TL;DR
- Python guide:
requests+BeautifulSoupto scrape Realtor listings; extract price, beds / baths / size, address; full code + sampleJSON. - Fine for small runs; Realtor will block fast scripts (IP bans / CAPTCHAs).
- For scale, switch fetch layer to Scrapingdog (rotating IPs / anti-bot) with 1k free credits.
- Pagination: tweak the search URL or follow “Next” to walk pages.
In this comprehensive tutorial, we are going to scraper realtor.com using Python and we will build a realtor scraper.
Realtor is one of the biggest real estate listing platforms. Many people in and outside the United States use this website for buying, renting, or selling property. So, this website has a lot of property data, and this huge data can be used to analyze future trends in any locality.
There are a lot of advantages of web scraping real estate data from real estate websites like Realtor. In this tutorial, I will explain to you a step-by-step procedure to build a scalable scraper for Realtor.
Setting up the prerequisites to scrape Realtor.com
Before we start coding we have to install certain libraries which are going to be used in the course of this article. I am assuming that you have already installed Python 3.x on your machine.
Before installing the libraries let’s create a folder where we will keep our scraping files.
mkdir realtor
Now, let’s install the libraries.
pip install requests
pip install beautifulsoup4
Requests — This will help us to make an HTTP connection with the host website.BeautifulSoup will help us to create an HTML tree for smooth data parsing.Now, create a Python file where you will write your scraper for Realtor. I am naming the file as realtor.py.What Are We Going to Extract From Realtor.com?
It is always a great idea to decide what exact data points we will extract from the page. We are going to target this page from Realtor.
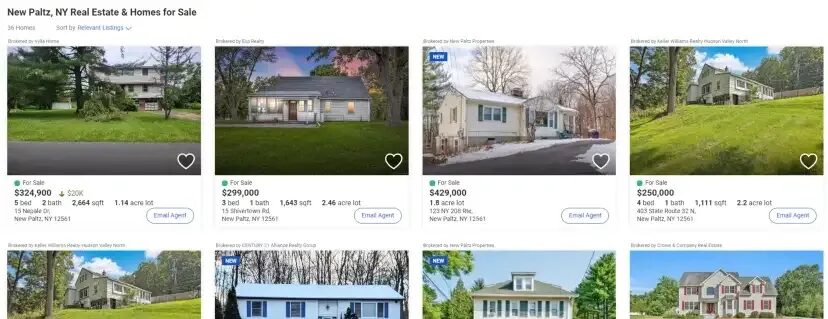
Page from which we are going to scrape data points in realtor.com
So, we will be scraping:
- Property selling price
- Property size, beds, etc.
- Property address.
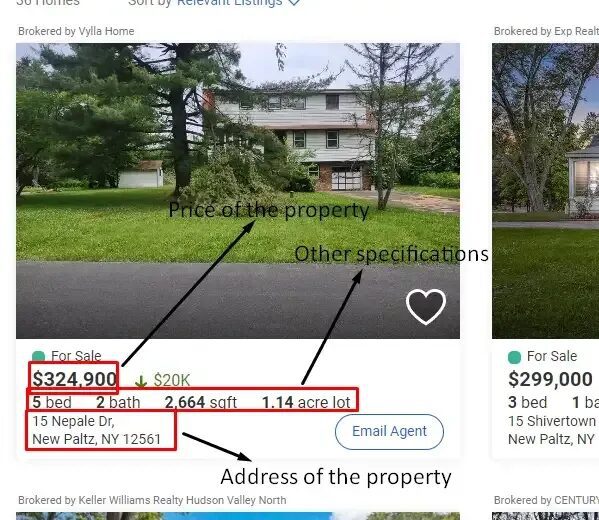
Data points we are going to scrape from property listing
Scraping Realtor
requests library.
import requests
from bs4 import BeautifulSoup
l=[]
o={}
target_url = "https://www.realtor.com/realestateandhomes-search/New-Paltz_NY/type-single-family-home,multi-family-home"
head={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"}
resp = requests.get(target_url, headers=head)
print(resp.status_code)
If you get 200 status code by running this code then you can proceed ahead with parsing process.
Above code is pretty straightforward but let me explain the code in step by step manner.
- We have imported all the libraries that we installed earlier in this post.
- Declare an empty list and an object for storing data later.
- Declared the target URL to
target_urlvariable. - Headers for passing while making a GET request.
- Using the
requestslibrary we made a GET request to the target website. - Finally, we are checking the status of the request made.
Parsing data from raw HTML
Before we start the parsing process, we have to identify the location of each target data element inside the HTML DOM.
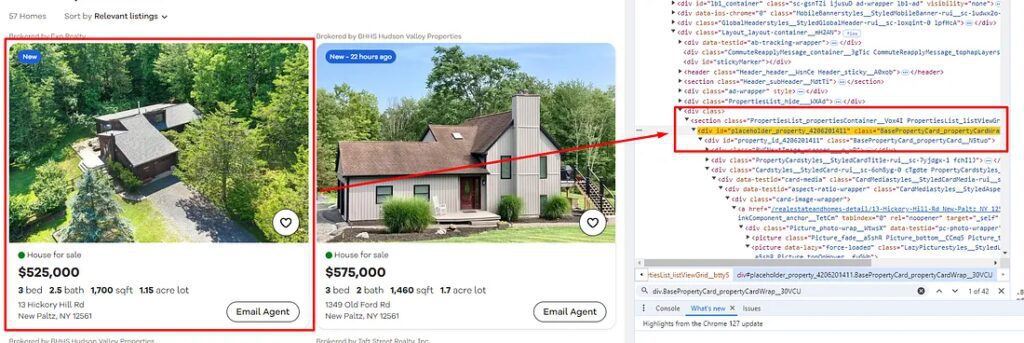
As you can see in the image above, the data of all the property boxes are stored inside the div tag with class BasePropertyCard_propertyCardWrap__30VCU .
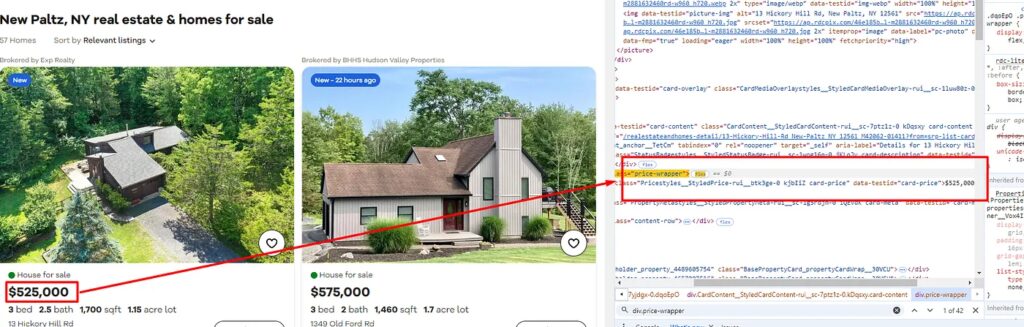
Identifying the location of price text
Price text is stored under the div tag with the class price-wrapper.
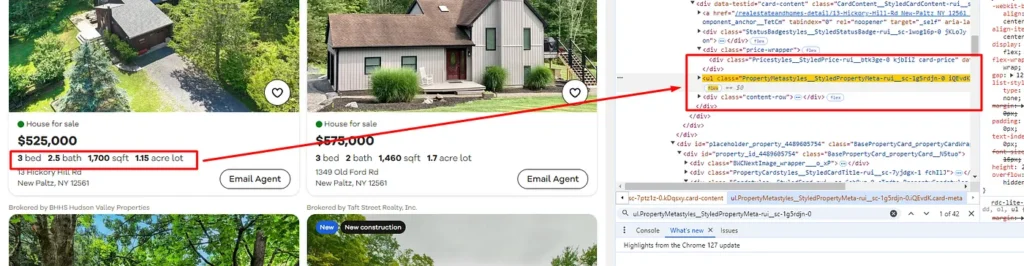
Identifying property specifications’ location in HTML
All this information is stored inside ul tag with class PropertyMetastyles__StyledPropertyMeta-rui__sc-1g5rdjn-0.
The last thing that is left is the address of the property. Let’s find that too.
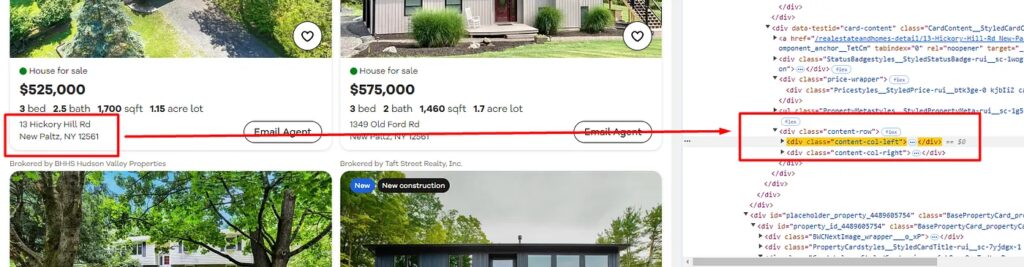
Identifying the address of the property in HTML
You can simply find the address inside the div tag with the class content-col-left.
We were able to find the location of each data element inside the DOM. Now, let’s code it in Python and parse this data out.
soup = BeautifulSoup(resp.text, 'html.parser')
allData = soup.find_all("div",{"class":"BasePropertyCard_propertyCardWrap__30VCU"})
for i in range(0, len(allData)):
try:
o["price"]=allData[i].find("div",{"class":"price-wrapper"}).text
except:
o["price"]=None
try:
metaData = allData[i].find("ul",{"class":"PropertyMetastyles__StyledPropertyMeta-rui__sc-1g5rdjn-0"})
except:
metaData=None
if(metaData is not None):
allMeta = metaData.find_all("li")
for x in range(0, len(allMeta)):
try:
o["bed"]=allMeta[0].text
except:
o["bed"]=None
try:
o["bath"]=allMeta[1].text
except:
o["bath"]=None
try:
o["size-sqft"]=allMeta[2].text
except:
o["size-sqft"]=None
try:
o["size-acre"]=allMeta[3].text
except:
o["size-acre"]=None
try:
o["address"]=allData[i].find("div",{"class":"content-col-left"}).text
except:
o["address"]=None
l.append(o)
o={}
print(l)
- Using the
find_all()method we first parsed all the property data and stored it inside the listallData. - Then we ran a
forloop to reach each and every property box in order to extract data of each property. - In the end, we are storing every property data one by one inside the list
l. Objectowas declared empty at the end because we have to store another property data once theforloop starts again.
Once you run the code you will get a beautiful JSON data like this.
[{'price': '$324,900', 'bed': '5bed', 'bath': '2bath', 'size-sqft': '2,664sqft', 'size-acre': '1.14acre lot', 'address': '15 Nepale Dr, New Paltz, NY 12561'}, {'price': '$299,000', 'bed': '3bed', 'bath': '1bath', 'size-sqft': '1,643sqft', 'size-acre': '2.46acre lot', 'address': '15 Shivertown Rd, New Paltz, NY 12561'}, {'price': '$429,000', 'bed': '1.8acre lot', 'bath': None, 'size-sqft': None, 'size-acre': None, 'address': '123 NY 208 Rte, New Paltz, NY 12561'}, {'price': '$250,000', 'bed': '4bed', 'bath': '1bath', 'size-sqft': '1,111sqft', 'size-acre': '2.2acre lot', 'address': '403 State Route 32 N, New Paltz, NY 12561'}, {'price': '$250,000', 'bed': '4bed', 'bath': '1bath', 'size-sqft': '1,111sqft', 'size-acre': '2.2acre lot', 'address': '403 Route 32, New Paltz, NY 12561'}, {'price': '$484,000', 'bed': '3bed', 'bath': '3bath', 'size-sqft': '1,872sqft', 'size-acre': '1.3acre lot', 'address': '21 Angel Rd, New Paltz, NY 12561'}, {'price': '$729,000', 'bed': '7,841sqft lot', 'bath': None, 'size-sqft': None, 'size-acre': None, 'address': '225 Main St, New Paltz, NY 12561'}, {'price': '$659,900', 'bed': '4bed', 'bath': '3.5bath', 'size-sqft': '3,100sqft', 'size-acre': '0.93acre lot', 'address': '8 Carroll Ln, New Paltz, NY 12561'}, {'price': '$479,000', 'bed': '3bed', 'bath': '3bath', 'size-sqft': '2,184sqft', 'size-acre': '1.1acre lot', 'address': '447 S Ohioville Rd, New Paltz, NY 12561'}, {'price': '$389,900', 'bed': '3bed', 'bath': '1.5bath', 'size-sqft': '1,608sqft', 'size-acre': '1.1acre lot', 'address': '10 Canaan Rd, New Paltz, NY 12561'}, {'price': '$829,900', 'bed': '4bed', 'bath': '2.5bath', 'size-sqft': '4,674sqft', 'size-acre': '2.81acre lot', 'address': '8 Yankee Folly Rd, New Paltz, NY 12561'}, {'price': '$639,000', 'bed': '4bed', 'bath': '2.5bath', 'size-sqft': '2,346sqft', 'size-acre': '2.1acre lot', 'address': '4 Willow Way, New Paltz, NY 12561'}, {'price': '$1,995,000', 'bed': '5bed', 'bath': '4bath', 'size-sqft': '4,206sqft', 'size-acre': '51.3acre lot', 'address': '1175 Old Ford Rd, New Paltz, NY 12561'}, {'price': '$879,000', 'bed': '8bed', 'bath': '5bath', 'size-sqft': '0.34acre lot', 'size-acre': None, 'address': '21 Grove St, New Paltz, NY 12561'}, {'price': '$209,900', 'bed': '3bed', 'bath': '1bath', 'size-sqft': '1,276sqft', 'size-acre': '0.6acre lot', 'address': '268 State Route 32 S, New Paltz, NY 12561'}, {'price': '$3,375,000', 'bed': '6bed', 'bath': '5.5+bath', 'size-sqft': '7,996sqft', 'size-acre': '108acre lot', 'address': '28 Autumn Knl, New Paltz, NY 12561'}, {'price': '$449,000', 'bed': '3bed', 'bath': '1bath', 'size-sqft': '1,662sqft', 'size-acre': '1.88acre lot', 'address': '10 Joalyn Rd, New Paltz, NY 12561'}, {'price': '$550,000', 'bed': '4bed', 'bath': '3.5bath', 'size-sqft': '2,776sqft', 'size-acre': '1.05acre lot', 'address': '19 Meadow Rd, New Paltz, NY 12561'}, {'price': '$399,000', 'bed': '3bed', 'bath': '1bath', 'size-sqft': '950sqft', 'size-acre': '2acre lot', 'address': '23 Tracy Rd, New Paltz, NY 12561'}, {'price': '$619,000', 'bed': '4bed', 'bath': '3bath', 'size-sqft': '3,100sqft', 'size-acre': '5.2acre lot', 'address': '20 Carroll Ln, New Paltz, NY 12561'}, {'price': '$1,200,000', 'bed': '6bed', 'bath': '5.5bath', 'size-sqft': '4,112sqft', 'size-acre': '3.3acre lot', 'address': '55 Shivertown Rd, New Paltz, NY 12561'}, {'price': '$425,000', 'bed': '3bed', 'bath': '1.5bath', 'size-sqft': '1,558sqft', 'size-acre': '0.88acre lot', 'address': '5 Cicero Ave, New Paltz, NY 12561'}, {'price': '$650,000', 'bed': '6bed', 'bath': '3bath', 'size-sqft': '3,542sqft', 'size-acre': '9.4acre lot', 'address': '699 N Ohioville Rd, New Paltz, NY 12561'}, {'price': '$524,900', 'bed': '4bed', 'bath': '2.5bath', 'size-sqft': '2,080sqft', 'size-acre': '0.87acre lot', 'address': '210 Horsenden Rd, New Paltz, NY 12561'}, {'price': '$379,999', 'bed': '2bed', 'bath': '1bath', 'size-sqft': '1,280sqft', 'size-acre': '0.53acre lot', 'address': '318 N State Route 32, New Paltz, NY 12561'}, {'price': '$589,999', 'bed': '4bed', 'bath': '3bath', 'size-sqft': '2,300sqft', 'size-acre': '1.5acre lot', 'address': '219 S Ohioville Rd, New Paltz, NY 12561'}, {'price': '$525,000', 'bed': '4bed', 'bath': '2.5bath', 'size-sqft': '1,812sqft', 'size-acre': '0.35acre lot', 'address': '35 Bonticou View Dr, New Paltz, NY 12561'}, {'price': '$699,000', 'bed': '3bed', 'bath': '2.5bath', 'size-sqft': '1,683sqft', 'size-acre': '10.87acre lot', 'address': '22 Cragswood Rd, New Paltz, NY 12561'}, {'price': '$1,225,000', 'bed': '3bed', 'bath': '2.5bath', 'size-sqft': '2,800sqft', 'size-acre': '5acre lot', 'address': '16 High Pasture Rd, New Paltz, NY 12561'}, {'price': '$1,495,000', 'bed': '4bed', 'bath': '2.5bath', 'size-sqft': '3,403sqft', 'size-acre': '5.93acre lot', 'address': '15 Cross Creek Rd, New Paltz, NY 12561'}, {'price': '$699,999', 'bed': '5bed', 'bath': '3bath', 'size-sqft': '1,956sqft', 'size-acre': '0.8acre lot', 'address': '265 Rt 32 N, New Paltz, NY 12561'}, {'price': '$1,495,000', 'bed': '4bed', 'bath': '2.5bath', 'size-sqft': '3,428sqft', 'size-acre': None, 'address': '430 State Route 208, New Paltz, NY 12561'}, {'price': '$599,999', 'bed': '3bed', 'bath': '3bath', 'size-sqft': '2,513sqft', 'size-acre': '0.43acre lot', 'address': '6 Old Mill Rd, New Paltz, NY 12561'}, {'price': '$2,750,000', 'bed': '3bed', 'bath': '2.5bath', 'size-sqft': '2,400sqft', 'size-acre': '20.36acre lot', 'address': '44 Rocky Hill Rd, New Paltz, NY 12561'}, {'price': '$1,100,000', 'bed': '5bed', 'bath': '3bath', 'size-sqft': '5,638sqft', 'size-acre': '5acre lot', 'address': '191 Huguenot St, New Paltz, NY 12561'}, {'price': '$1,100,000', 'bed': '4bed', 'bath': '3bath', 'size-sqft': '2,540sqft', 'size-acre': '9.7acre lot', 'address': '100 Red Barn Rd, New Paltz, NY 12561'}]
Complete Code
You can make a few more changes to get more details from the page. You can scrape images, etc. But for now, the code will look somewhat like this.
import requests
from bs4 import BeautifulSoup
l=[]
o={}
target_url = "https://www.realtor.com/realestateandhomes-search/New-Paltz_NY/type-single-family-home,multi-family-home"
head={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"}
resp = requests.get(target_url, headers=head)
print(resp.status_code)
soup = BeautifulSoup(resp.text, 'html.parser')
allData = soup.find_all("div",{"class":"BasePropertyCard_propertyCardWrap__30VCU"})
for i in range(0, len(allData)):
try:
o["price"]=allData[i].find("div",{"class":"price-wrapper"}).text
except:
o["price"]=None
try:
metaData = allData[i].find("ul",{"class":"PropertyMetastyles__StyledPropertyMeta-rui__sc-1g5rdjn-0"})
except:
metaData=None
if(metaData is not None):
allMeta = metaData.find_all("li")
for x in range(0, len(allMeta)):
try:
o["bed"]=allMeta[0].text
except:
o["bed"]=None
try:
o["bath"]=allMeta[1].text
except:
o["bath"]=None
try:
o["size-sqft"]=allMeta[2].text
except:
o["size-sqft"]=None
try:
o["size-acre"]=allMeta[3].text
except:
o["size-acre"]=None
try:
o["address"]=allData[i].find("div",{"class":"content-col-left"}).text
except:
o["address"]=None
l.append(o)
o={}
print(l)
Now there are some limitations when it comes to scraping realtor like this.
Realtor.com will start blocking your IP if it finds out that a script is trying to access its data at a rapid pace.
To avoid this we are going to use Scrapingdog Web Scraping API to scrape Realtor at scale without getting blocked.
Using Scrapingdog for Scraping Realtor
Scrapingdog’s scraping API can be used to extract data from any website including Realtor.com.
You can start using Scrapingdog in seconds by just signing up. You can sign up from here and in the free pack, you will get 1000 free API credits. It will use new IP on every new request.
Once you sign up, you will be redirected to your dashboard. The dashboard will look somewhat like this.

Scrapingdog Dashboard
Now, you can paste your target realtor page link to the left and then select JS Rendering as No. After this click on Copy Code from the right. Now use this API in your script to scrape realtor.
The code will remain the same as above but we just have to replace the target URL with the Scraping API URL.
import requests
from bs4 import BeautifulSoup
l=[]
o={}
target_url = "https://api.scrapingdog.com/scrape?api_key=Your-API-Key&url=https://www.realtor.com/realestateandhomes-search/New-Paltz_NY/type-single-family-home,multi-family-home&dynamic=false"
# head={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"}
resp = requests.get(target_url)
print(resp.status_code)
soup = BeautifulSoup(resp.text, 'html.parser')
allData = soup.find_all("div",{"class":"BasePropertyCard_propertyCardWrap__30VCU"})
for i in range(0, len(allData)):
try:
o["price"]=allData[i].find("div",{"class":"price-wrapper"}).text
except:
o["price"]=None
try:
metaData = allData[i].find("ul",{"class":"PropertyMetastyles__StyledPropertyMeta-rui__sc-1g5rdjn-0"})
except:
metaData=None
if(metaData is not None):
allMeta = metaData.find_all("li")
for x in range(0, len(allMeta)):
try:
o["bed"]=allMeta[0].text
except:
o["bed"]=None
try:
o["bath"]=allMeta[1].text
except:
o["bath"]=None
try:
o["size-sqft"]=allMeta[2].text
except:
o["size-sqft"]=None
try:
o["size-acre"]=allMeta[3].text
except:
o["size-acre"]=None
try:
o["address"]=allData[i].find("div",{"class":"content-col-left"}).text
except:
o["address"]=None
l.append(o)
o={}
print(l)
Do remember to use your API key while using this script. Just like this Scrapingdog can be used for scraping any website without getting BLOCKED.
Conclusion
In this tutorial, we managed to scrape property prices for a given area from Realtor. If you want to scrape Realtor at scale then you might require a web scraping API that can handle all the hassle of proxy rotation and headless browsers.
You can scrape all the other pages by making changes to the target URL. You have to find the change in the URL structure once you click Next from the bottom of the page. In this manner, you will be able to scrape the data from the next page as well.
I hope you like this little tutorial and if you do then please do not forget to share it with your friends and on your social media.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:


