentioned an API capable of fetching data from all major search engines with a single request. Now it’s time to put that into action. We’ll be using Scrapingdog’s Universal Search API for this.
Before we dive into the code, here’s a quick video showing how to get data from multiple search engines in one API call using Scrapingdog’s Universal Search API:
Universal Search API fetches results from all major search engines in a single request, allowing you to collect data efficiently without making separate API calls for each engine.
You can access this scraper from here. To access this API we are going to make a GET request to https://api.scrapingdog.com/search
It is a very clean python code and once you run this you will get this JSON response.
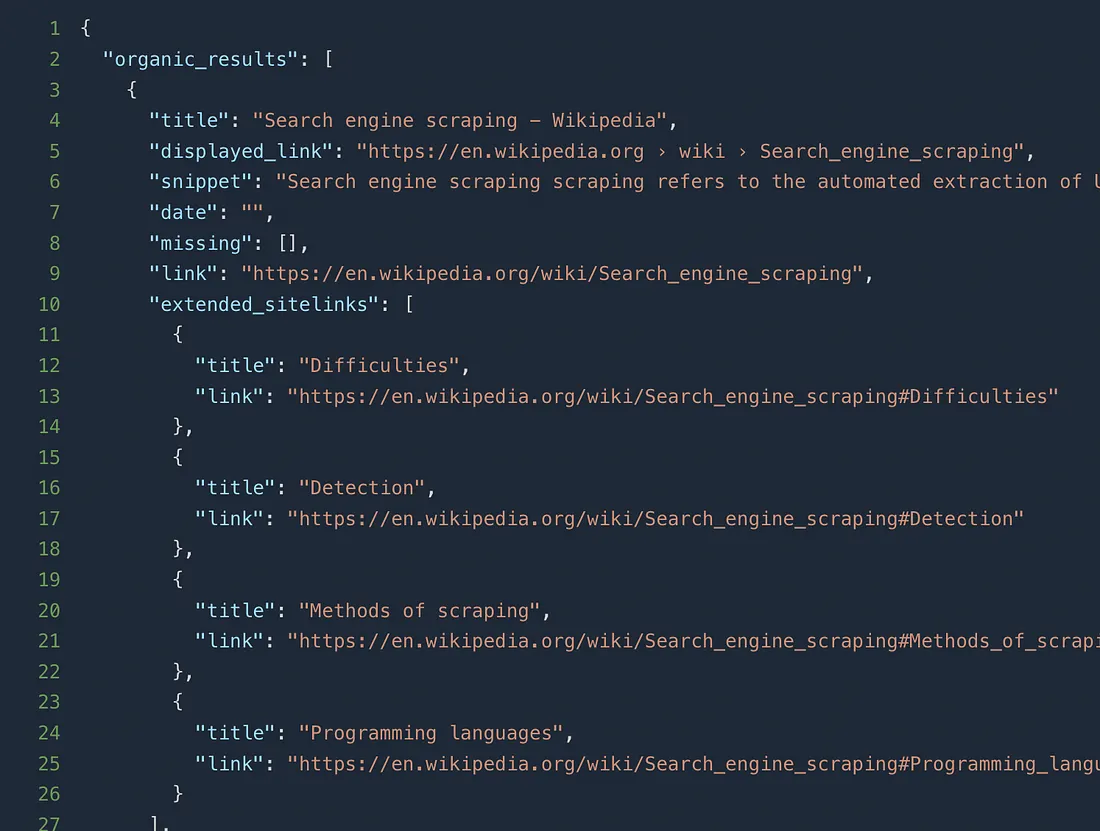
With this we are going to wrap this article.


