
TL;DR
- R guide using
rvest+dplyrto scrape IMDb (title, year, rating, synopsis) into a data frame and save CSV. - Then visit each movie’s page to collect cast via a small helper function.
- Add pagination with a loop (page param increments of 50) and
rbindto merge results. - Full code provided; if you don’t want to code, Scrapingdog’s API is suggested at the end.
If you’re looking to gather data from the web, you may be wondering how to go about it. Just as there are many ways to gather data, there are also many ways to scrape data from the web. In this blog post, we’ll be scraping data from websites using r.
R is a programming language that is well-suited for web scraping due to its many libraries and tools. We’ll go over some of the basics of web scraping with R so that you can get started on your own projects.
This tutorial is divided into three sections.
In the first section, we are going to scrape a single page from IMDB. In the second section, we are going to open links to each movie and then scrape the data from there as well.
In the last and final section, we are going to scrape data from all the pages. We will see how URL patterns change when page numbers are changed.
Requirements
install.packages(“rvest”)
install.packages(“dplyr”)
and then we will import the libraries within our script.
library(rvest)
library(dplyr)
What data will we scrape from IMDB?
It is always best to decide this thing in advance before writing the code. We will scrape the name, the year, the rating, and the synopsis.
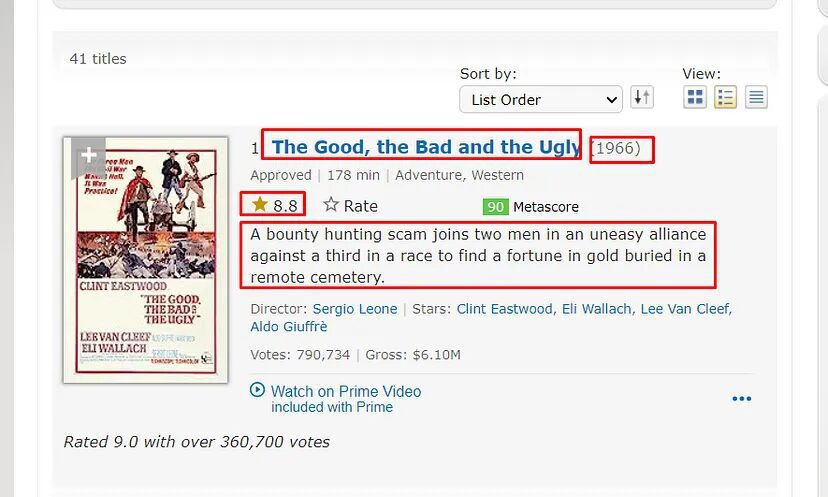
Scraping IMDB using R
Web Scraping with R is super easy and useful, and in this tutorial, I scrape movies from IMDb into a data frame in R using the rvest library and then export the data frame as a CSV, all in a few lines of code. This method works across many sites — typically those that show static content — such as Yelp, Amazon, Wikipedia, Google, and more.
library(rvest)
library(dplyr)
link = "https://www.imdb.com/list/ls058457633/"
page = read_html(link)
We will first start with creating the name column. So, we will declare a variable called name. We will extract the name from the HTML code that we just fetched.

library(rvest)
library(dplyr)
link = "https://www.imdb.com/list/ls058457633/"
page = read_html(link)
name = page %>% html_nodes(".lister-item-header a") %>% html_text()
We have used the HTML nodes function to extract that particular HTML tag. After inspecting the title we found out that all the titles are stored under the class names lister-item-header with a tag. After this, we piped that one result into HTML text.
Let us understand what we have done so far. What every command do and also what this pipe operator is, in case you have never seen it before.
- read_html — We are using it to read HTML and essentially what it does is, it is provided with a URL and it gives you back an HTML document or the source code of the target URL.
- html_nodes — Given the HTML source code, it pulls out the actual elements that we want to grab.
- html_text — It will parse the text out of those tags.
- Pipe Operator(%>%) — It’s part of the deep wire library and essentially it makes coding really easy. I highly recommend this library. It is equivalent to taking the mean i.e. a %>% mean = mean(a). Everything that’s to the left of the pipe is computed and it takes the result and passes it in as the first argument to the function that’s after the pipe. So, pretty easy and super useful.
So, now we have written the code for the name column, we can go ahead and run the code. This is what we get as the output.
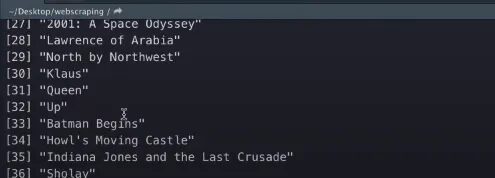
It looks pretty good and it has all of our movie titles. Now, we will try to grab the year’s text. If we inspect the year, we will find that all the years are stored under the class text-muted unbold.
library(rvest)
library(dplyr)
link = "https://www.imdb.com/list/ls058457633/"
page = read_html(link)
name = page %>% html_nodes(".lister-item-header a") %>% html_text()
year = page %>% html_nodes(".text-muted unbold") %>% html_text()
If we run that line we will get the below output.
Now, we will grab the ratings. After the inspection, we can find that all the ratings are stored under the class ipl-rating-star__rating.

library(rvest)
library(dplyr)
link = "https://www.imdb.com/list/ls058457633/"
page = read_html(link)
name = page %>% html_nodes(".lister-item-header a") %>% html_text()
year = page %>% html_nodes(".text-muted unbold") %>% html_text()
rating = page %>% html_nodes(".ipl-rating-star__rating") %>% html_text()
And the last thing is to get the synopsis of the movies.
library(rvest)
library(dplyr)
link = "https://www.imdb.com/list/ls058457633/"
page = read_html(link)
name = page %>% html_nodes(".lister-item-header a") %>% html_text()
year = page %>% html_nodes(".text-muted unbold") %>% html_text()
rating = page %>% html_nodes(".ipl-rating-star__rating") %>% html_text()
synopsis = page %>% html_nodes(".ratings-metascore+ p") %>% html_text()
Just to confirm we are getting the right data we are going to print it.
So, the rating looks good. Let us check the synopsis.

The synopsis also looks good. Now, we have our four variables and we are going to treat these as columns for our data frame, in order to make this data frame we are going to call data.frame command.
library(rvest)
library(dplyr)
link = "https://www.imdb.com/list/ls058457633/"
page = read_html(link)
name = page %>% html_nodes(".lister-item-header a") %>% html_text()
year = page %>% html_nodes(".text-muted unbold") %>% html_text()
rating = page %>% html_nodes(".ipl-rating-star__rating") %>% html_text()
synopsis = page %>% html_nodes(".ratings-metascore+ p") %>% html_text()
movies = data.frame(name, year, rating, synopsis, stringAsFactors=FALSE)
We have passed another argument stringAsFactors as false. Essentially what it does is when it is true it makes all of your columns into factors instead of characters or numeric or whatever else they should be. So, just watch out for that.
We can run this code and view our movie’s data frame and you can see just in a few lines we got the whole text from the IMDB page into a data frame.
View(movies)
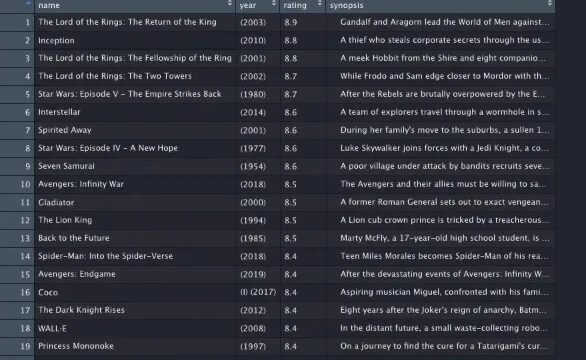
And the last thing I want to show you is how you can store the data in a CSV file.
library(rvest)
library(dplyr)
link = "https://www.imdb.com/list/ls058457633/"
page = read_html(link)
name = page %>% html_nodes(".lister-item-header a") %>% html_text()
year = page %>% html_nodes(".text-muted unbold") %>% html_text()
rating = page %>% html_nodes(".ipl-rating-star__rating") %>% html_text()
synopsis = page %>% html_nodes(".ratings-metascore+ p") %>% html_text()
movies = data.frame(name, year, rating, synopsis, stringAsFactors=FALSE)
write.csv(movies, "movies.csv")
After running it you will get the movies.csv file inside your folder.
Scraping Individual Movie Pages
In this section, we are going to open every movie link from the same IMDb page in order to scrape more data on every individual movie. Essentially I want to add one more data column to the above movies’ data frame of all the primary cast members of each of these movies. I want to scrape all the primary cast of the movie, and that is only possible by going inside every individual page.
So, the first thing is to grab all those URLs for each of these movies. We have already written the code for it or at least most of the code for it. So, it is not so hard, we just need to add a new variable called movie links.
if you will run the below code
name = page %>% html_nodes(“.lister-item-header a”)
you will get this.
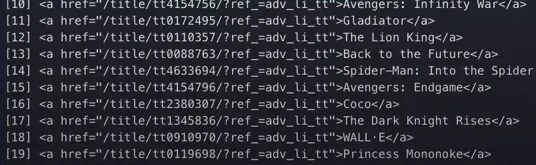
So, we just need to extract the href attribute from this code to complete the URL.
movie_links = page %>% html_nodes(“.lister-item-header a”) %>%
html_attr(“href”) %>% paste("https://www.imdb.com", ., sep="")
the paste will concatenate the imdb.com with the href tag value. And piping will take everything to the left of the pipe. It computes that and it passes whatever that result is like the first argument to the function after the pipe. Whatever is being passed in is passed as a second argument by putting that period there. The paste will add an empty space in between so to avoid that we have used sep as empty quotes. So, we can go ahead and run this code.
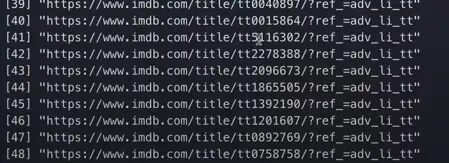
This is exactly what we want. That looks good. Now, that we have all the movie links, we need to figure out a way to go into each of the pages and scrape the cast members. If you come from a programming background or have done any coding at all you might be tempted to use the for loop here but I think r is actually more efficient when it is used by applying function rather than for loops.
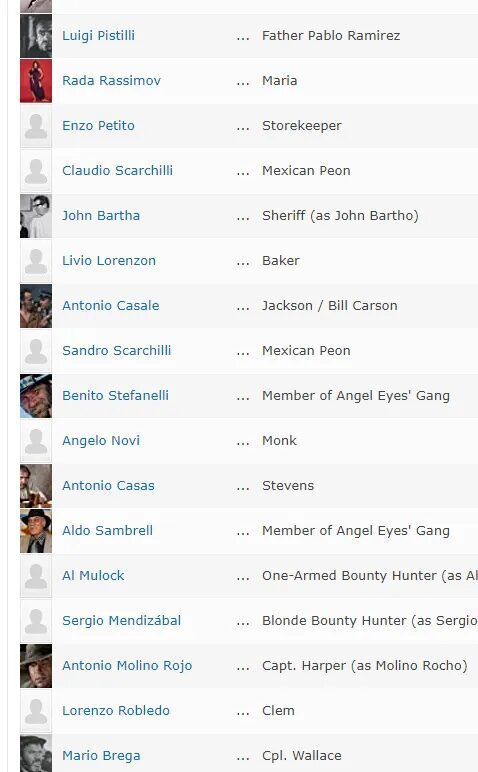
I am going to create a function that essentially takes in one of these movie links and scrapes these cast members and then just returns whatever that string is. You can find the HTML element by inspecting it.
get_cast = function(movie_link){
movie_page = read_html(movie_link)
movie_cast = movie_page %>% html_nodes(".cast_list a") %>% html_text()
}
Now, if I will print the cast, it will appear in this manner.
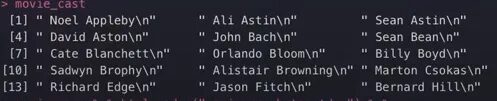
But I need all of them in one line, therefore we will use the paste function.
get_cast = function(movie_link){
movie_page = read_html(movie_link)
movie_cast = movie_page %>% html_nodes(".cast_list a") %>% html_text() %>% paste(collapse = ",")
return(movie_cast)
}
So, now I have all the movie links and I have this function get_cast that scrapes all the cast names and returns a single string with them. So, to put it all together, I will create a cast column using the sapply function.
cast = sapply(movie_links, FUN = get_cast)
Essentially the way sapply works is, given the first variable which is a vector of movie links it will go into each one grab this and run it through the function. movie_links is passed as parameters and then whatever the result is it will just put that back into a vector for us.
The last thing you can do is to add cast to the movies dataframe as our fifth column.
movies = data.frame(name, year, rating, cast, synopsis, stringAsFactors=FALSE)
Now, if you run this, we will get all the cast within our movie data frame.

If you want to do the text cleaning you can do that, but I liked it this way.
Complete Code
library(rvest)
library(dplyr)
link = "https://www.imdb.com/list/ls058457633/"
page = read_html(link)
name = page %>% html_nodes(".lister-item-header a") %>% html_text()
movie_links = page %>% html_nodes(“.lister-item-header a”) %>% html_attr(“href”) %>% paste("https://www.imdb.com", ., sep="")
year = page %>% html_nodes(".text-muted unbold") %>% html_text()
rating = page %>% html_nodes(".ipl-rating-star__rating") %>% html_text()
synopsis = page %>% html_nodes(".ratings-metascore+ p") %>% html_text()
get_cast = function(movie_link){
movie_page = read_html(movie_link)
movie_cast = movie_page %>% html_nodes(".cast_list a") %>% html_text() %>% paste(collapse = ",")
return(movie_cast)
}
cast = sapply(movie_links, FUN = get_cast)
movies = data.frame(name, year, rating, cast, synopsis, stringAsFactors=FALSE)
write.csv(movies, "movies.csv")
Handling Pagination
In this section, we are going to scrape multiple pages with r. The first step is to figure out how the URL of the website is changing.
So, to scrape multiple pages, you can see if we go down to the very bottom you will find the next button. And when you click it you will find &start=51 in your URL and again if you will click it you will find &start=101 in your URL.
The page number is increasing by 50 for every new page. Similarly, if you add &start=1 to the URL you will be redirected to the first page, and hence we have figured out how the URL changes.
We will create a for loop that will go through each of the pages that we want to scrape then just do everything that we did before. So, not super hard but there are a few components to it.
We will create a big for loop outside everything and I know in the last section I said that the sapply function is preferable to for loops but for this situation, it just kind of makes sense for me to use a for loop but you can do it the way that you feel most comfortable.
library(rvest)
library(dplyr)
get_cast = function(movie_link){
movie_page = read_html(movie_link)
movie_cast = movie_page %>% html_nodes(".cast_list a") %>% html_text() %>% paste(collapse = ",")
return(movie_cast)
}
movies=data.frame()
for (page_result in seq(from = 1, to = 51, by = 50)){
link=paste("https://www.imdb.com/search/title/?genres=action&start=",page_result, "&explore=title_type,genres&ref_=adv_nxt", sep="")
page = read_html(link)
name = page %>% html_nodes(".lister-item-header a") %>% html_text()
movie_links = page %>% html_nodes(“.lister-item-header a”) %>% html_attr(“href”) %>% paste("https://www.imdb.com", ., sep="")
year = page %>% html_nodes(".text-muted unbold") %>% html_text()
rating = page %>% html_nodes(".ipl-rating-star__rating") %>% html_text()
synopsis = page %>% html_nodes(".ratings-metascore+ p") %>% html_text()
cast = sapply(movie_links, FUN = get_cast)
}
movies = rbind(movies,data.frame(name, year, rating, cast, synopsis, stringAsFactors=FALSE))
print(paste("Page:",page_result))
I am using the paste function again to make our URL dynamic and I have used sep to remove all the spaces between the strings that you are trying to concatenate.
I have kept get_cast out of the for loop as it does not change each time. As we are going to call it from inside the for loop. If we put the movie’s data frame inside the for loop it will keep changing the value on every run.
So, in the end, it will have the values of the last 50 results. In our case, it would be the second page and that’s not what we want. For that, we are going to use rbind function which means row bind and it will take the first argument as movies and the second argument will stay this data frame.
So, now each time this for loops runs, it will take whatever the old movies variable was and then just put on the new rows of movies that it got from this page that it’s running on.
In the end, we are going to use the print statement to track our progress.
This is what our movie’s data frame looks like.
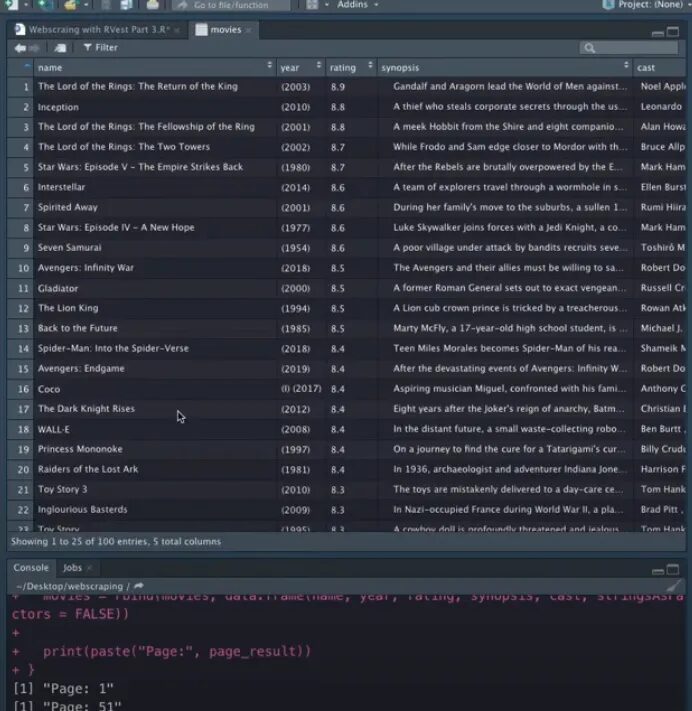
We have managed to scrape the first 100 pages of IMDb. Now, if you want to scrape all the pages then you can make the changes in your for loop according to your requirements.
Key Takeaways:
The guide teaches how to perform web scraping using R, a programming language popular for data analysis.
It explains how to send HTTP requests and fetch web page content within R using appropriate libraries.
You learn how to parse HTML and extract data from web pages using DOM selectors.
The tutorial shows how to structure and save the extracted data for further analysis or reporting.
It also covers best practices like handling errors, respecting website terms, and avoiding too-frequent requests.
Conclusion
In this tutorial, we discussed the various R open-source libraries you may use to scrape a website. If you followed along with the tutorial, you were able to create a basic scraper to crawl any page. While this was an introductory article, we covered most methods you can use with the libraries. You may choose to build on this knowledge and create complex web scrapers that can crawl thousands of pages.
If you don’t want to code your own scraper then you can always use our web scraping API.
Feel free to message us to inquire about anything you need clarification on.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:


