
TL;DR
cURLscraping basics:GET/POST, custom headers, cookies, Basic Auth, proxies.- At scale you’ll hit blocks — use rotating proxies or a scraping API.
- Shows proxy setup; Scrapingdog proxies / API handle rotation, headless, retries.
- Error handling with status-code printing and a simple retry loop.
Features of cURL:
- It provides SSL/TLS support.
- You can pass cookies.
- Pass custom headers like User-Agent, Accept, etc.
- You can use a proxy while making a request to any host.
cURL can be used on any operating system such as Windows, MacOS, Linux, etc. cURL is already installed in all the operating systems and you can verify it by typing curl or curl --helpon your cmd.
How to use cURL?
Let’s understand how cURL can be used with multiple different examples.
The basic syntax for using cURL will always be the same.
curl [options] [url]
How to make a GET request with cURL
Let’s say you want to make an HTTP GET request to this URL. Then it can be done simply like this.
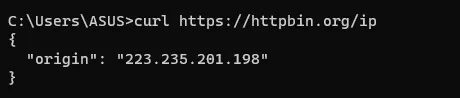
curl https://httpbin.org/ip
The response will look like this.
How to make a POST request with cURL
Let’s assume you want to make a POST request to an API that returns JSON data then this is how you can do it.
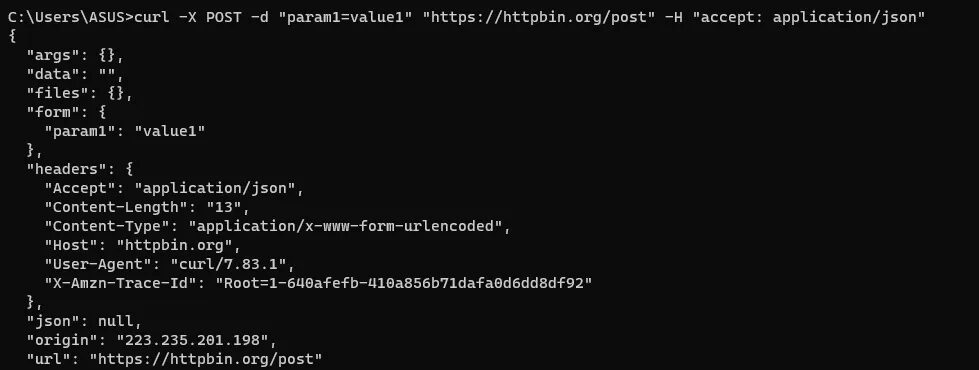
curl -X POST -d "param1=value1" "https://httpbin.org/post" -H "accept: application/json"
Here -d represents --data command line parameter. -X will tell which HTTP method will be used and -H is used for sending headers. accept: application/json is the way of telling the server that we need the response in JSON.
We have made a dedicated page on How to get JSON with cURL in brief here. You can check that out too!!
How to use authentication with cURL
curl -X GET -u admin:admin "https://httpbin.org/basic-auth/admin/admin" -H "accept: application/json"
- We have used
-Xto specify which HTTP method we are going to use. In the current scenario, we are making a GET request. -uis used to pass credentials. In general, it is known as Basic Authentication. Here username is admin and the password is also admin.- Then we passed our target URL. On this URL we are performing a GET request.
- The last step is to pass headers. For this, we have used
-Hto pass accept header.
The response will look like this.

Read More: Send HTTP header using cURL
These are some of the few applications in which cURL can be used directly from your CMD. You can even download data from a website into a file or upload files to a random FTP server using cURL. Let’s try one more example.
We have made a concise page to further understand cURL Basic Authentication. Do check it out too!!
How to use cURL in web scraping?
Let’s say you want to scrape amazon.com with cURL and your target page is this.
curl -X GET "https://www.amazon.com/dp/B09ZW52XSQ" -H "User-Agent: Mozilla/5.0 (Linux; Android 8.0.0; SM-G955U Build/R16NW) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Mobile Safari/537.36, Accept-Encoding:gzip,deflate"
With this command, you will be able to scrape data from amazon. But what if you want to scrape millions of such pages? In this case, this technique will not work because amazon will block your IP due to excessive HTTP connection at a short interval of time. The only way to bypass this limitation is to use a web scraping API or a rotating proxy.
How to use a proxy with cURL?
Passing a proxy while making a GET request through cURL is super simple.
curl -x <proxy-server>:<port> -U <username>:<password> <URL>
Here -x is used to pass the proxy URL or the IP and -U is used to pass the username and password if the proxy requires authentication.
Let’s use a free proxy and understand how it can help you scrape amazon or any such website at scale.
If you sign up to Scrapingdog you will find an API Key on your dashboard. That API Key will be used as a password for the proxy. You can consider reading the docs before using the proxy but the usage is pretty straightforward.
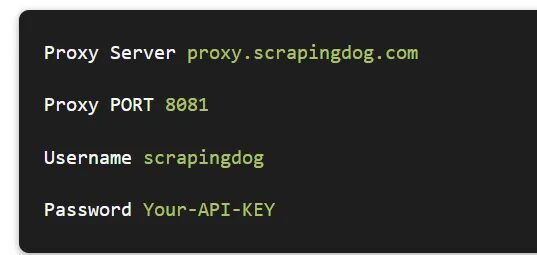
Let’s use this information to make a request to amazon.
curl -x proxy.scrapingdog.com:8081 -U scrapingdog:YOUR-API-KEY https://www.amazon.com/dp/B09ZW52XSQ
This cURL command will make a GET request to Amazon with new IP on every single request. This will avoid any blockage of your data pipeline from Amazon.
What if you don’t want to pass a proxy and handle retries in case a request fails? Well, then you can use a Scraping API which will handle all the retries, headers, headless chrome, etc.
How to use a Web Scraping API with cURL?
Using a scraping API with cURL is dead simple. All you have to do is to make a GET request. I have already explained to you how you can make a GET request using cURL.
To understand how the API works please read the docs from here.
API URL will look like this — https://api.scrapingdog.com/scrape?api_key=YOUR-API-KEY&url=https://www.amazon.com/dp/B09ZW52XSQ
So, the cURL command will look like this.
curl https://api.scrapingdog.com/scrape?api_key=YOUR-API-KEY&url=https://www.amazon.com/dp/B09ZW52XSQ
This will make a GET request and will return the data from amazon.
Advantages of using API over proxy
- You don’t have to manage headless chrome.
- You don’t have to make retries on request failure. API will handle it on its own.
- Proxy management will be done by the API itself. API has the ability to pick the right proxy on its own depending on the website you want to scrape.
Handling errors and exceptions with cURL
It is necessary to handle errors while doing web scraping. Web Scraping can be tedious if errors are not handled properly. Let’s discuss some techniques to handle such a situation.
How to check the status code of the request in cURL?
In general, we always check the status code of the response to check whether the API request was successful or not. In cURL also you can track the status of the request.
curl -s -o /dev/null -w "%{http_code}" https://scrapingdog.com
-sallows us to suppress any output to the console. That means the output will not be shown on the console.-owill redirect the output to /dev/null instead of any file. /dev/null is kind of a black hole that discards any input. It is used when you don’t want to see it or store it.-wwill print the response code on the console. This will help us identify whether the API request was successful or not.
How to retry the request with cURL if the request fails?
What if the request fails and you have to retry manually? Well, the alternative for this is to use a for loop. If the request fails you can wait for 5 seconds and if the request was successful then you can break out of the for loop.
for i in {1..5}; do curl -s https://scrapingdog.com && break || sleep 5; done
The loop will run five times with a 5-second gap in case the request keeps failing.
Key Takeaways:
The guide explains how to use cURL, a command-line tool, to send HTTP requests and retrieve web page content for scraping.
It shows how to customize request headers, user-agents, and query parameters to mimic browser behavior.
You learn how to use cURL options to follow redirects, handle cookies, and manage authentication when needed.
The tutorial demonstrates saving the scraped output to a file, making it easier to parse later with other tools or scripts.
Using cURL for scraping is lightweight and powerful, especially for quick data fetching and testing without full code.
Conclusion
Web Scraping with cURL is fun and simple. In this article, we focused on understanding the various features cURL has to offer. Right from making a GET request to error handling we covered every topic. Of course, there are endless features cURL has to offer.
cURL can be used for parsing data as well. Overall it is a reliable tool with great community support. You can customize it according to your demands. You can automate your web scraping with cURL in just a few steps.
I hope you like this little tutorial on how you can perform web scraping with cURL. It would great if you can share this article on your social platforms.
Additional Resources
Here are a few additional resources that you may find helpful during your web scraping journey:


