
TL;DR
- Node.js tutorial: use
node-fetch+Cheerioto grab HTML, parse data, and writeJSON. - Flow: install deps, enable ESM, fetch, select / loop items, save
data.json(full code shown). - Anti-bot: set a real
User-Agent; add proxies viahttps-proxy-agent. - For scale, Scrapingdog handles rotation, headless, and CAPTCHAs.
The Fetch API’s introduction changed how JavaScript developers handle HTTP requests. Now, developers don’t need to use third-party packages to make an HTTP request. This is especially good news for front-end developers because the fetch function is only for browser use.
Backend developers used to need different third-party packages until node-fetch was introduced. Node-fetch brings the same fetch API functionality to the backend that browsers have. In this article, we’ll look at how you can use node-fetch for web scraping.
Prerequisites
Before you start, make sure you meet all the following requirements:
- You’ll need Node.js installed on your machine. Download it from the official Node.js download page. This tutorial uses Node.js version 20.12.2 with npm 10.7.0, the latest LTS version at the time of writing.
- You’ll need a code editor like VS Code or Atom installed on your machine.
- You should have experience writing ES6 JavaScript, understanding promises, and async/await.
Understanding the node-fetch
The Fetch API provides an interface for making asynchronous HTTP requests in modern browsers. It is based on promises, making it a powerful tool for working with asynchronous code.
Node Fetch is a widely used lightweight module that brings the Fetch API to Node.js. It allows you to use the fetch function in Node.js as you would use window.fetch in native JavaScript but with a few differences.
One can connect to remote servers and fetch or post data from an external web server or API, making it a suitable tool for various tasks, including Node.js web scraping.
Read More: Web Scraping with Node.Js
How to use node-fetch?
npm install node-fetch
npm install node-fetch@2
import fetch from 'node-fetch';
const response = await fetch('<https://github.com/>');
const body = await response.text();
console.log(body);
Basics of Cheerio
load() function. This function takes a string containing the HTML as an argument and returns an object.
import cheerio from 'cheerio';
const htmlMarkup = `<html>
<head>
<title>Cheerio Demo</title>
</head>
<body>
<p>Hello, developers!</p> <script data-no-optimize="1">window.lazyLoadOptions=Object.assign({},{threshold:300},window.lazyLoadOptions||{});!function(t,e){"object"==typeof exports&&"undefined"!=typeof module?module.exports=e():"function"==typeof define&&define.amd?define(e):(t="undefined"!=typeof globalThis?globalThis:t||self).LazyLoad=e()}(this,function(){"use strict";function e(){return(e=Object.assign||function(t){for(var e=1;e<arguments.length;e++){var n,a=arguments[e];for(n in a)Object.prototype.hasOwnProperty.call(a,n)&&(t[n]=a[n])}return t}).apply(this,arguments)}function o(t){return e({},at,t)}function l(t,e){return t.getAttribute(gt+e)}function c(t){return l(t,vt)}function s(t,e){return function(t,e,n){e=gt+e;null!==n?t.setAttribute(e,n):t.removeAttribute(e)}(t,vt,e)}function i(t){return s(t,null),0}function r(t){return null===c(t)}function u(t){return c(t)===_t}function d(t,e,n,a){t&&(void 0===a?void 0===n?t(e):t(e,n):t(e,n,a))}function f(t,e){et?t.classList.add(e):t.className+=(t.className?" ":"")+e}function _(t,e){et?t.classList.remove(e):t.className=t.className.replace(new RegExp("(^|\\s+)"+e+"(\\s+|$)")," ").replace(/^\s+/,"").replace(/\s+$/,"")}function g(t){return t.llTempImage}function v(t,e){!e||(e=e._observer)&&e.unobserve(t)}function b(t,e){t&&(t.loadingCount+=e)}function p(t,e){t&&(t.toLoadCount=e)}function n(t){for(var e,n=[],a=0;e=t.children[a];a+=1)"SOURCE"===e.tagName&&n.push(e);return n}function h(t,e){(t=t.parentNode)&&"PICTURE"===t.tagName&&n(t).forEach(e)}function a(t,e){n(t).forEach(e)}function m(t){return!!t[lt]}function E(t){return t[lt]}function I(t){return delete t[lt]}function y(e,t){var n;m(e)||(n={},t.forEach(function(t){n[t]=e.getAttribute(t)}),e[lt]=n)}function L(a,t){var o;m(a)&&(o=E(a),t.forEach(function(t){var e,n;e=a,(t=o[n=t])?e.setAttribute(n,t):e.removeAttribute(n)}))}function k(t,e,n){f(t,e.class_loading),s(t,st),n&&(b(n,1),d(e.callback_loading,t,n))}function A(t,e,n){n&&t.setAttribute(e,n)}function O(t,e){A(t,rt,l(t,e.data_sizes)),A(t,it,l(t,e.data_srcset)),A(t,ot,l(t,e.data_src))}function w(t,e,n){var a=l(t,e.data_bg_multi),o=l(t,e.data_bg_multi_hidpi);(a=nt&&o?o:a)&&(t.style.backgroundImage=a,n=n,f(t=t,(e=e).class_applied),s(t,dt),n&&(e.unobserve_completed&&v(t,e),d(e.callback_applied,t,n)))}function x(t,e){!e||0<e.loadingCount||0<e.toLoadCount||d(t.callback_finish,e)}function M(t,e,n){t.addEventListener(e,n),t.llEvLisnrs[e]=n}function N(t){return!!t.llEvLisnrs}function z(t){if(N(t)){var e,n,a=t.llEvLisnrs;for(e in a){var o=a[e];n=e,o=o,t.removeEventListener(n,o)}delete t.llEvLisnrs}}function C(t,e,n){var a;delete t.llTempImage,b(n,-1),(a=n)&&--a.toLoadCount,_(t,e.class_loading),e.unobserve_completed&&v(t,n)}function R(i,r,c){var l=g(i)||i;N(l)||function(t,e,n){N(t)||(t.llEvLisnrs={});var a="VIDEO"===t.tagName?"loadeddata":"load";M(t,a,e),M(t,"error",n)}(l,function(t){var e,n,a,o;n=r,a=c,o=u(e=i),C(e,n,a),f(e,n.class_loaded),s(e,ut),d(n.callback_loaded,e,a),o||x(n,a),z(l)},function(t){var e,n,a,o;n=r,a=c,o=u(e=i),C(e,n,a),f(e,n.class_error),s(e,ft),d(n.callback_error,e,a),o||x(n,a),z(l)})}function T(t,e,n){var a,o,i,r,c;t.llTempImage=document.createElement("IMG"),R(t,e,n),m(c=t)||(c[lt]={backgroundImage:c.style.backgroundImage}),i=n,r=l(a=t,(o=e).data_bg),c=l(a,o.data_bg_hidpi),(r=nt&&c?c:r)&&(a.style.backgroundImage='url("'.concat(r,'")'),g(a).setAttribute(ot,r),k(a,o,i)),w(t,e,n)}function G(t,e,n){var a;R(t,e,n),a=e,e=n,(t=Et[(n=t).tagName])&&(t(n,a),k(n,a,e))}function D(t,e,n){var a;a=t,(-1<It.indexOf(a.tagName)?G:T)(t,e,n)}function S(t,e,n){var a;t.setAttribute("loading","lazy"),R(t,e,n),a=e,(e=Et[(n=t).tagName])&&e(n,a),s(t,_t)}function V(t){t.removeAttribute(ot),t.removeAttribute(it),t.removeAttribute(rt)}function j(t){h(t,function(t){L(t,mt)}),L(t,mt)}function F(t){var e;(e=yt[t.tagName])?e(t):m(e=t)&&(t=E(e),e.style.backgroundImage=t.backgroundImage)}function P(t,e){var n;F(t),n=e,r(e=t)||u(e)||(_(e,n.class_entered),_(e,n.class_exited),_(e,n.class_applied),_(e,n.class_loading),_(e,n.class_loaded),_(e,n.class_error)),i(t),I(t)}function U(t,e,n,a){var o;n.cancel_on_exit&&(c(t)!==st||"IMG"===t.tagName&&(z(t),h(o=t,function(t){V(t)}),V(o),j(t),_(t,n.class_loading),b(a,-1),i(t),d(n.callback_cancel,t,e,a)))}function $(t,e,n,a){var o,i,r=(i=t,0<=bt.indexOf(c(i)));s(t,"entered"),f(t,n.class_entered),_(t,n.class_exited),o=t,i=a,n.unobserve_entered&&v(o,i),d(n.callback_enter,t,e,a),r||D(t,n,a)}function q(t){return t.use_native&&"loading"in HTMLImageElement.prototype}function H(t,o,i){t.forEach(function(t){return(a=t).isIntersecting||0<a.intersectionRatio?$(t.target,t,o,i):(e=t.target,n=t,a=o,t=i,void(r(e)||(f(e,a.class_exited),U(e,n,a,t),d(a.callback_exit,e,n,t))));var e,n,a})}function B(e,n){var t;tt&&!q(e)&&(n._observer=new IntersectionObserver(function(t){H(t,e,n)},{root:(t=e).container===document?null:t.container,rootMargin:t.thresholds||t.threshold+"px"}))}function J(t){return Array.prototype.slice.call(t)}function K(t){return t.container.querySelectorAll(t.elements_selector)}function Q(t){return c(t)===ft}function W(t,e){return e=t||K(e),J(e).filter(r)}function X(e,t){var n;(n=K(e),J(n).filter(Q)).forEach(function(t){_(t,e.class_error),i(t)}),t.update()}function t(t,e){var n,a,t=o(t);this._settings=t,this.loadingCount=0,B(t,this),n=t,a=this,Y&&window.addEventListener("online",function(){X(n,a)}),this.update(e)}var Y="undefined"!=typeof window,Z=Y&&!("onscroll"in window)||"undefined"!=typeof navigator&&/(gle|ing|ro)bot|crawl|spider/i.test(navigator.userAgent),tt=Y&&"IntersectionObserver"in window,et=Y&&"classList"in document.createElement("p"),nt=Y&&1<window.devicePixelRatio,at={elements_selector:".lazy",container:Z||Y?document:null,threshold:300,thresholds:null,data_src:"src",data_srcset:"srcset",data_sizes:"sizes",data_bg:"bg",data_bg_hidpi:"bg-hidpi",data_bg_multi:"bg-multi",data_bg_multi_hidpi:"bg-multi-hidpi",data_poster:"poster",class_applied:"applied",class_loading:"litespeed-loading",class_loaded:"litespeed-loaded",class_error:"error",class_entered:"entered",class_exited:"exited",unobserve_completed:!0,unobserve_entered:!1,cancel_on_exit:!0,callback_enter:null,callback_exit:null,callback_applied:null,callback_loading:null,callback_loaded:null,callback_error:null,callback_finish:null,callback_cancel:null,use_native:!1},ot="src",it="srcset",rt="sizes",ct="poster",lt="llOriginalAttrs",st="loading",ut="loaded",dt="applied",ft="error",_t="native",gt="data-",vt="ll-status",bt=[st,ut,dt,ft],pt=[ot],ht=[ot,ct],mt=[ot,it,rt],Et={IMG:function(t,e){h(t,function(t){y(t,mt),O(t,e)}),y(t,mt),O(t,e)},IFRAME:function(t,e){y(t,pt),A(t,ot,l(t,e.data_src))},VIDEO:function(t,e){a(t,function(t){y(t,pt),A(t,ot,l(t,e.data_src))}),y(t,ht),A(t,ct,l(t,e.data_poster)),A(t,ot,l(t,e.data_src)),t.load()}},It=["IMG","IFRAME","VIDEO"],yt={IMG:j,IFRAME:function(t){L(t,pt)},VIDEO:function(t){a(t,function(t){L(t,pt)}),L(t,ht),t.load()}},Lt=["IMG","IFRAME","VIDEO"];return t.prototype={update:function(t){var e,n,a,o=this._settings,i=W(t,o);{if(p(this,i.length),!Z&&tt)return q(o)?(e=o,n=this,i.forEach(function(t){-1!==Lt.indexOf(t.tagName)&&S(t,e,n)}),void p(n,0)):(t=this._observer,o=i,t.disconnect(),a=t,void o.forEach(function(t){a.observe(t)}));this.loadAll(i)}},destroy:function(){this._observer&&this._observer.disconnect(),K(this._settings).forEach(function(t){I(t)}),delete this._observer,delete this._settings,delete this.loadingCount,delete this.toLoadCount},loadAll:function(t){var e=this,n=this._settings;W(t,n).forEach(function(t){v(t,e),D(t,n,e)})},restoreAll:function(){var e=this._settings;K(e).forEach(function(t){P(t,e)})}},t.load=function(t,e){e=o(e);D(t,e)},t.resetStatus=function(t){i(t)},t}),function(t,e){"use strict";function n(){e.body.classList.add("litespeed_lazyloaded")}function a(){console.log("[LiteSpeed] Start Lazy Load"),o=new LazyLoad(Object.assign({},t.lazyLoadOptions||{},{elements_selector:"[data-lazyloaded]",callback_finish:n})),i=function(){o.update()},t.MutationObserver&&new MutationObserver(i).observe(e.documentElement,{childList:!0,subtree:!0,attributes:!0})}var o,i;t.addEventListener?t.addEventListener("load",a,!1):t.attachEvent("onload",a)}(window,document);</script><script data-no-optimize="1">window.litespeed_ui_events=window.litespeed_ui_events||["mouseover","click","keydown","wheel","touchmove","touchstart"];var urlCreator=window.URL||window.webkitURL;function litespeed_load_delayed_js_force(){console.log("[LiteSpeed] Start Load JS Delayed"),litespeed_ui_events.forEach(e=>{window.removeEventListener(e,litespeed_load_delayed_js_force,{passive:!0})}),document.querySelectorAll("iframe[data-litespeed-src]").forEach(e=>{e.setAttribute("src",e.getAttribute("data-litespeed-src"))}),"loading"==document.readyState?window.addEventListener("DOMContentLoaded",litespeed_load_delayed_js):litespeed_load_delayed_js()}litespeed_ui_events.forEach(e=>{window.addEventListener(e,litespeed_load_delayed_js_force,{passive:!0})});async function litespeed_load_delayed_js(){let t=[];for(var d in document.querySelectorAll('script[type="litespeed/javascript"]').forEach(e=>{t.push(e)}),t)await new Promise(e=>litespeed_load_one(t[d],e));document.dispatchEvent(new Event("DOMContentLiteSpeedLoaded")),window.dispatchEvent(new Event("DOMContentLiteSpeedLoaded"))}function litespeed_load_one(t,e){console.log("[LiteSpeed] Load ",t);var d=document.createElement("script");d.addEventListener("load",e),d.addEventListener("error",e),t.getAttributeNames().forEach(e=>{"type"!=e&&d.setAttribute("data-src"==e?"src":e,t.getAttribute(e))});let a=!(d.type="text/javascript");!d.src&&t.textContent&&(d.src=litespeed_inline2src(t.textContent),a=!0),t.after(d),t.remove(),a&&e()}function litespeed_inline2src(t){try{var d=urlCreator.createObjectURL(new Blob([t.replace(/^(?:<!--)?(.*?)(?:-->)?$/gm,"$1")],{type:"text/javascript"}))}catch(e){d="data:text/javascript;base64,"+btoa(t.replace(/^(?:<!--)?(.*?)(?:-->)?$/gm,"$1"))}return d}</script><script data-no-optimize="1">var litespeed_vary=document.cookie.replace(/(?:(?:^|.*;\s*)_lscache_vary\s*\=\s*([^;]*).*$)|^.*$/,"");litespeed_vary||(sessionStorage.getItem("litespeed_reloaded")?console.log("LiteSpeed: skipping guest vary reload (already reloaded this session)"):fetch("/wp-content/plugins/litespeed-cache/guest.vary.php",{method:"POST",cache:"no-cache",redirect:"follow"}).then(e=>e.json()).then(e=>{console.log(e),e.hasOwnProperty("reload")&&"yes"==e.reload&&(sessionStorage.setItem("litespeed_docref",document.referrer),sessionStorage.setItem("litespeed_reloaded","1"),window.location.reload(!0))}));</script><script data-optimized="1" type="litespeed/javascript" data-src="https://www.scrapingdog.com/wp-content/litespeed/js/227bd2a37b2cfa71fb46d1b313444708.js?ver=e89e0"></script></body>
</html >`;
const $ = cheerio.load(htmlMarkup);
import cheerio from 'cheerio';
const htmlMarkup = `
<html>
<head>
<title>Cheerio Demo</title>
</head>
<body>
<p>Hello, developers.</p>
<p>Coding is fun.</p>
<p>Code all day and night.</p> <script data-no-optimize="1">window.lazyLoadOptions=Object.assign({},{threshold:300},window.lazyLoadOptions||{});!function(t,e){"object"==typeof exports&&"undefined"!=typeof module?module.exports=e():"function"==typeof define&&define.amd?define(e):(t="undefined"!=typeof globalThis?globalThis:t||self).LazyLoad=e()}(this,function(){"use strict";function e(){return(e=Object.assign||function(t){for(var e=1;e<arguments.length;e++){var n,a=arguments[e];for(n in a)Object.prototype.hasOwnProperty.call(a,n)&&(t[n]=a[n])}return t}).apply(this,arguments)}function o(t){return e({},at,t)}function l(t,e){return t.getAttribute(gt+e)}function c(t){return l(t,vt)}function s(t,e){return function(t,e,n){e=gt+e;null!==n?t.setAttribute(e,n):t.removeAttribute(e)}(t,vt,e)}function i(t){return s(t,null),0}function r(t){return null===c(t)}function u(t){return c(t)===_t}function d(t,e,n,a){t&&(void 0===a?void 0===n?t(e):t(e,n):t(e,n,a))}function f(t,e){et?t.classList.add(e):t.className+=(t.className?" ":"")+e}function _(t,e){et?t.classList.remove(e):t.className=t.className.replace(new RegExp("(^|\\s+)"+e+"(\\s+|$)")," ").replace(/^\s+/,"").replace(/\s+$/,"")}function g(t){return t.llTempImage}function v(t,e){!e||(e=e._observer)&&e.unobserve(t)}function b(t,e){t&&(t.loadingCount+=e)}function p(t,e){t&&(t.toLoadCount=e)}function n(t){for(var e,n=[],a=0;e=t.children[a];a+=1)"SOURCE"===e.tagName&&n.push(e);return n}function h(t,e){(t=t.parentNode)&&"PICTURE"===t.tagName&&n(t).forEach(e)}function a(t,e){n(t).forEach(e)}function m(t){return!!t[lt]}function E(t){return t[lt]}function I(t){return delete t[lt]}function y(e,t){var n;m(e)||(n={},t.forEach(function(t){n[t]=e.getAttribute(t)}),e[lt]=n)}function L(a,t){var o;m(a)&&(o=E(a),t.forEach(function(t){var e,n;e=a,(t=o[n=t])?e.setAttribute(n,t):e.removeAttribute(n)}))}function k(t,e,n){f(t,e.class_loading),s(t,st),n&&(b(n,1),d(e.callback_loading,t,n))}function A(t,e,n){n&&t.setAttribute(e,n)}function O(t,e){A(t,rt,l(t,e.data_sizes)),A(t,it,l(t,e.data_srcset)),A(t,ot,l(t,e.data_src))}function w(t,e,n){var a=l(t,e.data_bg_multi),o=l(t,e.data_bg_multi_hidpi);(a=nt&&o?o:a)&&(t.style.backgroundImage=a,n=n,f(t=t,(e=e).class_applied),s(t,dt),n&&(e.unobserve_completed&&v(t,e),d(e.callback_applied,t,n)))}function x(t,e){!e||0<e.loadingCount||0<e.toLoadCount||d(t.callback_finish,e)}function M(t,e,n){t.addEventListener(e,n),t.llEvLisnrs[e]=n}function N(t){return!!t.llEvLisnrs}function z(t){if(N(t)){var e,n,a=t.llEvLisnrs;for(e in a){var o=a[e];n=e,o=o,t.removeEventListener(n,o)}delete t.llEvLisnrs}}function C(t,e,n){var a;delete t.llTempImage,b(n,-1),(a=n)&&--a.toLoadCount,_(t,e.class_loading),e.unobserve_completed&&v(t,n)}function R(i,r,c){var l=g(i)||i;N(l)||function(t,e,n){N(t)||(t.llEvLisnrs={});var a="VIDEO"===t.tagName?"loadeddata":"load";M(t,a,e),M(t,"error",n)}(l,function(t){var e,n,a,o;n=r,a=c,o=u(e=i),C(e,n,a),f(e,n.class_loaded),s(e,ut),d(n.callback_loaded,e,a),o||x(n,a),z(l)},function(t){var e,n,a,o;n=r,a=c,o=u(e=i),C(e,n,a),f(e,n.class_error),s(e,ft),d(n.callback_error,e,a),o||x(n,a),z(l)})}function T(t,e,n){var a,o,i,r,c;t.llTempImage=document.createElement("IMG"),R(t,e,n),m(c=t)||(c[lt]={backgroundImage:c.style.backgroundImage}),i=n,r=l(a=t,(o=e).data_bg),c=l(a,o.data_bg_hidpi),(r=nt&&c?c:r)&&(a.style.backgroundImage='url("'.concat(r,'")'),g(a).setAttribute(ot,r),k(a,o,i)),w(t,e,n)}function G(t,e,n){var a;R(t,e,n),a=e,e=n,(t=Et[(n=t).tagName])&&(t(n,a),k(n,a,e))}function D(t,e,n){var a;a=t,(-1<It.indexOf(a.tagName)?G:T)(t,e,n)}function S(t,e,n){var a;t.setAttribute("loading","lazy"),R(t,e,n),a=e,(e=Et[(n=t).tagName])&&e(n,a),s(t,_t)}function V(t){t.removeAttribute(ot),t.removeAttribute(it),t.removeAttribute(rt)}function j(t){h(t,function(t){L(t,mt)}),L(t,mt)}function F(t){var e;(e=yt[t.tagName])?e(t):m(e=t)&&(t=E(e),e.style.backgroundImage=t.backgroundImage)}function P(t,e){var n;F(t),n=e,r(e=t)||u(e)||(_(e,n.class_entered),_(e,n.class_exited),_(e,n.class_applied),_(e,n.class_loading),_(e,n.class_loaded),_(e,n.class_error)),i(t),I(t)}function U(t,e,n,a){var o;n.cancel_on_exit&&(c(t)!==st||"IMG"===t.tagName&&(z(t),h(o=t,function(t){V(t)}),V(o),j(t),_(t,n.class_loading),b(a,-1),i(t),d(n.callback_cancel,t,e,a)))}function $(t,e,n,a){var o,i,r=(i=t,0<=bt.indexOf(c(i)));s(t,"entered"),f(t,n.class_entered),_(t,n.class_exited),o=t,i=a,n.unobserve_entered&&v(o,i),d(n.callback_enter,t,e,a),r||D(t,n,a)}function q(t){return t.use_native&&"loading"in HTMLImageElement.prototype}function H(t,o,i){t.forEach(function(t){return(a=t).isIntersecting||0<a.intersectionRatio?$(t.target,t,o,i):(e=t.target,n=t,a=o,t=i,void(r(e)||(f(e,a.class_exited),U(e,n,a,t),d(a.callback_exit,e,n,t))));var e,n,a})}function B(e,n){var t;tt&&!q(e)&&(n._observer=new IntersectionObserver(function(t){H(t,e,n)},{root:(t=e).container===document?null:t.container,rootMargin:t.thresholds||t.threshold+"px"}))}function J(t){return Array.prototype.slice.call(t)}function K(t){return t.container.querySelectorAll(t.elements_selector)}function Q(t){return c(t)===ft}function W(t,e){return e=t||K(e),J(e).filter(r)}function X(e,t){var n;(n=K(e),J(n).filter(Q)).forEach(function(t){_(t,e.class_error),i(t)}),t.update()}function t(t,e){var n,a,t=o(t);this._settings=t,this.loadingCount=0,B(t,this),n=t,a=this,Y&&window.addEventListener("online",function(){X(n,a)}),this.update(e)}var Y="undefined"!=typeof window,Z=Y&&!("onscroll"in window)||"undefined"!=typeof navigator&&/(gle|ing|ro)bot|crawl|spider/i.test(navigator.userAgent),tt=Y&&"IntersectionObserver"in window,et=Y&&"classList"in document.createElement("p"),nt=Y&&1<window.devicePixelRatio,at={elements_selector:".lazy",container:Z||Y?document:null,threshold:300,thresholds:null,data_src:"src",data_srcset:"srcset",data_sizes:"sizes",data_bg:"bg",data_bg_hidpi:"bg-hidpi",data_bg_multi:"bg-multi",data_bg_multi_hidpi:"bg-multi-hidpi",data_poster:"poster",class_applied:"applied",class_loading:"litespeed-loading",class_loaded:"litespeed-loaded",class_error:"error",class_entered:"entered",class_exited:"exited",unobserve_completed:!0,unobserve_entered:!1,cancel_on_exit:!0,callback_enter:null,callback_exit:null,callback_applied:null,callback_loading:null,callback_loaded:null,callback_error:null,callback_finish:null,callback_cancel:null,use_native:!1},ot="src",it="srcset",rt="sizes",ct="poster",lt="llOriginalAttrs",st="loading",ut="loaded",dt="applied",ft="error",_t="native",gt="data-",vt="ll-status",bt=[st,ut,dt,ft],pt=[ot],ht=[ot,ct],mt=[ot,it,rt],Et={IMG:function(t,e){h(t,function(t){y(t,mt),O(t,e)}),y(t,mt),O(t,e)},IFRAME:function(t,e){y(t,pt),A(t,ot,l(t,e.data_src))},VIDEO:function(t,e){a(t,function(t){y(t,pt),A(t,ot,l(t,e.data_src))}),y(t,ht),A(t,ct,l(t,e.data_poster)),A(t,ot,l(t,e.data_src)),t.load()}},It=["IMG","IFRAME","VIDEO"],yt={IMG:j,IFRAME:function(t){L(t,pt)},VIDEO:function(t){a(t,function(t){L(t,pt)}),L(t,ht),t.load()}},Lt=["IMG","IFRAME","VIDEO"];return t.prototype={update:function(t){var e,n,a,o=this._settings,i=W(t,o);{if(p(this,i.length),!Z&&tt)return q(o)?(e=o,n=this,i.forEach(function(t){-1!==Lt.indexOf(t.tagName)&&S(t,e,n)}),void p(n,0)):(t=this._observer,o=i,t.disconnect(),a=t,void o.forEach(function(t){a.observe(t)}));this.loadAll(i)}},destroy:function(){this._observer&&this._observer.disconnect(),K(this._settings).forEach(function(t){I(t)}),delete this._observer,delete this._settings,delete this.loadingCount,delete this.toLoadCount},loadAll:function(t){var e=this,n=this._settings;W(t,n).forEach(function(t){v(t,e),D(t,n,e)})},restoreAll:function(){var e=this._settings;K(e).forEach(function(t){P(t,e)})}},t.load=function(t,e){e=o(e);D(t,e)},t.resetStatus=function(t){i(t)},t}),function(t,e){"use strict";function n(){e.body.classList.add("litespeed_lazyloaded")}function a(){console.log("[LiteSpeed] Start Lazy Load"),o=new LazyLoad(Object.assign({},t.lazyLoadOptions||{},{elements_selector:"[data-lazyloaded]",callback_finish:n})),i=function(){o.update()},t.MutationObserver&&new MutationObserver(i).observe(e.documentElement,{childList:!0,subtree:!0,attributes:!0})}var o,i;t.addEventListener?t.addEventListener("load",a,!1):t.attachEvent("onload",a)}(window,document);</script><script data-no-optimize="1">window.litespeed_ui_events=window.litespeed_ui_events||["mouseover","click","keydown","wheel","touchmove","touchstart"];var urlCreator=window.URL||window.webkitURL;function litespeed_load_delayed_js_force(){console.log("[LiteSpeed] Start Load JS Delayed"),litespeed_ui_events.forEach(e=>{window.removeEventListener(e,litespeed_load_delayed_js_force,{passive:!0})}),document.querySelectorAll("iframe[data-litespeed-src]").forEach(e=>{e.setAttribute("src",e.getAttribute("data-litespeed-src"))}),"loading"==document.readyState?window.addEventListener("DOMContentLoaded",litespeed_load_delayed_js):litespeed_load_delayed_js()}litespeed_ui_events.forEach(e=>{window.addEventListener(e,litespeed_load_delayed_js_force,{passive:!0})});async function litespeed_load_delayed_js(){let t=[];for(var d in document.querySelectorAll('script[type="litespeed/javascript"]').forEach(e=>{t.push(e)}),t)await new Promise(e=>litespeed_load_one(t[d],e));document.dispatchEvent(new Event("DOMContentLiteSpeedLoaded")),window.dispatchEvent(new Event("DOMContentLiteSpeedLoaded"))}function litespeed_load_one(t,e){console.log("[LiteSpeed] Load ",t);var d=document.createElement("script");d.addEventListener("load",e),d.addEventListener("error",e),t.getAttributeNames().forEach(e=>{"type"!=e&&d.setAttribute("data-src"==e?"src":e,t.getAttribute(e))});let a=!(d.type="text/javascript");!d.src&&t.textContent&&(d.src=litespeed_inline2src(t.textContent),a=!0),t.after(d),t.remove(),a&&e()}function litespeed_inline2src(t){try{var d=urlCreator.createObjectURL(new Blob([t.replace(/^(?:<!--)?(.*?)(?:-->)?$/gm,"$1")],{type:"text/javascript"}))}catch(e){d="data:text/javascript;base64,"+btoa(t.replace(/^(?:<!--)?(.*?)(?:-->)?$/gm,"$1"))}return d}</script><script data-optimized="1" type="litespeed/javascript" data-src="https://www.scrapingdog.com/wp-content/litespeed/js/227bd2a37b2cfa71fb46d1b313444708.js?ver=e89e0"></script></body>
</html>
`;
const $ = cheerio.load(htmlMarkup);
const $paragraphs = $('p');
console.log($paragraphs.text());
import cheerio from "cheerio";
const htmlMarkup = `
<body>
<h3 class="country-list">List of Countries:</h3>
<ul>
<li class="country">India</li>
<li class="country">Canada</li>
<li class="country">UK</li>
<li class="country">Australia</li>
</ul> <script data-no-optimize="1">window.lazyLoadOptions=Object.assign({},{threshold:300},window.lazyLoadOptions||{});!function(t,e){"object"==typeof exports&&"undefined"!=typeof module?module.exports=e():"function"==typeof define&&define.amd?define(e):(t="undefined"!=typeof globalThis?globalThis:t||self).LazyLoad=e()}(this,function(){"use strict";function e(){return(e=Object.assign||function(t){for(var e=1;e<arguments.length;e++){var n,a=arguments[e];for(n in a)Object.prototype.hasOwnProperty.call(a,n)&&(t[n]=a[n])}return t}).apply(this,arguments)}function o(t){return e({},at,t)}function l(t,e){return t.getAttribute(gt+e)}function c(t){return l(t,vt)}function s(t,e){return function(t,e,n){e=gt+e;null!==n?t.setAttribute(e,n):t.removeAttribute(e)}(t,vt,e)}function i(t){return s(t,null),0}function r(t){return null===c(t)}function u(t){return c(t)===_t}function d(t,e,n,a){t&&(void 0===a?void 0===n?t(e):t(e,n):t(e,n,a))}function f(t,e){et?t.classList.add(e):t.className+=(t.className?" ":"")+e}function _(t,e){et?t.classList.remove(e):t.className=t.className.replace(new RegExp("(^|\\s+)"+e+"(\\s+|$)")," ").replace(/^\s+/,"").replace(/\s+$/,"")}function g(t){return t.llTempImage}function v(t,e){!e||(e=e._observer)&&e.unobserve(t)}function b(t,e){t&&(t.loadingCount+=e)}function p(t,e){t&&(t.toLoadCount=e)}function n(t){for(var e,n=[],a=0;e=t.children[a];a+=1)"SOURCE"===e.tagName&&n.push(e);return n}function h(t,e){(t=t.parentNode)&&"PICTURE"===t.tagName&&n(t).forEach(e)}function a(t,e){n(t).forEach(e)}function m(t){return!!t[lt]}function E(t){return t[lt]}function I(t){return delete t[lt]}function y(e,t){var n;m(e)||(n={},t.forEach(function(t){n[t]=e.getAttribute(t)}),e[lt]=n)}function L(a,t){var o;m(a)&&(o=E(a),t.forEach(function(t){var e,n;e=a,(t=o[n=t])?e.setAttribute(n,t):e.removeAttribute(n)}))}function k(t,e,n){f(t,e.class_loading),s(t,st),n&&(b(n,1),d(e.callback_loading,t,n))}function A(t,e,n){n&&t.setAttribute(e,n)}function O(t,e){A(t,rt,l(t,e.data_sizes)),A(t,it,l(t,e.data_srcset)),A(t,ot,l(t,e.data_src))}function w(t,e,n){var a=l(t,e.data_bg_multi),o=l(t,e.data_bg_multi_hidpi);(a=nt&&o?o:a)&&(t.style.backgroundImage=a,n=n,f(t=t,(e=e).class_applied),s(t,dt),n&&(e.unobserve_completed&&v(t,e),d(e.callback_applied,t,n)))}function x(t,e){!e||0<e.loadingCount||0<e.toLoadCount||d(t.callback_finish,e)}function M(t,e,n){t.addEventListener(e,n),t.llEvLisnrs[e]=n}function N(t){return!!t.llEvLisnrs}function z(t){if(N(t)){var e,n,a=t.llEvLisnrs;for(e in a){var o=a[e];n=e,o=o,t.removeEventListener(n,o)}delete t.llEvLisnrs}}function C(t,e,n){var a;delete t.llTempImage,b(n,-1),(a=n)&&--a.toLoadCount,_(t,e.class_loading),e.unobserve_completed&&v(t,n)}function R(i,r,c){var l=g(i)||i;N(l)||function(t,e,n){N(t)||(t.llEvLisnrs={});var a="VIDEO"===t.tagName?"loadeddata":"load";M(t,a,e),M(t,"error",n)}(l,function(t){var e,n,a,o;n=r,a=c,o=u(e=i),C(e,n,a),f(e,n.class_loaded),s(e,ut),d(n.callback_loaded,e,a),o||x(n,a),z(l)},function(t){var e,n,a,o;n=r,a=c,o=u(e=i),C(e,n,a),f(e,n.class_error),s(e,ft),d(n.callback_error,e,a),o||x(n,a),z(l)})}function T(t,e,n){var a,o,i,r,c;t.llTempImage=document.createElement("IMG"),R(t,e,n),m(c=t)||(c[lt]={backgroundImage:c.style.backgroundImage}),i=n,r=l(a=t,(o=e).data_bg),c=l(a,o.data_bg_hidpi),(r=nt&&c?c:r)&&(a.style.backgroundImage='url("'.concat(r,'")'),g(a).setAttribute(ot,r),k(a,o,i)),w(t,e,n)}function G(t,e,n){var a;R(t,e,n),a=e,e=n,(t=Et[(n=t).tagName])&&(t(n,a),k(n,a,e))}function D(t,e,n){var a;a=t,(-1<It.indexOf(a.tagName)?G:T)(t,e,n)}function S(t,e,n){var a;t.setAttribute("loading","lazy"),R(t,e,n),a=e,(e=Et[(n=t).tagName])&&e(n,a),s(t,_t)}function V(t){t.removeAttribute(ot),t.removeAttribute(it),t.removeAttribute(rt)}function j(t){h(t,function(t){L(t,mt)}),L(t,mt)}function F(t){var e;(e=yt[t.tagName])?e(t):m(e=t)&&(t=E(e),e.style.backgroundImage=t.backgroundImage)}function P(t,e){var n;F(t),n=e,r(e=t)||u(e)||(_(e,n.class_entered),_(e,n.class_exited),_(e,n.class_applied),_(e,n.class_loading),_(e,n.class_loaded),_(e,n.class_error)),i(t),I(t)}function U(t,e,n,a){var o;n.cancel_on_exit&&(c(t)!==st||"IMG"===t.tagName&&(z(t),h(o=t,function(t){V(t)}),V(o),j(t),_(t,n.class_loading),b(a,-1),i(t),d(n.callback_cancel,t,e,a)))}function $(t,e,n,a){var o,i,r=(i=t,0<=bt.indexOf(c(i)));s(t,"entered"),f(t,n.class_entered),_(t,n.class_exited),o=t,i=a,n.unobserve_entered&&v(o,i),d(n.callback_enter,t,e,a),r||D(t,n,a)}function q(t){return t.use_native&&"loading"in HTMLImageElement.prototype}function H(t,o,i){t.forEach(function(t){return(a=t).isIntersecting||0<a.intersectionRatio?$(t.target,t,o,i):(e=t.target,n=t,a=o,t=i,void(r(e)||(f(e,a.class_exited),U(e,n,a,t),d(a.callback_exit,e,n,t))));var e,n,a})}function B(e,n){var t;tt&&!q(e)&&(n._observer=new IntersectionObserver(function(t){H(t,e,n)},{root:(t=e).container===document?null:t.container,rootMargin:t.thresholds||t.threshold+"px"}))}function J(t){return Array.prototype.slice.call(t)}function K(t){return t.container.querySelectorAll(t.elements_selector)}function Q(t){return c(t)===ft}function W(t,e){return e=t||K(e),J(e).filter(r)}function X(e,t){var n;(n=K(e),J(n).filter(Q)).forEach(function(t){_(t,e.class_error),i(t)}),t.update()}function t(t,e){var n,a,t=o(t);this._settings=t,this.loadingCount=0,B(t,this),n=t,a=this,Y&&window.addEventListener("online",function(){X(n,a)}),this.update(e)}var Y="undefined"!=typeof window,Z=Y&&!("onscroll"in window)||"undefined"!=typeof navigator&&/(gle|ing|ro)bot|crawl|spider/i.test(navigator.userAgent),tt=Y&&"IntersectionObserver"in window,et=Y&&"classList"in document.createElement("p"),nt=Y&&1<window.devicePixelRatio,at={elements_selector:".lazy",container:Z||Y?document:null,threshold:300,thresholds:null,data_src:"src",data_srcset:"srcset",data_sizes:"sizes",data_bg:"bg",data_bg_hidpi:"bg-hidpi",data_bg_multi:"bg-multi",data_bg_multi_hidpi:"bg-multi-hidpi",data_poster:"poster",class_applied:"applied",class_loading:"litespeed-loading",class_loaded:"litespeed-loaded",class_error:"error",class_entered:"entered",class_exited:"exited",unobserve_completed:!0,unobserve_entered:!1,cancel_on_exit:!0,callback_enter:null,callback_exit:null,callback_applied:null,callback_loading:null,callback_loaded:null,callback_error:null,callback_finish:null,callback_cancel:null,use_native:!1},ot="src",it="srcset",rt="sizes",ct="poster",lt="llOriginalAttrs",st="loading",ut="loaded",dt="applied",ft="error",_t="native",gt="data-",vt="ll-status",bt=[st,ut,dt,ft],pt=[ot],ht=[ot,ct],mt=[ot,it,rt],Et={IMG:function(t,e){h(t,function(t){y(t,mt),O(t,e)}),y(t,mt),O(t,e)},IFRAME:function(t,e){y(t,pt),A(t,ot,l(t,e.data_src))},VIDEO:function(t,e){a(t,function(t){y(t,pt),A(t,ot,l(t,e.data_src))}),y(t,ht),A(t,ct,l(t,e.data_poster)),A(t,ot,l(t,e.data_src)),t.load()}},It=["IMG","IFRAME","VIDEO"],yt={IMG:j,IFRAME:function(t){L(t,pt)},VIDEO:function(t){a(t,function(t){L(t,pt)}),L(t,ht),t.load()}},Lt=["IMG","IFRAME","VIDEO"];return t.prototype={update:function(t){var e,n,a,o=this._settings,i=W(t,o);{if(p(this,i.length),!Z&&tt)return q(o)?(e=o,n=this,i.forEach(function(t){-1!==Lt.indexOf(t.tagName)&&S(t,e,n)}),void p(n,0)):(t=this._observer,o=i,t.disconnect(),a=t,void o.forEach(function(t){a.observe(t)}));this.loadAll(i)}},destroy:function(){this._observer&&this._observer.disconnect(),K(this._settings).forEach(function(t){I(t)}),delete this._observer,delete this._settings,delete this.loadingCount,delete this.toLoadCount},loadAll:function(t){var e=this,n=this._settings;W(t,n).forEach(function(t){v(t,e),D(t,n,e)})},restoreAll:function(){var e=this._settings;K(e).forEach(function(t){P(t,e)})}},t.load=function(t,e){e=o(e);D(t,e)},t.resetStatus=function(t){i(t)},t}),function(t,e){"use strict";function n(){e.body.classList.add("litespeed_lazyloaded")}function a(){console.log("[LiteSpeed] Start Lazy Load"),o=new LazyLoad(Object.assign({},t.lazyLoadOptions||{},{elements_selector:"[data-lazyloaded]",callback_finish:n})),i=function(){o.update()},t.MutationObserver&&new MutationObserver(i).observe(e.documentElement,{childList:!0,subtree:!0,attributes:!0})}var o,i;t.addEventListener?t.addEventListener("load",a,!1):t.attachEvent("onload",a)}(window,document);</script><script data-no-optimize="1">window.litespeed_ui_events=window.litespeed_ui_events||["mouseover","click","keydown","wheel","touchmove","touchstart"];var urlCreator=window.URL||window.webkitURL;function litespeed_load_delayed_js_force(){console.log("[LiteSpeed] Start Load JS Delayed"),litespeed_ui_events.forEach(e=>{window.removeEventListener(e,litespeed_load_delayed_js_force,{passive:!0})}),document.querySelectorAll("iframe[data-litespeed-src]").forEach(e=>{e.setAttribute("src",e.getAttribute("data-litespeed-src"))}),"loading"==document.readyState?window.addEventListener("DOMContentLoaded",litespeed_load_delayed_js):litespeed_load_delayed_js()}litespeed_ui_events.forEach(e=>{window.addEventListener(e,litespeed_load_delayed_js_force,{passive:!0})});async function litespeed_load_delayed_js(){let t=[];for(var d in document.querySelectorAll('script[type="litespeed/javascript"]').forEach(e=>{t.push(e)}),t)await new Promise(e=>litespeed_load_one(t[d],e));document.dispatchEvent(new Event("DOMContentLiteSpeedLoaded")),window.dispatchEvent(new Event("DOMContentLiteSpeedLoaded"))}function litespeed_load_one(t,e){console.log("[LiteSpeed] Load ",t);var d=document.createElement("script");d.addEventListener("load",e),d.addEventListener("error",e),t.getAttributeNames().forEach(e=>{"type"!=e&&d.setAttribute("data-src"==e?"src":e,t.getAttribute(e))});let a=!(d.type="text/javascript");!d.src&&t.textContent&&(d.src=litespeed_inline2src(t.textContent),a=!0),t.after(d),t.remove(),a&&e()}function litespeed_inline2src(t){try{var d=urlCreator.createObjectURL(new Blob([t.replace(/^(?:<!--)?(.*?)(?:-->)?$/gm,"$1")],{type:"text/javascript"}))}catch(e){d="data:text/javascript;base64,"+btoa(t.replace(/^(?:<!--)?(.*?)(?:-->)?$/gm,"$1"))}return d}</script><script data-optimized="1" type="litespeed/javascript" data-src="https://www.scrapingdog.com/wp-content/litespeed/js/227bd2a37b2cfa71fb46d1b313444708.js?ver=e89e0"></script></body>`;
const $ = cheerio.load(htmlMarkup);
const listItems = $('li');
listItems.each((index, element) => {
console.log($(element).text());
});
Building a Simple Web Scraper
Let’s build a web scraper in Node.js using Node-fetch and Cheerio. We’ll target the Scrapingdog homepage and use these libraries to select HTML elements, retrieve data, and convert it into a useful format.
Step 1: Initial Setup
To begin with, you need to create a folder for your Node.js web scraping project. You can do this by running the following command:
mkdir nodejs-webscraper
cd nodejs-webscraper
npm init -y
Now, create an index.js file in the root folder of your project.
Step 2: Install node-fetch and Cheerio
Install the dependencies required for the Node.js web scraper: cheerio and node-fetch.
npm install node-fetch cheerio
"type": "module",
// index.js
import fetch from 'node-fetch';
import cheerio from 'cheerio';
Step 3: Download your target website
Now, use node-fetch to connect to your target website.
const response = await fetch('<https://scrapingdog.com/>', {
method: 'GET'
});
Step 4: Inspect the HTML page
If you visit the Scrapingdog homepage, you’ll see a list of dedicated scraper APIs for web scraping offered by Scrapingdog. Right-click on one of these HTML elements and select “Inspect”:
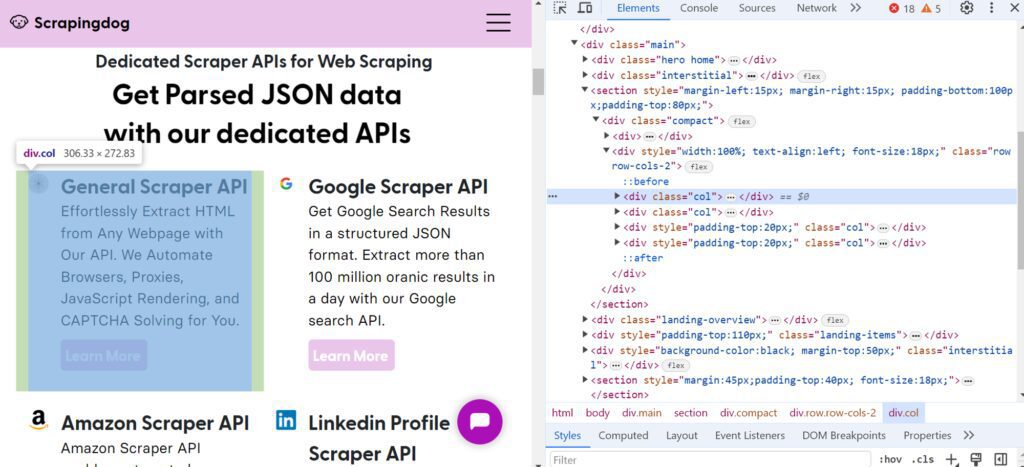
These APIs are organized into sections, each representing a specific scraper. Each section is contained within a <div> element with the class col. Within each section, you’ll find a title (using the <strong> element) and a description (using the <p> element).
Similarly, you can scrape additional data, such as:
- Information about satisfied customers.
- Insights into how customers use Scrapingdog.
Step 5: Select HTML elements with Cheerio
Cheerio loads HTML as a string and returns an object for data extraction using its built-in methods. It offers several ways to select HTML elements, including tag, class, and attribute value.
You can load the HTML using the load function. This function takes a string containing the HTML as an argument and returns an object. The resulting object is assigned to the variable $, which is a common convention used to refer to jQuery objects in JavaScript. In Cheerio, it acts as a reference to the parsed HTML document.
const $ = cheerio.load(html);
$ object provided by Cheerio.To select elements with class names, use the . (dot) followed by the class name selector. For example, if you want to get elements with the class name “hero-title”, use the selector .hero-title. In Cheerio, the .text() method is used to extract the text content of an HTML element.
const title = $('.hero-title').text();
Step 6: Scrape data from a target webpage with Cheerio
You can expand the above logic to extract the desired data from a webpage. First, let’s see how to scrape all dedicated scraper APIs for web scraping.
The hero-title class holds the title. Each col class represents a section with details about a Scraper API. It contains a strong element (<strong>) for the API title and a paragraph (<p>) for the description.
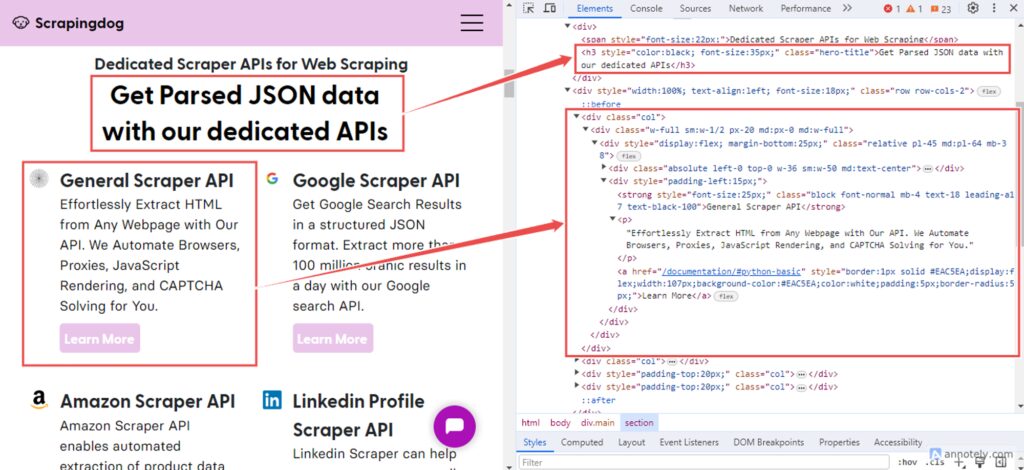
const scraperAPIs = [];
const title = $('.hero-title').text().trim();
$('.col').each((index, element) => {
const api = {};
api.title = $(element).find('strong').text().trim();
api.description = $(element).find('p').text().trim();
scraperAPIs.push(api);
});
The .hero-title selector targets elements with the class hero-title, which likely contains subtitles. The .text() method extracts the text content of these elements.
The .col selector targets elements with the class col, representing individual sections with information about different Scraper APIs. Here, the .each() method iterates over each selected element. Within this loop, .find('strong') selects the <strong> element within each .col, typically containing the API title. Similarly, .find('p') selects the <p> element containing the API description.
The .find method helps us to further filter out the selected elements based on any selector. It searches for matching descendant elements at any level below the selected element.
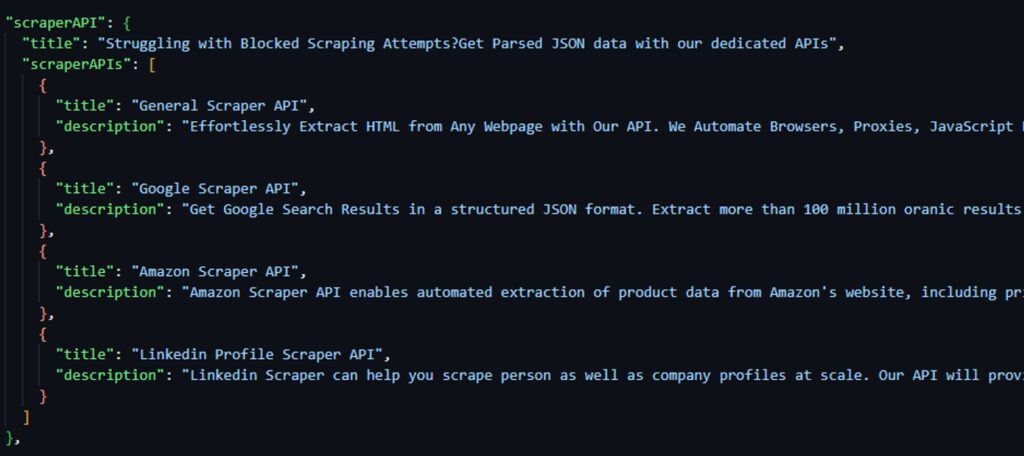
The result of extracted data would be:
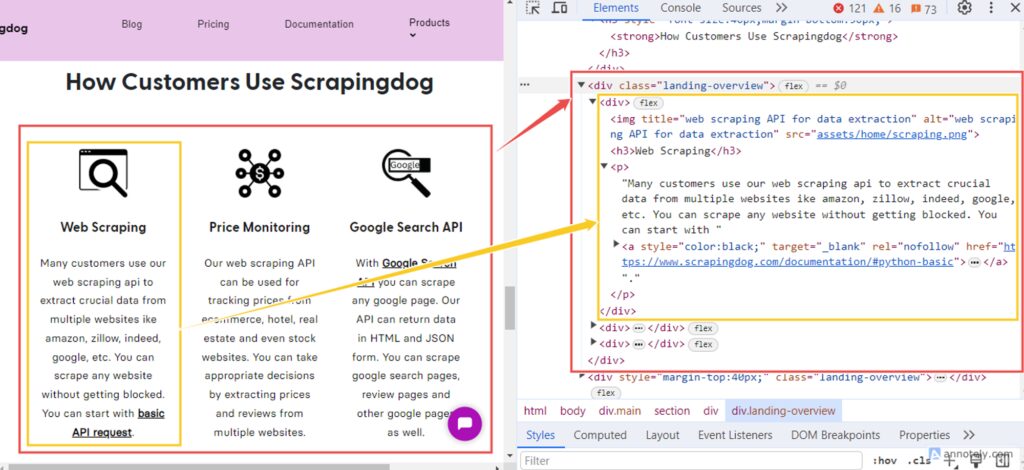
Similarly, you can extract the data on how customers use Scrapingdog. For this, you have to extract data from each < div> element within the class landing-overview. Then iterate through each < div> and retrieve the title from the < h3> tag and the description from the < p> tag.
const customerUsageData = [];
$('.landing-overview div').each((index, element) => {
const titleElement = $(element).find('h3');
const title = titleElement.text().trim();
if (titleElement.length && title.length > 0) {
const descriptionElement = $(element).find('p');
const description = descriptionElement.text().trim();
customerUsageData.push({ title, description });
}
});
This code snippet extracts data from each <div> element within the class landing-overview. It iterates through each <div> and retrieves the title from the <h3> tag and the description from the <p> tag. If both the title and description are found, they are pushed into the “customerUsageData” array.
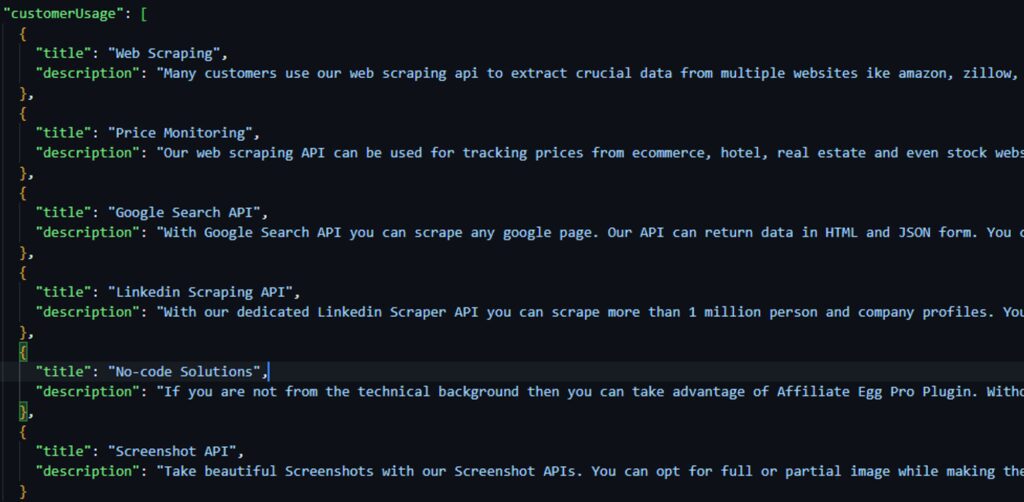
The result is:
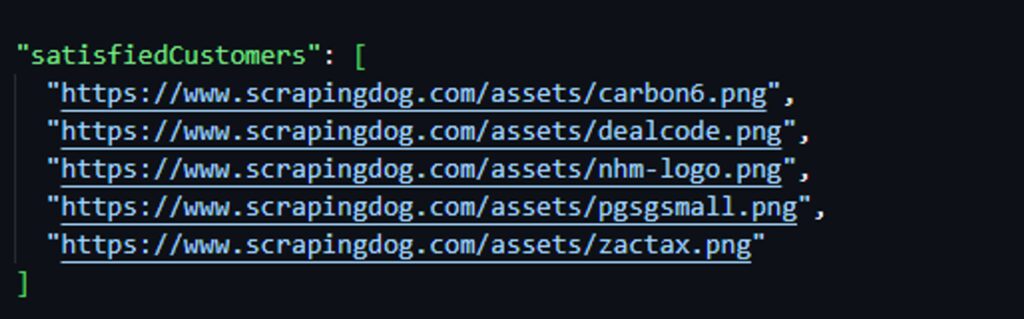
Lastly, you can extract the data of satisfied customers of scrapingdog. For this, you have to fetch the absolute paths of images (< img> elements) that are descendants of < div> element with the class interstitial-companies.
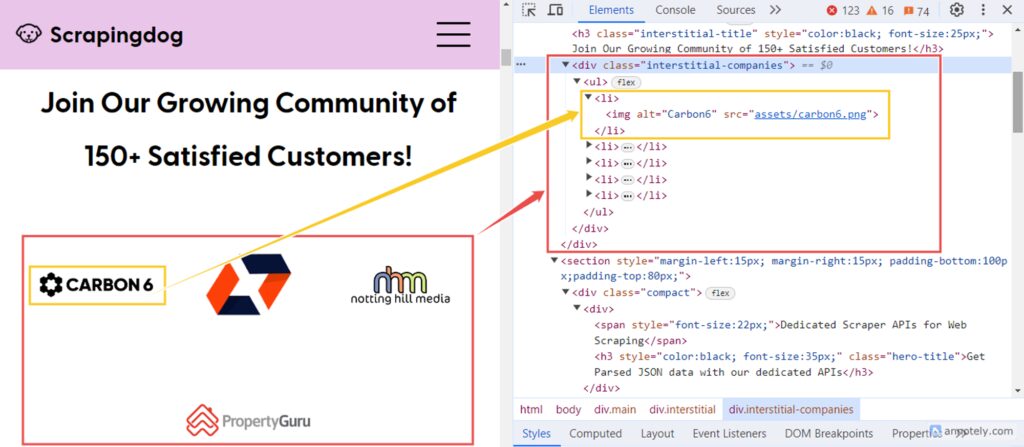
const satisfiedCustomersData = [];
$('div.interstitial-companies img').each((index, element) => {
const relativePath = $(element).attr('src');
const absolutePath = new URL(relativePath, url).href;
satisfiedCustomersData.push(absolutePath);
});
Step 7: Convert the extracted data to JSON
JSON is one of the best data formats for storing scraped data on your local machine. You can use the built-in fs module in Node.js. It allows you to interact with the computer’s file system. Here’s how you can modify the code to write the data to a JSON file:
const data = {
customerUsage: customerUsageData,
scraperAPI: scraperAPIData,
satisfiedCustomers: satisfiedCustomersData
};
const jsonData = JSON.stringify(data); // Convert the object to JSON format
fs.writeFile('data.json', jsonData, () => {
console.log('Data written to the file.');
});
First, you need to create a JavaScript object to hold all the scraped data. Then, you can convert that object into JSON format using JSON.stringify(). The writeFile function takes three arguments: the filename, the data you want to write, and an optional function (called a callback) that gets executed after the writing is complete.
Here’s the JSON data stored in a data.json file:
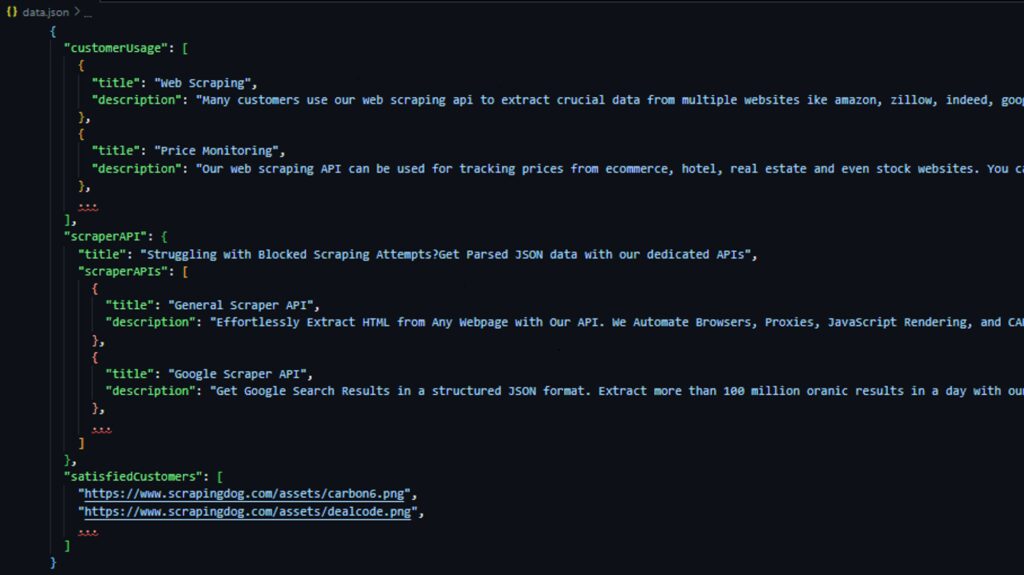
Putting it all together
import fetch from 'node-fetch';
import cheerio from 'cheerio';
import fs from 'fs';
async function customerUsage(url) {
const response = await fetch(url);
const html = await response.text();
const $ = cheerio.load(html);
const customerUsageData = [];
$('.landing-overview div').each((index, element) => {
const titleElement = $(element).find('h3');
const title = titleElement.text().trim();
if (titleElement.length && title.length > 0) {
const descriptionElement = $(element).find('p');
const description = descriptionElement.text().trim();
customerUsageData.push({ title, description });
}
});
return customerUsageData;
}
async function scraperAPI(url) {
const response = await fetch(url);
const html = await response.text();
const $ = cheerio.load(html);
const scraperAPIs = [];
const title = $('.hero-title').text().trim();
$('.col').each((index, element) => {
const api = {};
api.title = $(element).find('strong').text().trim();
api.description = $(element).find('p').text().trim();
scraperAPIs.push(api);
});
return { title, scraperAPIs };
}
async function satisfiedCustomers(url) {
const response = await fetch(url);
const html = await response.text();
const $ = cheerio.load(html);
const satisfiedCustomersData = [];
$('div.interstitial-companies img').each((index, element) => {
const relativePath = $(element).attr('src');
const absolutePath = new URL(relativePath, url).href;
satisfiedCustomersData.push(absolutePath);
});
return satisfiedCustomersData;
}
async function writeDataToJsonFile() {
const url = '<https://scrapingdog.com/>';
const customerUsageData = await customerUsage(url);
const scraperAPIData = await scraperAPI(url);
const satisfiedCustomersData = await satisfiedCustomers(url);
const data = {
customerUsage: customerUsageData,
scraperAPI: scraperAPIData,
satisfiedCustomers: satisfiedCustomersData
};
fs.writeFile('data.json', JSON.stringify(data, null, 2), (err) => {
if (err) {
console.error('Error writing JSON file:', err);
} else {
console.log('Data has been written to data.json');
}
});
}
writeDataToJsonFile();
As shown here, Node.js web scraping allows you to download and parse HTML web pages, extract their data, and convert it into a structured JSON format – all with the help of libraries like Cheerio and node-fetch.
Finally, launch your web scraper with:
npm run start
Handling Exceptions and Errors
Your requests can sometimes fail for a variety of reasons, including small errors within the fetch() function, internet connectivity issues, server errors, and so on. You need a way to handle or detect these errors.
You can handle runtime exceptions by adding catch() at the end of the promise chain. Let’s add a simple catch() function to the code:
fetch(url)
.then(response => response.json())
.then(data => console.log('Data:', data))
.catch(error => console.error('Error:', error));
It is not recommended to ignore and print errors, but instead, have a mechanism to handle them effectively. One way to ensure failed requests throw an error is to check the HTTP status of the server’s response.
If the status code doesn’t indicate success (codes outside the 2xx range), you can throw an error, and .catch() will catch it. You can use the ok field of Response objects, which equals true if the status code is in the 2xx range.
fetch(url)
.then(res => {
if (res.ok) {
return res.json();
} else {
throw new Error(`The HTTP status of the response: ${res.status} (${res.statusText})`);
}
})
.then(data => {
console.log('Data:', data);
})
.catch(error => {
console.error('Error:', error);
});
async function customerUsage(url) {
return fetch(url)
.then(response => {
if (!response.ok) {
throw new Error('Network response was not ok');
}
return response.text();
})
.then(html => {
const $ = cheerio.load(html);
const customerUsageData = [];
$('.landing-overview div').each((index, element) => {
const titleElement = $(element).find('h3');
const title = titleElement.text().trim();
if (titleElement.length && title.length > 0) {
const descriptionElement = $(element).find('p');
const description = descriptionElement.text().trim();
customerUsageData.push({ title, description });
}
});
return customerUsageData;
})
.catch(error => {
console.error('There was a problem with the fetch operation:', error);
});
}
The code uses fetch(URL) to make an asynchronous HTTP request to the specified URL. It returns a Promise that resolves to the response. The .then() method is chained to handle the response. Inside this block, the status code is checked using response.ok. If the status code isn’t in the 200-299 range (success), an error is thrown.
Following the .then() block, the .catch() method catches any errors during the fetch or subsequent Promise chain. If an error occurs, this block logs it to the console using console.error().
Avoiding Blocks
Note that, websites often implement anti-scraping measures to prevent unauthorized data collection. A common method involves blocking requests that lack a valid User-Agent HTTP header and the use of proxies. To bypass these anti-bot mechanisms, ensure you use a real user agent and proxies.
For example, Node-Fetch includes the following user-agent in the request it sends:
"User-Agent": "node-fetch"
This user agent identifies requests made by the Node-Fetch library, which makes it easy for websites to block scraping.
Setting a fake user-agent in Node-Fetch is simple. You can create an options object with the desired user-agent string in the headers parameter and pass it to the fetch request.
const options = {
method: "GET",
headers: {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36'
}
};
import fetch from 'node-fetch';
(async () => {
const url = '<http://httpbin.org/headers>';
const options = {
method: 'GET',
headers: {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36'
}
};
try {
const response = await fetch(url, options);
const data = await response.json();
console.log(data);
} catch (error) {
console.log('error', error);
}
})();
Using proxies with the Node-fetch library allows you to distribute your requests over multiple IP addresses, making it harder for websites to detect and block your web scrapers.
However, Node-fetch does not natively support proxies. There is a workaround, though: you need to integrate a proxy server using the HTTPS-proxy-agent library. Install it using the command below:
npm install https-proxy-agent
Once installed, you need to create a proxy agent using HttpsProxyAgent and pass it into your fetch request using the agent parameter.
import fetch from 'node-fetch';
import { HttpsProxyAgent } from 'https-proxy-agent';
(async () => {
const targetUrl = '<https://httpbin.org/ip?json>';
const proxyUrl = '<http://20.210.113.32:80>';
const agent = new HttpsProxyAgent(proxyUrl);
const response = await fetch(targetUrl, { agent });
const data = await response.text();
console.log(data);
})();
Depending on your specific needs, setting up a Node-fetch proxy may not be enough to avoid being blocked. If you make too many requests from the same IP address, you could get blocked or banned.
One way to avoid this is by rotating proxies, which means each request will appear to come from a different IP, making it difficult for websites to detect. However, manually rotating proxies has its drawbacks. You will need to create and maintain an updated list yourself.
Also, when you are setting user-agents to your scraper, the same principle applies!
Scrapingdog simplifies web scraping. You no longer need to manually configure proxy rotation using open-source libraries which are less updated. Scrapingdog handles all of this for you with its user-friendly web scraping API. It takes care of rotating proxies, headless browsers, and CAPTCHAs, making the entire process effortless.


