
TL;DR
- 5 JS libraries for scraping in 2026:
request-promise-native,Unirest,Cheerio,Puppeteer,Osmosis. - Fetch with HTTP clients; parse fast with
Cheerio; usePuppeteerfor JS-rendered pages & interactions;Osmosisas a lightweight alternative. - Demos use Books to Scrape / Wikipedia with concise code for
GET/POST, DOM parsing, and headless grabs.
Web Scraping is a great way to collect large amounts of data in less time. Worldwide data is increasing, and web scraping has become more important for businesses than ever before.
In this article, we are going to list & use JavaScript scraping libraries and frameworks to extract data from web pages. We are going to scrape “Book to Scrape” for demo purposes.
List of Best Javascript Web Scraping Library
Request-Promise-Native
It is an HTTP client through which you can easily make HTTP calls. It also supports HTTPS & follows redirects by default. Now, let’s see an example of request-promise-native and how it works.
const request = require(‘request-promise-native’);
let scrape = async() => {
var respo = await request(‘http://books.toscrape.com/')
return respo;
}
scrape().then((value) => {
console.log(value); // HTML code of the website
});
What are the advantages of using request-promise-native:
- It provides proxy support
- Custom headers
- HTTP Authentication
- Support TLS/SSL Protocol
Unirest
Unirest is a lightweight HTTP client library from Mashape. Along with JS, it’s also available for Java, .Net, Python, Ruby, etc.
- GET request
var unirest = require('unirest');
let scrape = async() => {
var respo = await unirest.get(‘http://books.toscrape.com/')
return respo.body;
}
scrape().then((value) => {
console.log(value); // Success!
});
var unirest = require(‘unirest’);
let scrape = async() => {
var respo = await unirest.post(‘http://httpbin.org/anything').headers({'X-header': ‘123’})
return respo.body;
}
scrape().then((value) => {
console.log(value); // Success!
});
{
args: {},
data: ‘’,
files: {},
form: {},
headers: {
‘Content-Length’: ‘0’,
Host: ‘httpbin.org’,
‘X-Amzn-Trace-Id’: ‘Root=1–5ed62f2e-554cdc40bbc0b226c749b072’,
‘X-Header’: ‘123’
},
json: null,
method: ‘POST’,
origin: ‘23.238.134.113’,
url: ‘http://httpbin.org/anything'
}
var unirest = require(‘unirest’);
let scrape = async() => {
var respo = await unirest.put(‘http://httpbin.org/anything').headers({'X-header': ‘123’})
return respo.body;
}
scrape().then((value) => {
console.log(value); // Success!
});
{
args: {},
data: ‘’,
files: {},
form: {},
headers: {
‘Content-Length’: ‘0’,
Host: ‘httpbin.org’,
‘X-Amzn-Trace-Id’: ‘Root=1–5ed62f91-bb2b684e39bbfbb3f36d4b6e’,
‘X-Header’: ‘123’
},
json: null,
method: ‘PUT’,
origin: ‘23.63.69.65’,
url: ‘http://httpbin.org/anything'
}
In the response to POST and PUT requests, you can see I have added a custom header. We add custom headers to customize the result of the response.
Advantages of using Unirest
- support all HTTP Methods (GET, POST, DELETE, etc.)
- support forms uploads
- supports both streaming and callback interfaces
- HTTP Authentication
- Proxy Support
- Support TLS/SSL Protocol
Cheerio
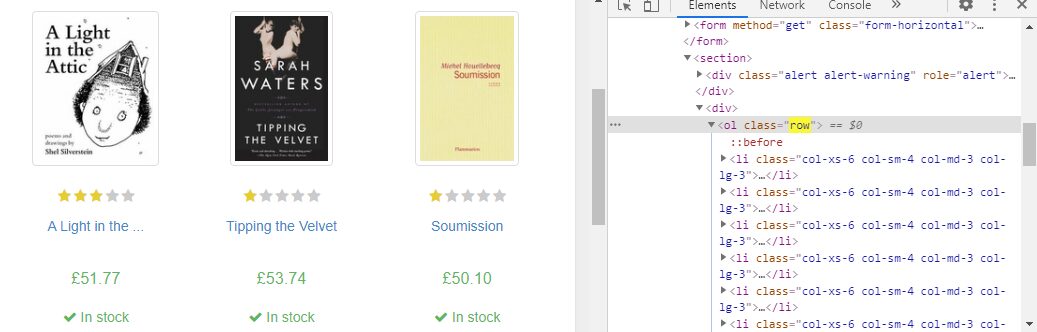
In the Cheerio module, you can use jQuery’s syntax while working with downloaded web data. Cheerio allows developers to provide their attention to the downloaded data rather than parsing it. Now, we’ll calculate the number of books available on the first page of the target website.
const cheerio = require(‘cheerio’)
let scrape = async() => {
var respo = await request(‘http://books.toscrape.com/')
return respo;
}
scrape().then((value) => {
const $ = cheerio.load(value)
var numberofbooks = $(‘ol[class=”row”]’).find(‘li’).length
console.log(numberofbooks); // 20!
});
We are finding all the li tags inside the ol tag with class row.
Advantages of using Cheerio
- Familiar syntax: Cheerio implements a subset of core jQuery. It removes all the DOM inconsistencies and browser cruft from the jQuery library, revealing its genuinely gorgeous API.
- Lightening Quick: Cheerio works with a straightforward, consistent DOM model. As a result, parsing, manipulating, and rendering are incredibly efficient. Preliminary end-to-end benchmarks suggest that cheerio is about 8x faster than JSDOM.
- Stunningly flexible: Cheerio can parse nearly any HTML or XML document.
Puppeteer
- Puppeteer is a Node.js library that offers a simple but efficient API that enables you to control Google’s Chrome or Chromium browser.
- It also enables you to run Chromium in headless mode (useful for running browsers in servers) and send and receive requests without needing a user interface.
- It has better control over the Chrome browser as it does not use any external adaptor to control Chrome plus it has Google support too.
- The great thing is that it works in the background, performing actions as instructed by the API.
We’ll see an example of a puppeteer scraping the complete HTML code of our target website.
let scrape = async () => {
const browser = await puppeteer.launch({headless: true});
const page = await browser.newPage();
await page.goto(‘http://books.toscrape.com/');
await page.waitFor(1000);
var result = await page.content();
browser.close();
return result;
};
scrape().then((value) => {
console.log(value); // complete HTML code of the target url!
});
What each step means here:
- This will launch a chrome browser.
- Second-line will open a new tab.
- The third line will open that target URL.
- We are waiting for 1 second to let the page load completely.
- We are extracting all the HTML content of that website.
- We are closing the Chrome browser.
- returning the results.
Advantages of using Puppeteer
- Click elements such as buttons, links, and images
- Automate form submissions
- Navigate pages
- Take a timeline trace to find out where the issues are on a website
- Carry out automated testing for user interfaces and various front-end apps directly in a browser
- Take screenshots
- Convert web pages to PDF files
I have explained everything about Puppeteer over here; please go through the complete article.
Osmosis
- Osmosis is HTML/XML parser and web scraper.
- It is written in node.js which packed with css3/XPath selector and lightweight HTTP wrapper
- No large dependencies like Cheerio
We’ll do a simple single-page scrape. We’ll be working with this page on Wikipedia, which contains population information for the US States.
osmosis('https://en.wikipedia.org/wiki/List_of_U.S._states_and_territories_by_population').set({ heading: ‘h1’, title: ‘title’}).data(item => console.log(item));
The response will look like this
{ heading: ‘List of U.S. states and territories by population’, title: ‘List of U.S. states and territories by population — Wikipedia’ }
Advantages of using Osmosis
- Supports CSS 3.0 and XPath 1.0 selector hybrids
- Load and search AJAX content
- Logs URLs, redirects, and errors
- Cookie jar and custom cookies/headers/user agent
- Login/form submission, session cookies, and basic auth
- Single proxy or multiple proxies and handles proxy failure
- Retries and redirect limits
How To Choose the Best JavaScript Library for Web Scraping?
There are a few things to consider before choosing the best javascript library for web scraping:
- Easy to use and has good documentation.
- Able to handle a large amount of data.
- Able to handle different types of data (e.g., text, images, etc.).
- The library should be able to handle different types of web pages (e.g., static, dynamic, etc.).
Key Takeaways:
JavaScript offers multiple scraping libraries, including Cheerio, Puppeteer, Playwright, Axios, and Request-based tools.
Cheerio is lightweight and ideal for parsing static HTML content.
Puppeteer and Playwright handle JavaScript-heavy websites through headless browser automation.
Axios is commonly used for sending HTTP requests before parsing responses.
The right library depends on whether the target site is static, dynamic, or requires full browser interaction.
Conclusion
We understood how we could scrape data with Nodejs using Puppeteer, Osmosis, Request-promise-Native & Unirest regardless of the type of website. Web scraping is set to grow as time progresses. As web scraping applications abound, JavaScript libraries will grow in demand. While there are salient JavaScript libraries, it could be puzzling to choose the right one. However, it would eventually boil down to your own respective requirements.
Additional Resources
And there’s the list! At this point, you should feel comfortable writing your first web scraper to gather data from any website. Here are a few additional resources that you may find helpful during your web scraping journey:


